Data Ingestion Reference Architecture
This data ingestion reference architecture provides a simplified, unified and efficient foundation for loading data from diverse enterprise sources into the Databricks Data Intelligence Platform.
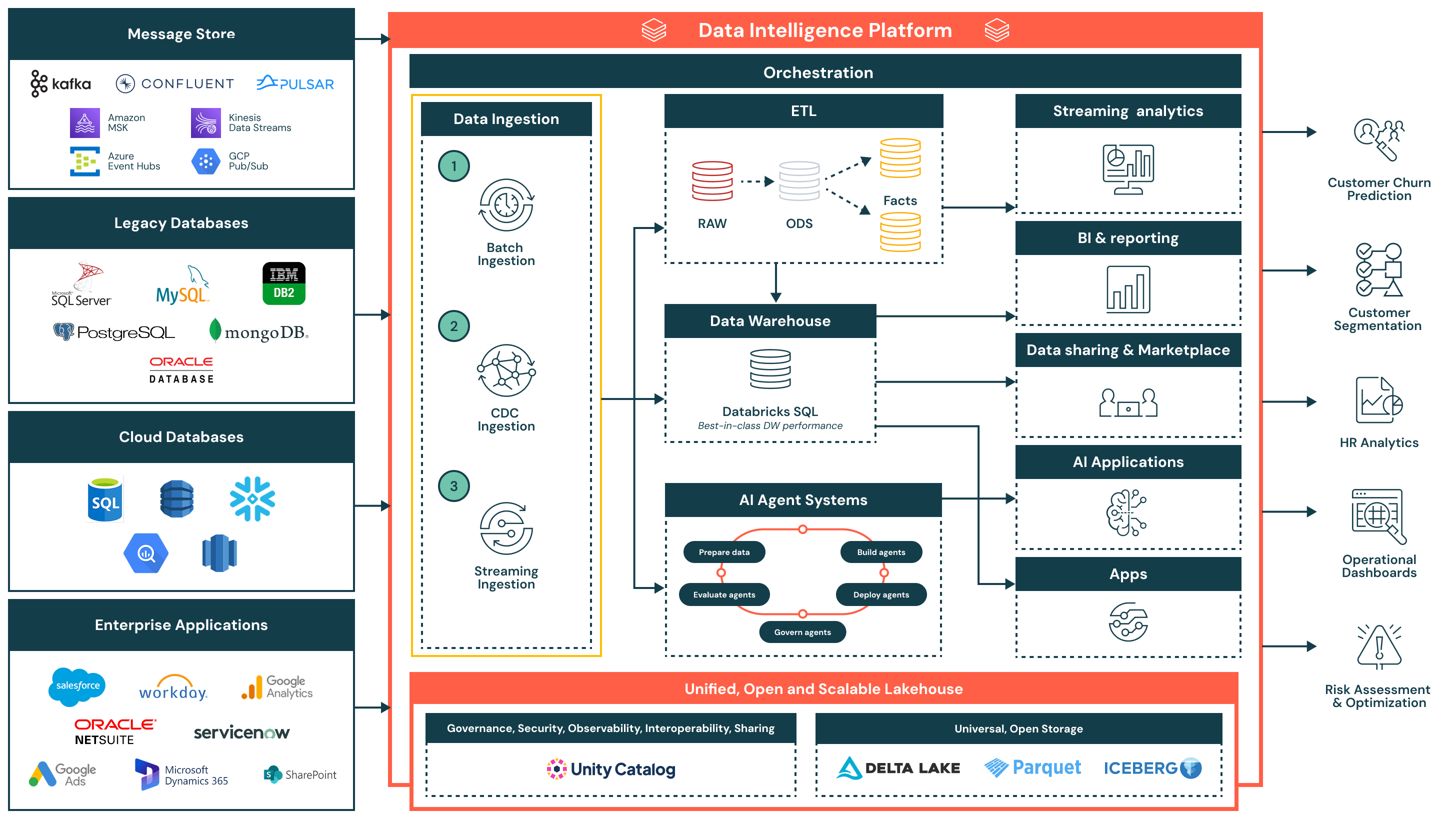
Architecture Summary
The data ingestion reference architecture supports a wide range of ingestion patterns — including batch, change data capture (CDC) and streaming — while ensuring governance, performance and interoperability. Once ingested, data is refined and made available for analytics, AI and secure data sharing across the organization.
This architecture is ideal for organizations looking to modernize and operationalize data pipelines while reducing complexity and integration overhead. It is built around three key principles:
- Simple and low maintenance: Ingestion pipelines are easy to build and manage, enabling faster time to value, fewer operational bottlenecks and broader access to data across teams
- Unified with the lakehouse architecture: Data flows directly into the lakehouse using open formats and governed by Unity Catalog — ensuring consistency across BI, AI and operational use cases
- Efficient end-to-end flow: From ingestion to transformation and delivery, the platform supports efficient, incremental processing that minimizes duplication, latency and resource usage
Use Cases
Technical Use Cases
- Periodic batch ingestion from flat files, exports or APIs into staging zones
- Change data capture (CDC) ingestion to incrementally sync updates from transactional systems like Oracle or PostgreSQL
- Streaming ingestion of real-time events from Kafka or message queues for use in live dashboards or alerting systems
- Harmonizing ingestion across legacy systems, cloud-native databases and enterprise SaaS applications
- Feeding curated and transformed data into data warehouses, AI applications and external APIs
Business Use Cases
- Predicting customer churn by ingesting behavioral, transactional and support data
- Powering executive dashboards with fresh operational metrics from ERP and CRM systems
- Segmenting customers by combining campaign, sales and product usage data
- Conducting HR analytics by integrating data from Workday and productivity platforms
- Performing risk assessment by analyzing transactions and alert feeds in near real time
Data Ingestion Flow and Key Capabilities
- Batch ingestion
- Loads data at scheduled intervals or on-demand from sources like flat files, APIs or database exports
- Suitable for daily reporting, historical data loads and system-of-record snapshots
- Supports both full and incremental loads, with native scheduling, retry logic and transformation using SQL or Python
- Change data capture (CDC) ingestion
- Captures incremental changes from transactional systems such as Oracle, PostgreSQL and MySQL
- Keeps lakehouse tables updated without full reloads, improving efficiency and data freshness
- Enables near real-time data sync for fact tables, audit trails and reporting layers
- Streaming ingestion
- Continuously processes data from event sources like Kafka, Kinesis, Pub/Sub or Event Hubs
- Ideal for real-time dashboards, alerting systems and anomaly detection
- Structured Streaming manages state, fault tolerance and throughput, reducing operational overhead
Additional Platform Capabilities
- Unified governance
- Unity Catalog provides unified governance, including access control, lineage and audit tracking
- Data is stored in open, interoperable formats using Delta Lake and Apache Iceberg™, ensuring flexibility and interoperability across tools and environments
- A centralized orchestration layer manages pipeline scheduling, dependencies, monitoring and recovery
- Lakehouse architecture: Ingested data is transformed and modeled into the medallion architecture (Bronze, Silver and Gold), powering high-performance querying in Databricks SQL
- Orchestration: Built-in orchestration manages data pipelines, AI workflows and scheduled jobs across batch and streaming workloads, with native support for dependency management and error handling
- AI and agent systems: Data feeds into agent systems for preparing features, evaluating models and deploying AI-powered applications
- Downstream consumption:
- Streaming analytics: Real-time visualization of key metrics and operational signals
- BI/analytics: Curated datasets served to tools like Power BI, Lakeview and SQL clients
- AI applications: Governed datasets consumed by training pipelines and inference engines
- Data sharing and marketplace: Secure internal and external data sharing via Delta Sharing
- Operational apps: Embedded intelligence and contextual insights in enterprise tools



