Announcing Databricks Runtime 5.4
Databricks is pleased to announce the release of Databricks Runtime 5.4. This release includes Apache Spark 2.4.3 along with several important improvements and bug fixes . We recommend all users upgrade to take advantage of this new runtime release. This blog post gives a brief overview of some of the new high value features that simplify manageability and improve usability in Databricks.
Simplified Manageability
We continue to make advances in Databricks that simplify data and resource management.
Delta Lake Auto Optimize - public preview
Delta Lake is the best place to store and manage data in an open format. We've included a feature in public preview called Auto Optimize that removes administrative overhead by determining optimum file sizes and performing necessary compaction at write time. It's configured as an individual table property and can be added to existing tables. Optimized tables allow you to query those tables efficiently for analytics.
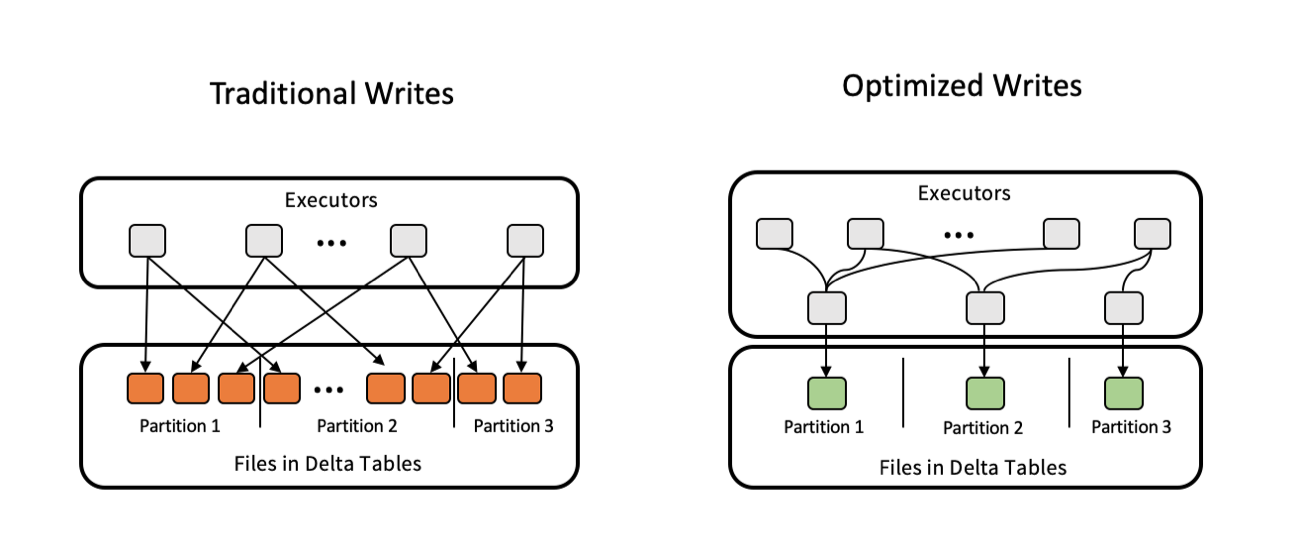
To try out Auto Optimize, consult the Databricks documentation(Azure | AWS).
AWS Glue as the Metastore for Databricks - public preview
We've partnered with the Data Services team at Amazon to bring the Glue Catalog to Databricks. Databricks Runtime can now use Glue as a drop-in replacement for the Hive metastore. This provides several immediate benefits:
- Simplifies manageability by using the same glue catalog across multiple Databricks workspaces.
- Simplifies integrated security by using IAM Role Passthrough for metadata in Glue.
- Provides easier access to metadata across the Amazon stack and access to data catalogued in Glue.
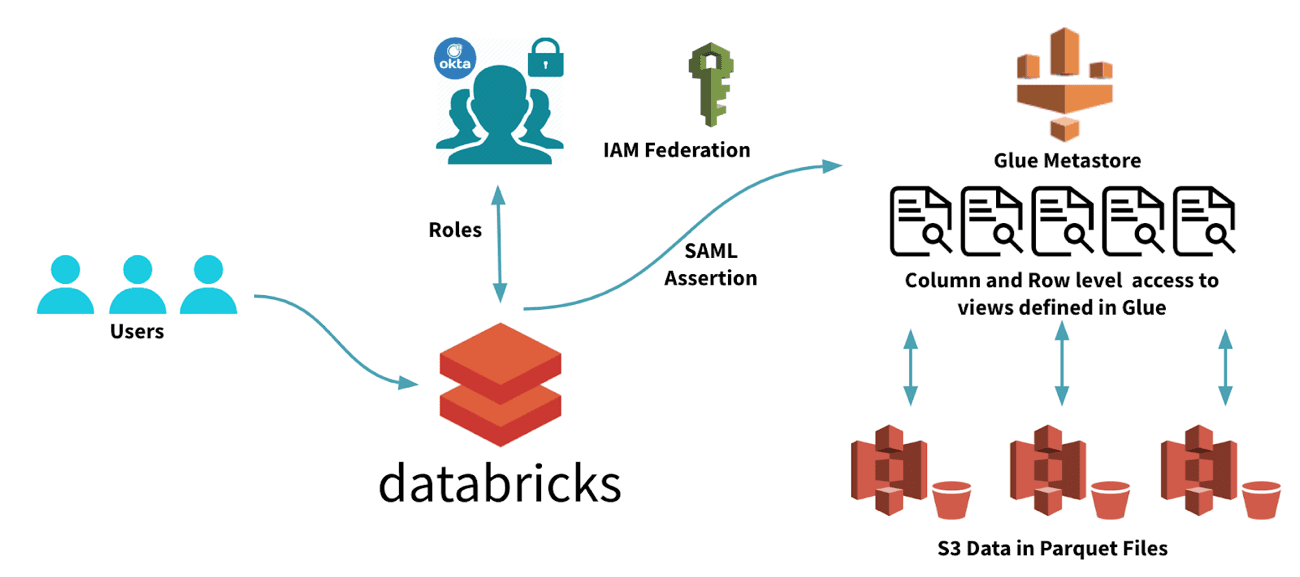
Glue as the metastore is currently in public preview, and to start using this feature please consult the Databricks Documentation for configuration instructions.
Improved Usability
Databricks Runtime 5.4 includes several new features that improve usability.
Databricks Connect - general availability
A popular feature that has enjoyed wide adoption during public preview, Databricks Connect is a framework that makes it possible to develop applications on the Databricks Runtime from anywhere. This enables two primary use cases:
- Connect to Databricks and work interactively through your preferred IDE
- Build applications that connect to Databricks through an SDK
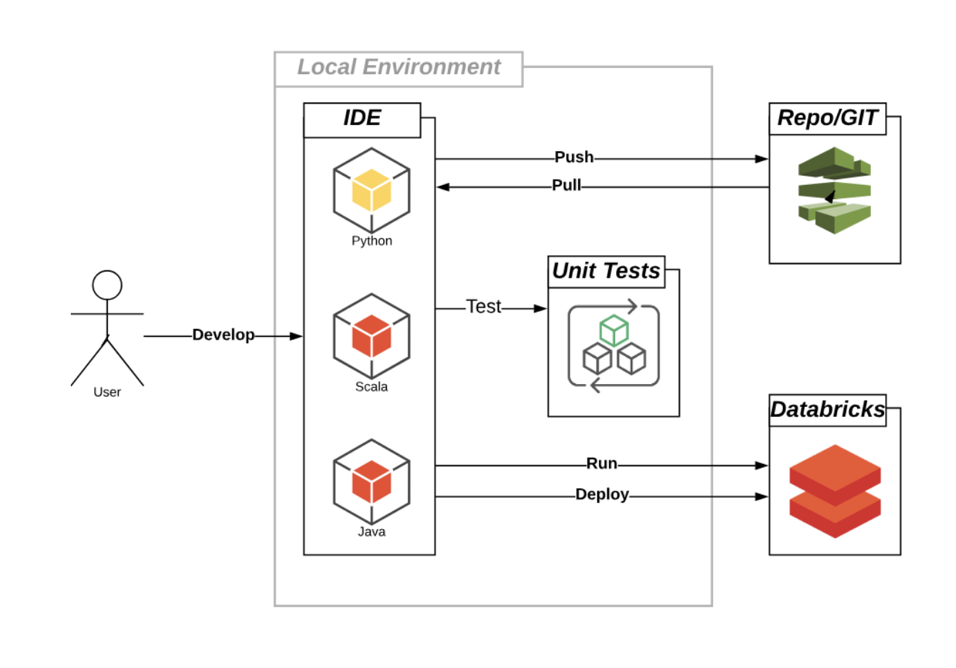
Databricks Connect allows you to:
- Plug into your existing workflows for software development life cycle.
- Check out, and develop locally in your preferred IDE, or notebook environment.
- Run your code on Databricks clusters.
For an in depth description, refer to the Databricks Connect blog post, which goes into further detail. To try out Databricks Connect, refer to the getting started documentation(Azure | AWS).
Databricks Runtime with Conda - beta
Take advantage of the power of Conda for managing Python dependencies inside Databricks. Conda has become the package and environment management tool of choice in the data science community and we're excited to bring this capability to Databricks. Conda is especially well suited for ML Workloads, and Databricks Runtime with Conda lets you create and manage Python environments from within the scope of a user session. We provide two simplified Databricks Runtime pathways to get started:
- databricks-standard environment includes updated versions of many popular Python packages. This environment is intended as a drop-in replacement for existing notebooks that run on Databricks Runtime. This is the default Databricks Conda-based runtime environment.
- databricks-minimal environment contains a minimum number of packages that are required for PySpark and Databricks Python notebook functionality. This environment is ideal if you want to customize the runtime with various Python packages.
For more in depth information, visit the blog post introducing Databricks Runtime with Conda. To get started, refer to the Databricks Runtime with Conda documentation(Azure | AWS).
Library Utilities - general availability
Databricks Library Utilities enable you to manage Python dependencies within the scope of a single user session. You can add, remove, and update libraries and switch Python environments (if using our new Databricks Runtime with Conda) all from within the scope of a session. When you disconnect, the session is not persisted and is garbage collected and resources are freed up for future user sessions. This has several important benefits:
- Install libraries when and where they’re needed, from within a notebook. This eliminates the need to globally install libraries on a cluster before you can attach a notebook that requires those libraries.
- Notebooks are completely portable between clusters.
- Library environments are scoped to individual sessions. Multiple notebooks using different versions of a particular library can be attached to a cluster without interference.
- Different users on the same cluster can add and remove dependencies without affecting other users. You don’t need to restart your cluster to reinstall libraries.
For an in depth example visit the blog post Introducing Library Utilities. For further information, refer to Library Utilities in the Databricks documentation(Azure | AWS).
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.