Data Lakes on Azure
Complete and authoritative data source to power your lakehouse

What is an Azure data lake?
An Azure data lake includes scalable, cloud data storage and analytics services. Azure Data Lake Storage enables organizations to store data of any size, format and speed for a wide variety of processing, analytics and data science use cases. When used with other Azure services — such as Azure Databricks — Azure Data Lake Storage is a far more cost-effective way to store and retrieve data across your entire organization.
Whether your data is large or small, fast or slow, structured or unstructured, Azure Data Lake integrates with Azure identity, management and security to simplify data management and governance. Azure storage automatically encrypts your data, and Azure Databricks provides tools to safeguard data to meet your organization’s security and compliance needs.

Why do you need an Azure data lake?
Data lakes are open format, so users avoid lock-in to a proprietary system like a data warehouse. Open standards and formats have become increasingly important in modern data architectures. Data lakes are also highly durable and low cost because of their ability to scale and leverage object storage. Additionally, advanced analytics and machine learning on unstructured data are some of the most strategic priorities for enterprises today. The unique ability to ingest raw data in a variety of formats — structured, unstructured and semi-structured — along with the other benefits mentioned makes a data lake the clear choice for data storage.
When properly architected, data lakes provide the ability to:
- Power data science and machine learning
- Centralize, consolidate and catalog your data
- Quickly and seamlessly integrate diverse data sources and formats
- Democratize your data by offering users self-service tools
What is the difference between an Azure data lake and an Azure data warehouse?
A data lake is a central location that holds a large amount of data in its native, raw format, as well as a way to organize large volumes of highly diverse data. Compared to a hierarchical data warehouse, which stores data in files or folders, a data lake uses a flat architecture to store the data. Data lakes are usually configured on a cluster of scalable commodity hardware. As a result, you can store raw data in the lake in case it will be needed at a future date — without worrying about the data format, size or storage capacity.
In addition, data lake clusters can exist on-premises or in the cloud. Historically, the term "data lake" was often associated with Hadoop-oriented object storage, but today the term generally refers to the broader category of object storage. Object storage stores data with metadata tags and a unique identifier, which makes it easier to locate and retrieve data across regions and improves performance. The Databricks Lakehouse Platform makes all the data in your data lake available for any number of data-driven use cases.

Why use Delta Lake format for your Azure data lake?
Here are five key reasons to convert data lakes from Apache Parquet, CSV, JSON and other formats to Delta Lake format:
- Prevent data corruption
- Faster queries
- Increase data freshness
- Reproduce ML models
- Achieve compliance
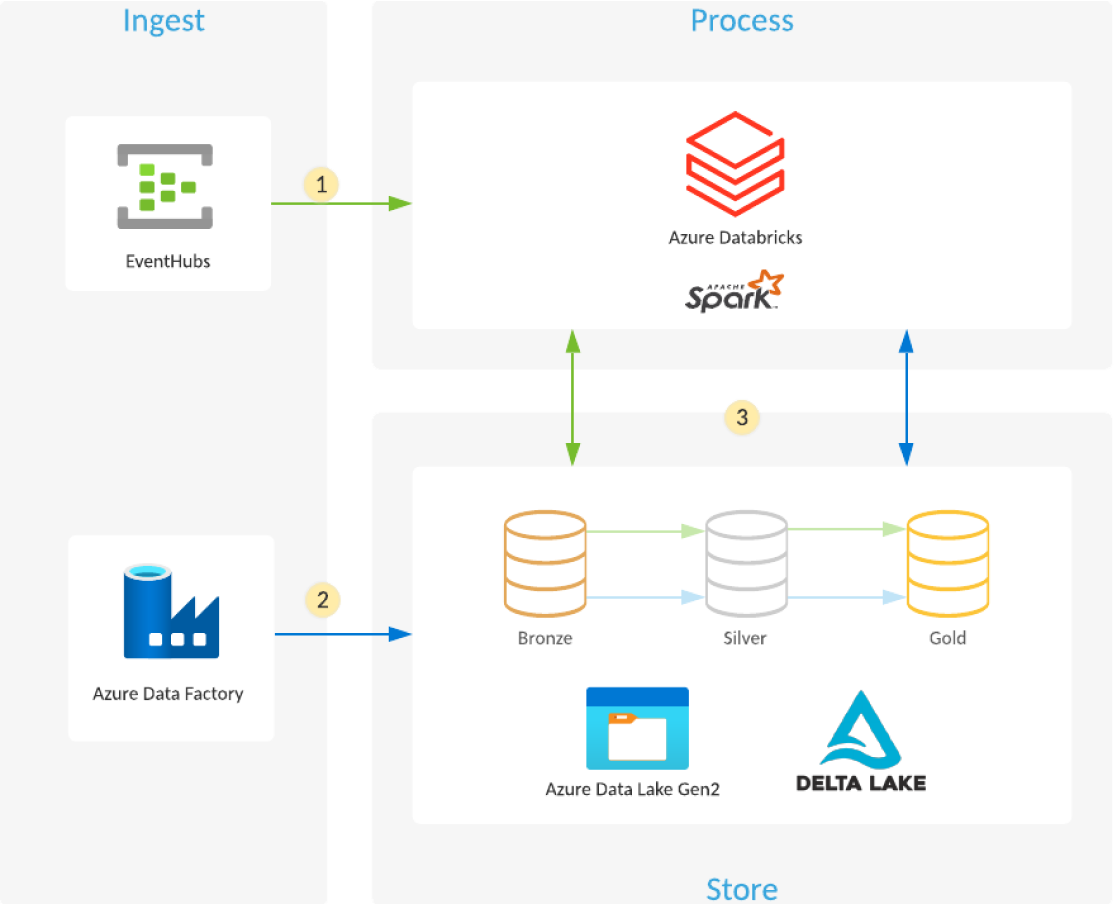
How do you build a data lake using Azure Databricks and Azure Data Lake Storage?
Managed Delta Lake in Azure Databricks provides a layer of reliability that enables you to curate, analyze and derive value from your data lake on the cloud.
- Azure Databricks reads streaming data from event queues, such as Azure Event Hubs, Azure IoT Hub or Kafka, and loads the raw events into optimized, compressed Delta Lake tables and folders (Bronze layer) stored in Azure Data Lake Storage.
- Scheduled or triggered Azure Data Factory pipelines copy data from different data sources in their raw format into Azure Data Lake Storage. The Auto Loader in Azure Databricks processes the files as they land and loads them into optimized, compressed Delta Lake tables and folders (Bronze layer) stored in Azure Data Lake Storage.
- Streaming or scheduled/triggered Azure Databricks jobs read new transactions from the Bronze layer and then join, clean, transform and aggregate them before using ACID transactions (INSERT, UPDATE, DELETE, MERGE) to load them into curated data sets (Silver and Gold layers) stored in Delta Lake on Azure Data Lake Storage.
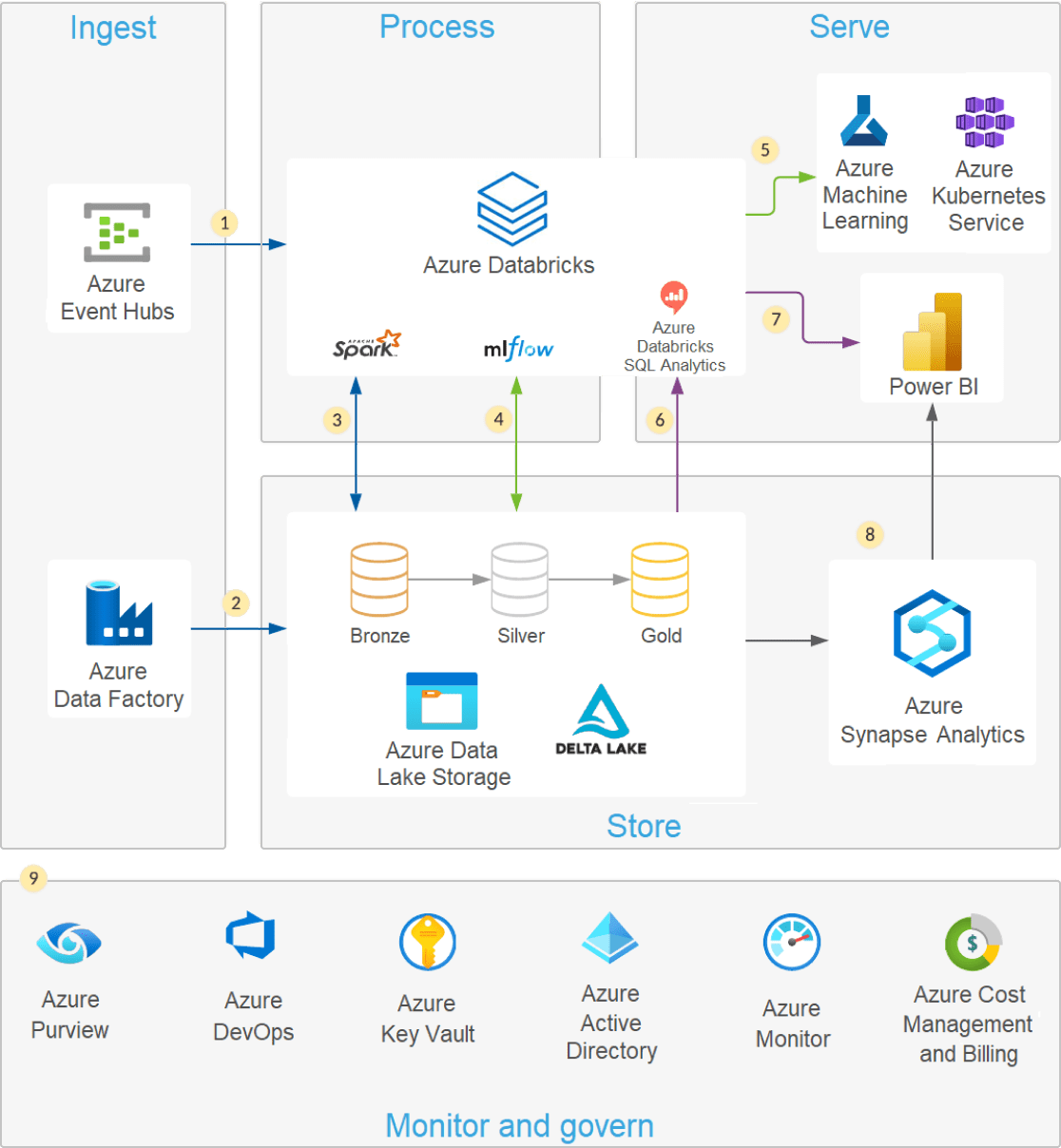
Modern data lake architecture
A modern lakehouse architecture that combines the performance, reliability and data integrity of a warehouse with the flexibility, scale and support for unstructured data available in a data lake.
Modern data lakes leverage cloud elasticity to store virtually unlimited amounts of data "as is," without the need to impose a schema or structure. Structured Query Language (SQL) is a powerful querying language to explore your data and discover valuable insights. Delta Lake is an open source storage layer that brings reliability to data lakes with ACID transactions, scalable metadata handling and unified streaming and batch data processing. Delta Lake is fully compatible and brings reliability to your existing data lake.
You can easily query your data lake using SQL and Delta Lake with Azure Databricks. Delta Lake enables you to execute SQL queries on both your streaming and batch data without moving or copying your data. Azure Databricks provides added benefits when working with Delta Lake to secure your data lake through native integration with cloud services, delivers optimal performance and helps audit and troubleshoot data pipelines.
- Delta Lake integrates with scalable cloud storage or HDFS to help eliminate data silos
- Explore your data using SQL queries and an ACID-compliant transaction layer directly on your data lake
- Leverage Gold, Silver and Bronze "medallion tables" to consolidate and simplify data quality for your data pipelines and analytics workflows
- Use Delta Lake time travel to see how your data changed over time
- Azure Databricks optimizes performance with features like Delta cache, file compaction and data skipping