Block is a global technology company that champions accessible financial services and prioritizes economic empowerment. Its subsidiaries, including Square, Cash App and TIDAL, are committed to expanding economic access. By utilizing artificial intelligence (AI) and machine learning (ML), Block proactively identifies and prevents fraud, ensuring secure customer transactions in real time. In addition, Block enhances user experiences by delivering personalized recommendations and using identity resolution to gain a comprehensive understanding of customer activities across its diverse services. Internally, Block optimizes operations through automation and predictive analytics, driving efficiency in financial service delivery. Block uses the Databricks Lakehouse Platform to bolster its capabilities, consolidating and streamlining its data, AI and analytics workloads. This strategic move positions Block for the forthcoming automation-driven innovation shift and solidifies its position as a pioneer in AI-driven financial services.
Enabling change data capture for streaming data events on Delta Lake
Block’s Data Foundations team is dedicated to helping its internal customers aggregate, orchestrate and publish data at scale across the company’s distributed system to support business use cases such as fraud detection, payment risk evaluation and real-time loan decisions. The team needs access to high-quality, low-latency data to enable fast, data-driven decisions and reactions.
Block had been consolidating on Kafka for data ingestion and Delta Lake for data storage. More recently, the company sought to make real-time streaming data available in Delta Lake as Silver (cleansed and conformed) data for analytics and machine learning. It also wanted to support event updates and simple data transformations and enable data quality checks to ensure higher-quality data. To accomplish this, Block considered a few alternatives, including the Confluent-managed Databricks Delta Lake Sink connector, a fully managed solution with low latency. However, that solution did not offer change data capture support and had limited transformation and data quality check support. The team also considered building their own solution with Spark Structured Streaming, which also provided low latency and strong data transformation capabilities. But that solution required the team to maintain significant code to define task workflows, change data and capture logic. They’d also have to implement their own data quality checks and maintenance jobs.
Leveraging the Lakehouse to sync Kafka streams to Delta Tables in real time
Rather than redeveloping its data pipelines and applications on new, complex, proprietary and disjointed technology stacks, Block turned to the Databricks Lakehouse Platform and Spark Declarative Pipelines for change data capture and to enable the development of end-to-end, scalable streaming pipelines and applications. Spark Declarative Pipelines pipelines simply orchestrate the way data flows between Delta tables for ETL jobs, requiring only a few lines of declarative code. It automates much of the operational complexity associated with running ETL pipelines and, as such, comes with preselected smart defaults, yet is also tunable, enabling the team to optimize and debug easily. “Spark Declarative Pipelines offers declarative syntax to define a pipeline, and we believed it could greatly improve our development velocity,” says Yue Zhang, Staff Software Engineer for the Data Foundations team at Block. “It’s also a managed solution, so it manages the maintenance tasks for us, it has data quality support, and it has advanced, efficient autoscaling and Unity Catalog integration.”
Today, Block’s Data Foundations team ingests events from internal services in Kafka topics. A Spark Declarative Pipelines pipeline consumes those events into a Bronze (raw data) table in real time, and they use the Spark Declarative Pipelines API to apply changes and merge data into a higher-quality Silver table. The Silver table can then be used by other Spark Declarative Pipelines pipelines for model training, to schedule model orchestration, or to define features for a features store. “It’s very straightforward to implement and build Spark Declarative Pipelines pipelines,” says Zhang.
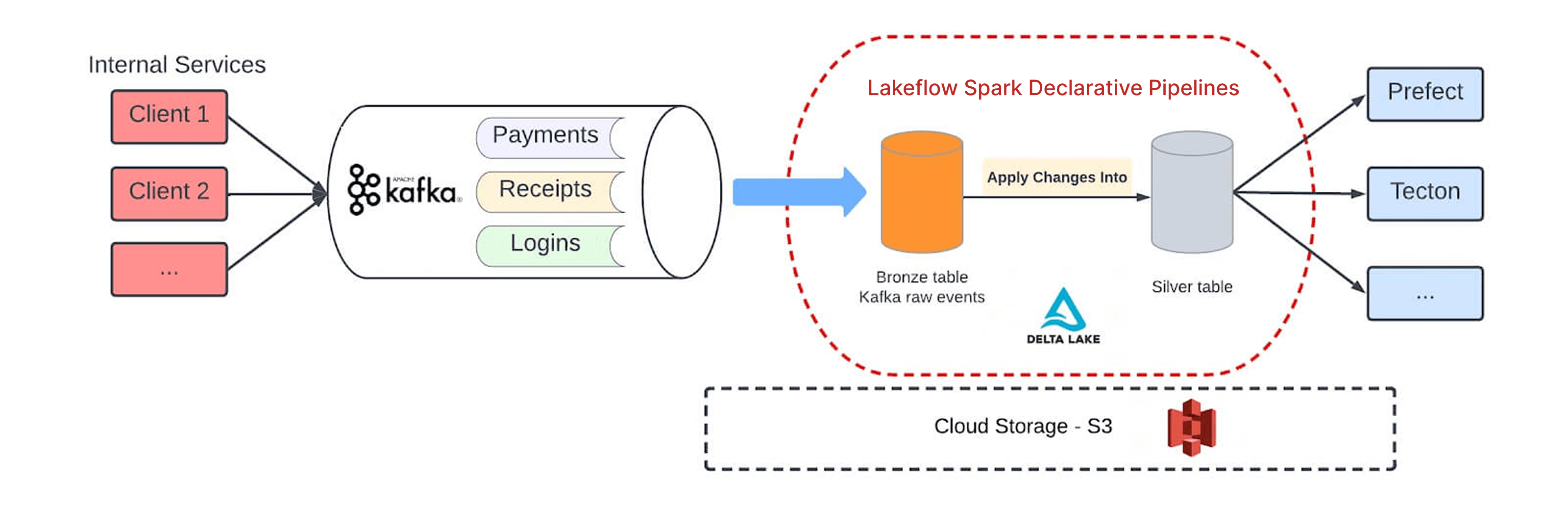
Using the Python API to define a pipeline requires three steps: a row table, a Silver table and a merge process. The first step is to define the row table. Block consumes events from Kafka, performs some simple transformations, and establishes the data quality check and its rule. The goal is to ensure all events have a valid event ID.
The next step is to define the Silver table or target table, its storage location and how it is partitioned. With those tables defined, the team then determines the merge logic. Using the Spark Declarative Pipelines API, they simply select APPLY CHANGES INTO. If two units have the same event ID, Spark Declarative Pipelines will choose the one with the latest ingest timestamp. “That’s all the code you need to write,” says Zhang.
Finally, the team defines basic configuration settings from the Spark Declarative Pipelines UI, such as characterizing clusters and whether the pipeline will run in continuous or triggered modes.
Following their initial Spark Declarative Pipelines proof of concept, Zhang and his team implemented CI/CD to make Spark Declarative Pipelines pipelines more accessible to internal Block teams. Different teams can now manage pipeline implementations and settings in their own repos, and, once they merge, simply use the Databricks pipelines API to create, update and delete those pipelines in the CI/CD process.
Boosting development velocity with Spark Declarative Pipelines
Implementing Spark Declarative Pipelines has been a game changer for Block, enabling it to boost development velocity. “With the adoption of Spark Declarative Pipelines, the time required to define and develop a streaming pipeline has gone from days to hours,” says Zhang.
Meanwhile, managed maintenance tasks have resulted in better query performance, improved data quality has boosted customer trust, and more efficient autoscaling has improved cost efficiency. Access to fresh data means Block data analysts get more timely signals for analytics and decision-making, while Unity Catalog integration means they can better streamline and automate data governance processes. “Before we had support for Unity Catalog, we had to use a separate process and pipeline to stream data into S3 storage and a different process to create a data table out of it,” says Zhang. “With Unity Catalog integration, we can streamline, create and manage tables from the Spark Declarative Pipelines pipeline directly.”
Block is currently running approximately 10 Spark Declarative Pipelines pipelines daily, with about two terabytes of data flowing through them, and has another 150 pipelines to onboard. “Going forward, we’re excited to see the bigger impacts Spark Declarative Pipelines can offer us,” adds Zhang.