

Scribd is using data analytics and AI to provide engaging storytelling experiences that connect authors to their audiences. Using Delta Lake as its unified storage solution, Scribd is able to handle vast amounts of data streamed into its platform and, leveraging Delta Lake’s openness, has implemented a flexible data platform that uses a wide set of technologies. Additionally, the company has made some significant contributions to the Delta Lake open source project. With an open, unified data storage layer, Scribd benefits from the best that the Databricks Data Intelligence Platform has to offer and keeps the ability to mix and match other open source technologies in a heterogeneous environment. This flexibility allows Scribd to innovate faster and deliver more value to customers.
Scribd is on a mission to build the largest and most accessible digital library connecting storytellers with their audiences. The San Francisco-based company launched in 2007 with the world’s first open publishing platform and then evolved in 2013 to introduce a monthly subscription service, providing readers with access to books for one flat fee. Since then, Scribd has added audiobooks, sheet music, magazines, podcasts and presentations to its collection. With millions of titles in its online library, Scribd is focused on leveraging data and analytics to uncover interesting ways to get people excited about reading and learning.
“Data is core to what makes Scribd successful,” says R. Tyler Croy, Director of Platform Engineering at Scribd. “Having the right data platform is important to build out, scale and mature our recommendation engines and search models — so that our users can find content that’s compelling and interesting.”
Choosing Delta Lake for all data storage
A few years ago, Scribd migrated to the cloud to overcome challenges related to performance and maintenance at scale that it was experiencing with its on-prem Hadoop-based infrastructure. However, its migration to cloud storage introduced new challenges around data consistency.
“The primary challenge I was concerned about was the eventually consistent model of AWS S3,” says Croy. “We have many data sets with multiple writers and readers in the nightly batch. The eventually consistent nature of S3 means we might miss data in the nightly batch process because of scheduling.”
This led Scribd to consider Delta Lake as its storage format of choice. “The transactional model of Delta Lake is very compelling in that we don’t have to worry about the underlying storage layer and how it handles consistency,” says Croy. In addition to data consistency, Scribd has realized several other advantages of adopting Delta Lake, such as overcoming the challenges of dealing with too many small files, a common data lake issue that can hinder manageability and performance. “The small files problem is not something I even think about anymore,” says Croy.
Other features, like “time travel,” are also handy when managing a data platform. Time travel allows data engineers to return to earlier versions of Delta tables if needed. “The transactional nature of Delta Lake gives us these superpowers,” says Croy. “You can allow growth and data restructuring in interesting ways without affecting end users.” For example, Scribd recently used Delta Lake to rewrite Delta tables in production without any downtime.
Delta Lake also provided new benefits to streaming. Scribd uses Delta tables both as data sinks and data sources. “The fact that Delta Lake is built for streaming from the ground up empowers our internal users to query live data. As soon as the data comes in, it’s appended to the tables,” says Croy. Because data is streamed directly into Delta tables, there is no need to wait for an ETL pipeline to finish for new data to be made available.
“Today, our storage layer is Delta Lake,” Croy explains. “All the data we’re working with sits in Delta Lake.”
Shaping the future of an open source project
Delta Lake is an open source project and is part of the Linux Foundation. The fact that Delta Lake is built on an open standard was important to Croy to avoid vendor lock-in and maintain control of Scribd’s data. “Data is inherent to our business’s success; it’s the ‘crown jewels,’” he says. The company built a lot of its infrastructure on open source technology. It uses Apache SparkTM, HashiCorp Terraform, Jenkins, Redis and Apache Kafka, to name a few.
Scribd ingests a lot of data through Kafka and wanted a simple, cost-efficient way to write ingested data directly into Delta tables. The fact that Delta Lake is an open standard allowed Croy and his team to create kafka-delta-ingest, a highly efficient daemon for streaming data through Kafka into Delta Lake. Croy and his team then contributed the connector to the open source project, a common practice at Scribd. “On GitHub, you’ll see a lot of open source work coming out of our platform engineering team, like Terraform modules and more. There’s no sense in keeping it proprietary,” says Croy.
The Kafka connector is now available to any Delta Lake user, and it’s not the only thing Scribd has contributed to the project. As part of writing that connector, the team created the Delta Lake native Rust API, which allows developers to create even more integrations and connectors to Delta Lake. Thanks to this kind of work from Scribd and other contributors, there is now a broad and ever-expanding collection of integrations to Delta Lake.
“Our engineering team can pick the right technology to solve our data problems because our data is in Delta Lake rather than being forced to another vendor’s suite of tools,” Croy explains. “To me, the key selling point with Delta Lake is that nothing will stop me from using it with any other data tool because I can just go write the code to integrate with that tool if I need to.”
Scribd is one of several companies contributing to Delta Lake. Through the project’s open source community, Scribd collaborated with other companies on various parts of the project, including collaborations with Rust and Python.
Today, Scribd is an active part of the community helping shape Delta Lake’s future, working with Databricks and other companies on the project’s direction and road map.
Leveraging the Databricks Data Intelligence Platform with Delta Lake
As part of its initial move to the cloud and selecting Delta Lake, Scribd also began using Databricks. With streaming data coming in via Kafka and written into Delta tables — and Delta Lake sitting at the base of the Databricks Data Intelligence Platform — Scribd can easily use Databricks for Apache Spark workloads. “We run anything that uses Spark on Databricks,” Croy explains, “Databricks is really good at the computing side, meaning processing and analyzing lots of data. In addition, our engineering team uses Databricks Notebooks to accomplish a myriad of tasks.”
With Databricks Notebooks, different people in the company can perform ad hoc data explorations and collaborate. A lot of the performance Croy speaks of is achieved through the use of Databricks’ high-performance query engine, Photon, which improves on the performance gains already provided by Delta Lake.
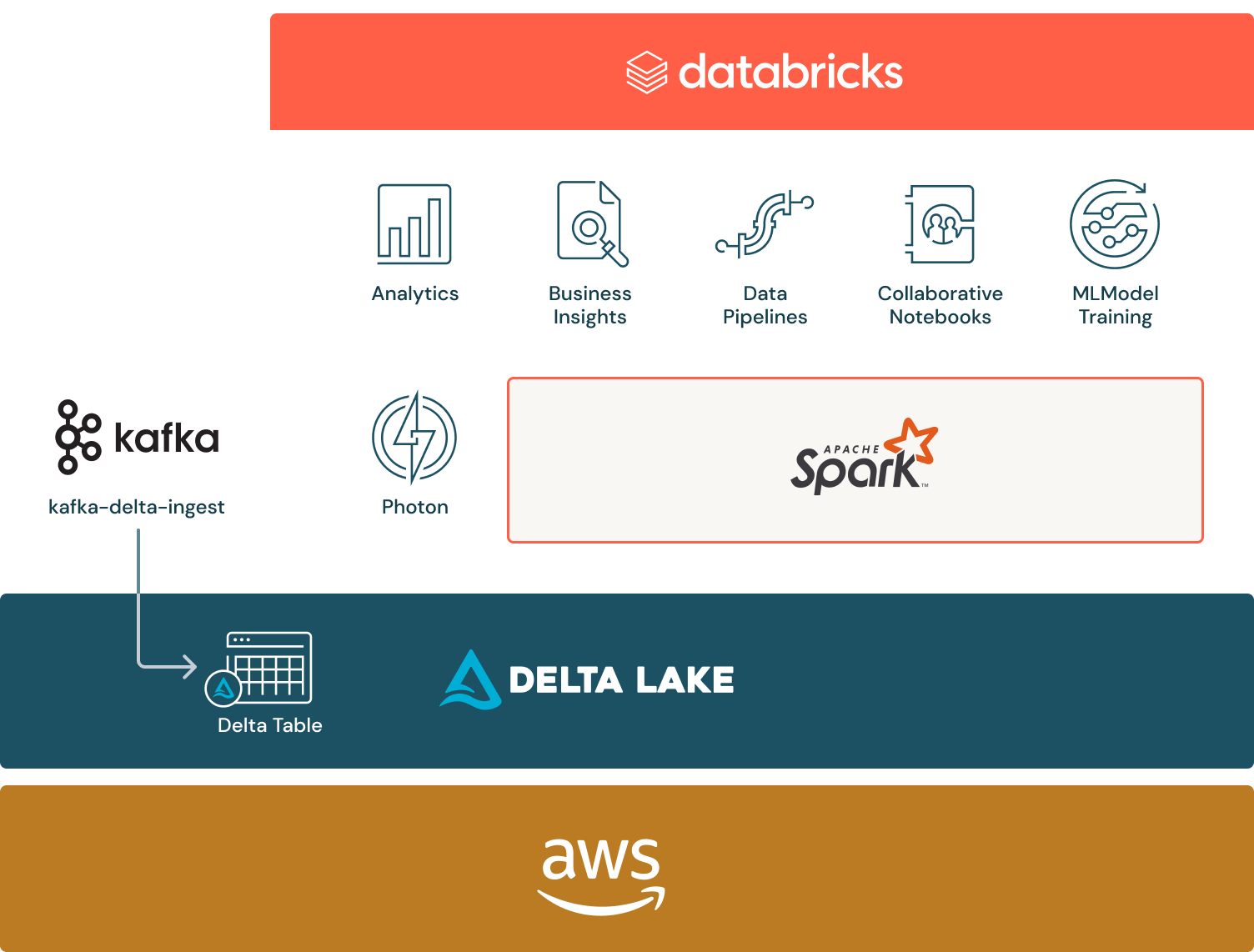
The Spark workloads Scribd runs in Databricks include model training for machine learning models, which use PySpark. However, model serving — meaning providing an endpoint to use the model via HTTP requests — happens outside the Databricks platform. “It is definitely a heterogeneous environment, and Delta Lake is at the center of everything,” says Croy.
Because data is stored using Delta tables, and Delta Lake is an open standard, Scribd has the flexibility to use any technology that meets its needs. That means it keeps ingestion cheap and performant using Kafka and the Kafka-Delta ingest connector it created. It then uses Databricks for high-performing Spark processing (with the help of Photon), and integrates additional tools where it makes sense.
On the Databricks Data Intelligence Platform, Scribd is also beginning to adopt the Databricks Unity Catalog and leverage serverless Databricks Data Intelligence Platform services.