Unified governance for data, apps and AI agents
Ensure your data, models, agents and apps are discoverable, governed and secure
TOP TEAMS SUCCEED WITH UNIFIED AND OPEN GOVERNANCE


From trusted data to reliable AI, in one catalog
Ground your AI in trusted data with shared business context, govern what your models and agents can do, and run anywhere.Unified data and AI assets
Bring all your AI assets such as agents, AI apps, MCPs and models under the same discovery, governance and guardrails as your data, across the clouds and platforms.
Context-rich discovery
Leverage shared business semantics to help your users and agents discover trusted data and AI assets with the context they need to use them confidently.
AI-powered governance controls
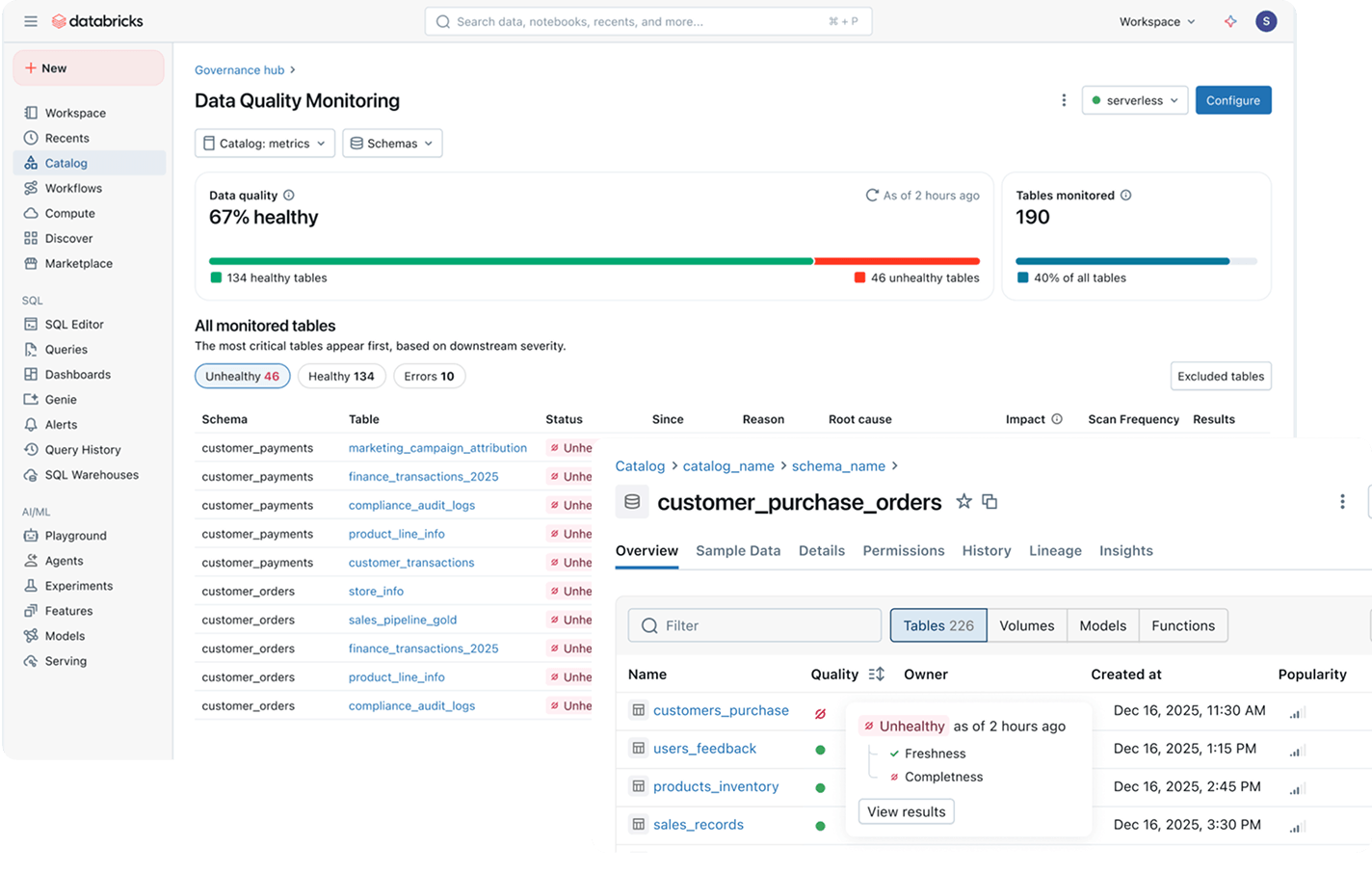
Built-in intelligence automatically enforces access policies, protects sensitive data, monitors quality and optimizes performance across your platform.
Bring all of your data and AI assets in one catalog
Use one catalog to manage all your data and AI assets, including models, agents and MCPs, across any cloud or platform.Control what agents, models and MCPs can access and do, with the same governance, spend controls and visibility you apply to data, through Unity AI Gateway.


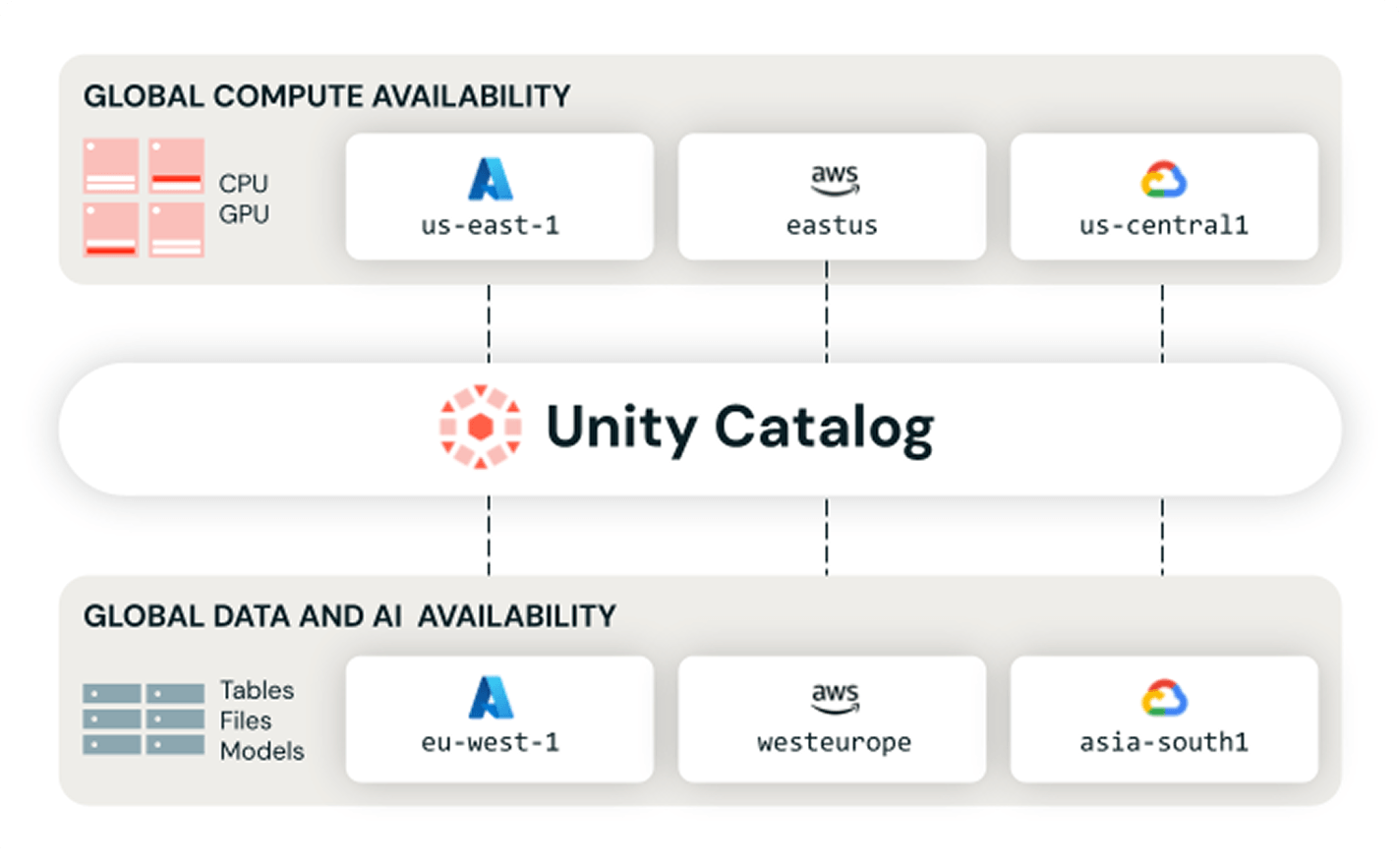
Trusted discovery for users and agents
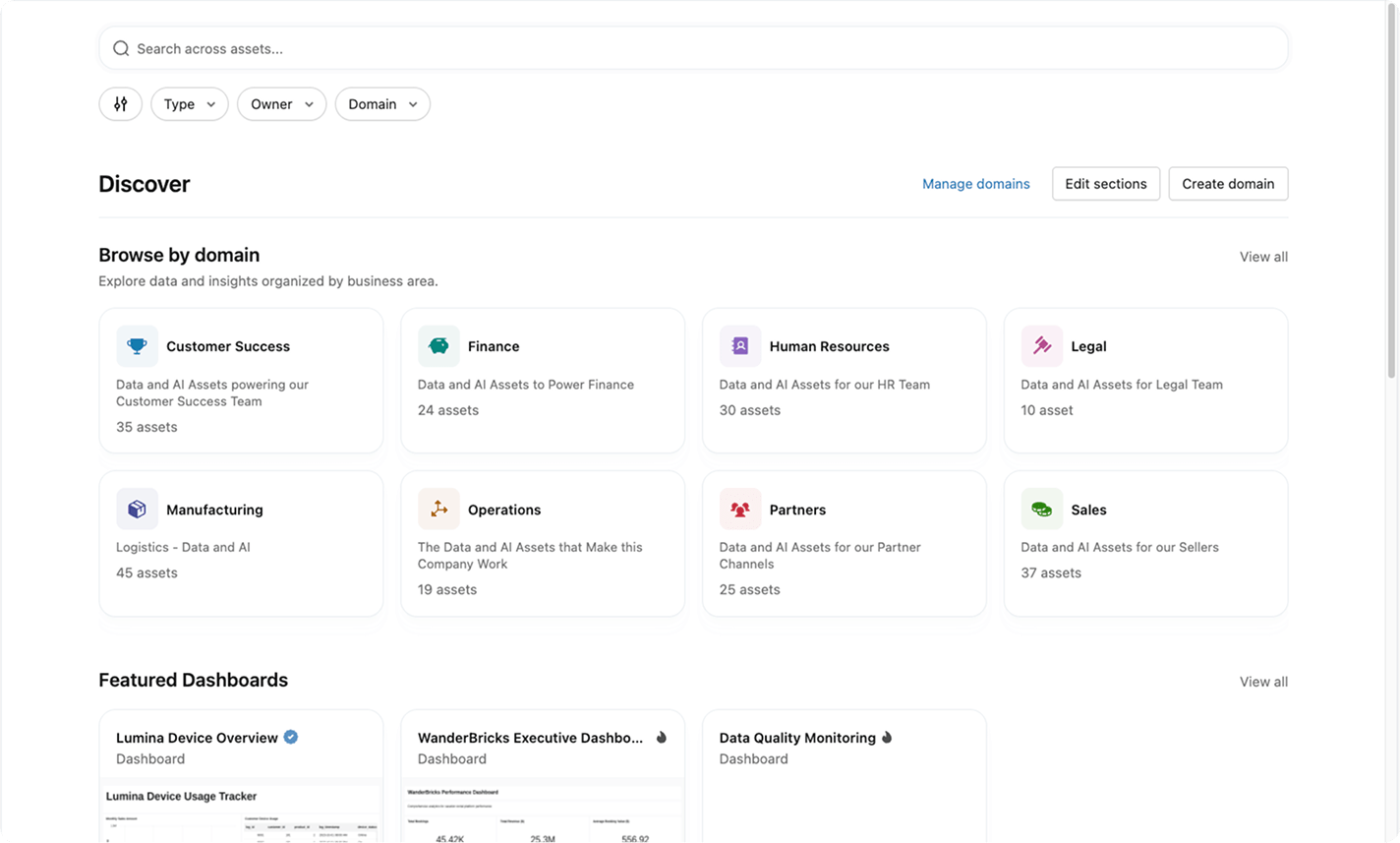
Help humans and agents find, understand and trust the right data and AI assets with shared context, semantics and signals across your entire estate.Unity Catalog delivers AI-powered curation of your most trusted data and AI assets, including tables, dashboards and models, with shared business context in one unified experience.
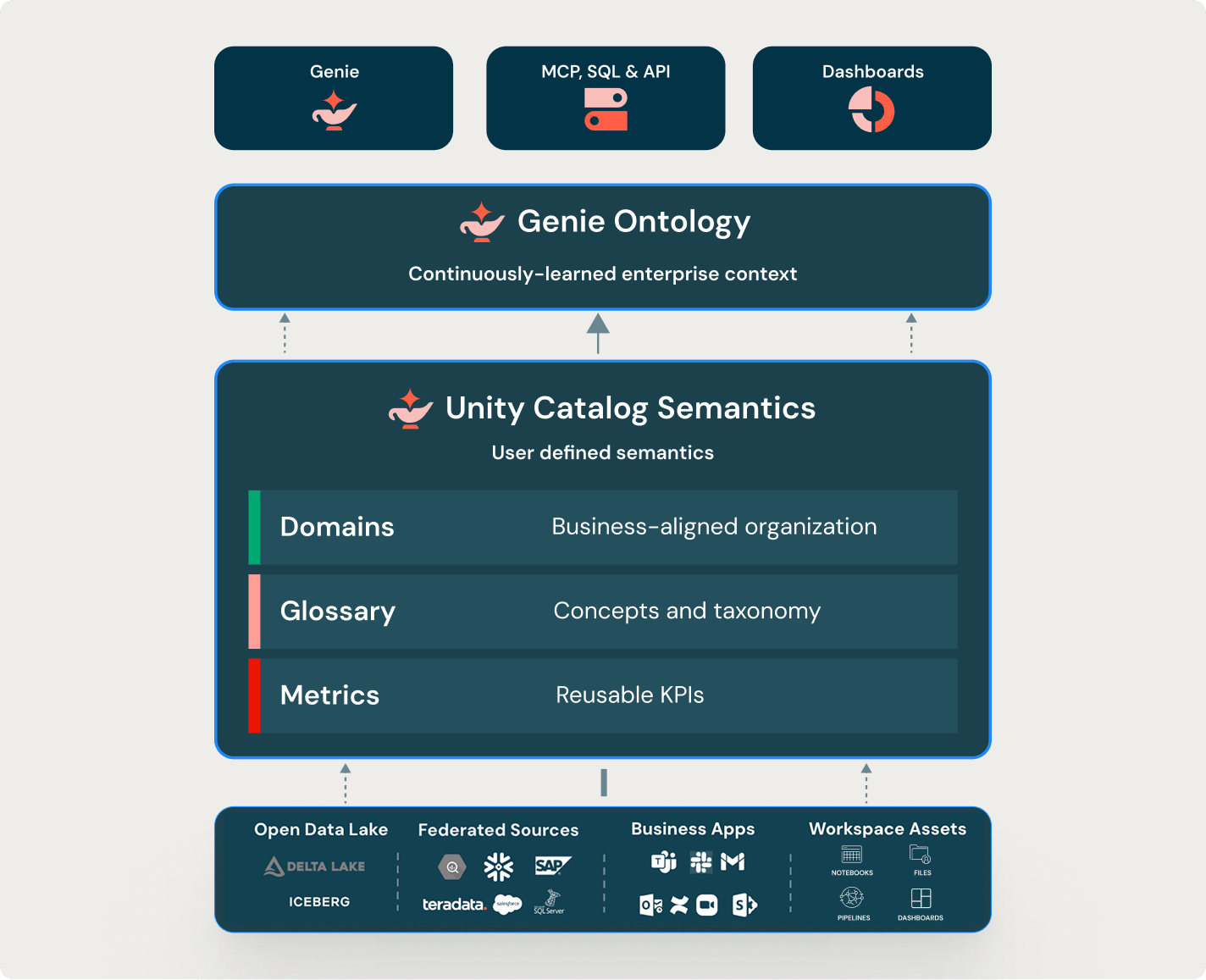
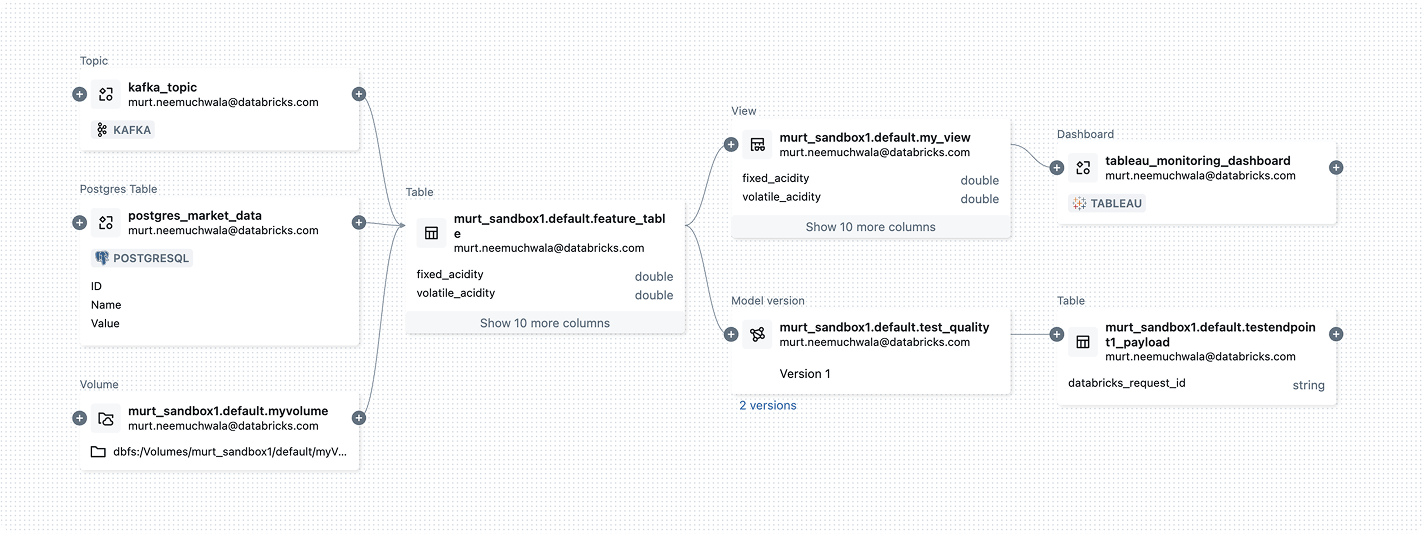
Automated governance, built in
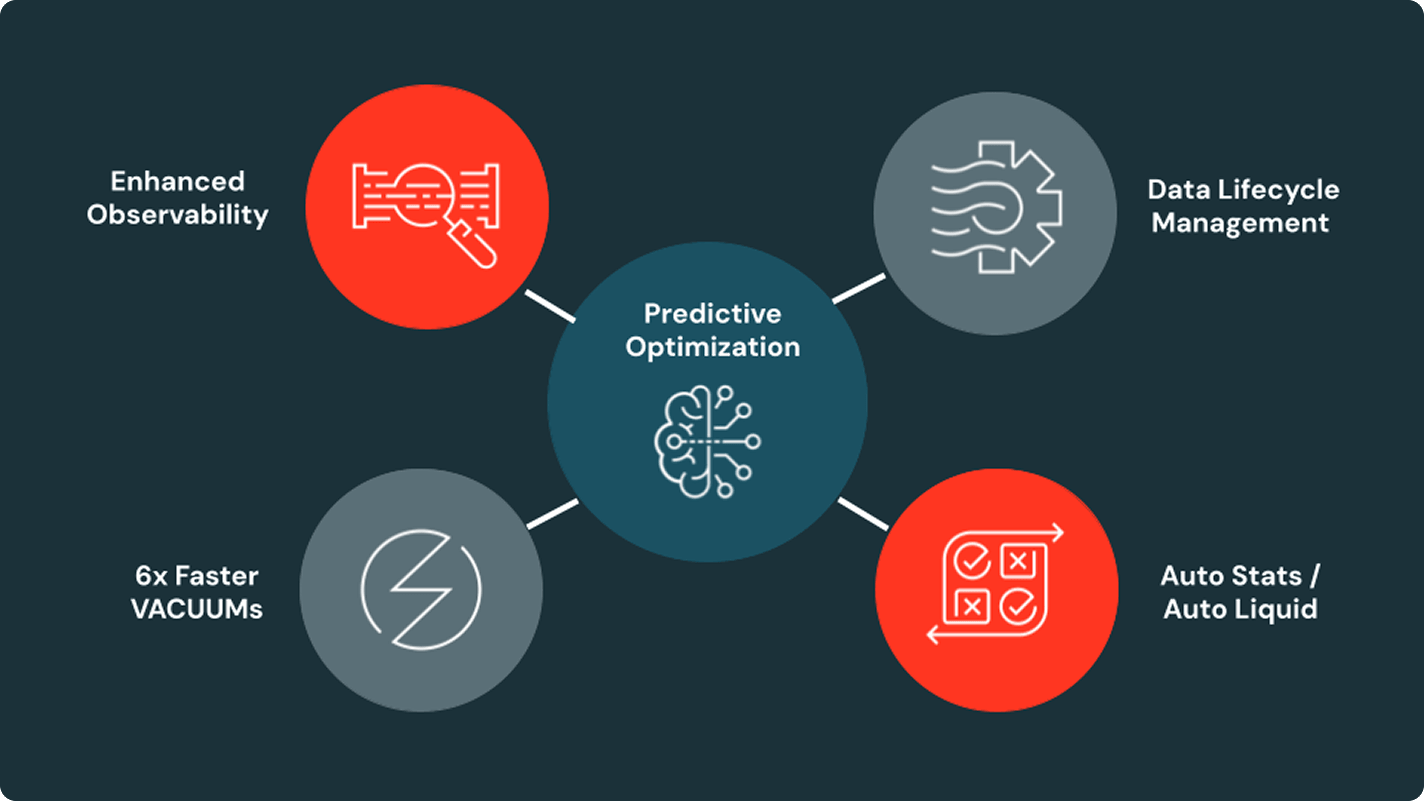
Scale consistent governance across every data and AI asset automatically, with optimized performance and no manual controls.Apply one policy model across your data estate. Unity Catalog uses attributes, tags and automated classification to enforce granular access at scale without manual effort.


Unlock the full business value of data with unified governance

Enable data mesh and domain data products with unified governance
Enable teams to own and publish high-quality data products while maintaining centralized visibility, security and trust across the organization.
- Apply consistent governance policies across domain data products and platforms
- Make domain data products easy to discover with centralized metadata and lineage
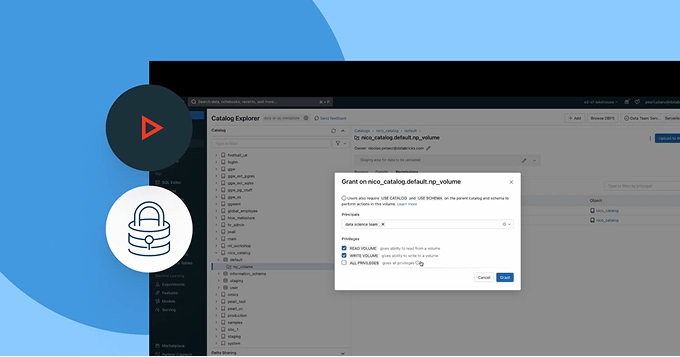
- Automatically classify and tag sensitive data to enable scalable access control
- Maintain a single control plane for federated governance and audit







Discover more
Explore products that extend the power of Unity Catalog across governance, collaboration and data intelligence.
Genie One
A conversational experience, powered by generative AI, for business teams to explore data and self-serve insights in real time through natural language.

Lakehouse Storage
Eliminate data management headaches with open table formats, centralized governance and automatic data optimizations.

OpenSharing
An open source approach to data and AI sharing across platforms. Share live data with centralized governance and no replication.

Databricks Clean Rooms
Analyze shared data from multiple parties without providing direct access to the raw data.

Databricks Marketplace
An open marketplace for data, as well as AI and analytics assets such as ML models and notebooks.
Take the next step




Unity Catalog FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation