Using Structured Streaming with Delta Sharing in Unity Catalog
by Will Girten, Josh Seidel, Lin Zhou and Sachin Thakur
We are excited to announce that support for using Structured Streaming with Delta Sharing is now generally available (GA) in Azure, AWS, and GCP! This new feature will allow data recipients on the Databricks Lakehouse Platform to stream changes from a Delta Table shared through the Unity Catalog.
Data providers can leverage this capability to scale their data-as-a-service easily, reduce the operational cost of sharing large data sets, improve data quality with immediate data validation and quality checks as new data arrives, and improve customer service with real-time data delivery. Similarly, data recipients can stream the latest changes from a shared dataset, reducing the infrastructure cost of processing large batch data and setting the foundation for cutting-edge, real-time data applications. Data recipients across many industry verticals can benefit from this new feature, for example:
- Retail: Data analysts can stream the latest sales figures for a seasonal fashion line and present business insights in the form of a BI report.
- Health Life Sciences: Health practitioners can stream electrocardiogram readings into an ML model to identify abnormalities.
- Manufacturing: Building management teams can stream smart thermostat readings and identify what time of day or night heating and cooling units should efficiently turn on or off.
Oftentimes, data teams rely upon data pipelines executed in a batch fashion to process their data due to the fact that batch execution is both robust and easy to implement. However, today, organizations need the latest arriving data to make real-time business decisions. Structured streaming not only simplifies real-time processing but also simplifies batch processing by reducing the number of batch jobs to just a few streaming jobs. Converting batch data pipelines to streaming is trivial as Structured Streaming supports the same DataFrame API.
In this blog article, we'll explore how enterprises can leverage Structured Streaming with Delta Sharing to maximize the business value of their data in near real-time using an example in the financial industry. We'll also examine how other complementary features, like Databricks Workflows, can be used in conjunction with Delta Sharing and Unity Catalog to build a real-time data application.
Support for Structured Streaming
Perhaps the most highly anticipated Delta Sharing feature over the past few months has been added support for using a shared Delta Table as a source in Structured Streaming. This new feature will allow data recipients to build real-time applications using Delta Tables shared through Unity Catalog on the Databricks Lakehouse Platform.
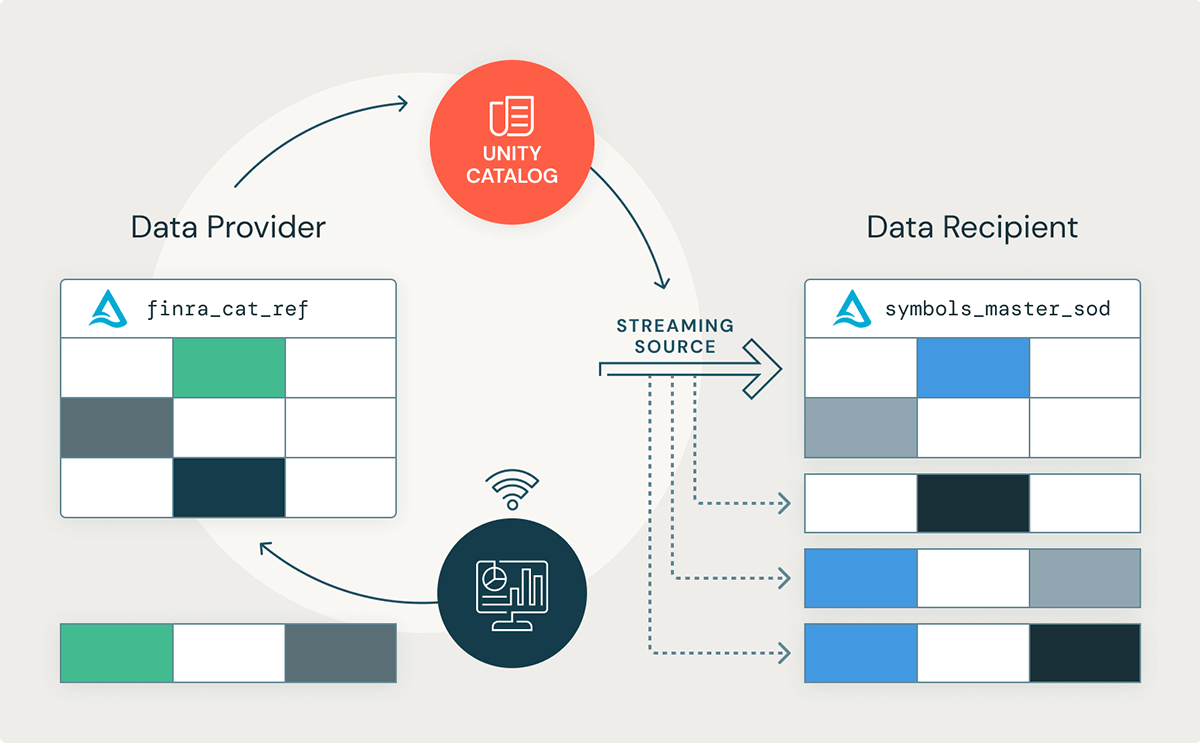
How to Use Delta Sharing with Structured Streaming
Let's take a closer look at how a data recipient might stream publicly traded stock symbol information for real-time trading insights. This article will use the FINRA CAT Reportable Equity Securities Symbol Master dataset, which lists all stocks and equity securities traded across the U.S. National Market System (NMS). Structured Streaming can be used to build real-time applications, but it can also be useful in scenarios where data arrives less frequently. For a simple notebook demonstration, we'll use a dataset that is updated three times throughout the day - once at the start of the transaction date (SOD), a second time during the day to reflect any intraday changes, and a third time at the end of the transaction date (EOD). There are no updates published on weekends or on U.S. holidays.
| Published File | Schedule |
|---|---|
| CAT Reportable Equity Securities Symbol Master – SOD | 6:00 a.m. EST |
| CAT Reportable Options Securities Symbol Master – SOD | 6:00 a.m. EST |
| Member ID (IMID) List | 6:00 a.m. EST |
| Member ID (IMID) Conflicts List | 6:00 a.m. EST |
| CAT Reportable Equity Securities Symbol Master – Intraday | 10:30 a.m. EST, and approximately every 2 hours until EOD file is published |
| CAT Reportable Options Securities Symbol Master – Intraday | 10:30 a.m. EST, and approximately every 2 hours until EOD file is published |
| CAT Reportable Equity Securities Symbol Master – EOD | 8 p.m. EST |
| CAT Reportable Options Securities Symbol Master – EOD | 8 p.m. EST |
Table 1.1 - The FINRA CAT symbol and member reference data is published throughout the business day. There are no updates published on weekends or on U.S. holidays.
From Data Provider's Perspective: Ingesting the CAT Data using Databricks Workflows
One of the major benefits of the Databricks Lakehouse Platform is that it makes continuously streaming changes into a Delta Table extremely easy. We'll first start by defining a simple Python task that downloads the FINRA CAT equity securities symbol file at the start of the transaction date (SOD). Afterward, we'll save the published file to a temporary directory on the Databricks filesystem.
Code 1.1. - A simple Python task can download the FINRA CAT equity symbol file at the start of the trading day.
To demonstrate, we'll also define a function that will ingest the raw file and continuously update a bronze table in our Delta Lake each time an updated file is published.
Code. 1.2 - The FINRA CAT equity symbol data is ingested into a Delta Table at the start of each trading day.
Once it is started, the Databricks Workflow will begin populating the CAT equity symbols dataset each time the file is published at the start of the trading day.
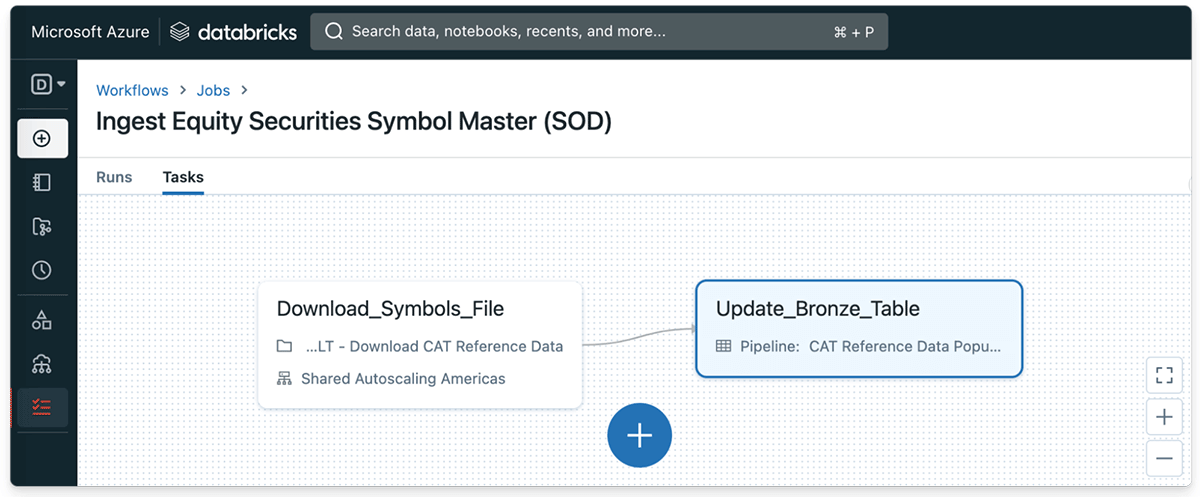
From Data Provider's Perspective: Sharing a Delta Table as a Streaming Source
Now that we've created a streaming pipeline to ingest updates to the symbol file each trading day, we can leverage Delta Sharing to share the Delta Table with data recipients. Creating a Delta Share on the Databricks Lakehouse Platform can be done with just a few clicks of the button or with a single SQL statement if SQL syntax is preferred.
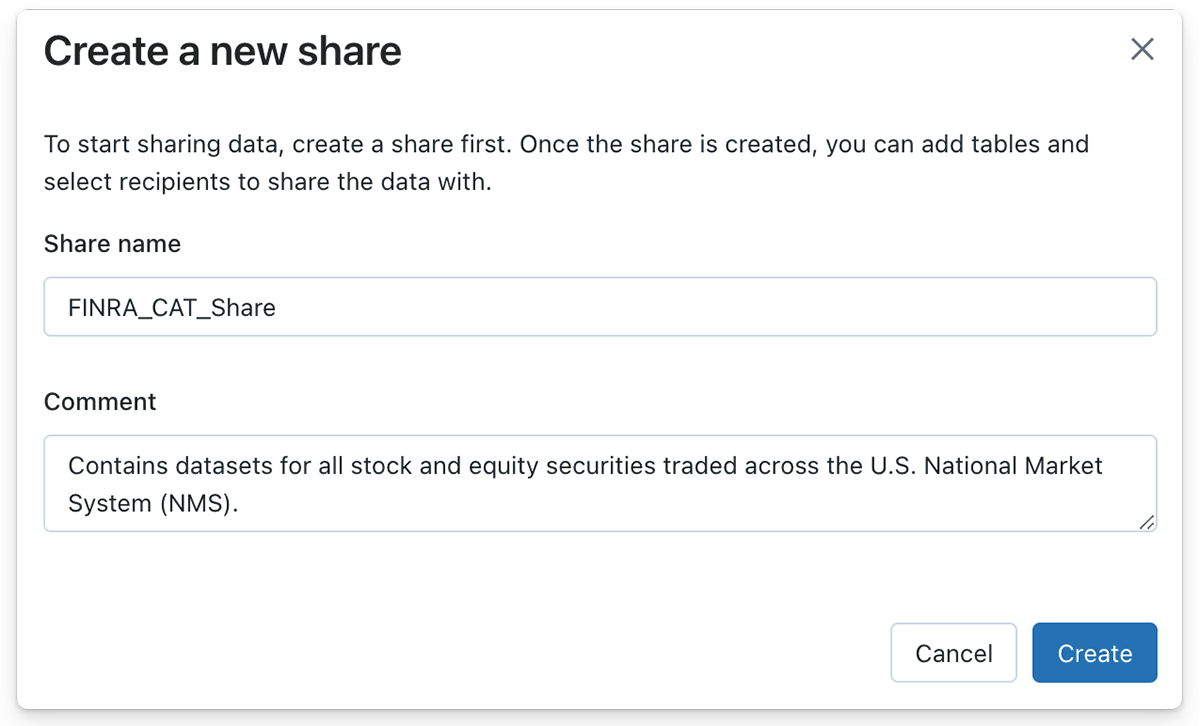
Similarly, a data provider can populate a Delta Share with one or more tables by clicking the 'Manage assets' button, followed by the 'Edit tables' button. In this case, the bronze Delta Table containing the equity symbol data is added to the Share object.
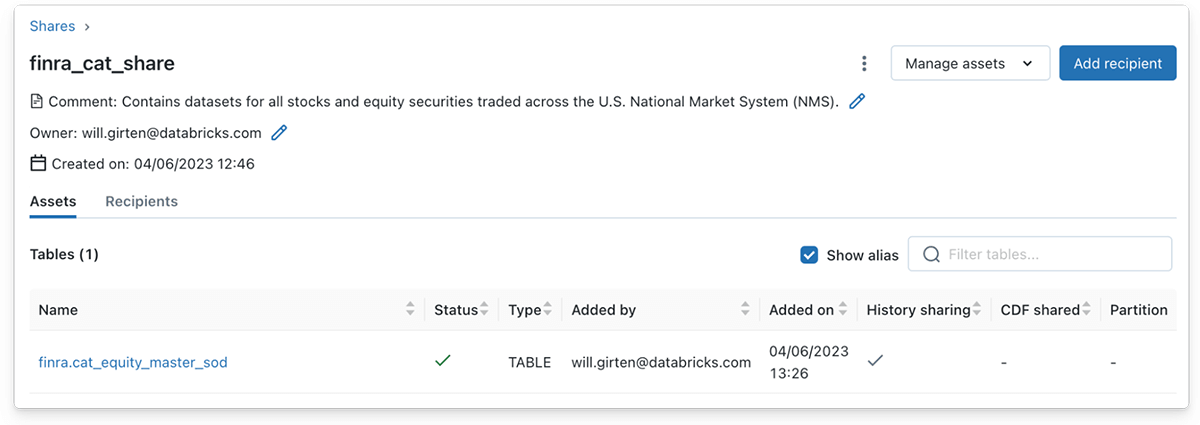
Note that the full history of a Delta table must be shared to support reads using Structured Streaming. History sharing is enabled by default using the Databricks UI to add a Delta table to a Share. However, history sharing must be explicitly specified when using the SQL syntax.
Code 1.4 - The history of a Delta table must be explicitly shared to support Structured Streaming reads when using the SQL syntax.
From Data Recipient's Perspective: Streaming a Shared Delta Table
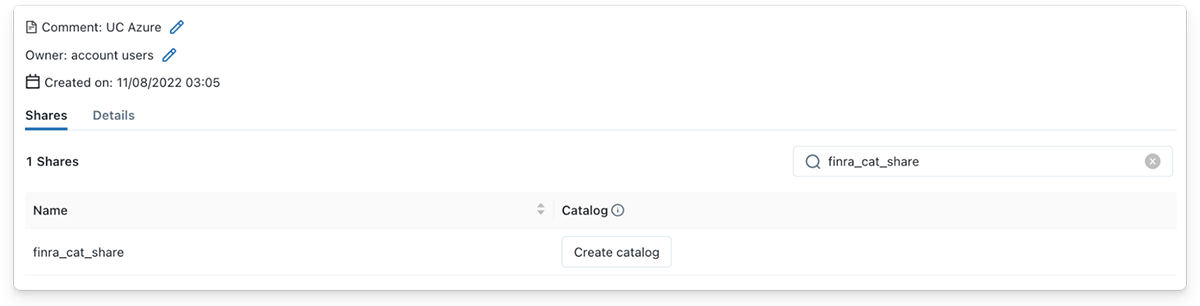
As a data recipient, streaming from a shared Delta table is just as simple! After the Delta Share has been shared with a data recipient, the recipient will immediately see the Share appear under the provider details in Unity Catalog. Subsequently, the data recipient can create a new catalog in Unity Catalog by clicking the 'Create catalog' button, providing a meaningful name, and adding an optional comment to describe the Share contents.
Data recipients can stream from a Delta Table shared through Unity Catalog using Databricks Runtime 12.1 or greater. In this example, we've used a Databricks cluster with Databricks 12.2 LTS Runtime installed. A data recipient can read the shared Delta table as a Spark Structured Stream using the deltaSharing data source and supplying the name of the shared table.
Code 1.4 - A data recipient can stream from a shared Delta Table using the deltaSharing data source.
As a further example, let's combine the shared CAT equity symbols master dataset with a stock price history dataset, local to the data recipient's Unity Catalog. We'll begin by defining a utility function for getting the weekly stock price histories of a given stock ticker symbol.
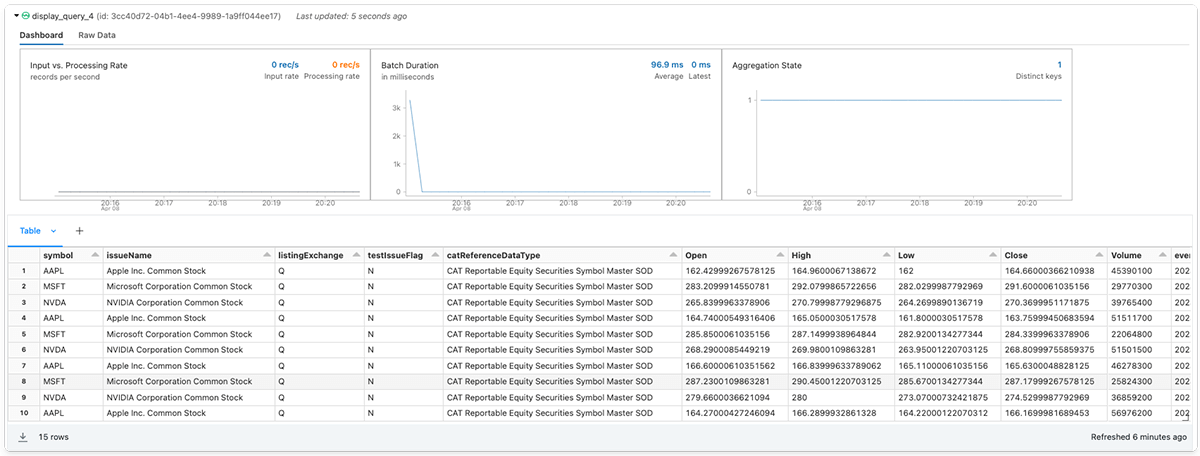
Next, we'll join together the equity stock master data stream with the local stock price histories of 3 large tech stocks - Apple Inc. (AAPL), the Microsoft Corporation (MSFT), and the Invidia Corporation (NVDA).
Finally, the data recipient can add an optional destination sink and start the streaming query.
Getting Started with Delta Sharing on Databricks
I hope you enjoyed this example of how organizations can leverage Delta Sharing to maximize the business value of their data in near real-time.
Want to get started with Delta Sharing but don't know where to start? If you already are a Databricks customer, follow the guide to get started using Delta Sharing (AWS | Azure | GCP). Read the documentation to learn more about the configuration options included in with feature. If you are not an existing Databricks customer, sign up for a free trial with a Premium or Enterprise workspace.
Credits
We'd like to extend special thanks for all of the contributions to this release, including Abhijit Chakankar, Lin Zhou, and Shixiong Zhu.
Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.