Redefining Customer Support: Swiggy’s Enterprise-Scale AI Agent Built with Databricks
How Swiggy transformed customer engagement with an enterprise-class AI Agent — achieving full automation, hyper-scalability, and industry-leading personalization.
by Gireesh Sreedhar and Shrinath Agarwal
- Swiggy’s Transformation With Enterprise AI Agents: How Swiggy and Databricks designed and scaled a ground-breaking AI solution to automate and personalize customer support at a massive scale.
- Step-by-Step Journey to Production AI: The full innovation roadmap, from initial prototypes and model selection to advanced multi-agent systems, real-time monitoring, and seamless CRM integration.
- Key Results, Lessons, and Best Practices: The measurable impact on customer experience and operations, plus practical insights and lessons for deploying AI agent architectures in real-world enterprise environments.
Raising the Bar: Swiggy’s Vision for Scalable, Intelligent Customer Support
Swiggy, India’s leading on-demand delivery platform, is dedicated to continually elevating operational efficiency and customer experience. While its rule-based engine provided a solid foundation for scalable support, Swiggy saw opportunities for greater personalization, adaptive context handling, and flexibility as its customer base rapidly expanded. Seizing this momentum, Swiggy partnered with Databricks to design and launch an enterprise-class AI Solution — delivering instant, empathetic, and hyper-scalable support that sets a new benchmark for intelligent customer engagement.
This blog explores the innovation journey, technical breakthroughs, and strategic business value achieved — offering insights into the future of intelligent, scalable customer support in digital commerce.
The Challenge: Why Legacy Approaches No Longer Fit
Swiggy, headquartered in Bangalore, delivers millions of restaurant orders each day across India, reflecting its commitment to seamless and delightful customer experiences at scale. As the platform rapidly expanded, inquiry volumes and complexity rose sharply.
Swiggy places customer satisfaction at the heart of its operations and views this challenge as an opportunity to enhance the customer experience by combining human expertise with AI.
Challenges:
Scalability challenges exist, as rule-based workflows require more manual oversight and lack the flexibility to adapt to sudden demand spikes.
Difficulty delivering personalized and contextually relevant support, as the rule-based system lacked personalization and context awareness.
Limited agility in updating or expanding support workflows makes deploying new solutions quickly for evolving customer needs difficult.
Delivery of generic, impersonal responses, with the rule-based engine unable to effectively handle complex or nuanced inquiries. Rule-based systems’ rigid, one-size-fits-all responses.
Objectives:
Achieve always-on instant support with a human-like touch
Automate handling of the maximum number of queries possible
Reduce reliance on, and costs associated with, human agents by reducing direct human intervention and moving to human-in-the-loop
Seamlessly absorb demand spikes without manual intervention
Personalize and humanize every customer interaction
Reduce average handling time (AHT)
Experimentation and Rapid Prototyping: Swiggy’s AI Agent Journey
Faced with an uncharted landscape with few proven templates, Swiggy and Databricks adopted an agile, iterative prototyping approach, rapidly leveraging state-of-the-art advances in large language models (LLMs) and agent frameworks. Instead of starting with a complex architecture, we began with mature and simple architectures for POC. The limitations were identified with each iteration, and the architecture and technology refinements were made until the technical and functional objectives were met.
The experimentation journey below shows the solution's evolution and how it adapted to accelerated technological change, taking advantage of the latest technologies to improve and meet business objectives.
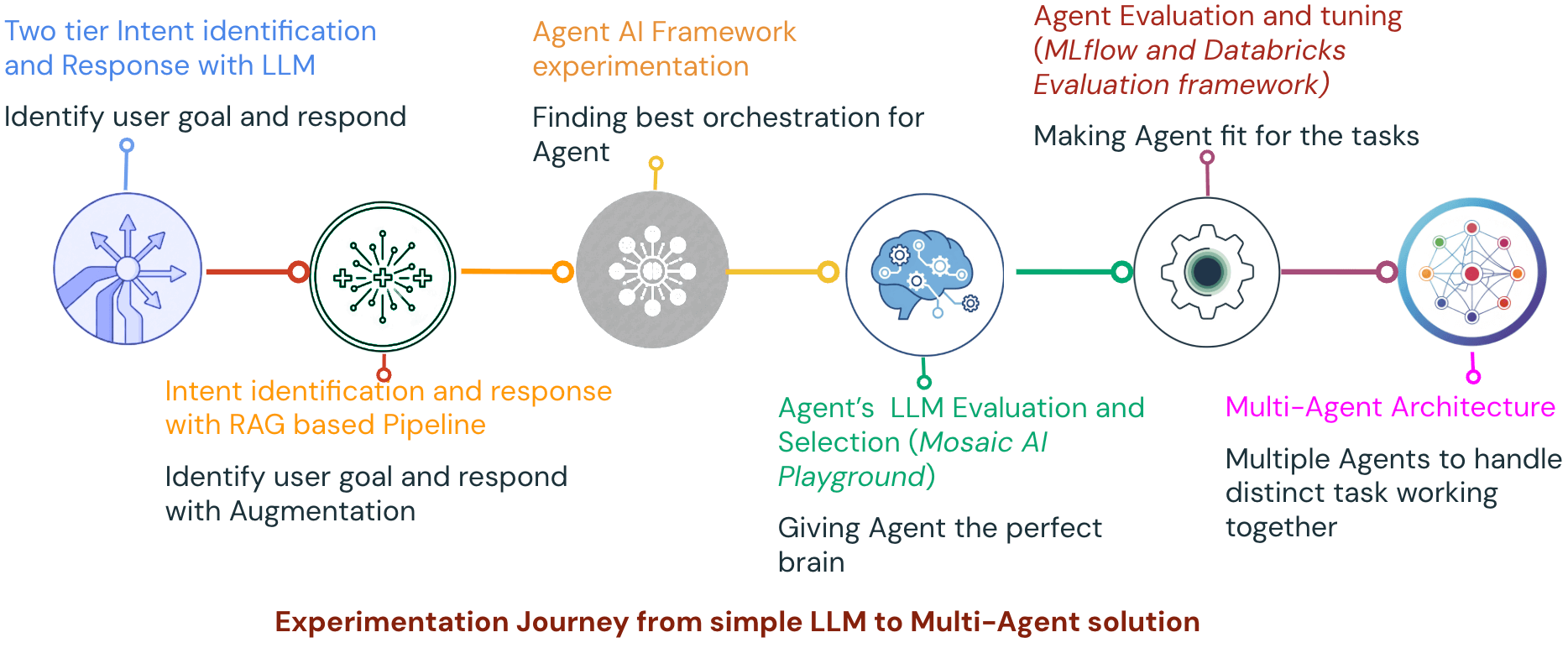
Key Phases
1. Two-Tier Intent + LLM Response Model:
The journey started with a two-layered pipeline architecture with an LLM as the intelligent layer.
The first layer, the Intent Identification Layer, primarily determines the underlying goal or purpose behind a user's input — what the user wants to achieve by interacting with the agent (e.g., order status, refund request, greeting, gratitude, etc.). A basic prompt-based intent classification using LLM was used for intent identification. The second layer, Response Formatting Layer, primarily aims to generate structured and business-relevant responses based on the identified Intent and order-related information collected from backend systems. The response is formatted into a clear, contextually appropriate and user-friendly response.
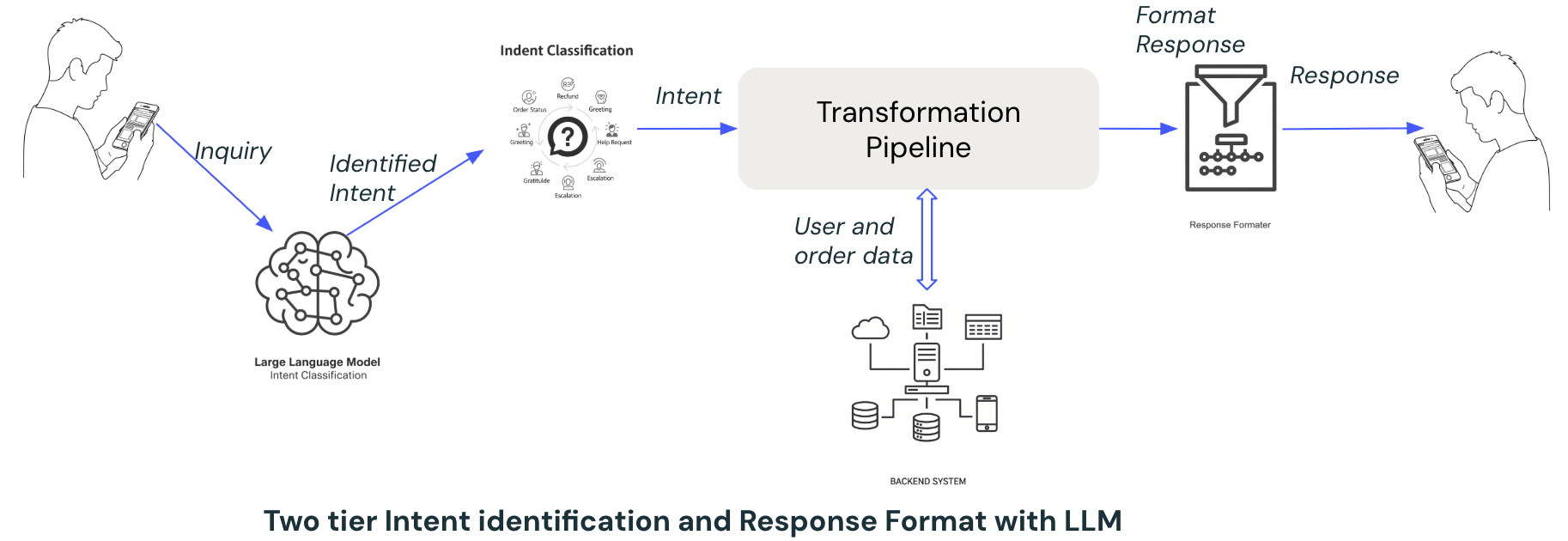
LLM-driven intent detection and response formatting enabled quick wins, but hit limits in context handling and extensibility.
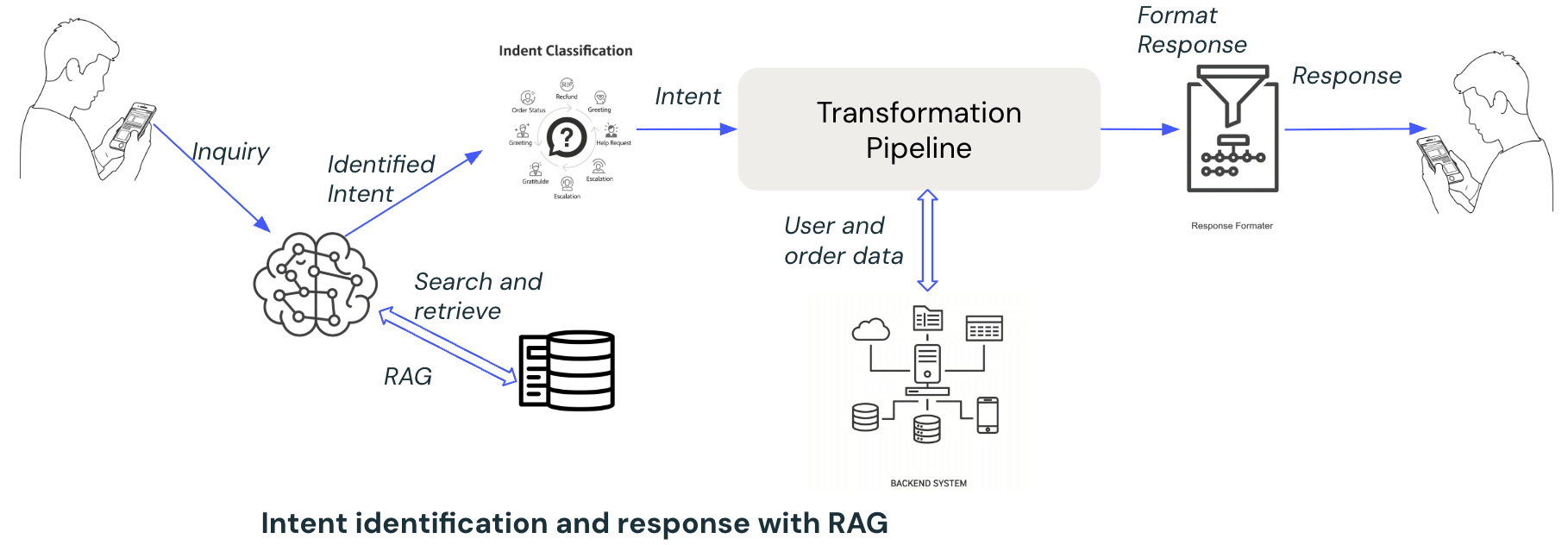
2. Addition of RAG (Retrieval-Augmented Generation):
The journey of the two-layered pipeline continued with the addition of the RAG pipeline to the intelligence layer. This approach enhanced the LLM by providing additional context based on retrievals, which is expected to improve the outcomes. This approach has serious limitations as follows:
Hardcoded Logic: Each intent required manual branching, making the system rigid and challenging to extend for new workflows.
Lack of Context Retention: The RAG approach was stateless, leading to context loss in multi-turn conversations and making it unsuitable for scenarios requiring follow-up actions or escalation.
No Feedback Loop: There was no mechanism to learn from previous interactions or improve over time.
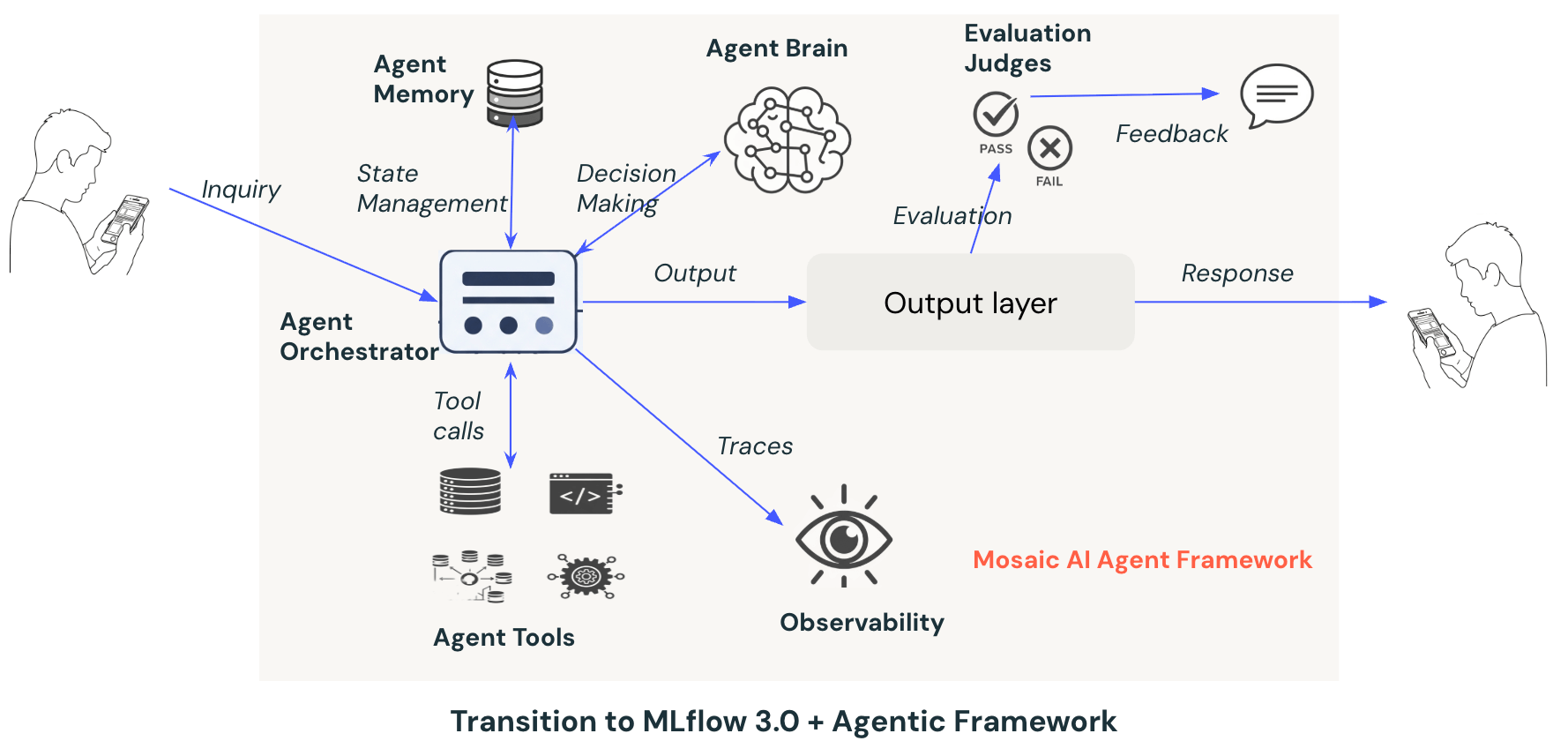
3. Agentic AI Transition:
The limitations of the simple LLM and RAG approach, especially around extensibility, rules management and context management, prompted a shift to a more flexible framework, intelligent and autonomous solutions. This was when Agentic AI was taking baby steps, and we captured this opportunity to take Agentic AI as our next frontier for the POC. The immediate benefits we realised with Agent were
Stateful Conversations: enabled persistent memory, allowing the agent to maintain context across multiple turns.
Modular Design: The node-based graph execution allowed different intent handlers to be modeled as graph branches, improving maintainability and extensibility.
Feedback Integration: The new setup supported feedback loops, enabling the agent to learn and adapt from user interactions.
Improved Reusability: Decoupling logic from intent handling made adding new features and workflows easier.
4. Large Language Model (LLM) Evaluation and Selection
The LLM acts as an Agent's brain that processes inputs received, understands its inputs and goals to be achieved. Since this is the most critical component of the Agent, evaluations were conducted on various models to determine the most suitable model capable of matching task requirements, performance, deployment requirements and at optimum cost. We leveraged Databricks AI Playground for quick experiments with models for candidate model selection. The summary of LLM experiments is as follows:
Model ‘family A’ - Most effective for conversational tasks, offering coherent multi-turn dialogue with minimal prompt engineering.
Model ‘family B’ - Demonstrated strong reasoning capabilities and provided concise responses, but requires significant prompt tuning to align with conversational expectations, making them less ideal for general dialogue use cases.
Model ‘family C’ - Demonstrated reasoning capabilities but failed in making tool calls, resulting in technical errors.
Based on experiment observations, Model ‘family C’ was eliminated after initial iterations, and we continued with ‘family A’ and ‘family B’. Even though ‘family B’ outperformed ‘family A’ in reasoning-heavy tasks, we selected ‘family A’ for its more natural conversational output and minimal prompt engineering efforts.
5. Agent Tuning and Robust Evaluation:
Once the Agent framework and LLM choice are finalised, we enter the final phase of the Agent’s evaluation and tuning. Here, we focused on two key aspects: the Evaluation of the Agent and tuning/refining the Agent.
Evaluation of the Agent — Evaluation ensures the tasks charted for the Agent work, including functional, non-functional and behavioral aspects. The critical areas in the assessment for our task are Accuracy, Factual correctness, Stability (consistency and reliability), Cost, Latency, Response Style, Conversational coherence and Security.
The evaluation is made comprehensive and straightforward by MLflow 3.0, providing advanced evaluation techniques using SDK and UI to define evaluation criteria specific to our needs. Features like built-in AI judges, custom AI judges, and a review app for human reviews cover all qualitative and quantitative metrics used to evaluate the quality of the experimentations.
6. Tuning of Agent (prompt engineering) - Providing effective prompts is crucial for directing LLM toward Agent's goals. Prompt is an area that needs a lot of iterations to get to a prompt that can maximise the agent's performance. We explored various prompt engineering techniques to improve the quality, consistency, and relevance. This included approaches such as Meta prompting, ReAct prompting (Reasoning and Acting), and Chain-of-Thought (CoT) prompting. Each technique was tested across multiple scenarios to assess its impact on reasoning ability, factual correctness, and conversational coherence.
These experiments helped us understand the strengths and trade-offs of each method — for example, Chain-of-Thought prompting improved step-by-step reasoning but increased response length, while ReAct prompting enhanced decision-making in interactive flows.
MLflow’s Prompt Registry simplifies prompt engineering by systematically evaluating different prompt versions to identify the most effective prompt for the agent.
7. Multi-Agent Architecture:
We enhanced the Agent with a multi-agent solution to support multi-intent conversations and better handle modular tasks. Here, a new agent instance is launched for each distinct disposition to enable clear functional separation, which improves the outcomes besides providing better code isolation, self-contained agents, flexibility to control and handle each task with a dedicated agent and improved operation, which can be controlled at the disposition level.
8. Experimentation Platform:
We harnessed the Databricks Platform and Swiggy in-house experiment platform for rapid prototyping, evaluation and iteration of solutions. Platform features like AI playground (model experimentation), Model serving (out-of-box serving), and MLflow (tracing, prompt registry, out-of-box evaluation and monitoring) and the flexibility to serve any model provided us with the best features and flexibility to focus on achieving POC goals quickly.
Architecture and Deployment: End-to-End Integration for Scalability and Trust
1. System Architecture
The high-level system architecture encompasses all system components and the end-to-end integration of Agent into the user journey. The key guiding principles and objectives we achieved were:
Seamless end-to-end integration of Agent with all systems, giving the user a seamless experience.
Scalable and elastic to handle traffic bursts and slumps with low latency at optimal cost.
Real-time granular tracing to track each step of the Agent to produce real-time operational and functional observability.
Real-time evaluation of the Agent’s output against evaluation criteria, flexibility to sample evaluation to keep cost and operational overhead in check.
Extensible to plug in new intents, responses, tools and flows for Agents.
Provide a framework for new plug-ins and new agents for new use cases.
A graceful fallback to human agents in case of a fallback needs to be identified.
Fall back capability at the component level, including auto LLM fall-backs.
Holistic state management is used to improve outcomes and manage failure recovery.
Component-level flexibility to scale and replace components to suit business and operational needs.
2. Deployment
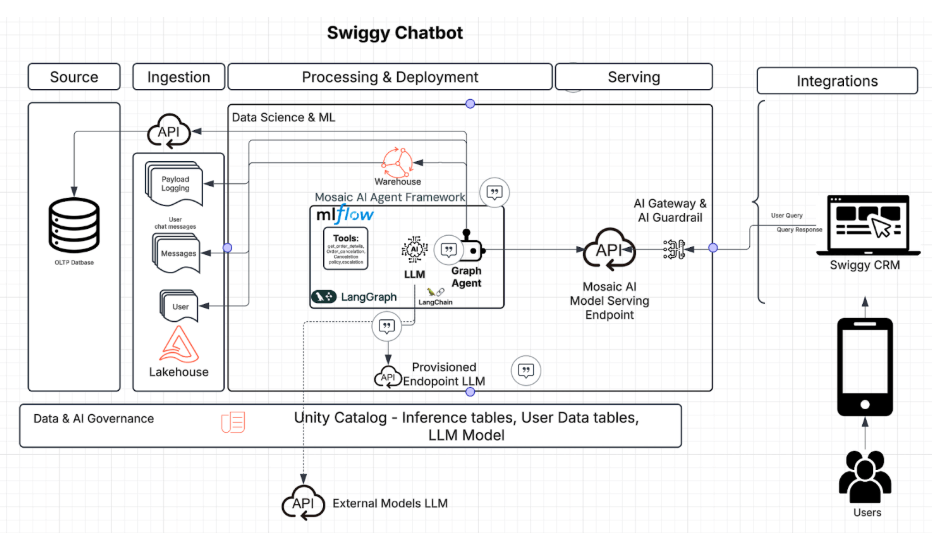
The deployment phase primarily focused on providing the infrastructure, governance, security, monitoring, observability, online evaluation and integration. The key components for Agent deployment are
Agent Bricks AI Gateway: We used Gateway to manage centralized permissions, rate limits for Agent access, payload logging and traffic fallback. This ensured compliance, security, auditing, monitoring compliance and system reliability.
Agent Bricks AI Gateway Guardrails: We ensured secure Agent interactions by providing the Guardrails that block unsafe, non-compliant, or harmful data at model endpoints.
Model Serving: This is the critical component of our deployment, which provides the infrastructure to run our Agent. We leveraged the optimised auto scaling of model serving to enable our Agent to handle highly variable traffic patterns without compromising latency and performance. Besides deep inbuilt integration with data platforms, MLflow 3.0 enabled seamless tool calls and granular real-time tracing capabilities.
MLflow 3.0 Tracing: The tracing capabilities were built on MLflow. We used Agent tracing provided by MLflow 3.0 to capture inputs, outputs, and metadata and track each Agent step in real time, which fueled our monitoring and observability.
MLflow 3.0 Evaluation: To achieve our business objectives, we evaluated Agent outputs on Accuracy, Factual correctness, Stability (consistency and reliability), Cost, Latency, Response Style, and Conversational coherence. The evaluations are built using a combination of MLflow’s built-in judges and custom-built judges using MLflow’s SDKs.
Tracing, monitoring and observability: Real-time observability was enabled from Model Serving using MLflow 3.0. We further customized the tracing feed to add operational metrics to provide deep visibility into the internal workings of Agents in real time. These metrics were fed into Swiggy's centralized monitoring system to enable monitoring teams to monitor Agents and take corrective actions when required.
Unity Catalog: We used Unity Catalog to organize, secure, access, and track all data and AI assets.
CRM integration: We implemented a structured action-trigger integration to enable seamless collaboration between the Agent and the CRM platform. Whenever the Agent makes intelligent decisions, the required corresponding actions will be executed in the CRM backend. These decisions are based on dynamic context and business rules and are communicated to the CRM system as action signals.
3. Agent Monitoring and Observability (Agent Ops)
Our agent is autonomous and complex, so implementing robust monitoring and observability systems is critical for ensuring reliability and performance. Our Agent becomes a "black box," difficult to debug and trust without proper observability. We defined key KPI for operations (like p99 latency < 500ms) and quality (accuracy > 99%), and enabled an alert mechanism when operational KPI or quality KPI do not meet the defined standards. Besides, granular observability from MLflow 3.0 Tracing allows deep visibility into the Agent’s internal working, like tool usage patterns, latency, Model calls, etc., providing real-time insight into the agent’s behaviour.
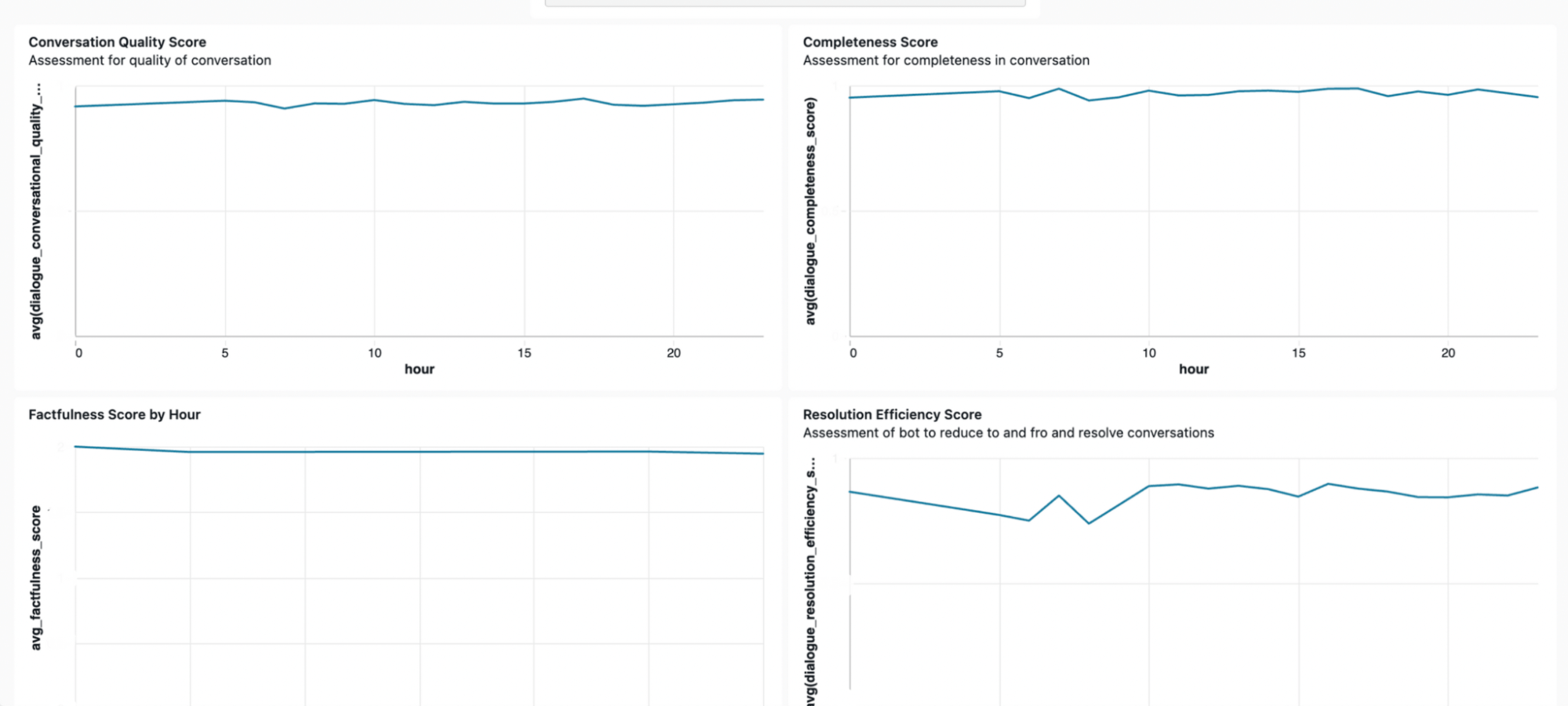
We closely monitor Conversation Quality Score, Completeness Score, Factfulness Score by Hour, and Resolution Efficiency Score to track the effectiveness of our chatbots. These metrics help us ensure that conversations are clear, accurate, and resolved quickly.
Lessons Learned and Best Practices
Implementing the AI agent for customer support brings significant benefits and introduces various technical, operational, and organizational challenges. Below is a structured overview of the most common hurdles, the key lessons learned from our real-world deployment and the best practices we adopted.
Complexity in handling multi-intent conversations: A single Agent handling complex multi-intent discussions does not provide functional segregation, lacks flexibility, creates maintenance overhead and impacts output quality. To overcome these, we implemented a multi-agent architecture where a new agent will handle a distinct task disposition to enable clear functional separation.
Integration with CRM system: Seamless integration between Agent and CRM system is a challenge, especially initiating dynamic actions in the CRM system based on intelligent decisions made by Agents. We implemented and structured action-trigger integration between Agent and CRM, where decisions by Agents are communicated to CRM as action signals that are integrated into CRM.
Over-reliance on short-term memory: We identified inaccurate responses (failed to return up-to-date information) due to the Agent’s over-reliance on short-term memory (incorrect assumption by Agent that it already has data in memory) instead of performing toll calls to get the latest information, leading to outdated information in response. This was resolved using a combination of Signal categorization (static and dynamic), prompting to refresh data and adding deterministic control in the tool call (use at least one tool instead of making the tool call optional)
Agent assignment optimisation: Giving agent assignment decisions entirely to LLM achieved 90% accuracy. However, the goal was 100% accuracy, which is a challenge with LLMs’ probabilistic behaviour. We tackled this issue by combining rule-based routing (intent-based trigger) and decoupling the Agent assignment task from the Agent to a dedicated lightweight LLM with tailored assignment prompts.
Cost optimization: We performed multiple cost optimizations to ensure efficient utilisation and maintain agents’ ROI. Databricks Model serving provided the infrastructure cost optimizations. Besides, we optimised the prompt to reduce LLM inference cost by removing emojis (save token without compromising semantic meaning), reducing few-shot examples and converting them to single-shot examples.
Model optimization: Instead of using a powerful reasoning model for all Agent tasks, we matched LLM capability with task complexity. We built the Agent with multiple LLM options (simple LLM, small reasoning LLM, large reasoning LLM) to provide a simple model for simple tasks, a small reasoning model for moderate tasks and a large reasoning model for complex tasks. This multi-model design helped to optimise cost and reduce latency.
Autoscaling of Model serving: Since the traffic pattern was highly variable and 24*7, the Databricks model serving was tuned to provide an extensive range of dynamic autoscaling (near zero to hundreds of nodes) to serve traffic at optimal cost and minimum latency.
Fine-tuning of model: We fine-tuned an open source model, which improved outcomes. However, we faced the issue of catastrophic forgetting (unlearning previously learned capabilities), which impacted overall performance. Further trade-off of effort required for fine-tuning vs. outcome is not worth it. The better approach is to focus more on other techniques, like prompt engineering.
Results and Strategic Impact
Created a pioneering AI Agent, the first of its kind at this scale, with granular monitoring and observability in the industry.
Scalability: The AI agent system handled thousands of concurrent support sessions, with sub-second latency.
Automation: 100% of customer queries were fully automated without human intervention.
Satisfaction: Customer satisfaction scores (CSAT) improved due to faster, more consistent, and personalized responses, with reduced resolution times.
Cost Savings: Operational costs were reduced by automating low-complexity, high-frequency inquiries, and the system flexibly scaled resources in line with real-time volume.
Best-in-Class Observability: Real-time monitoring, deep traceability, and rigorous evaluation cycles enabled rapid iteration, strong SLAs, and a measurable reduction in agent errors.
Strategic Positioning: Swiggy established a foundation for further AI-driven automation and innovation, positioning customer service teams as business differentiators rather than cost centers.
Conclusion: A Blueprint for Enterprise-Grade AI Agents
Swiggy’s transformation showcases what’s possible when technical leadership, operational excellence, and advanced LLMs converge on a real-world business problem. This blueprint — rooted in rapid experimentation, architectural rigor, and strategic partnership — offers technical and business leaders a roadmap for deploying GenAI agents at scale, unlocking lasting cost, efficiency, and customer experience advantages.
Ready to build hyper-scalable AI Agents? Learn more about AI Agents on Databricks in 5 Minutes.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.