Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs
by Nikhil Sardana, Julian Quevedo and Daya Khudia
Quantization is a technique for making machine learning models smaller and faster. We quantize Llama2-70B-Chat, producing an equivalent-quality model that generates 2.2x more tokens per second.
The larger the language model, the slower (and more expensive) it is to query: the GPU has to load more parameters from memory and perform more computations. Our team has developed and adopted numerous techniques to optimize LLM performance. In this blog post, we’ll discuss quantization, a popular technique that lowers the numerical precision of a model in order to reduce its memory footprint and make it run faster. Applying quantization to LLMs such as Llama2-70B-Chat leads to a model that generates 2.2 times more tokens per second than when running at full 16-bit precision. Critically, to ensure that the model quality is maintained, we rigorously test the quantized model on dozens of benchmarks in our Gauntlet model evaluation suite.
A Brief Primer on Quantization
Modern LLMs are largely trained using 16-bit precision. Once the model is trained, practitioners often quantize model weights to a lower precision, reducing the number of bits required to store the model or run computations, which speeds up inference. We can quantize one or more of the components of the model:
- Model parameters (i.e. the weights).
- Key-value (KV) cache. This is the state associated with the attention keys and values, which are saved to reduce repetitive computations as we generate output tokens sequentially.
- Activations. These are the outputs of each layer of the model, which are used as inputs to the next layer. When we quantize the activations, we are performing the actual computation (like matrix multiplications) with a lower precision.
Quantization produces a smaller and faster model. Reducing the size of the model allows us to use less GPU memory and/or increase the maximum batch size. A smaller model also reduces the bandwidth required to move weights from memory. This is especially important at low batch sizes, when we are bandwidth-bound—in low batch settings, there are a small number of operations per byte of the model loaded, so we are bottlenecked by the size of the model weights. In addition, if we quantize the activations, we can take advantage of hardware support for fast low-precision operations: NVIDIA A100 and H100 Tensor Core GPUs can perform 8-bit integer (INT8) math 2x faster than 16-bit floating point math. The H100 Tensor Core GPU features the Transformer Engine, which supports 8-bit floating point (FP8) operations at the same speed as 8-bit integer operations. To read more about challenges in LLM inference, please refer to our previous blog on this topic.
In this work, we discuss two different quantization setups:
- INT8 weights + KV cache quantization. In this setup, our model weights and KV cache are reduced, but our activations remain in 16 bits.
- FP8. Our weights, KV cache, and activations are all reduced to 8-bit floating point values. Eight-bit floating point operations are only supported by NVIDIA H100 Tensor Core GPUs, and not by NVIDIA A100 Tensor Core GPUs.
Integer vs. Floating Point Quantization
What’s the difference between INT8 and FP8?
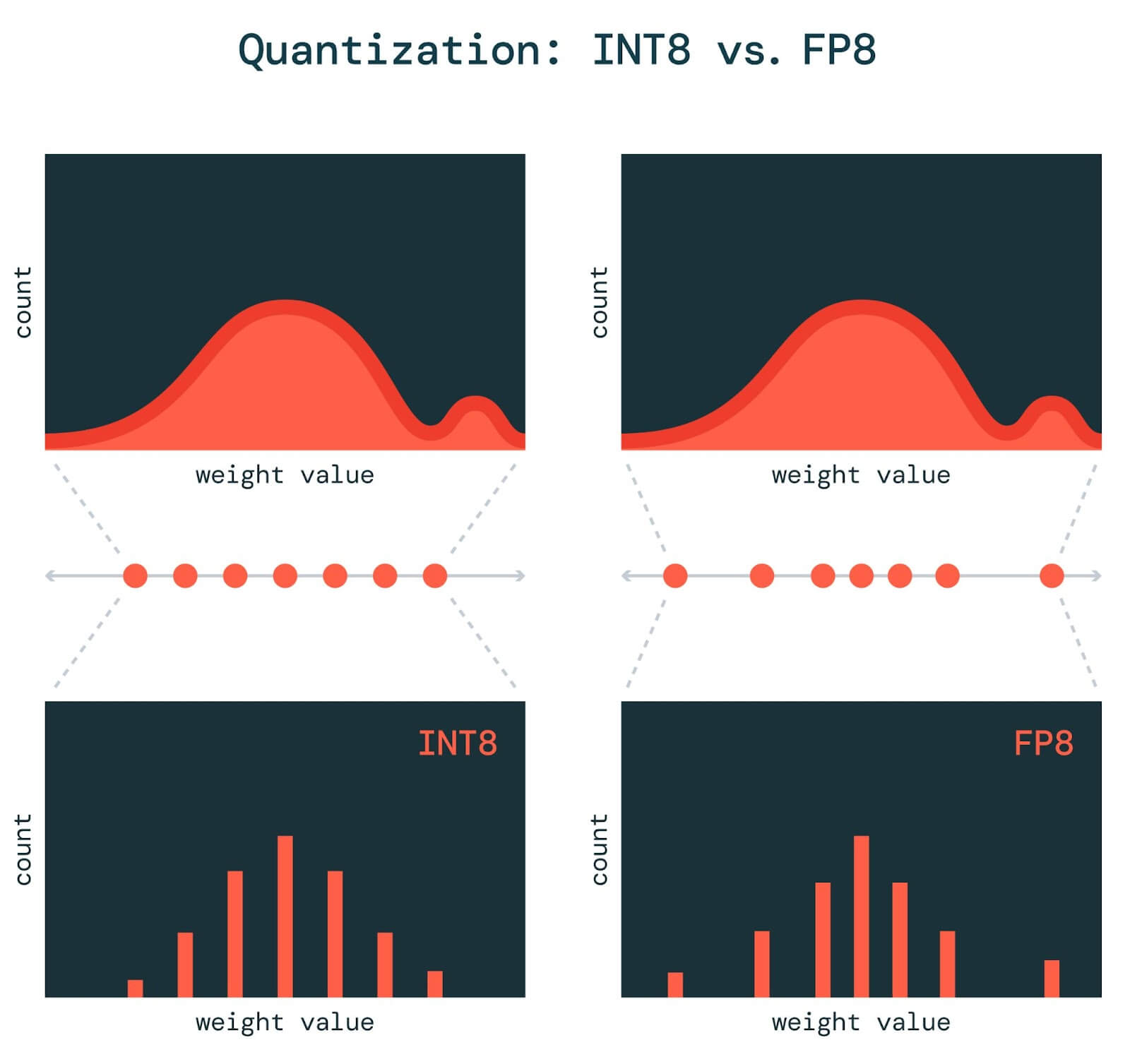
In INT8 quantization, we multiply our model’s parameters by a scaling factor, shift them up or down so they are centered around zero, and then round these values to one of the 256 integers representable by the INT8 format. This rounding induces errors, so the less we have to round our parameters, the better the quantized model’s quality. But the distribution of integers is uniform, so INT8 quantization works best when our model parameters and activations are also uniformly distributed.
Unfortunately, our weights and activations are rarely uniformly distributed. They usually look more like a bell curve, so FP8 quantization may work better. Floating point number formats can represent a non-uniform distribution; because we use some bits for the mantissa and some for the exponent, we can set our exponent to be negative when we want to represent numbers close to zero with high precision.
Recent research has shown that outlier weights and activations—numbers far away from typical values—are especially important for model quality. Because FP8 has an exponent component, it can represent very large numbers with less error than INT8. Therefore, quantization to FP8 tends to produce more accurate models than INT8.
Activations tend to contain more outliers than weights. So, to preserve model quality with INT8, we only quantize our weights and KV cache to INT8, leaving our activations in FP16 for now. Other techniques, such as SmoothQuant, get around the issues of outliers with INT8 quantization.
Quantizing Llama2-70B-Chat
Llama2-70B-Chat is currently one of the largest and highest quality models offered through our Foundation Model API. Unfortunately, that also means that it’s slower and offers more limited concurrency than smaller models. Let’s see if quantization can help!
We use the NVIDIA TensorRT-LLM library to quantize and serve our optimized Llama2-70B-Chat model. We find that we can quantize Llama2-70B-Chat and achieve:
(a) A 50% smaller model, lowering GPU memory requirements and allowing us to fit a 2x larger batch size on the same hardware.
(b) Up to 30% faster output token generation.
(c) The same quality, on average, as the original Llama2-70B-Chat model.
In sum, using FP8 quantization, we can increase our overall model throughput by 2.2x!
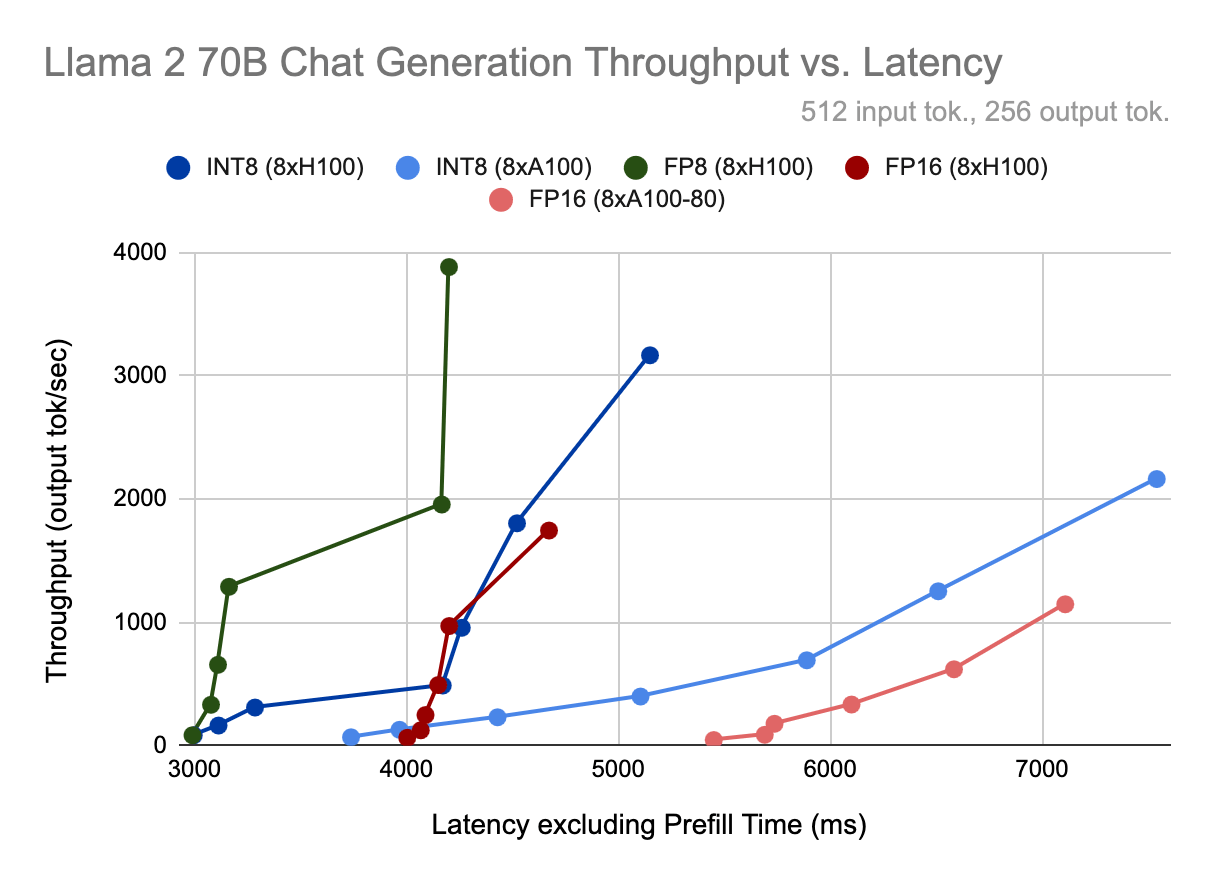
Speed
Quantization’s greatest benefit is that it unlocks higher concurrency, because it allows us to double the maximum batch size that can fit on the same hardware while maintaining the same latency budget. At batch size 64 on the H100 using FP8, we can generate 2.2x more tokens per second compared to batch size 32 using FP16, thanks to a 10% reduction in time per output token per user (TPOT).
Even if increasing concurrency is not an option, quantization provides some benefits. TPOT and throughput are ~30% better for quantized models at batch sizes < 8. Above that point, INT8 weight-only quantization provides little to no speedup because our computation remains in FP16. However, since the H100 uses the Transformer Engine to perform faster FP8 computation, even at high batch sizes it maintains a 10% TPOT improvement versus FP16.
What about processing the prompt? During prefill, we process the entire context at once, so we are typically compute bound. Faster FP8 operations on the H100 provide a 30% time-to-first-token (TTFT) improvement over FP16. However, INT8 weight-only quantization is actually slower than no quantization here because our computation remains in FP16, and we have the additional overhead of converting between data types.
Lastly, we compare GPU types. We see that TPOT is 25-30% better for the H100 vs. the A100 at the same batch size and precision (i.e., both running INT8 or FP16). If we compare the fastest H100 mode, FP8, to the fastest A100 mode, INT8 (weights and KV cache), this gap increases to 80% at large batch sizes. However, since the H100 has 67% more bandwidth and 3x more compute than the A100, this difference might increase in the future, as software and kernels for the H100 become more optimized. As of right now, it appears the H100 has more performance headroom than the A100. Our results show that model bandwidth utilization, a measure of how efficiently data moves from memory to the compute elements, ranges from 2% - 7% higher on the A100 vs. the H100 during output token generation.



Quality
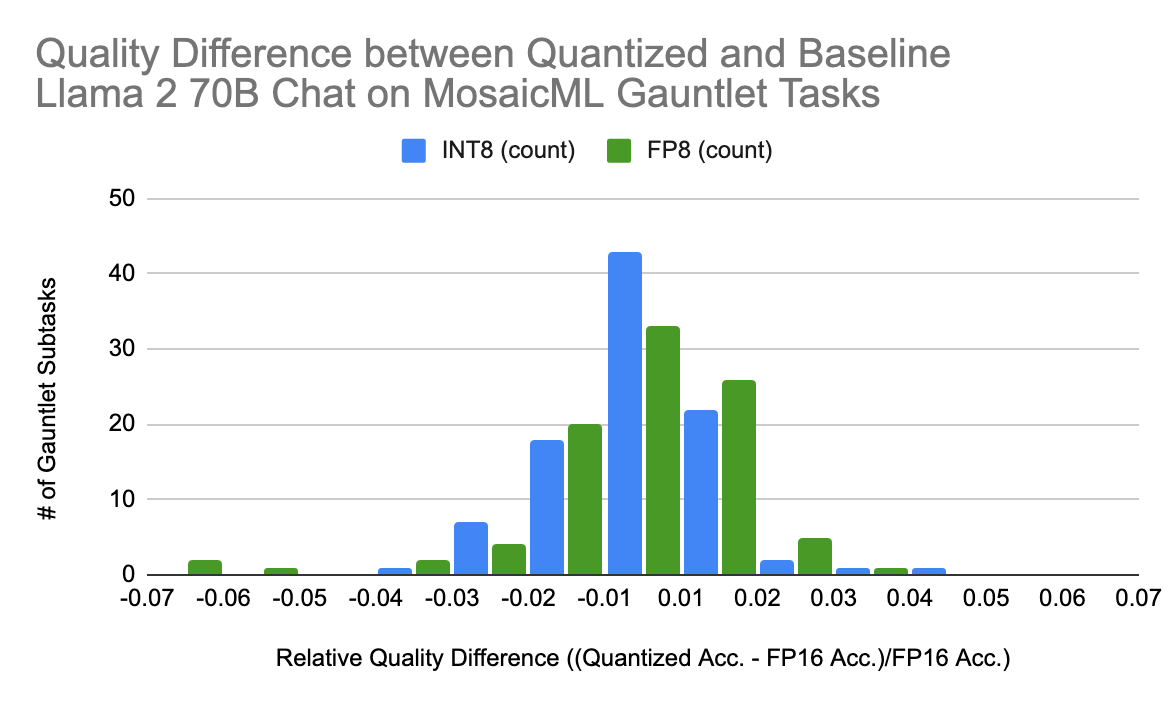
Quantizing models can affect model quality. We’ve developed our MosaicML Gauntlet Evaluation suite to test the quality of our models on a wide array of different tasks. Our suite includes dozens of industry-standard benchmarks, including MMLU, BigBench, Arc, and HellaSwag. These benchmarks comprise many different classes of problems, including world knowledge, commonsense reasoning, language understanding, symbolic problem solving, and reading comprehension.
We perform a thorough evaluation on our quantized Llama2-70B-Chat models using the Gauntlet and find no significant accuracy difference between either quantization mode and our baseline model. In Figure 3, we show the quality difference between each quantization type and the baseline Llama2-70B-Chat on the Gauntlet subtasks. On average, there is no quality difference between the quantized and baseline models, and the quantized models are within +/- 2% of the baseline performance for the vast majority of tasks.
Conclusion
Quantization is a powerful technique that can significantly improve model speed and throughput. At low batch sizes, both INT8-weight-only and FP8 offer similar benefits. However, for high throughput use-cases, FP8 quantization on NVIDIA’s H100s provides the most benefits.
Our engineering team is always careful to maintain model quality when we introduce a speedup, and quantization is no different. Our Gauntlet evaluation suite shows that on average, Llama2-70B-Chat maintains its original quality after either FP8 or INT8 quantization.
We'll soon be serving quantized Llama2-70B-Chat through our Foundation Model APIs, with all the performance benefits described above. You can quickly get started querying the model and pay per token, and in case you require concurrency guarantees for your production workload, you can deploy Foundation Model APIs with Provisioned Throughput. Learn more here.
We’re constantly working to make the models we serve faster while maintaining quality results. Stay tuned for more optimizations!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.