Building DBRX-class Custom LLMs with Databricks Training
by Anna Pfohl, Cheng Li, Mihir Patel, Wai Wu, Will Gleich, Ajay Saini and Hagay Lupesko
We recently introduced DBRX: an open, state-of-the-art, general-purpose LLM. DBRX was trained, fine-tuned, and evaluated using Databricks Training, scaling training to 3072 NVIDIA H100s and processing more than 12 trillion tokens in the process.
Training LLMs, and in particular MoE models such as DBRX, is hard. It requires overcoming many infrastructure, performance, and scientific challenges. Databricks Training was purposely built to address these challenges and was battle-tested through the training of DBRX, the MPT series of models, and many other LLMs such as Ola’s Krutrim, AI2’s OLMo, Dynamo AI’s Dynamo 8B, Refuel’s LLM-2, and others.
Databricks Training is available today for Databricks customers to build custom models on their own enterprise data that are tailored to a specific business context, language and domain, and can efficiently power key business use cases.
These custom models are especially useful when applied to particular domains (e.g., legal, finance, etc.) and when trained to handle low-resource languages. We've seen our customers either pretrain custom models or extensively continue training on open source models to power their unique business use cases, and we're looking forward to helping many more customers train and own their own LLMs.
This blog post details Databricks Training's core capabilities and how they were critical to the successful training of DBRX. To get started building your own DBRX-grade custom LLM that leverages your enterprise data, check out the Databricks Training product page or contact us today.
"Databricks Training infrastructure has been critical in our training of OLMo and other truly open large language models." - Dirk Groenveld, Principal Software Engineer, Allen Institute for Artificial Intelligence.
Databricks Training stack
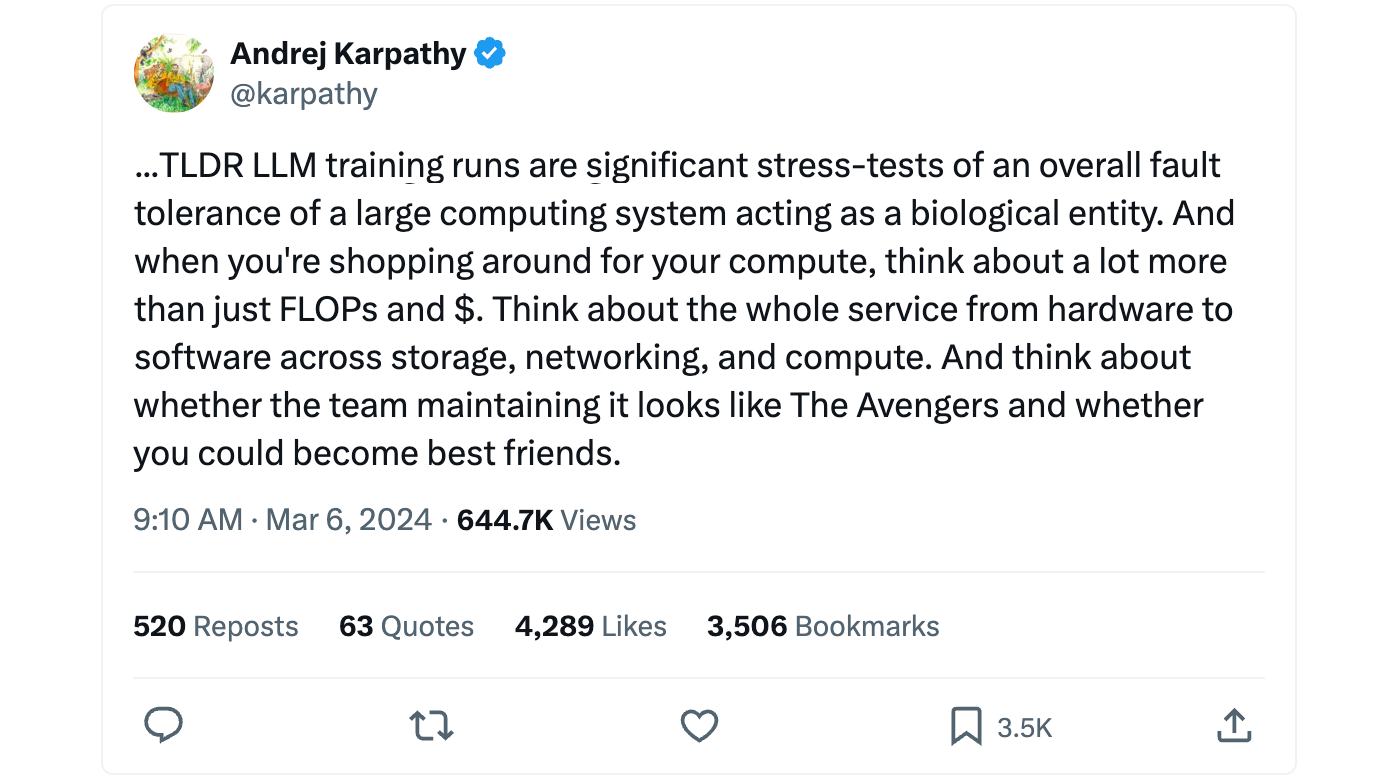
Training LLMs and other large AI models requires the integration of numerous components, from hardware device drivers to job orchestration and all the way up to the neural network training loop. This process is complex and necessitates a wide range of expertise. Even a simple mistake, such as a misconfigured network driver, can lead to a 5x slow down in training speed!
To simplify this complexity and to deliver an experience that “just works", Databricks Training offers an optimized training stack that handles all aspects of large-scale distributed training. The stack supports multiple GPU cloud providers (AWS, Azure, OCI, Coreweave, to name a few), is configured with the latest GPU drivers including NVIDIA CUDA and AMD ROCm, and includes core neural network and training libraries (PyTorch, MegaBlocks, Composer, Streaming). Lastly, battle-tested scripts for training, fine-tuning, and evaluating LLMs are available in LLMFoundry, enabling customers to start training their own LLMs immediately.
“At Refuel, we recognize the value of purpose-built, custom LLMs for specific use cases. Our newly released model, RefuelLLM-2, was trained on the Databricks Training infrastructure and gave us the ability to coordinate numerous components, from unstructured data to hardware device drivers to training libraries and job orchestration, in one easy-to-use resource." - Nihit Desai, Co-Founder & CTO, Refuel
Distributed training
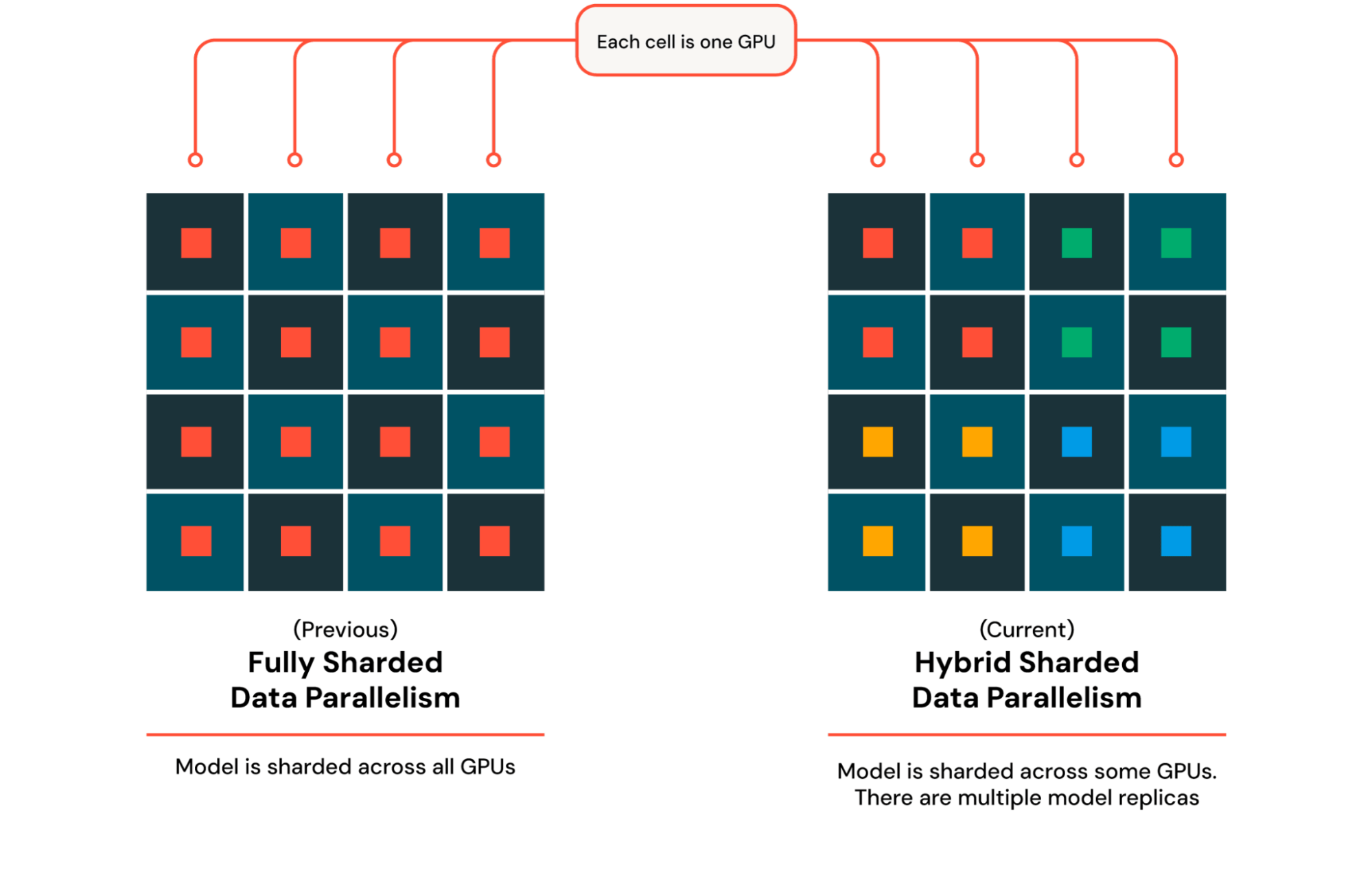
In order to train models on thousands of GPUs, Databricks Training leverages DTensor, a simple framework in PyTorch to describe how tensors are sharded and replicated. When extending model training from one GPU to multiple GPUs, we often leverage Distributed Data Parallel (DDP) training, which relies on replicating the model and optimizer across different GPUs. When training a model that does not fit in the memory of a single GPU, as is the case with DBRX, we instead use Fully Sharded Data Parallel (FSDP) training, where the model and optimizer are sharded across multiple GPUs and gathered for an operation such as a matrix multiplication. Each operation that involves gathering and sharding across multiple GPUs slows down as the number of machines increases, so we use Hybrid Sharded Data Parallel (HSDP) training, which shards the model and optimizer across a fixed replica size and then copies this replica multiple times to fill up the entire cluster (Figure 3). With DTensor, we can construct a device mesh that describes how tensors are sharded and replicated and pass it into Pytorch’s implementation of FSDP. For MoE models such as DBRX, we improve training parallelism to include expert parallelism, which places different experts on different GPUs. To boost performance, we leverage MegaBlocks, an efficient implementation of expert parallelism. Additionally, we apply sequence length parallelism to support long context training, greatly improving support for key use cases like Retrieval Augmented Generation (RAG). We integrate all these technologies into Composer, our open-source training library which handles parallelism under the hood, giving users a simple, clean interface to focus on their model and data.
Given an efficient parallelism setup, we leverage the open source Streaming library to fetch data on-the-fly during training. Streaming guarantees deterministic shuffling across thousands of machines with less than 1 minute of startup overhead and no training overhead. When we encounter hardware failures, Streaming is able to deterministically resume exactly where it left off instantaneously. This determinism is critical to ensuring reproducible results regardless of hardware issues or restarts. Beyond data shuffling, modern LLM training often involves multiple stages of training in a process called curriculum training, where important, higher quality data is upsampled towards the end of training. With just a few parameter overrides, Streaming natively supports advanced features like these, automatically updating dataset mixtures later into training.
Distributed checkpointing
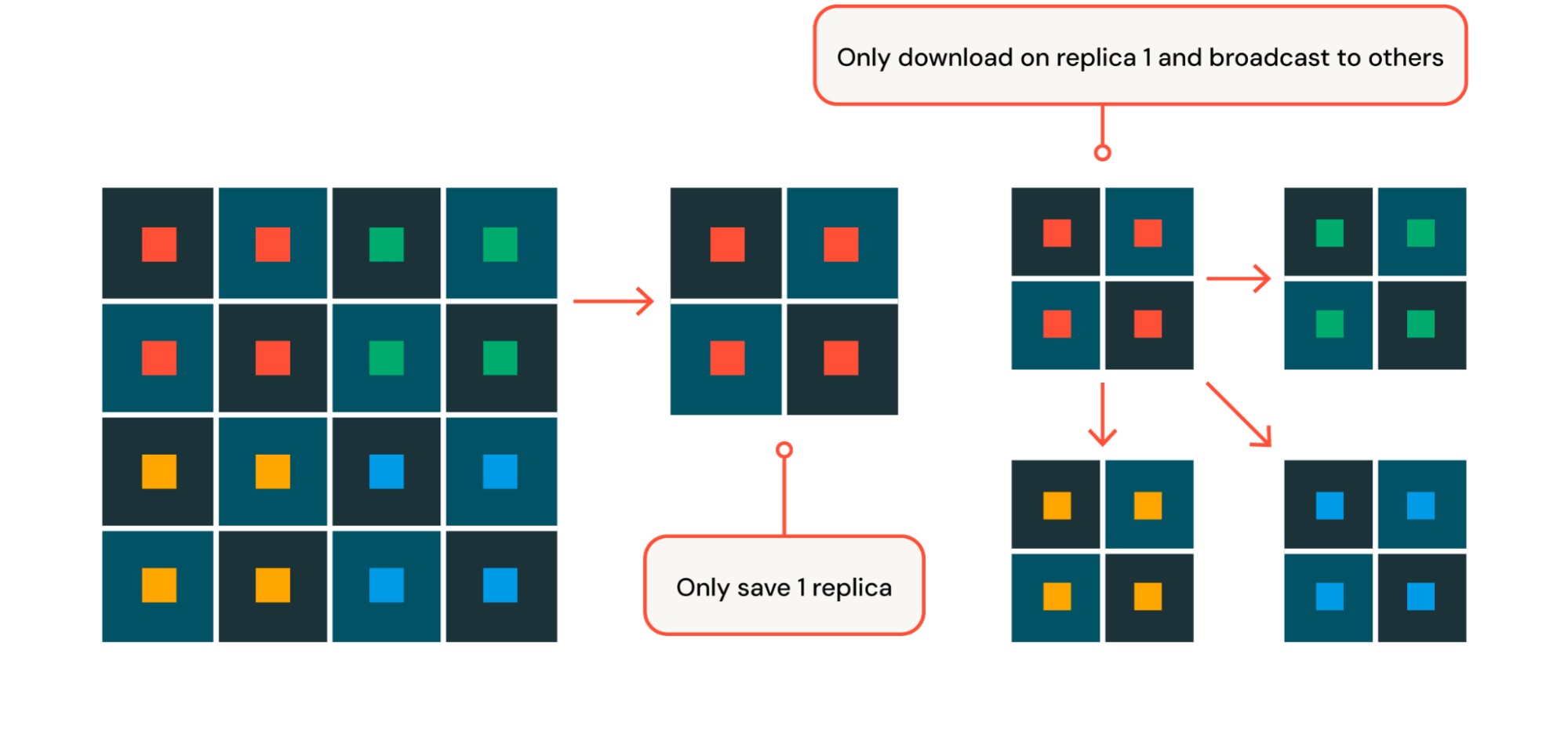
To ensure rapid recovery from hardware failures (more on hardware failures later in this blog post!), Databricks Training implements heavily-optimized checkpoint saving and loading. When pre-training, we leverage a sharded checkpoint where each GPU saves or loads only its sharded portion of the model parameters and optimizer state. By spreading out the work of saving and loading across hundreds of machines, we minimize blocking time to under 30 seconds during save and load, even when training models with hundreds of billions of parameters and checkpoints that are several terabytes in size such as DBRX. With HSDP, we further optimize this process by only saving and loading checkpoint within the first replica and broadcasting to all other replicas when necessary (Figure 4).
Training performance optimizations
Attaining the best possible performance during LLM training is critical to minimizing both training duration and cost, especially given the scale of LLM training, which often involves thousands of expensive high-end GPUs. As an example, DBRX training spanned 3072 H100 GPUs across a 3-month duration. Databricks Training aggressively optimizes memory usage and computation to achieve such SOTA training efficiency.
The memory usage of training LLM includes the model parameters, optimizer state, gradients, and activations. These limit the runnable training batch size, and as models scale, can become a critical performance bottleneck. Note that a larger batch size results in larger matrix multiplications that provide higher GPU utilization. To address model parameters, optimizer state, and gradients, we leverage PyTorch FSDP and HSDP as previously described. To address activation memory, we use a mixture of selective activation checkpointing and compression. Activation checkpointing recomputes instead of saving some of these intermediate tensors, saving memory at the cost of additional computation. This additional memory enables a larger batch size in DBRX training. To apply activation checkpointing efficiently, we support checkpointing the activations in a configurable way, where we can easily specify model granularity (full block, attention, etc.) and range (e.g., first-n layers, range(m, k) layers). Along with activation checkpointing, we’ve developed custom, low-level kernels to compress activations. Instead of storing all activations in 16-bit precision, we compress these activations into custom, lower-precision formats, significantly reducing activation memory while having a minimal impact on model quality. These memory optimizations reduce the memory footprint by nearly 3x for large models like DBRX.
Databricks Training also optimizes computation, ensuring the GPU is running at maximal FLOPS as long as possible. We first generate detailed event profiles (CPU, CUDA kernels, NCCL, etc.) of our models using the PyTorch profiler as well as custom benchmarks. These results heavily motivate further improvements, enabling us to always target the most significant bottleneck. For example, we leverage performant operators from FlashAttention 2, MegaBlocks, and other custom kernels to avoid CPU and memory bottlenecks for key layers in DBRX. To enable fast, dropless MoEs, we reorder GPU and CPU events to ensure CUDA kernels are not blocked by device synchronization, further avoiding CPU bottlenecks. To avoid communication bottlenecks, we employ other optimizations that maximizes the flops per GPU. Put together, this work enables training advanced MoE architectures at nearly the same speed as standard transformers across a large variety of scales.
GPU fault tolerance
Training LLMs involves orchestrating thousands of GPUs across hundreds of nodes, introducing infrastructure scaling and reliability challenges. Node failures are extremely common at this scale. We will discuss some key features of Databricks Training that enabled our success.
To quickly detect and remediate device-level issues, Databricks Training ships with a robust set of GPU alerts leveraging NVIDIA’s prometheus metric exporter (DCGM Exporter) which detects common GPU errors (XID errors) such as ECC uncorrectable errors and remapping errors, GPU disconnections, and GPU ROM failures. We extend the DCGM operator configuration to monitor GPU throttling to identify additional GPU performance issues, such as thermal and power violations reported from the GPUs.
Databricks Training also triggers automatic cluster sweeps with smaller diagnostic workloads when certain configurable conditions are met during training, such as when Model FLOPs Utilization (MFU) drops below a pre-configured threshold. Upon diagnostic test failure, Databricks Training cordons straggling nodes and automatically resumes the run from the latest checkpoint using Composer’s autoresume functionality and distributed checkpointing.
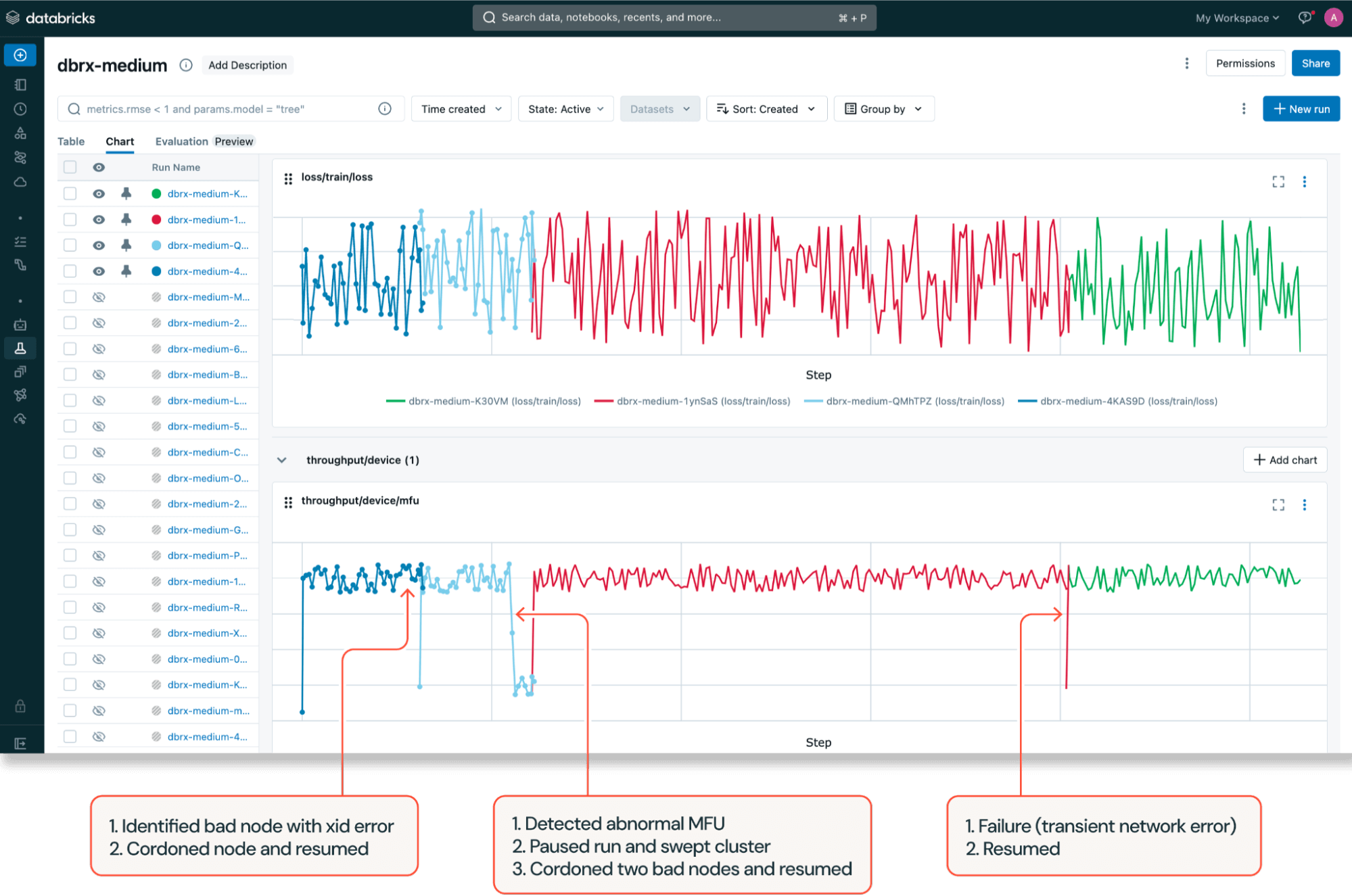
In combination, these fault tolerance capabilities were extremely helpful for DBRX training. With limited GPU capacity, even a slight drop in the number of nodes available could have greatly affected scheduling goodput, a term coined by Google representing the fraction of time that all the resources required to run the training job are available. Our alerting and remediation system identified various GPU errors and recycled bad nodes before the run was scheduled, thereby ensuring high scheduling goodput.
Network fabric fault tolerance
Databricks Training offers the ability to pinpoint specific issues within the GPUDirect Remote Direct Memory Access (GDRDMA) fabric, such as switch port failures and complete switch failures.
To collect these metrics, Databricks Training periodically schedules a set of quick-running blocking health checks. These are canary deployments that stress test sets of nodes to collect both compute and communication benchmarks. The compute tests include multi-gpu CUDA stress tests to check that GPUs run optimally at fully utilized workloads. The communication tests include all-reduce NCCL tests between neighboring nodes using the NVIDIA nccl-test methodology. Databricks Training then consumes the metrics from these tests for varying NCCL payload sizes and cordons off cluster nodes with any anomalies or failures.
When training DBRX, these network fabric checks identified multiple switch issues that occurred during the three-month training period. This enabled the run to resume on a smaller partition of nodes while the cloud provider serviced the switch outage.
Figure 6 shows the rough outline of how our network fabric checks were orchestrated:
- Databricks Health Checking API tracks and awaits target nodes that are ready for checking.
- API spawns distributed training processes that run NCCL all reduce tests.
- RPC callbacks to health checking API with collective communication and compute metrics.
- Health Checking API cordons nodes with anomalous metrics.
Experiment tracking
In addition to alerts and GPU health monitoring, Databricks Training integrates with MLflow and other experiment trackers to provide real-time tracking of training metrics, training progress, system metrics, and evaluation results. We used these to monitor progress at all phases of DBRX training, whether for our initial experiments, health checks, or final large-scale training run (see Figure 5).
To monitor DBRX training progress and approximate final model quality, we ran a full sweep of evaluation tasks for every 1T tokens trained using the Mosaic Evaluation Gauntlet across the full 12 trillion tokens the model was trained on. By saving intermediate and fine-tuned checkpoints in the MLflow Model Registry, we were able to easily manage multiple versions of the model for evaluation and deploy with Databricks Model Serving.
“Databricks enabled us to train Dynamo8B, an industry-leading foundation model, focusing on enterprise compliance and responsible AI for our customers. The configured container images and out-of-the-box training scripts saved us weeks’ worth of development time, and with Databricks Training's built-in speed-ups and GPU availability on-demand, it took us just ten days to pretrain our 8-billion parameter multilingual LLM." - Eric Lin, Head of Applied AI, Dynamo AI
Start training your own custom LLM
To get started building your own DBRX-grade custom LLM that leverages your enterprise data, check out the Databricks Training product page or contact us for more information.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.