Real-Time End-to-End Integration with Apache Kafka in Apache Spark’s Structured Streaming
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
View the Notebook in Databricks Community Edition
Structured Streaming APIs enable building end-to-end streaming applications called continuous applications in a consistent, fault-tolerant manner that can handle all of the complexities of writing such applications. It does so without having to reason about the nitty-gritty details of streaming itself and by allowing the usage of familiar concepts within Spark SQL such as DataFrames and Datasets. All of this has led to a high interest in use cases wanting to tap into it. From introduction, to ETL, to complex data formats, there has been a wide coverage of this topic. Structured Streaming is also integrated with third party components such as Kafka, HDFS, S3, RDBMS, etc.
In this blog, I'll cover an end-to-end integration with Kafka, consuming messages from it, doing simple to complex windowing ETL, and pushing the desired output to various sinks such as memory, console, file, databases, and back to Kafka itself. In the case of writing to files, I'll cover writing new data under existing partitioned tables as well.

Connecting to a Kafka Topic
Let's assume you have a Kafka cluster that you can connect to and you are looking to use Spark's Structured Streaming to ingest and process messages from a topic. The Databricks platform already includes an Apache Kafka 0.10 connector for Structured Streaming, so it is easy to set up a stream to read messages:

There are a number of options that can be specified while reading streams. The details of those options can be found here.
Let's quickly look at the schema for streamingInputDF DataFrame that we set up above.

It includes key, value, topic, partition, offset, timestamp and timestampType fields. We can pick and choose the ones as needed for our processing. The ‘value’ field is the actual data, and timestamp is message arrival timestamp. In windowing cases, we should not confuse this timestamp with what might be included in the messages itself which is more relevant most of the time.
Streaming ETL
Now that the stream is set up, we can start doing the required ETL on it to extract meaningful insights. Notice that streamingInputDF is a DataFrame. Since DataFrames are essentially an untyped Dataset of rows, we can perform similar operations to them.
Let’s say that the generic ISP hit JSON data is being pushed to the Kafka

It is now possible to do interesting analysis quickly, such as how many users are coming in from a zipcode, what ISP do users come in from, etc. We can then create dashboards that can be shared to the rest of our organization. Let’s dive in:
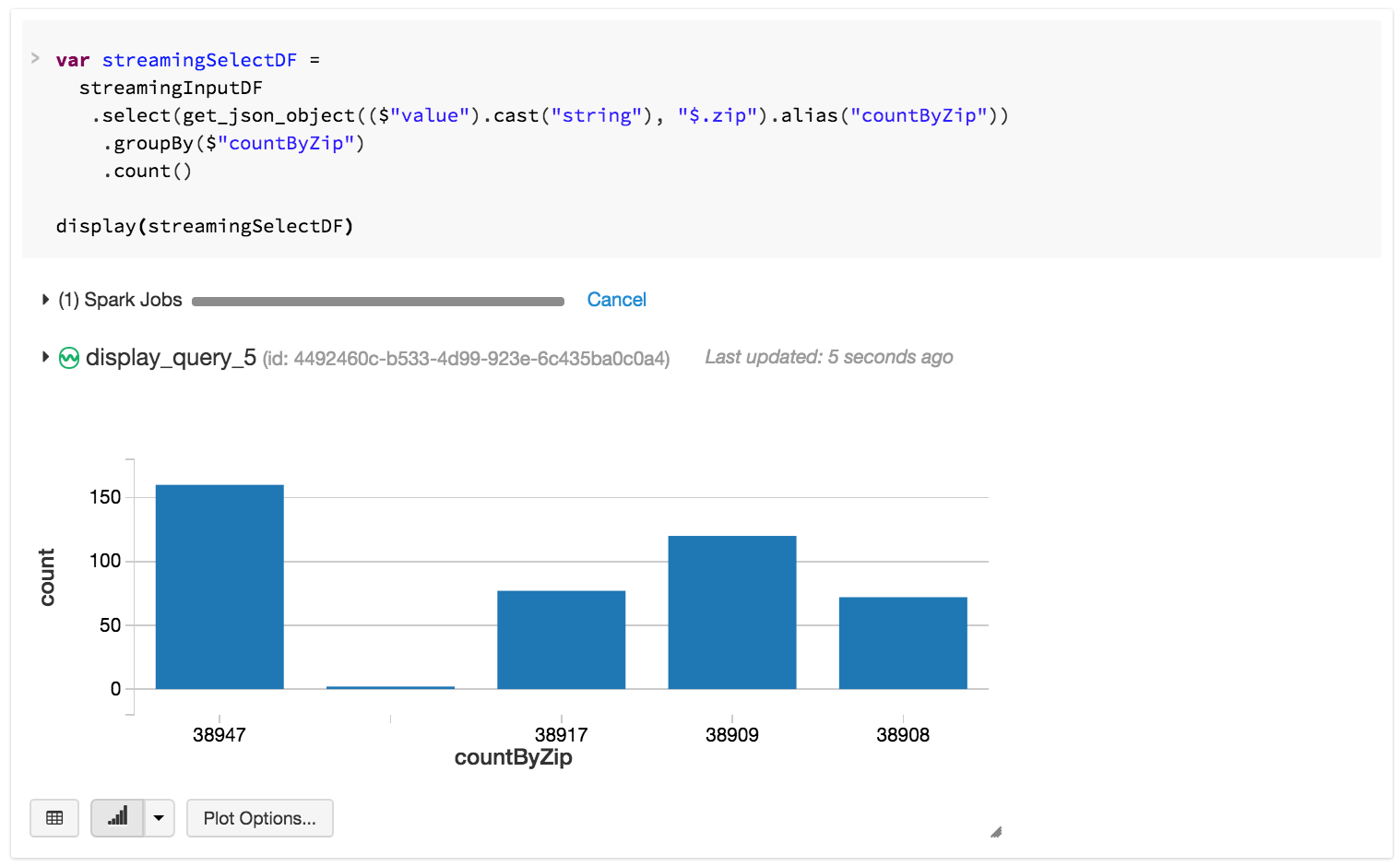
Notice in the command above, we are able to parse the zipcode out of incoming JSON messages, group them and do a count, all in real-time as we are reading data from the Kafka topic. Once we have the count, we can display it, which fires the streaming job in the background and continuously updates the counts as new messages arrive. This auto-updating chart can now be shared as an access-controlled dashboard in Databricks with the rest of our organization.
Windowing
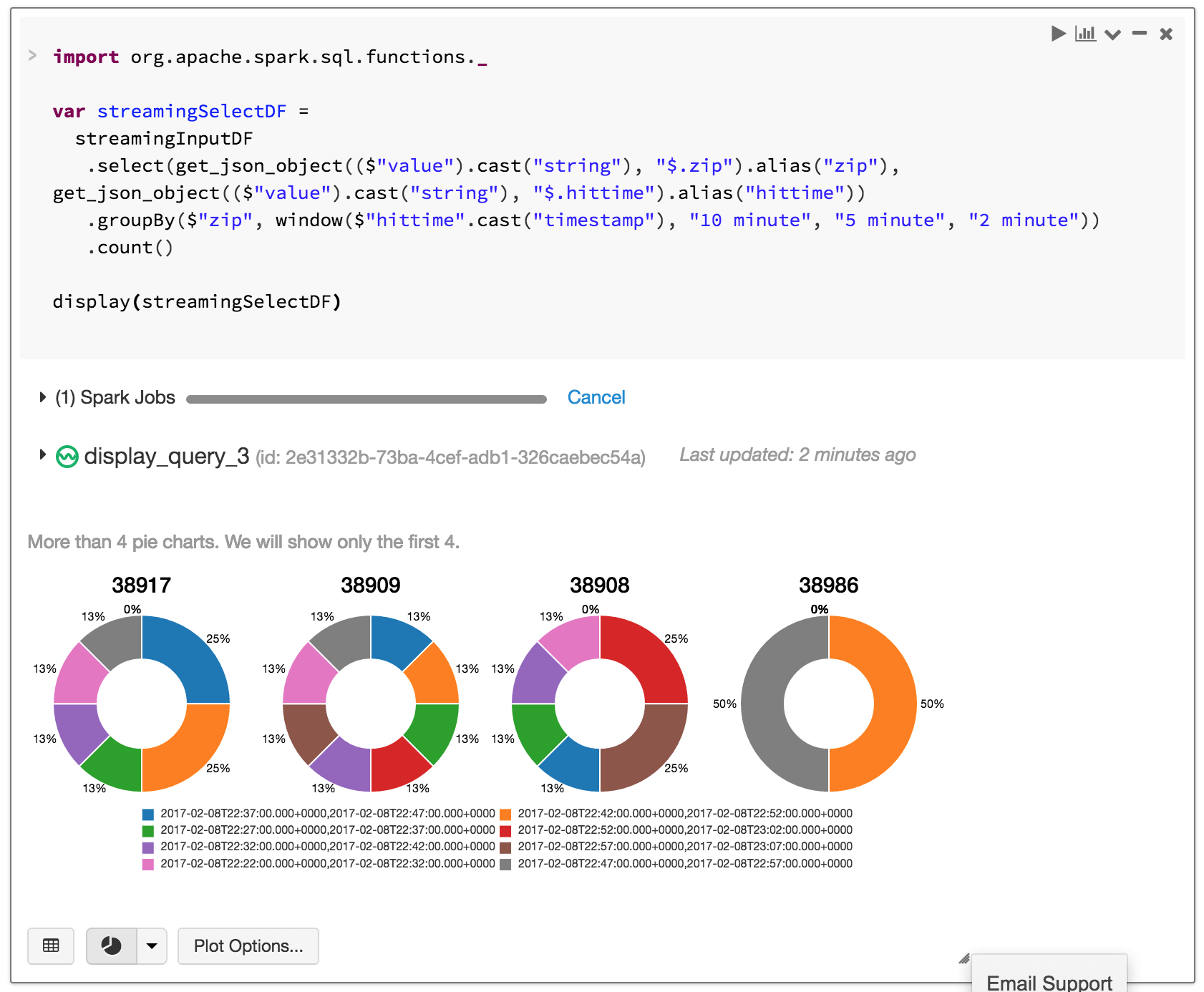
Now that we have parse, select, groupBy and count queries continuously executing, what if we want to find out traffic per zip code for a 10 minute window interval, with sliding duration of 5 minutes starting 2 minutes past the hour?
In this case, the incoming JSON contains timestamp in ‘hittime,’ so let’s use that to query the traffic per each 10 minute window.
Note that in Structured Streaming, windowing is considered a groupBy operation. The pie charts below represents each 10 minute window.
Output Options
So far, we have seen the end results being displayed automatically. If we want more control in terms output options, there are a variety of output modes available. For instance, if we need to debug, you may wish to select the console output. If we need to be able to query the dataset interactively as data is being consumed, the memory output would be an ideal choice. Similarly, the output can be written to files, external databases, or even streamed back to Kafka.
Let’s go over these options in detail.
Memory
In this scenario, data is stored as an in-memory table. From here, users are able to query the dataset using SQL. The name of the table is specified from the queryName option. Note we continue to use streamingSelectDF from the above windowing example.
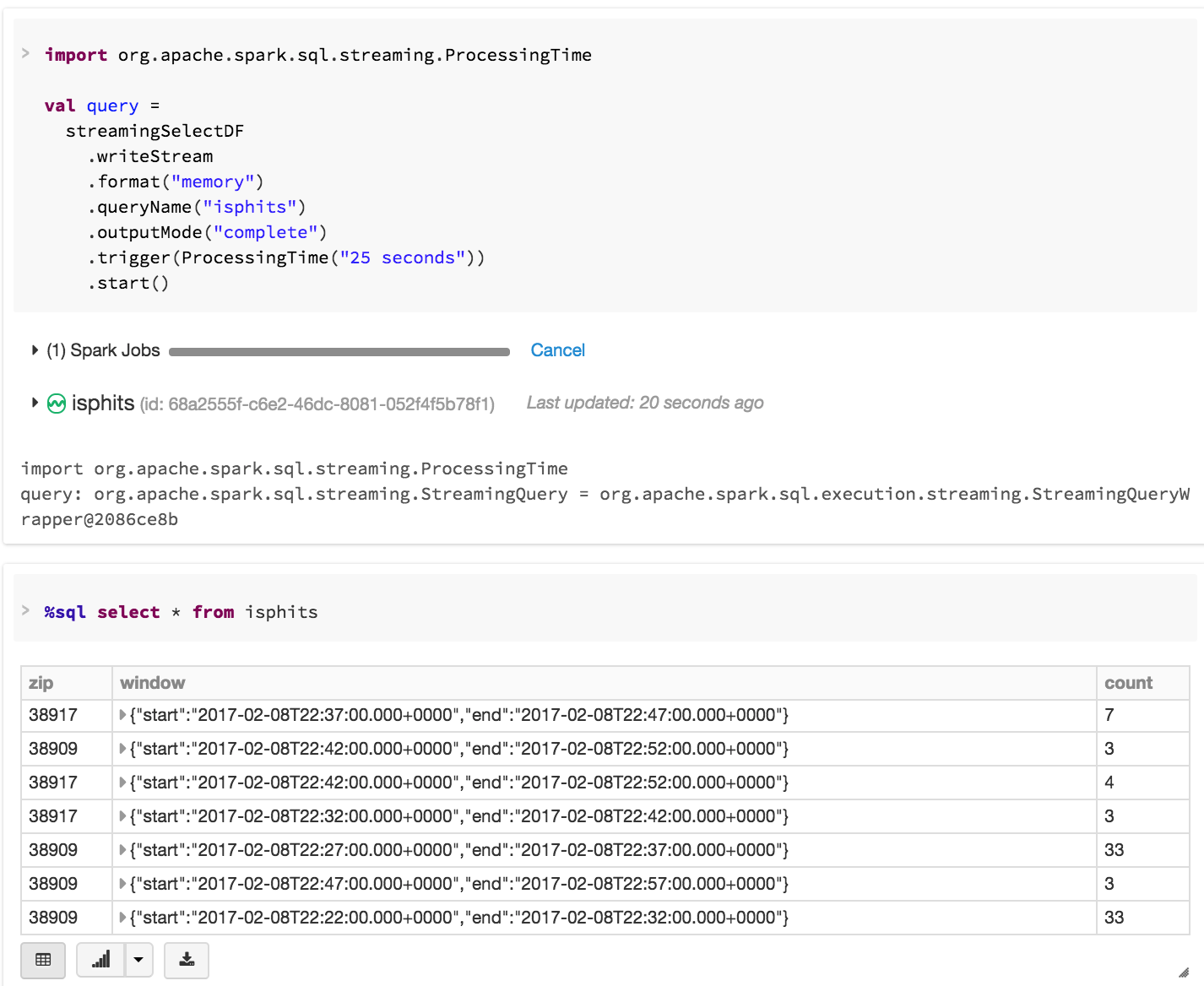
From here, you are now able to do more interesting analysis just as you would on a regular table while the data is automatically being updated.
Console
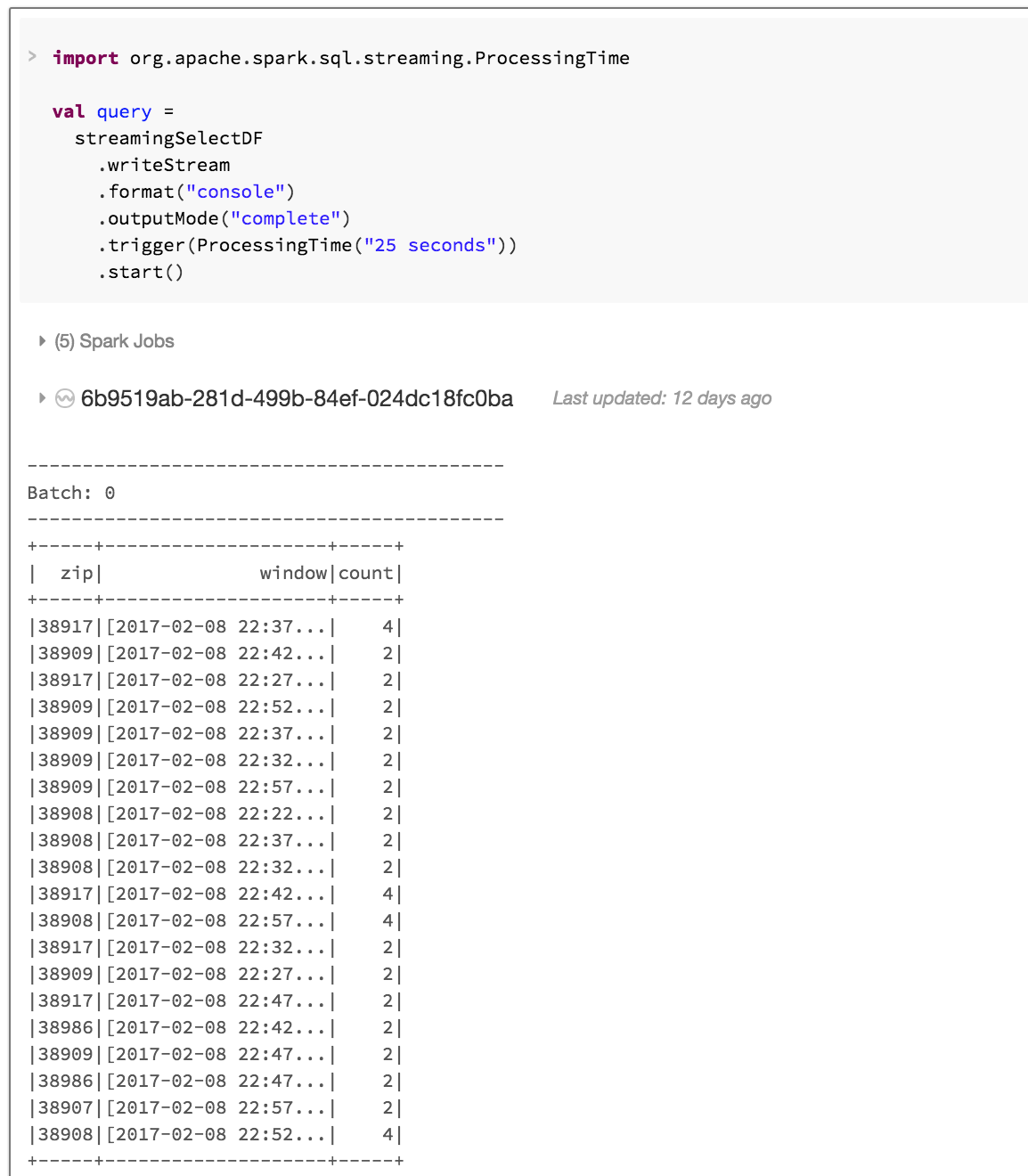
In this scenario, output is printed to console/stdout log.
File
This scenario is ideal for long-term persistence of output. Unlike memory and console sinks, files and directories are fault-tolerant. As such, this option requires a checkpoint directory, where state is maintained for fault-tolerance.

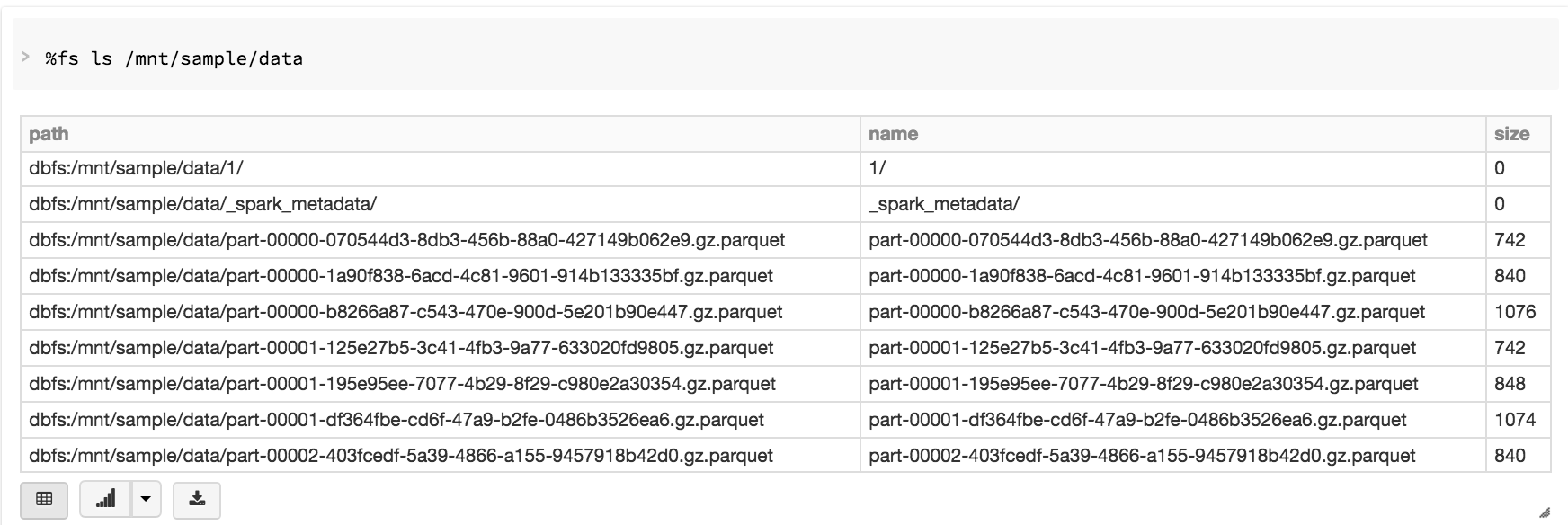
Once the data is saved, it can be queried as one would do in Spark with any other dataset.

The other advantage of file output sinks is that you can dynamically partition incoming messages by any variation of columns. In this particular example, we can partition by ‘zipcode’ and ‘day’. This can help make queries faster as chunks of data could be skipped just by referencing individual partitions.

We could then partition the incoming data by ‘zip’ by ‘day’.

Let’s look at the output directory.
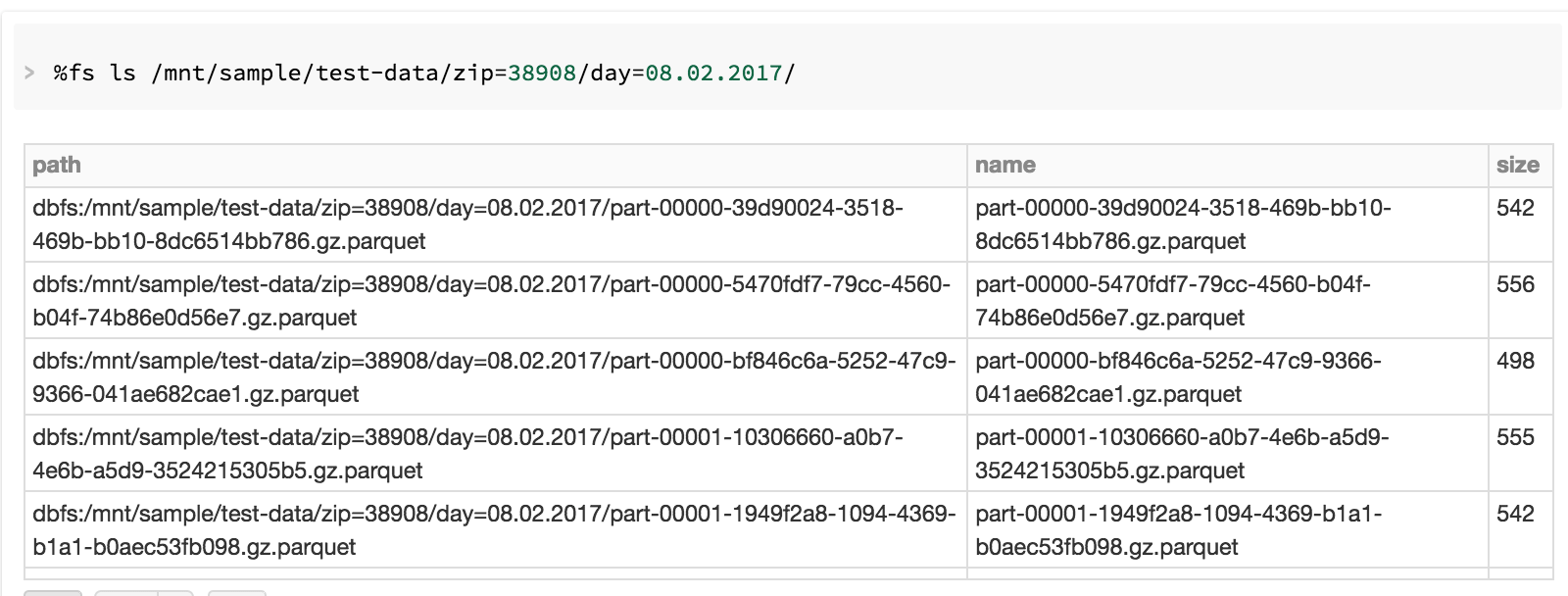
Now, the partitioned data can be used directly in datasets and DataFrames, and if a table is created pointing to the directory where files are written to, Spark SQL can be used to query the data.

The one caveat with this approach is that a partition will have to be added to the table for datasets under it to be accessible.

The partition reference can be pre-populated beforehand so that as files are created in them; they become instantly available.
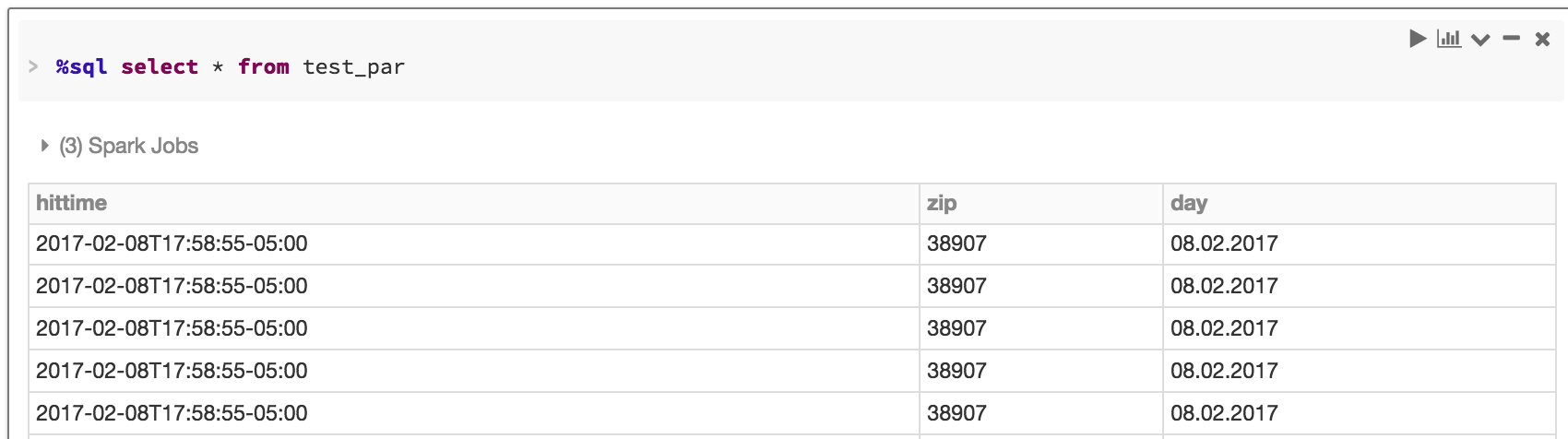
You can now perform analysis on the table that is getting automatically updated while persisting data in the correct partition.
Databases
Often times we want to be able to write output of streams to external databases such as MySQL. At the time of writing, the Structured Streaming API does not support external databases as sinks; however, when it does, the API option will be as simple as .format("jdbc").start("jdbc:mysql/.."). In the meantime, we can use the foreach sink to accomplish this. Let’s create a custom JDBC Sink that extends ForeachWriter and implements its methods.

We can now use the JDBCSink:
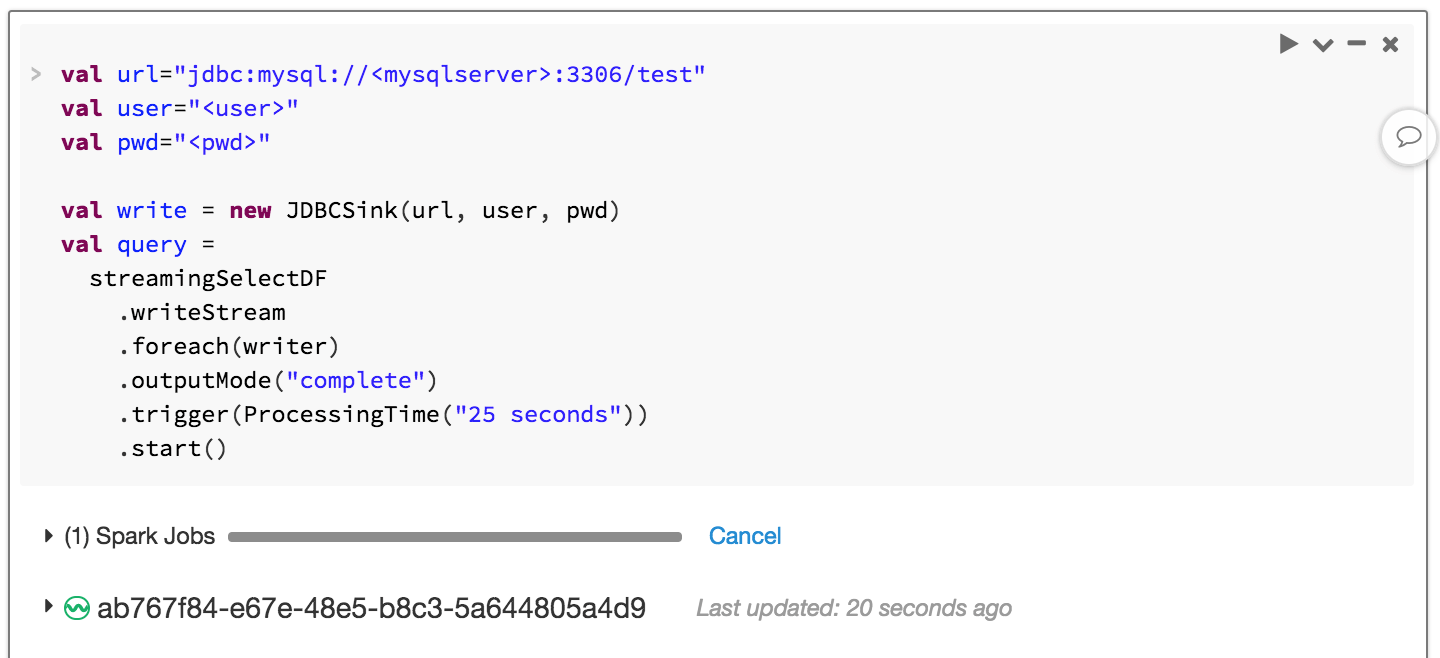
As batches are complete, counts by zip could be INSERTed/UPSERTed into MySQL as needed.

Kafka
Similar to writing to databases, the current Structured Streaming API does not support the “kafka” format, but this will be available in the next version. In the meantime, we can create a custom class named KafkaSink` which extends _ForeachWriter. Let’s see how that looks:

Now we can use the writer:
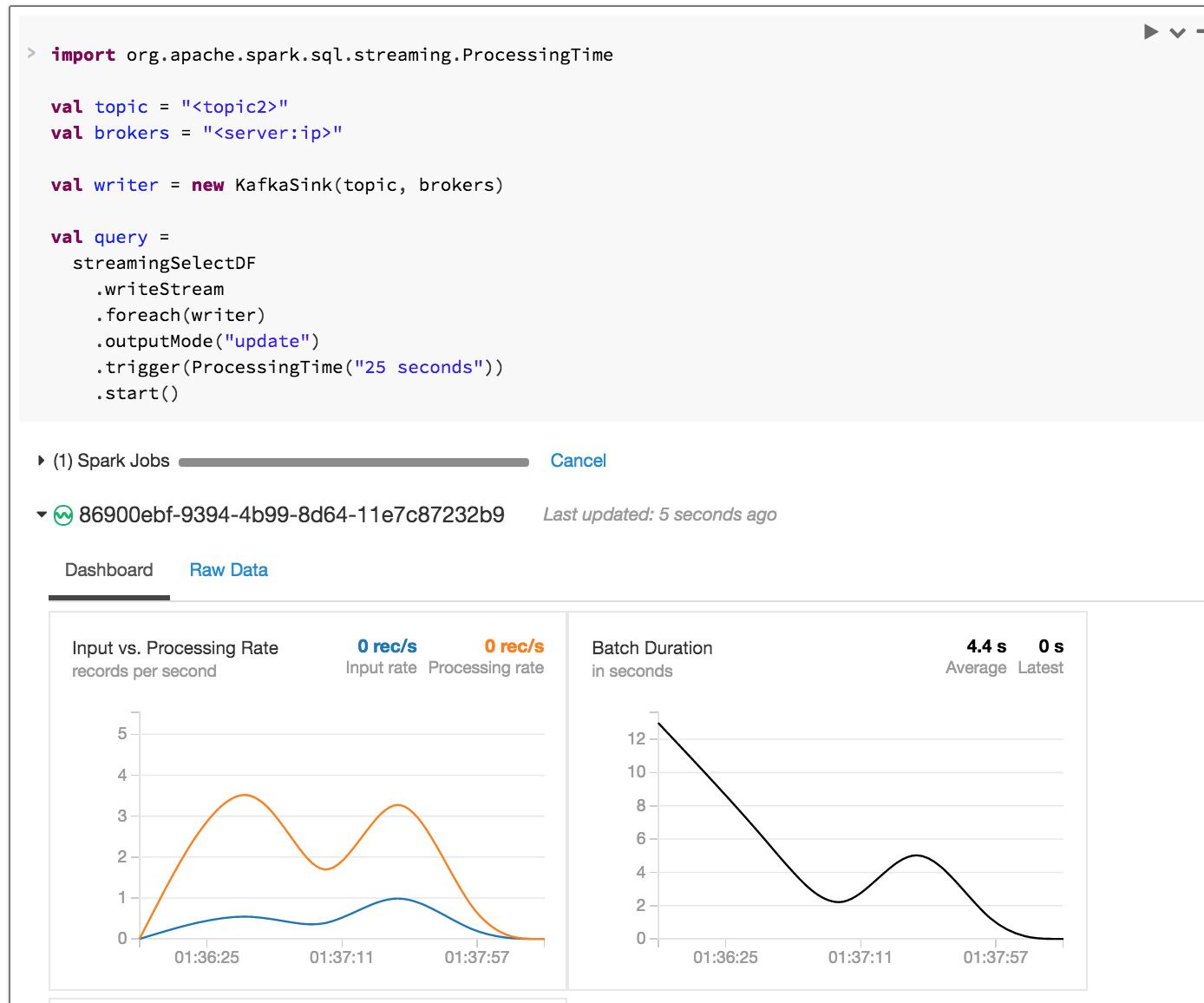
You can now see that we are pumping messages back to Kafka topic zipcode:count at the end of each batch. The other thing to note is that streaming Dashboard provides insights into incoming messages versus processing rate, batch duration and raw data that is used to generate it. This comes in very handy when debugging issues and monitoring system.
On the Kafka consumer side, we can see:

In this case, we are running in “update” output mode. As messages are being consumed, zipcodes that are getting updated during that batch are being pushed back to Kafka. Zipcodes that do not get updated are not being sent. You can also run in “complete” mode, as we did in the database sink above, in which all of the zipcodes with latest count will be sent, even if some of the zipcode counts did not change since the last batch.
Conclusion
At a high level, I covered Structured Streaming integration with Kafka. Also, I showed how you could use various sinks and sources using the APIs. One thing to note is that what we have gone through here is equally relevant to other streams: sockets, directory, etc. For instance, if you wish to consume a socket source and push processed messages to MySQL, the sample here should be able to do just that simply by changing the stream. Also, examples showing ForeachWriter could be used for fanning out writes to multiple downstream systems. I plan to cover deeper insights into fanning out as well as sinks covered here in more detail in subsequent posts.
The example code we used in this blog is available as a Databricks Notebook. You can start experimenting with Structured Streaming today by signing up for a free Databricks Community Edition account. If you have questions, or would like to get started with Databricks, please contact us.
Finally, I encourage you to read our series of blogs on Structured Streaming:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.