What is Apache Kylin?
A distributed OLAP engine that pre-calculates multidimensional cubes from Hadoop data, delivering sub-second queries on petabyte-scale datasets
- Apache Kylin is an open source analytics engine that builds precomputed OLAP cubes on big data to deliver very fast SQL queries.
- Apache Kylin is designed to support interactive analysis at scale by trading some storage for speed, making complex reports and dashboards more responsive.
- Kylin typically sits on top of Hadoop or cloud data stores and integrates with BI tools to accelerate query performance for large datasets.
What is Apache Kylin?
Apache Kylin is a distributed open source online analytics processing (OLAP) engine for interactive analytics Big Data. Apache Kylin has been designed to provide SQL interface and multi-dimensional analysis (OLAP) on Hadoop/Spark. In addition, it easily integrates with BI tools via ODBC driver, JDBC driver, and REST API. It was created by eBay in 2014, graduated to Top Level Project of Apache Software Foundation just one year later, in 2015 and won the Best Open Source Big Data Tool in 2015 as well as in 2016. Currently, it is being used by thousands of companies worldwide as their critical analytics application for Big Data. While other OLAP engines struggle with the data volume, Kylin enables query responses in the milliseconds. It provides sub-second level query latency over datasets scaling to petabytes. It gets its amazing speed by precomputing the various dimensional combinations and the measure aggregates via Hive queries and populating HBase with the results. 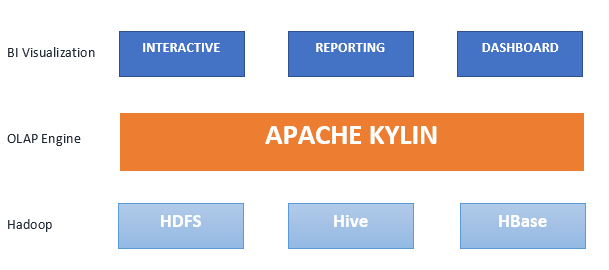
The agentic AI playbook for the enterprise

How Does Apache Kylin Work?
The Kylin query engine which can be accessed in Kylin’s user-friendly UI, via an API or via JDBC will leverage the Apache Calcite query processor and HBase features for rapid lookups. Kylin relies upon the Hadoop Eco-system:
- Hive – Input source, pre-join star schema during cube building
- MapReduce – Aggregate metrics during cube building
- HDFS – Store intermediate files during cube building
- HBase – Store and query data cubes
- Calcite – SQL parsing, code generation, optimization How can Apache Kylin help your organization?
- Very Fast OLAP Engine at Scale - Kylin is designed to reduce query latency on Hadoop for 10+ billions of rows of data to seconds
- ANSI SQL Interface on Hadoop - Kylin offers ANSI SQL on Hadoop and supports most ANSI SQL query functions. It can easily be used by both analysts and engineers as no programming needed
- Seamless Integration with BI Tools - Kylin currently offers integration capability with BI Tools like Tableau, JDBC/ODBC/Rest API
- Interactive Query Capability - Users can interact with Hadoop data via Kylin at sub-second latency
- MOLAP cube query serving on billions of rows - Users have the ability to define a data model and pre-build in Kylin even if it has more than 10+ billions of raw data records.
Open-source ODBC driver - Kylin’s ODBC driver is built from scratch and works very well with Tableau.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.