Recap of Databricks Machine Learning announcements from Data & AI Summit

Databricks Machine Learning on the lakehouse provides end-to-end machine learning capabilities from data ingestion and training to deployment and monitoring, all in one unified experience, creating a consistent view across the ML lifecycle and enabling stronger team collaboration. At the Data and AI Summit this week, we announced capabilities that further accelerate ML lifecycle and production ML with Databricks. Here’s a quick recap of the major announcements.
MLflow 2.0 Including MLflow Pipelines
MLflow 2.0 is coming soon and will include a new component, Pipelines. MLflow Pipelines provides a structured framework that enables teams to automate the handoff from exploration to production so that ML engineers no longer have to juggle manual code rewrites and refactoring. MLflow Pipeline templates scaffold pre-defined graphs with user-customizable steps and natively integrate with the rest of MLflow’s model lifecycle management tools. Pipelines also provide helper functions, or “step cards”, to standardize model evaluation and data profiling across projects. You can try out a Beta version of MLflow Pipelines today with MLflow 1.27.0.
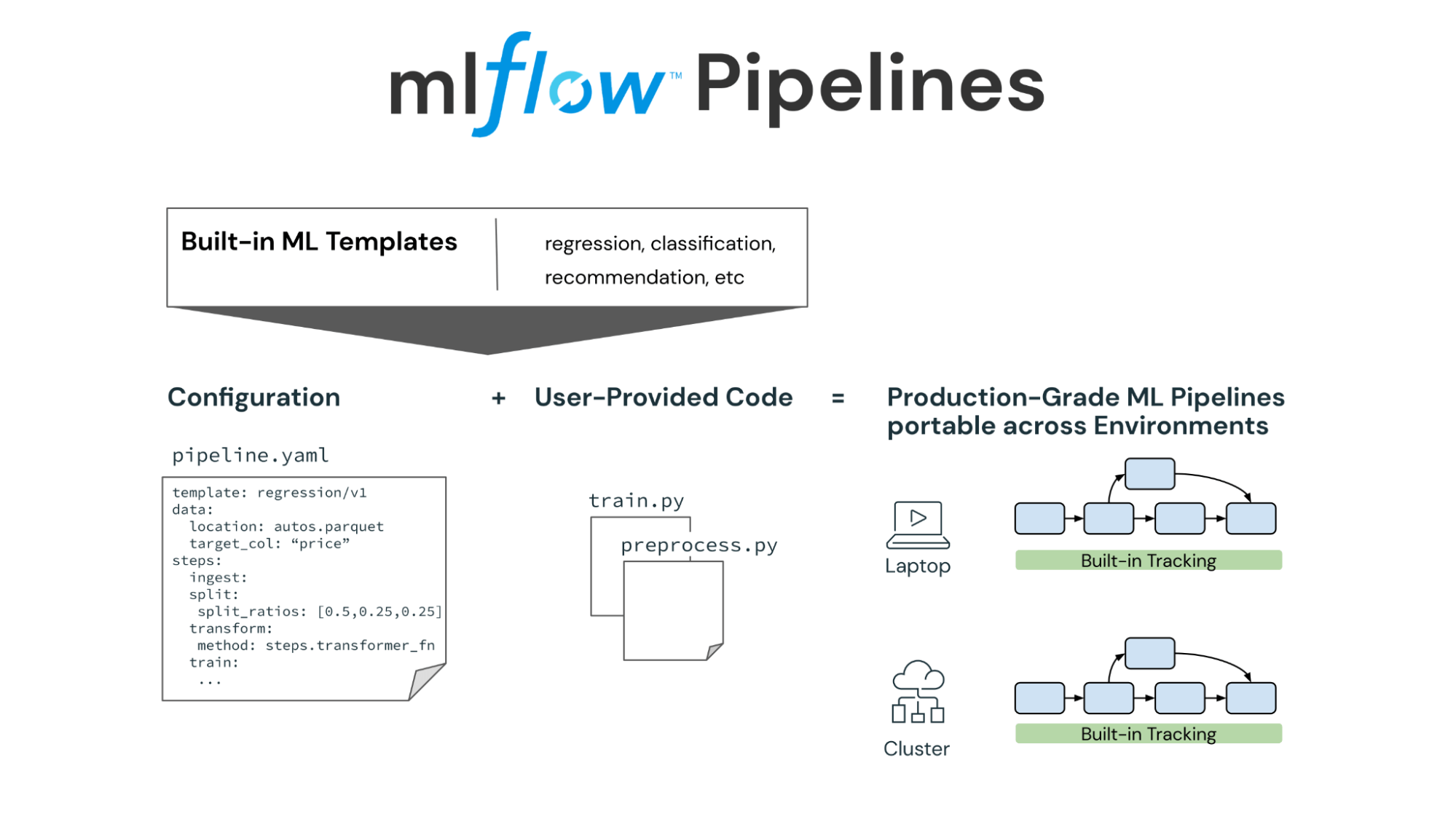
MLflow 2.0 introduces MLflow Pipelines - pre-defined, production-ready templates to accelerate ML
Serverless Model Endpoints
Deploy your models on Serverless Model Endpoints for real-time inference for your production applications. Serverless Model Endpoints provide highly available, low latency REST endpoints that can be set up and configured via UI or API. Users can customize autoscaling to handle their model’s throughput and for predictable traffic use cases, and teams can save costs by autoscaling all the way down to 0. Serverless Model Endpoints also have built-in observability so you can stay on top of your model serving. Now your data science teams don’t have to build and maintain their own kubernetes infrastructure to serve ML models. Sign up now to get notified for the Gated Public Preview.
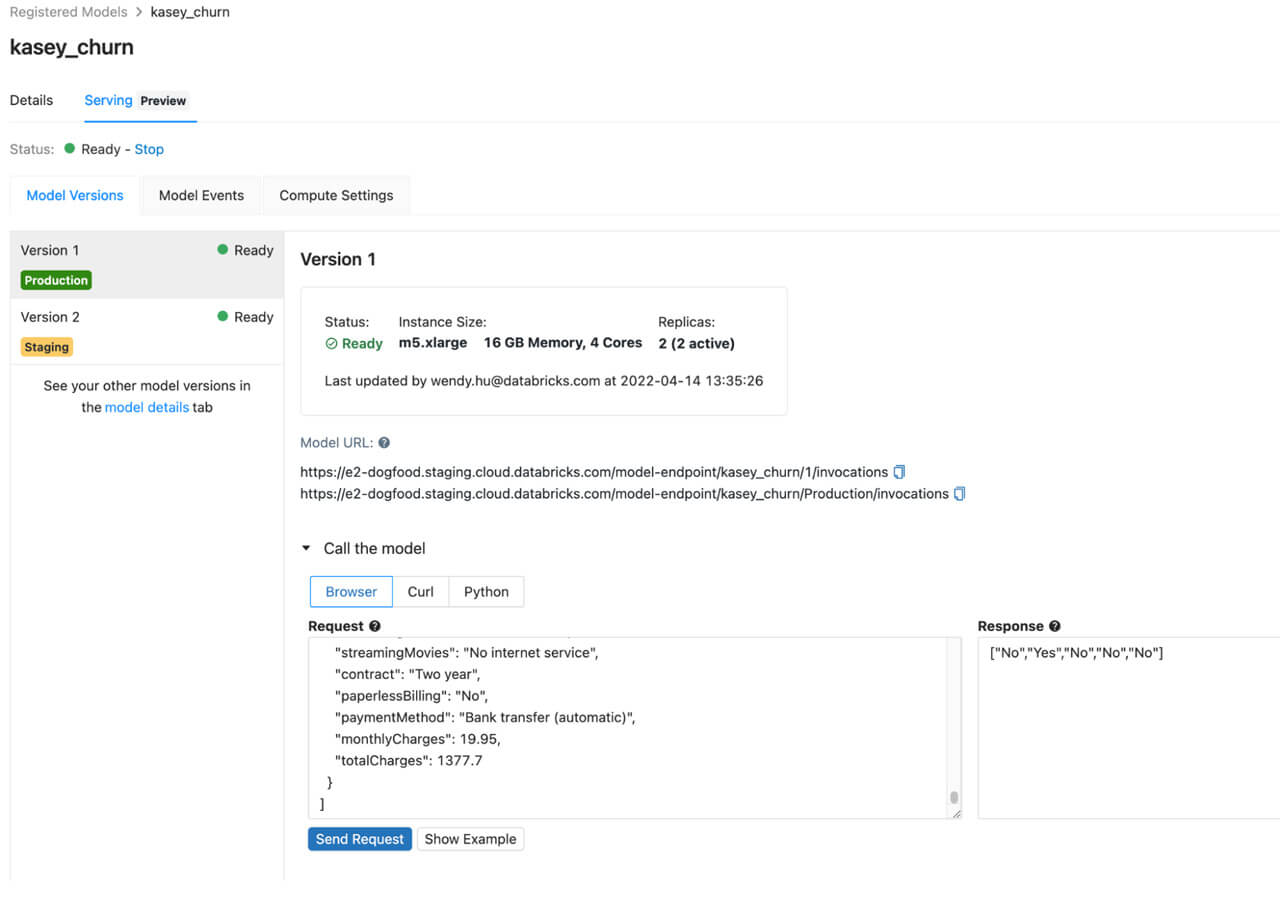
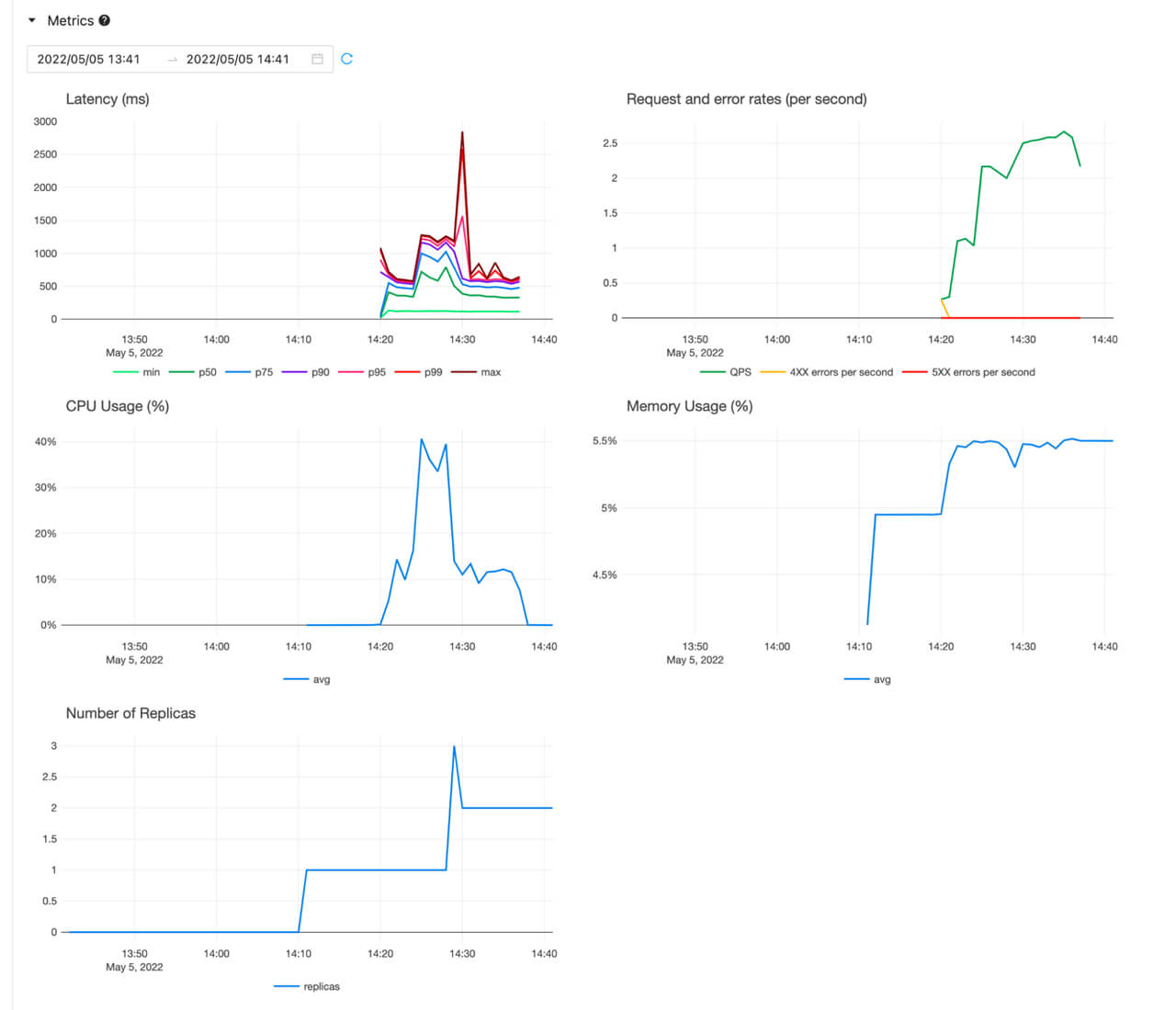
Serverless Model Endpoints provide production-grade model serving hosted by Databricks
Model Monitoring
Track the performance of your production models with Model Monitoring. Our model monitoring solution auto-generates dashboards to help teams view and analyze data and model quality drift. We also provide the underlying analysis and drift tables as Delta tables so teams can join performance metrics with business value metrics to calculate business impact as well as create alerts when metrics have fallen below specified thresholds. While Model Monitoring automatically calculates drift and quality metrics, it also provides an easy mechanism for users to incorporate additional custom metrics. Stay tuned for the Public Preview launch…
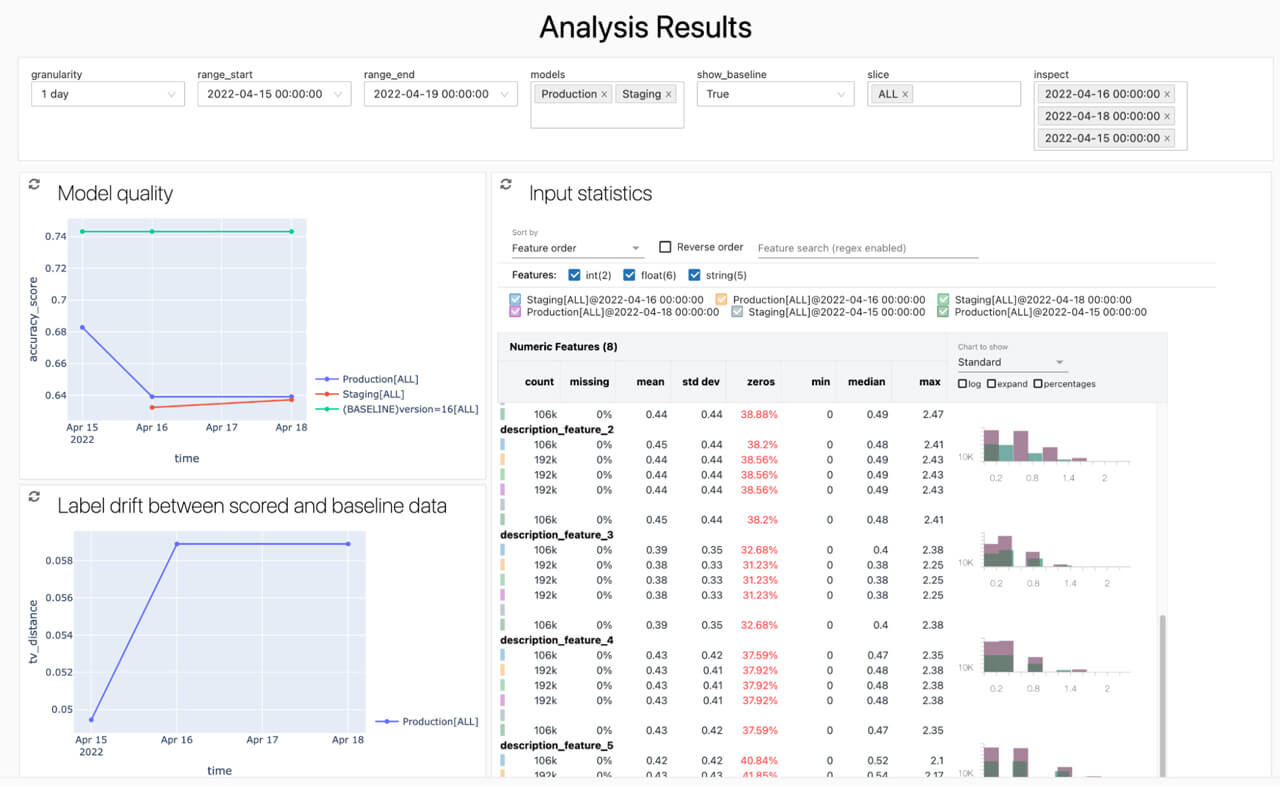
Monitor your deployed models and the related data that feeds them all in a centralized location with auto-generated dashboards and alerting.
Learn more:
- Watch Data + AI Summit 2022 on-summit videos:
https://www.databricks.com/dataaisummit/ - MLflow 2.0 with MLflow Pipelines:
https://www.databricks.com/blog/2022/06/29/introducing-mlflow-pipelines-with-mlflow-2-0.html - Databricks Machine Learning:
https://www.databricks.com/product/machine-learning - Big Book of MLOps:
https://www.databricks.com/p/ebook/the-big-book-of-mlops
Never miss a Databricks post
What's next?


Product
November 21, 2024/3 min read