No-code data science and machine learning
Proliferate data science across your entire organization and help everyone make data-driven decisions

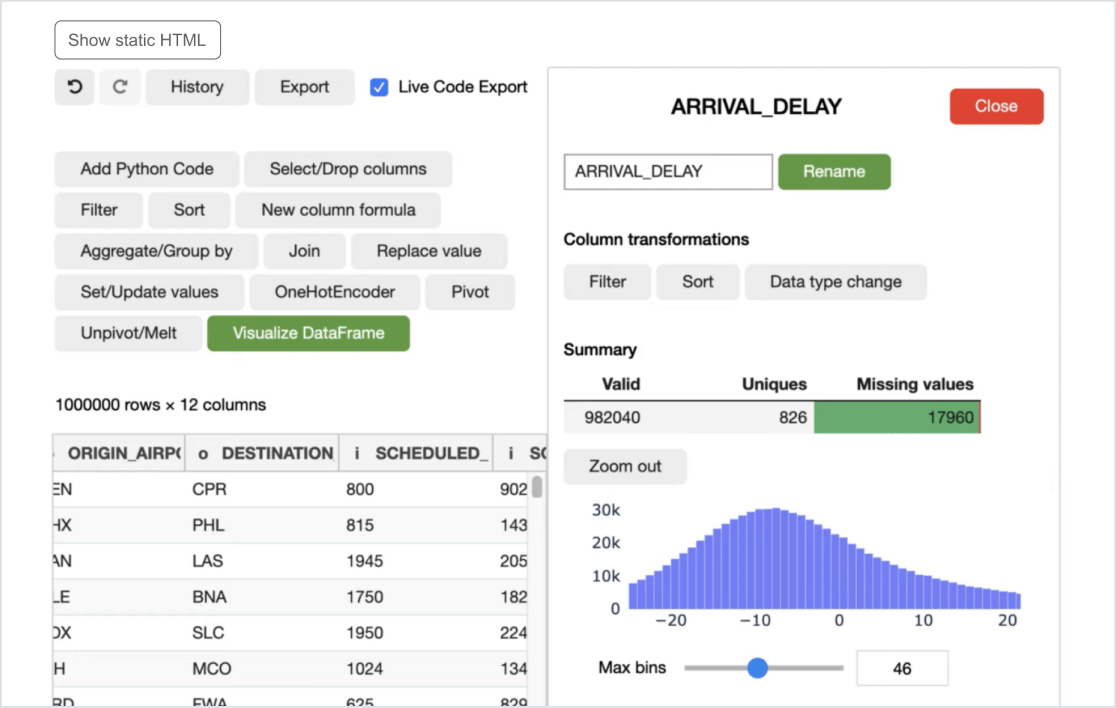
Tools with enterprise reliability and scale for citizen data scientists
Databricks helps you analyze vast and complex data sets, discover insights and make predictions with just a few clicks. Organize, transform and visualize your data without having to write a single line of code.
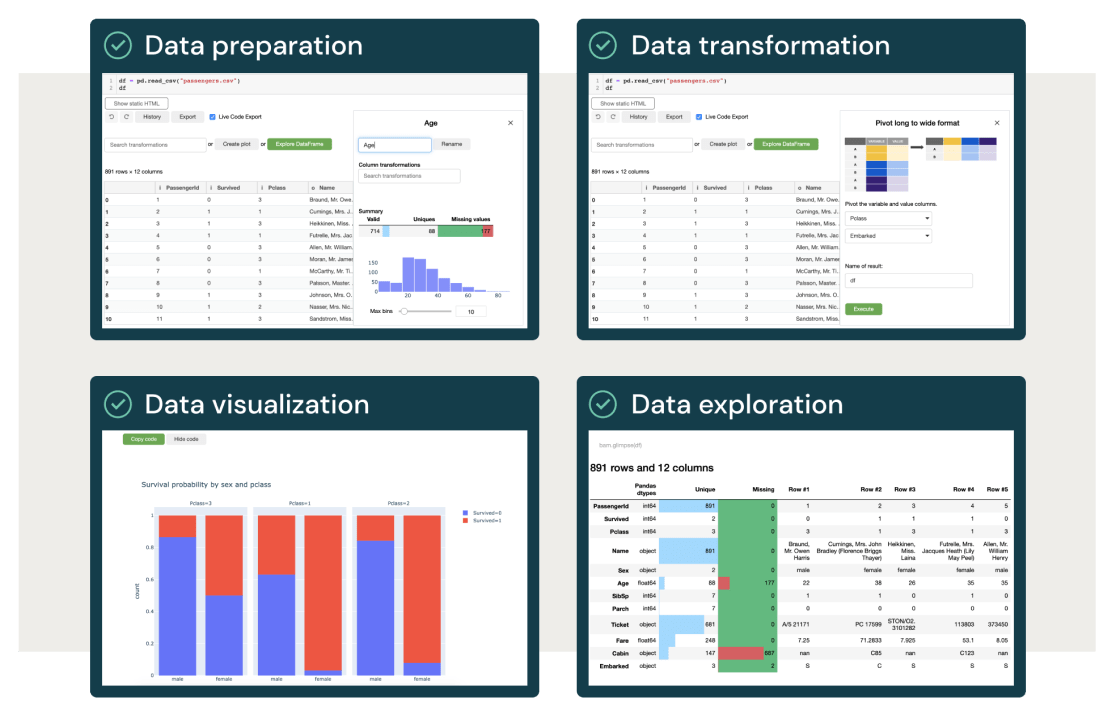
Data engineering for non-engineers
Machine learning begins with data engineering. For the first time, you can now prepare, transform, visualize and perform exploratory data analysis without writing code. Databricks allows anyone in the organization to prepare data for any downstream use case.
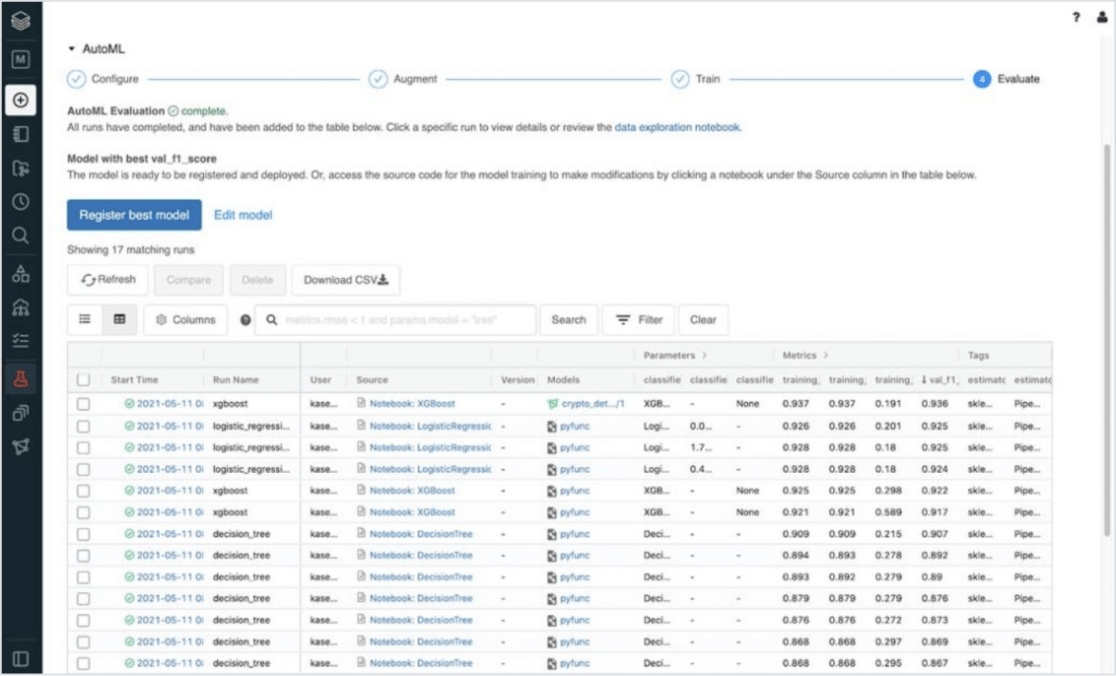
Fully automated machine learning
Databricks AutoML provides a glass box approach to citizen data science, enabling teams to quickly build, train and deploy machine learning models by automating the heavy lifting of preprocessing, feature engineering and model training and tuning. Import data sets, configure training and deploy models — without having to leave the UI.
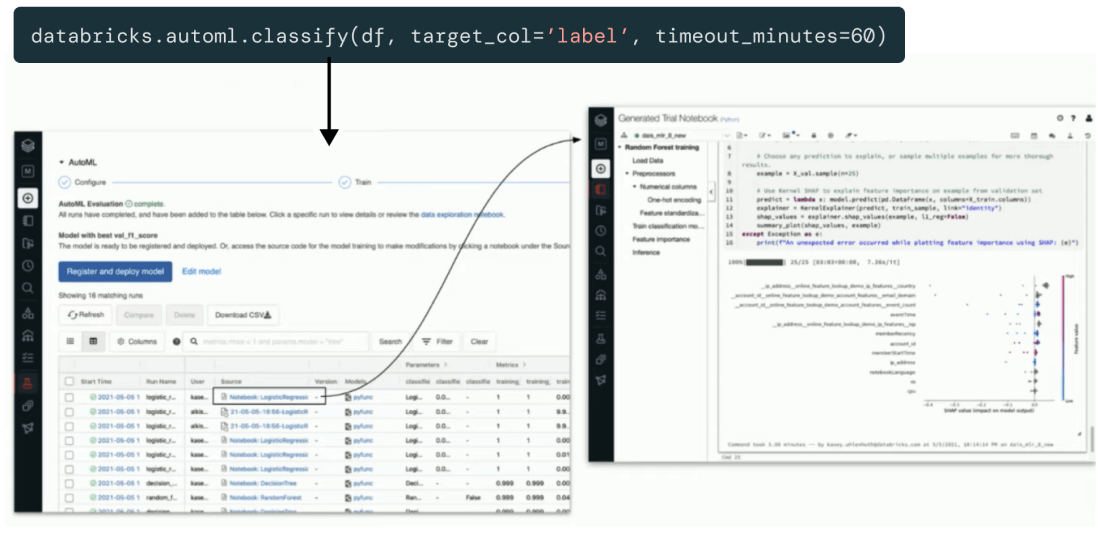
Transparency and visibility for a closer look when you need it
Unique to Databricks Machine Learning, all steps performed in the UI also generate production-grade code under the hood.
Expert data scientists and machine learning engineers can inspect this code and add their own customizations, or regulators can reference it when reproducibility and transparency are critical. Databricks Machine Learning is natively integrated with MLflow, enabling granular experiment tracking and version control — from preprocessing and feature engineering to training and deployment.
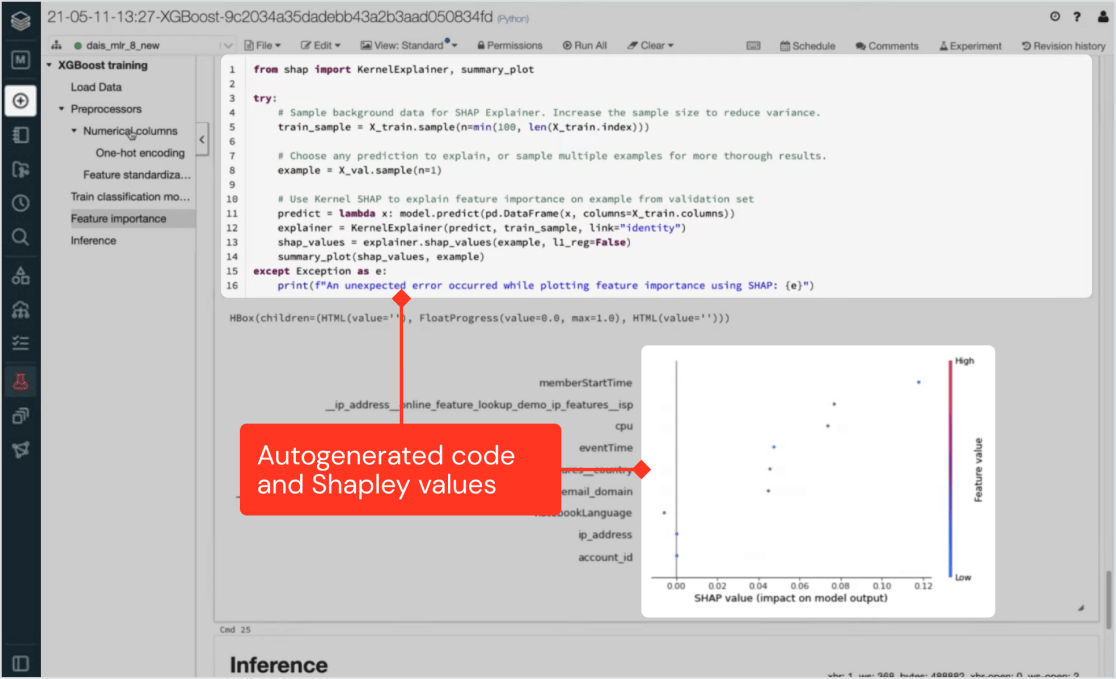
Explainable and compliant for cross-functional collaboration
Databricks’ support for full lineage tracking and registering autogenerated code ensures that everyone’s data science projects are secure, compliant and traceable. Explainability features provide insight into which inputs have the most bearing on the generated model. This creates a foundation for a wide variety of teams to collaborate — from the user to data scientists and machine learning engineers all the way to IT, legal and compliance.
Resources
eBooks
Documentation
Solutions
Ready to get started with Databricks?