US Air Force Hackathon: How Large Language Models Will Revolutionize USAF Flight Test
by Jordan Conner, Luis Moros, Riley Livermore, Danny Riley, Troy Soileau, Ben Faircloth, Tim Lortz and Li Yu

[DISTRIBUTION STATEMENT A. Approved for public release; Distribution is unlimited 412TW-PA-24004] The views expressed are those of the author and do not reflect the official policy or position of the US Air Force, Department of Defense, or the US Government.
What is the US Air Force (USAF) Hackathon?
The Air Force Test Center (AFTC) Data Hackathon is a consortium of test experts across the AFTC that meet for a week-long event to tackle some of the Air Force's novel problems utilizing new technologies. This 5th Hackathon focused on Large Language Models (LLMs) and included 44 participants, congregated at 3 AFTC base locations, as well as remote participants. LLMs, like OpenAI's ChatGPT, have rapidly gained prominence in the tech landscape, making the idea of utilizing a digital assistant for initializing code or drafting written content increasingly mainstream. Despite these advantages, the Air Force's near-term use of commercial models is constrained, due to the potential for exposing sensitive information outside of the domain.
There is an appetite to deploy functioning LLMs within the Air Force boundary, but limited methods exist to do so. The Air Force Data Fabric's secure VAULT environment, which the AFTC Data Hackathon has used for every event, utilizes the Databricks technology stack for large scale data science computing efforts. The Hackathon leveraged a test document repository that contains over 180,000 unclassified documents to serve as a test corpus for the development of the desired LLM. The Hackathon community has been primed on using the Databricks technology, and the large data sets available to train with suggests the goal is technically feasible.
What is a Large Language Model (LLM)?
A Large Language Model is essentially a massive digital brain full of billions of neuron-like units that have been trained on an enormous amount of text. It learns patterns, language, information, and can generate human-like text based on the data it's fed, along with coding and performing advanced data analysis in a matter of seconds.
The Hackathon's Mission
While publicly hosted LLM services like ChatGPT already exist, the Hackathon centered on configuring and comparing several open source LLMs hosted in a secured platform. A retrieval augmented generation (RAG) approach was employed, harnessing the power of thousands of USAF flight test documents to produce contextually pertinent answers and generate documents akin to flight test and safety plans. It's crucial to understand that a flight test plan or report is not just a mere document; it encapsulates intricate details, test parameters, safety procedures, and anticipated outcomes, all methodically laid out following a specific formula. These documents are typically crafted over weeks, if not longer, necessitating the time and expertise of multiple flight test engineers. The meticulous nature of their creation, combined with the formulaic approach, suggests that an LLM could be an invaluable tool in expediting and streamlining this extensive process.
The Role of Databricks
The USAF Hackathon's success was significantly bolstered by its collaboration with Databricks. Their Lakehouse platform, tailored for the U.S. Public Sector, brought advanced AI/ML capabilities and end-to-end model management to the forefront. Furthermore, Databricks' commitment to promoting state-of-the-art open-source LLMs underscores their dedication to the broader data science community. Their recent acquisition of MosaicML, a leading platform for creating and customizing generative AI models, exemplifies a pledge to democratize generative AI capabilities for enterprises, seamlessly integrating data and AI for superior application across the sector.
The Process
- Repository Creation: First, the team collated tens of thousands of past flight test documents and uploaded them to a secure server for the LLM to access and reference. The documents were stored in a vector database to facilitate the retrieval and referencing of those closely related to the corresponding tasks given to LLMs.
- Pretrained Models: Training LLMs from scratch takes a large number of resources and computing power, which was not feasible for this Hackathon, given time and computing constraints. Instead, the team leveraged a variety of relatively small existing open-source models, such as MPT-7b, MPT-30b, Falcon-7b, and Falcon-40b as foundations and then used them to search and reference the secure repository of documents.
- Testing: Using this document library, the team was able to get the LLM to understand, reference, and generate USAF-specific content. This allowed the LLM to tailor its responses to generate test documents indistinguishable from human-made alternatives, as shown in the example below.
- Issues: During the Hackathon, the team encountered numerous challenges when leveraging the LLMs within a secure environment. Faced with constraints in both time and computational resources, the pre-existing LLMs employed were computationally intensive, stressing the 16 high-performance compute clusters used, resulting in slower response times than desired. Despite these challenges, the experience offered vital insights into the complexities of utilizing existing LLMs in specialized, secure settings, setting the stage for future advancements.
This diagram illustrates the process used of converting raw documents into actionable insights using embeddings. It begins with the extraction, transformation, and loading (ETL) of raw documents into a Delta Table. These documents are then cleaned, chunked, and their embeddings are loaded into a Vector Database (DB), specifically ChromaDB. Upon querying (e.g., 'How to grow blueberries?'), a similarity
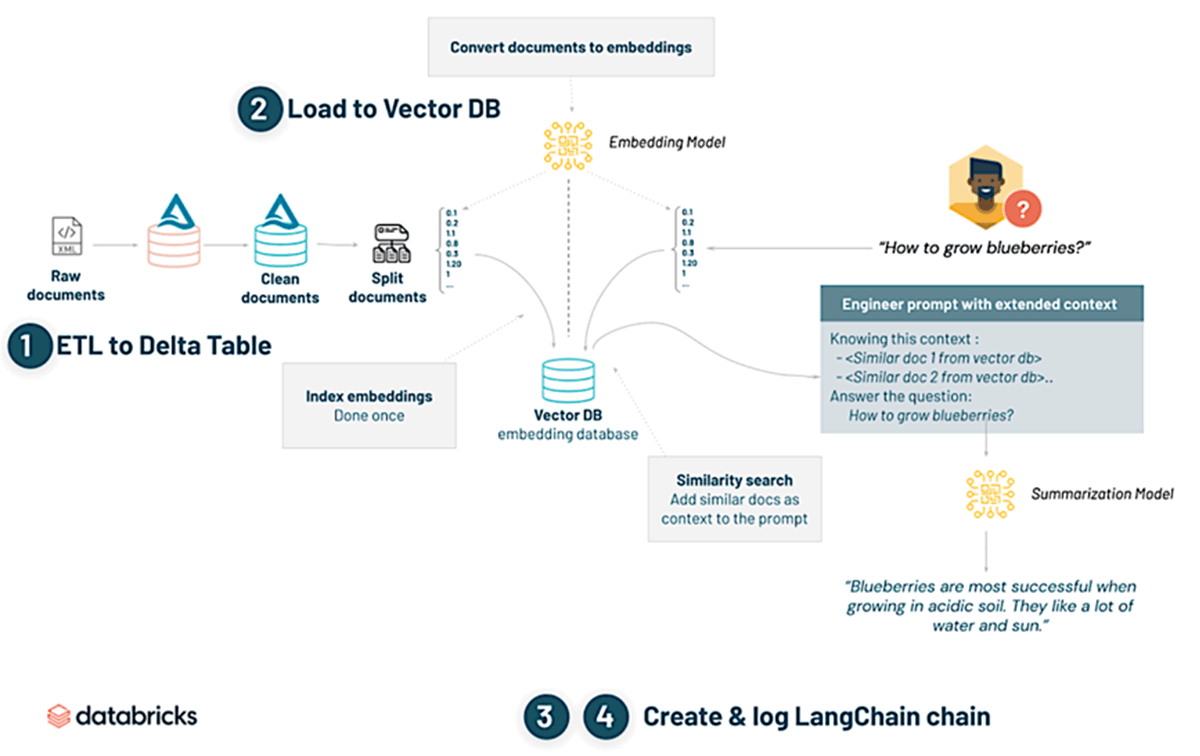
search is performed in the Vector DB to find related documents. These findings are used to engineer a prompt with an extended context. Finally, a summarization model distills this information, providing a concise answer based on the aggregated context and citing the documents from which the information was referenced. This search and summarization capability was just one of the ways in which the LLM could be used. Additionally, the tool could also be queried regarding any topic, without any context from the reference documents.
Why It's Significant
- Efficiency: A well-trained LLM can process and generate content rapidly. This could drastically reduce the time spent on searching reference documents, drafting reports, writing code, or analyzing data from flight test events.
- Cost Savings: Time is money. If time is saved by automating some tasks using LLMs, the USAF can drastically reduce costs. Given the magnitude of USAF operations, the financial implications are massive.
- Error Reduction: Human error, while inevitable, can have significant repercussions in the world of flight test. When properly overseen and their responses reviewed, LLMs can ensure consistency and accuracy in the tasks they've been trained for.
- Accessibility: With an LLM, a large swath of information becomes instantly accessible. Queries that would previously take hours to answer by manually combing through databases can be addressed in a matter of minutes.
The Future
While the USAF Hackathon project occurred on a relatively small scale, it showcased the potential that LLMs provide and the amount of time and resources that they save. If the USAF were to implement LLMs into its workflow, flight testing could be utterly transformed, serving as a force multiplier, and saving millions of dollars in the process.
In Conclusion
The use of LLMs for the Air Force operational mission might seem distant, but the USAF Hackathon demonstrated its potential for use in specialized fields like flight test. While the event highlighted the many advantages of integrating LLMs into DoD workflow, it also underscored the necessity for further investment. To truly harness the full capabilities of this technology and make our skies safer and operations more efficient, sustained support and funding will be imperative. The Hackathon was just a glimpse into the future; to make it a reality, collaborative effort and continued work towards implementation are essential.
Hear more about the work Databricks is doing with the US Department of Defense at our in-person Government Forum on February 29 in Northern VA or our Virtual Government Forum on March 21, 2024
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.