StreamNative and Databricks Unite to Power Real-Time Data Processing with Pulsar-Spark Connector
by Tristen Wentling, Neng Lu, Chaoqin Li and Matteo Merli

StreamNative, a leading Apache Pulsar-based real-time data platform solutions provider, and Databricks, the Data Intelligence Platform, are thrilled to announce the enhanced Pulsar-Spark Connector.
In an era where real-time data processing is becoming increasingly vital for businesses, this collaboration combines the strengths of two powerful open source technologies: Apache Pulsar™ and Apache Spark™.
Apache Pulsar™
Apache Pulsar™ is an open source, distributed messaging and event streaming platform that offers high durability, scalability, and low latency messaging. It's designed to handle real-time data streaming and can be used for various applications, from simple pub/sub messaging to complex event-driven microservices architectures.
Some key features of Apache Pulsar include:
- Multi-Protocol support: Pulsar comes with built-in support for standard messaging protocols such as Pulsar's own binary protocol, MQTT, and Apache Kafka protocol. These built-in protocol handlers facilitate interoperability with a wide range of client libraries and messaging systems, making it easier for developers to integrate Pulsar into their existing infrastructure.
- Data Retention and Tiered Storage: Pulsar provides flexible data retention and tiered storage options, allowing you to optimize storage costs.
- Multi-tenancy: It supports multi-tenancy, making it suitable for use in cloud environments and shared infrastructures.
- Geo-replication: Pulsar allows data to be replicated across multiple geographic regions, providing disaster recovery and low-latency access to data.
Apache Spark™
Apache Spark™ is an open source, distributed computing system that's designed for big data processing and analytics. With over a billion annual downloads, Spark is known for its speed and ease of use, providing a unified analytics engine for all large-scale data processing tasks.
Key features of Apache Spark include:
- In-Memory Processing: Spark performs in-memory data processing, significantly accelerating data analysis compared to traditional disk-based processing systems.
- Ease of Use: It offers high-level APIs in Java, Scala, Python, and SQL, making it accessible to many data professionals.
- Support for Real-Time Data: Apache Spark's Structured Streaming enables real-time data processing, allowing businesses to analyze data as it arrives.
Integrating Apache Pulsar™ and Apache Spark™
Businesses are still looking for more than batch processing and static reports. They demand real-time insights and instant responses to data as it flows into their systems. Apache Pulsar and Apache Spark™ have played pivotal roles in this transformation, but there has been a growing need to unify the power of these two technologies.
The Pulsar-Spark Connector: Addressing Real-Time Data Challenges
Seamless Integration
The motivation to develop the Pulsar-Spark Connector stems from the need to seamlessly integrate the high-speed, low-latency data ingestion capabilities of Apache Pulsar with the advanced data processing and analytics capabilities of Apache Spark. This integration empowers organizations to construct end-to-end data pipelines, ensuring data flows smoothly from ingestion to analysis, all in real-time.
Scalability and Reliability
Real-time data processing requires scalability and reliability. Apache Pulsar's innate capabilities in this regard, combined with the distributed computing power of Apache Spark, deliver an unmatched solution that addresses these crucial challenges.
Unified Analytics
Businesses need a unified analytics platform to analyze and make decisions on real-time data. The Pulsar-Spark Connector paves the way for this by offering a seamless solution to combine the best of Apache Pulsar and Apache Spark, resulting in rapid insights and data-driven decision-making.
Open Source Collaboration
Furthermore, releasing the Pulsar-Spark Connector as an open-source project reflects our commitment to transparency, collaboration, and creating a thriving community of users and contributors.
In summary, the motivation behind developing the Pulsar-Spark Connector is to provide organizations with a unified, high-performance solution that seamlessly integrates the speed and scalability of Apache Pulsar with the data processing capabilities of Databricks' Spark platform. This empowers businesses to meet the growing demands for real-time data processing and analytics.
Common use cases
Real-Time Data Processing and Analytics: Apache Pulsar's pub-sub messaging system enables the ingestion of massive streams of data from diverse sources in real-time. Spark Structured Streaming provides the capability to process these data streams with low latency, enabling real-time analytics, monitoring, and alerting. Together, Pulsar and Spark can form the backbone of real-time data processing pipelines, allowing organizations to gain insights and take immediate actions on streaming data.
Continuous ETL (Extract, Transform, Load): In modern data architectures, the need for continuous ETL processes is paramount. Apache Pulsar facilitates the ingestion of data from various sources, while Apache Spark provides powerful transformation capabilities through its batch and streaming processing engines. Organizations can leverage Pulsar to ingest data streams and utilize Spark to perform real-time transformations, enrichments, and aggregations on the data before loading it into downstream systems or data stores.
Complex Event Processing (CEP): Complex Event Processing involves identifying patterns and correlations in streams of events or data in real-time. Apache Pulsar's ability to handle high-throughput event streams and Spark's rich set of stream processing APIs make them an excellent combination for implementing CEP applications. Organizations can use Pulsar to ingest event streams and Spark to analyze and detect complex patterns, anomalies, and trends in real-time, enabling proactive decision-making and rapid responses to critical events.
Machine Learning on Streaming Data: As organizations increasingly adopt machine learning techniques for real-time decision-making, the integration of Apache Pulsar and Apache Spark becomes instrumental. Pulsar enables the ingestion of continuous streams of data generated by sensors, IoT devices, or application logs, while Spark's MLlib library provides scalable machine learning algorithms that can operate on streaming data. Organizations can leverage this combination to build and deploy real-time machine learning models for tasks such as anomaly detection, predictive maintenance, and personalization.
Real-Time Monitoring and Alerting: Monitoring and alerting systems require the ability to process and analyze large volumes of streaming data in real-time. Apache Pulsar can serve as a reliable messaging backbone for collecting and distributing event streams from various monitoring sources, while Apache Spark can be used to analyze incoming streams, detect anomalies, and trigger alerts based on predefined thresholds or patterns. This joint solution enables organizations to monitor their systems, applications, and infrastructure in real-time, ensuring timely detection and response to potential issues or failures.
Key Highlights of the Pulsar-Spark Connector:
- Ultra-Fast Data Ingestion: The Pulsar-Spark Connector enables lightning-fast data ingestion from Apache Pulsar into Databricks' Apache Spark clusters, allowing organizations to process real-time data at unprecedented speeds.
- End-to-end Data Pipelines: Seamlessly construct end-to-end data pipelines encompassing the entire data lifecycle, from ingestion to processing, analysis, and visualization.
- High Scalability and Reliability: Benefit from the inherent scalability and reliability of Apache Pulsar combined with the advanced data processing capabilities of Databricks' Spark platform.
- Native Integration: The Pulsar-Spark Connector is designed for seamless integration, making it easier for data engineers and scientists to work together, leveraging the best of both platforms.
- Unified Analytics: Analyze real-time data streams with Databricks' unified analytics platform, allowing for rapid insights and data-driven decision-making.
- Open Source: The Pulsar-Spark Connector will be released as an open-source project, ensuring transparency, collaboration, and a thriving community of users and contributors.
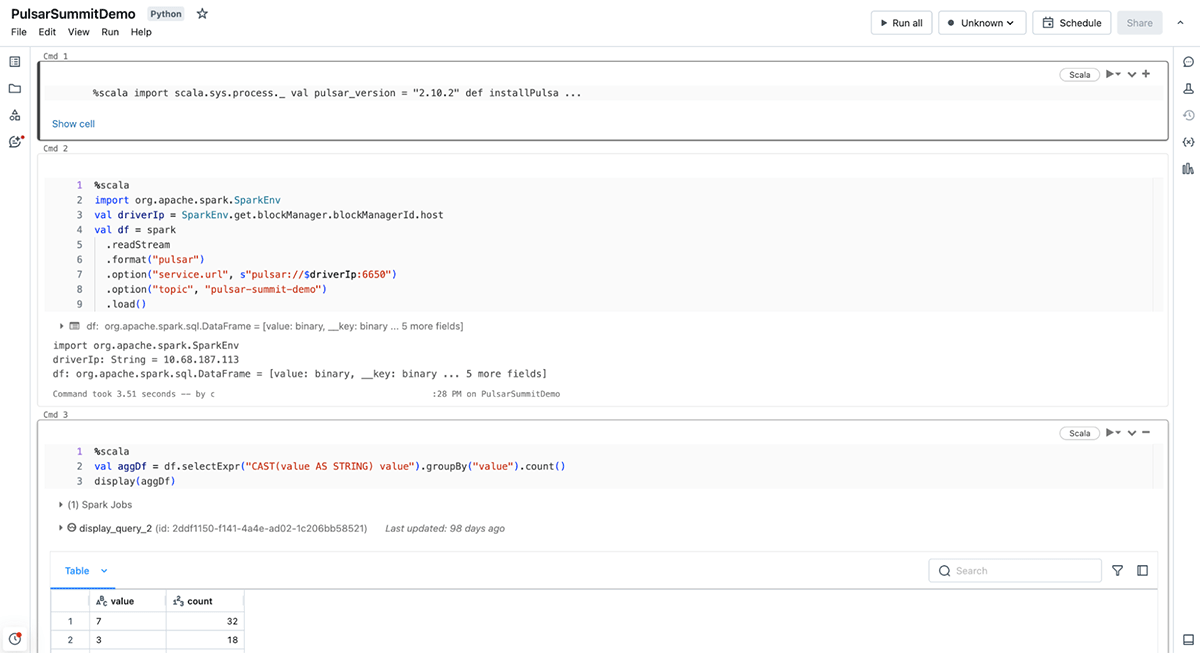
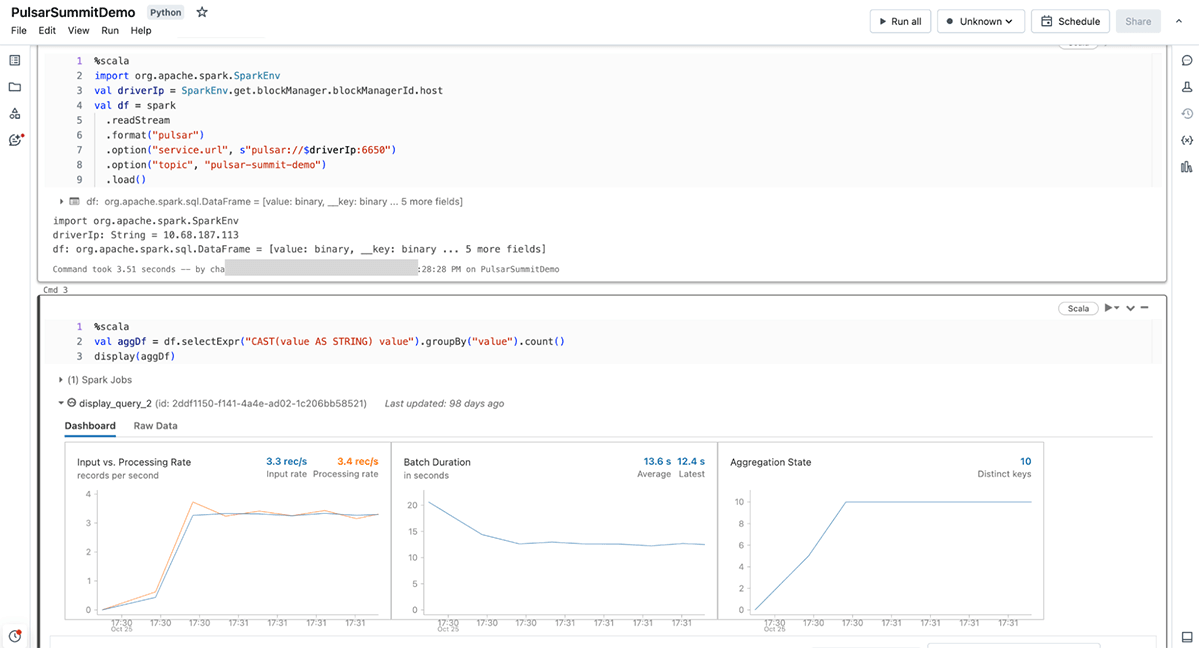
Diving a Little Deeper
The Pulsar-Spark connector implements the StreamSource and StreamSink and the relational APIs for supporting streaming and batch processing. The PulsarSource enables the Spark engine to
- Seamlessly integrate with Pulsar topic schemas
- Continuously generate micro-batches for executors to process the data
- Correctly manage the topic offsets during the processing
- Rate-limit the consumption of data among topics
- Checkpoint and rollback to the last successful commit during error recovery
Similarly, the PulsarSink enables the Spark engine to
- Validate the result row schema types
- Utilize Pulsar producers to flush processed data back into Pulsar topics
- Gracefully handle the error during data flush failure
The schema of a Pulsar topic is converted to the corresponding Spark SQL types. It supports the conventional scalar types and nested schema conversion. Furthermore, it also includes the metadata fields of a message such as topic name, message key, messageID, etc thus providing additional information while processing.
The Pulsar-Spark connector uses persistent Pulsar topic subscription. This subscription remembers the offset of the last successfully acknowledged message, so that when the connector asks for the next set of messages, it knows where to start from. This is used to generate the micro-batches. After successful processing of the micro-batch, the consumed messages are acknowledged and the offsets are persisted on Pulsar.
The rate-limit management is achieved by implementing admission control in the Pulsar source. It will actively look into the Pulsar ledger and entry metadata to calculate the approximate position of message ID. This enables users to control the rate of data processing and resource consumption of streaming queries that use the Pulsar source.
The Pulsar-Spark connector ensures that it does not use any Pulsar admin API, thus avoiding the need for admin privileges for Spark jobs. Instead, it uses only consumer or client public APIs to discover the topic partitions and consume data.
Also Available in the Databricks Runtime
The Databricks Data Intelligence Platform is the best place to run Apache Spark workloads. It's built on lakehouse architecture to provide an open, unified foundation for all data and governance, and is powered by a Data Intelligence engine that understands the uniqueness of your data while providing high-performance computation and queries for all kinds of data users. This means that getting data from Pulsar into analytics or machine learning processes can be both simple and efficient.
On top of the above benefits highlighted for the connector, Databricks has added some additional components to improve the quality of life for developers who use Pulsar on the Databricks platform. Starting with their support in DBR 14.1 (and Delta Live Tables preview channel), the Databricks engineering team has added two key additional areas that make using Pulsar simpler and easier, added support in SQL and an easier way to manage credentials files.
- Extended Language Support: Databricks extended the language support beyond the already supported Scala/Java and Python APIs to include a
read_pulsarSQL connector. Using each of the different flavors offers similar options and aligns with Spark's Structured Streaming methods but the SQL syntax is unique to the Databricks platform and the syntax itself differs to align with theSTREAMobject. - Credentials Management Options: For password authentication Databricks recommends using Secrets to help prevent credentials leaks. For TLS authentication you can use any of the following location types depending on your environment setup.
- External Location
.option("tlsTrustStorePath", "s3://<credential_path>/truststore.jks")
- DBFS
.option("tlsTrustStorePath", "dbfs:/<credential_path>/truststore.jks")
- Unity Catalog Volume
.option("tlsTrustStorePath", "/Volumes/<catalog>/<schema>/<volume>/truststore.jks")
In Databricks environments using Unity Catalog, it is important to allow Pulsar consumers access to the credentials file to avoid permissions errors when reading the stream.
- External locations
GRANT READ FILES ON EXTERNAL LOCATION s3://<credential_path> TO <user>
- Unity Catalog Volumes
GRANT READ VOLUME ON VOLUME <catalog.schema.credentials> TO <user>
Syntax Examples
Here we have an example of the syntax for each of the supported APIs. Note that both the Scala and Python APIs are used directly as a readStream input and the SQL API uses the STREAM object.
Scala
Python
SQL
To see further available configuration options please refer to the Databricks documentation. For usage with open source Apache Spark see the StreamNative documentation.
Summary
In a world driven by real-time data, the collaboration between StreamNative and Databricks to develop the Pulsar-Spark Connector represents a significant leap forward. This groundbreaking connector addresses the key challenges of real-time data processing, enabling organizations to construct end-to-end data pipelines, benefit from scalability and reliability, and make data-driven decisions at unparalleled speeds.
As we embark on this journey, we are committed to continuous improvement, innovation, and meeting our users' evolving needs. We also invite you to join us in contributing to this exciting endeavor, and we look forward to the positive impact the Pulsar-Spark Connector will have on your real-time data processing and analytics endeavors.
Thank you for your support, and we're excited to shape the future of real-time data processing with you.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.