Databricks and Apache Spark™ 2017 Year in Review
by Jules Damji
At Databricks we welcome the dawn of the New Year 2018 by reflecting on what we achieved collectively as a company and community in 2017. In this blog, we elaborate on the three themes: unification, expansion, and collaboration.

Year of Unification
Unification has been a pivotal and founding tenet of Apache Spark from its genesis. Not for nothing did Associated Computing Machinery (ACM) confer the team that started the Spark research project at UC Berkeley that later became Apache Spark the best paper award: Apache Spark: A Unified Engine for Big Data Processing. The prescient idea that Spark unifies all workloads with a single high-performant engine back then was an anathema. Conventional wisdom then dictated a separate big data engine for each new kind of data workload: SQL, Streaming, Machine Learning, and Graph processing. Not so for Spark, though. In three ways, Spark dunked the conventional wisdom.
But that notion of unification did not stop with Spark’s first release. In fact, it evolved and spurred Structure in Spark; it engendered unification of Structured Streaming APIs, undergirded by Spark SQL engine, so developers can do a batch and/or streaming computation using a unified high-level DataFrame/Dataset APIs. Most importantly, it provided the bedrock for building and introducing the Unified Analytics Platform: to unify data scientists, engineers, and analysts to work collaboratively, to bring together people and processes, using a single platform.
With the architectural framework for Unified Analytics Platform laid out, building and adding software modular components to augment its capability and capacity for disparate personas became natural. For instance, we introduced Databricks Serverless, a next-generation resource management for Apache Spark, providing auto-configuration, Spark-aware elasticity, and fine-grained resource sharing.
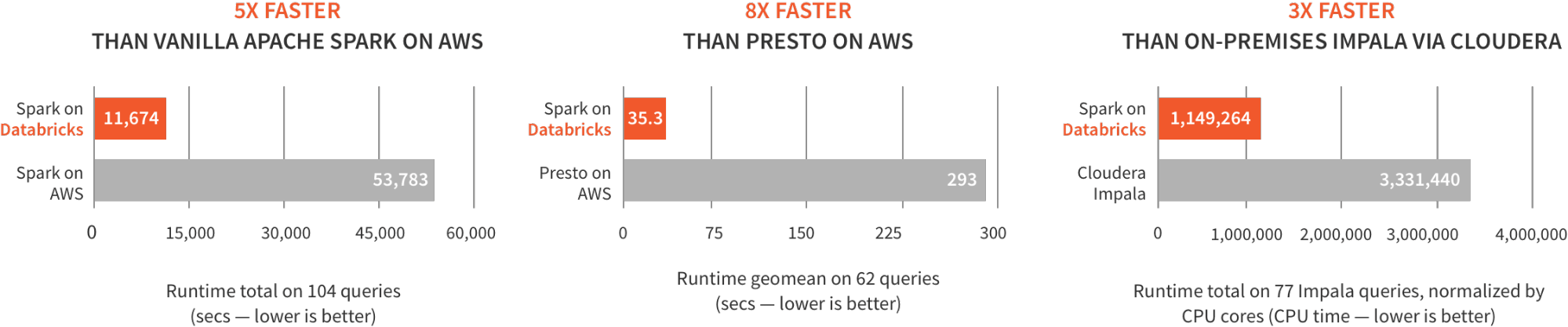
Add to a unified platform a performant and enhanced engine and you get the best of both worlds. For example, to provide the best performance experience to our users, we released Databricks Runtime (DBR), encompassing Databricks I/O (DBIO), Databricks Serverless, and open-source Apache Spark, optimized for the cloud. Running industry standard benchmarks on DBR against big data SQL engines showed us favorably outperform others by 5x, as shown below. Also, our R users benefited from extended capabilities and performance improvements.
Data Lakes and Warehouses Unified with Databricks Delta
Up until now, big data practitioners built scalable data pipelines using a mixture of lambda architectures for processing streaming data, combining or incorporating historical static data through cumbersome and complex ETL processing pipelines. The pipelines then persisted their raw data into data lakes and refined data into multiple warehouses, offering Business Intelligence (BI) tools to conduct ad-hoc queries or generate reports from their siloed warehouses and to serve a specific purpose. Not only are these collective processes complex, brittle, and expensive but they can also introduce inconsistent or invalid data into your data lakes.
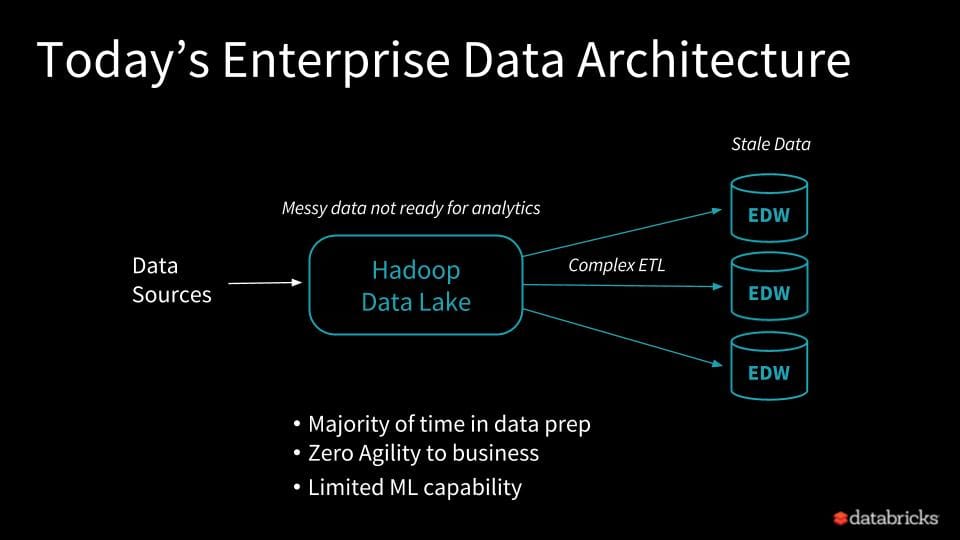
Imagine if you could do away with Data Lakes or Data Warehouses. What if you can simplify today’s enterprise data architecture pipelines for historically static and real-time data analytics and persistence. What form would it take?
Our answer to this data engineering headache is Databricks Delta, a unified data management system. It eliminates the need for complex ETL, data validation, and myriad data warehouses. Instead, as a unified data management system for your historical and real-time data, it offers our users the capacity of data lakes and the reliability of data warehouses, without using either, at streaming latency, all under a single unified platform.
We unveiled this offering as a private preview at Spark Summit EU in Dublin last year as part of our Unified Analytics Platform.
Year of Expansion
Yet the theme of unification is not so much just about unifying software components as much as expanding as a company under a unifying culture. Last summer, we got a financial boost and closed our venture series round D funding of $140 million, bringing our cumulative funding to $250 million.
With this financial shot in the arm, we extended our wings across the pond to EU and embarked upon developing and expanding our products as part of our expansion. Our Amsterdam engineering team now focuses on Apache Spark performance, as the team principally prides itself on engineers with in-depth expertise and experience in building high-performing and scalable distributed systems.

With the Bangalore's Databricks Technology Center, as part of the expansion, we can offer our dynamic enterprise customers a true 24x7 support on a global scale.
Next, the cosmopolitan city of London was not too far off. We expanded in the heart of London, to capitalize on Artificial Intelligence and Machine Learning opportunities in our EMEA headquarters, which is a growing market. The Economist writes: the “two letters [AI] can add up to a lot of money. No area of technology is hotter than AI. Venture-capital investment in AI in the first nine months of 2017 totaled $7.6bn.”
Equally important, we unveiled the availability of Unified Analytics Platform as a first-class service offering on Azure Cloud. Late in the year, we announced a private preview of Azure Databricks at Microsoft Connect. Now Microsoft enterprise customers can seamlessly launch Spark clusters and easily integrate with other Microsoft services for their big data analytics needs.
This was an immense achievement in 2017 as part of our expansion of the scalable Unified Analytics Platform beyond AWS to Azure cloud.
Finally, in the coming year and beyond 2020, we believe that more AI and machine learning real-world applications will permeate many aspects of our lives. The MIT Technology Review avers that “The West shouldn’t fear China’s artificial-intelligence revolution. It should copy it.”
AI has been one of the most exciting new and growing applications of big data and Apache Spark. But AI is not feasible without processing big data at scale. Nor does it catalyze rapid development for developers without making AI development frameworks easier to all. We want to address the “99% versus the 1% problem,” as Databricks’ EMEA VP David Wyatt explains AI has “‘one percent problem’—and how will this affect business.”
And to embrace AI, we renamed and expanded Spark Summit to Spark + AI Summit, to include all aspects of AI.

Year of Community Contributions and Collaboration@>
Last year, the Spark community released Apache Spark 2.2. And at the Spark Summit in San Francisco, we announced two open-source initiatives: Deep Learning Pipelines and production-ready Structured Streaming.
Python big data practitioners were happy that they could simply install PySpark using pip install pyspark, and start hacking away. Other notable community contributions and collaborative efforts were Vectorized UDFs in PySpark and Developing Custom Machine Learning Algorithms in Pyspark.
Lastly, a joint effort between Databricks and Spark community led to the Cost Based Optimizer in Apache Spark 2.2.
Closing Thoughts
That we can achieve so much together is a constant reminder to us that innovation is a result of collaboration, not isolation. That we have continued to innovate with the community affirms our enduring commitment. In that communal spirit, we will continue the year 2018 with the release of Apache Spark 2.3, with contributions both from the Apache Spark community and Databricks.
We will continue to expand and promote Spark community globally. We want to thank the Spark community for the hard work in advocating at Apache Spark Meetups and sharing best practices at big data conferences, some leading to valuable code contributions.
For 2018 and beyond 2020, we foresee Spark playing an integral and unifying role in democratizing AI, with Databricks ensuring that Deep Learning frameworks integrate with Spark and on Databricks’ Unified Analytics Platform.
So embrace and welcome the dawn of the New Year 2018 as we do and ignite your Sparks!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.