Migrating Transactional Data to a Delta Lake using AWS DMS
Simplify big data pipelines for Change Data Capture (CDC) using AWS Database Migration Services (DMS) and Delta Lakes
Try this notebook in Databricks
Note: We also recommend you read Efficient Upserts into Data Lakes with Databricks Delta which explains the use of MERGE command to do efficient upserts and deletes.
Challenges with moving data from databases to data lakes
Large enterprises are moving transactional data from scattered data marts in heterogeneous locations to a centralized data lake. Business data is increasingly being consolidated in a data lake to eliminate silos, gain insights and build AI data products. However, building data lakes from a wide variety of continuously changing transactional databases and keeping data lakes up to date is extremely complex and can be an operational nightmare.
Traditional solutions using vendor-specific CDC tools or Apache SparkTM direct JDBC ingest are not practical in typical customer scenarios represented below:
(a) Data sources are usually spread across on-prem servers and the cloud with tens of data sources and thousands of tables from databases such as PostgreSQL, Oracle, and MySQL databases
(b) Business SLA for change data captured in the data lake is within 15 mins
(c) Data occurs with varying degrees of ownership and network topologies for Database connectivity.
In scenarios such as the above, building a data lake using Delta Lake and AWS Database Migration Services (DMS) to migrate historical and real-time transactional data proves to be an excellent solution. This blog post walks through an alternate easy process for building reliable data lakes using AWS Database Migration Service (AWS DMS) and Delta Lake, bringing data from multiple RDBMS data sources. You can then use the Databricks Unified Analytics Platform to do advanced analytics on real-time and historical data.
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
What is Delta Lake?
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Specifically, Delta Lake offers:
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark's distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts with Managed Delta Lake on Databricks (also coming soon to the open source Delta Lake): The MERGE command allows you to efficiently upsert and delete records in your data lakes. MERGE dramatically simplifies how a number of common data pipelines can be built; all the complicated multi-hop processes that inefficiently rewrote entire partitions can now be replaced by simple MERGE queries. This finer-grained update capability simplifies how you build your big data pipelines for change data capture from AWS DMS changelogs.
What is AWS Database Migration Service (DMS)?
AWS DMS can migrate your data from the most widely used commercial and open-source databases to S3 for both migrations of existing data and changing data. The service supports migrations from different database platforms, such as Oracle to Amazon Aurora or Microsoft SQL Server to MySQL. With AWS Database Migration Service, you can continuously replicate your data with high availability and consolidate databases by streaming data to Amazon S3 from any of the supported sources.
Migrating data into a Delta Lake using AWS Database Migration Services
Assume that you have a "person" table built on a MySQL database that holds data for the application user records with the columns shown. The table is updated whenever a person moves, a new person gets added and an existing person may be deleted. We will ingest this table using AWS DMS into S3 and then load it using Delta Lake to showcase an example of ingesting and keeping the data lake in sync with the transactional data stores. We will demonstrate change data capture to this table in MySQL and use AWS DMS to replicate changes into S3 and easily merge into the data lake built using Delta Lake.

Architecture
In this solution, we will use DMS to bring the data sources into Amazon S3 for the initial ingest and continuous updates. We load initial data from S3 into a Delta Lake table, and then use Delta Lake's upserts capability to capture the changes into the Delta Lake table. We will run analytics on Delta Lake table that is in sync with the original sources to gain business insights. The following diagram demonstrates the proposed solution:

After the data is available on Delta Lake, you can easily use dashboards or BI tools to generate intelligent reports to gain insights. You can also take this a step further and use the data to build ML models with Databricks.
Solution Details
For the purposes of this post, we create an RDS database with a MySQL engine then load some data. In real life, there may be more than a single source database; the process described in this post would still be similar.
Follow the steps in Tutorial: Create a Web Server and an Amazon RDS Database to create the source database. Use the links from the main tutorial page to see how to connect to specific databases and load data. For more information, see: Creating a DB Instance Running the MySQL Database Engine
Make a note of the security group that you create and associate all the RDS instances with it. Call it "TestRDSSecurityGroup". Afterward, you should be able to see the database listed in the RDS Instances dashboard.

Setup Target S3 buckets
Set up two S3 buckets as shown below, one for batch initial load and another for incremental change data capture.

In the next step, choose Publicly Accessible for non-production usage to keep the configuration simple. Also, for simplicity, choose the same VPC where you have placed the RDS instances and include the TestRDSSecurityGroup in the list of security groups allowed to access.
Setup up DMS
You can set up DMS easily, as indicated in the AWS Database Migration Service blog post. You may take the following step-by-step approach:
- Create a replication instance.
- Create the endpoints for the source database and the target S3 buckets you set up in the previous step .
- Create a task to synchronize each of the sources to the target.
Create endpoints
In the DMS console, choose Endpoints, Create endpoint. You need to configure the endpoint representing the MySQL RDS database. You also need to create the target endpoint by supplying the S3 buckets that you created in the previous steps. After configuration, the endpoints look similar to the following screenshot:
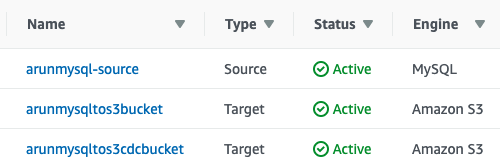
Create two tasks and start data migration
You can rely on DMS to migrate table(s) in your target Amazon S3 buckets
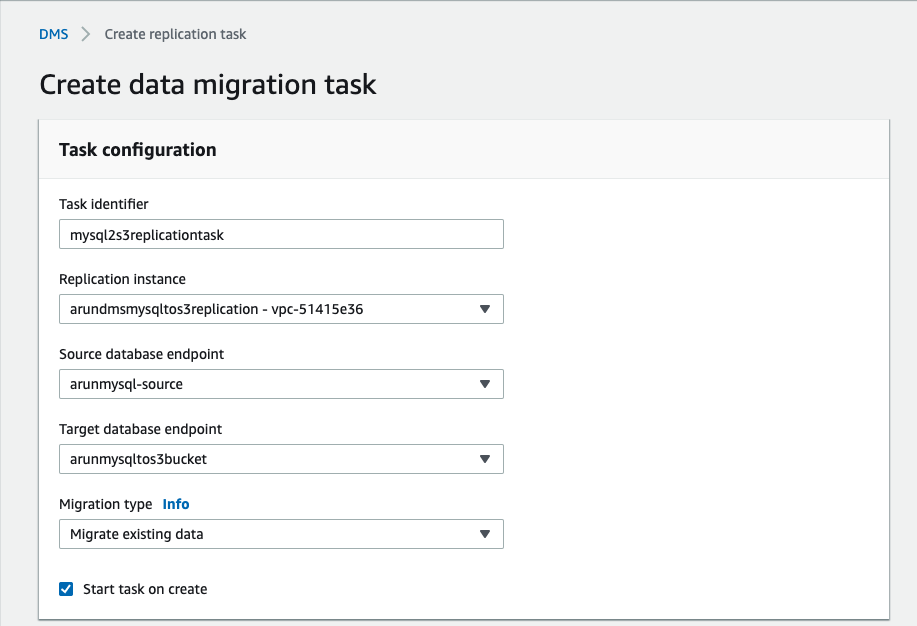
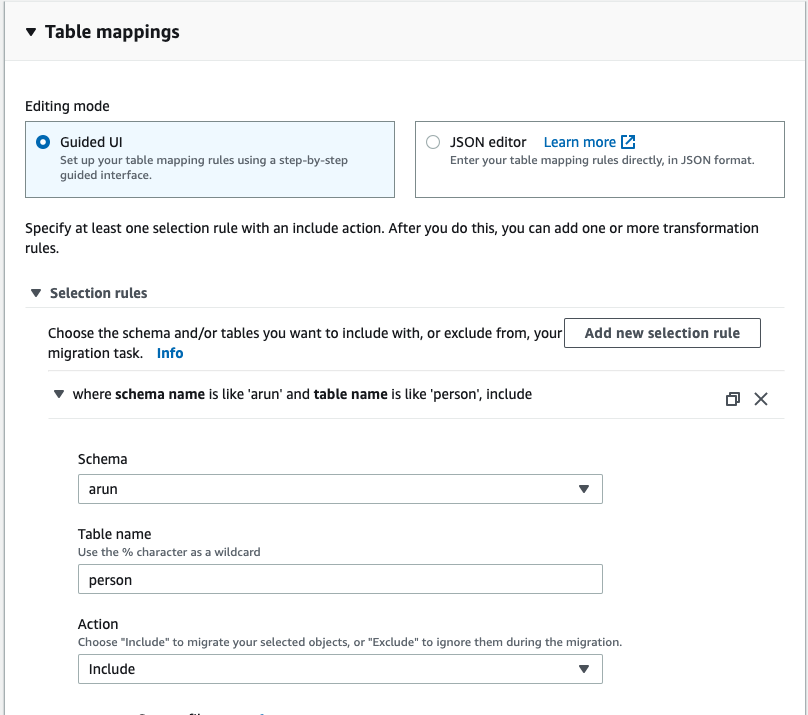
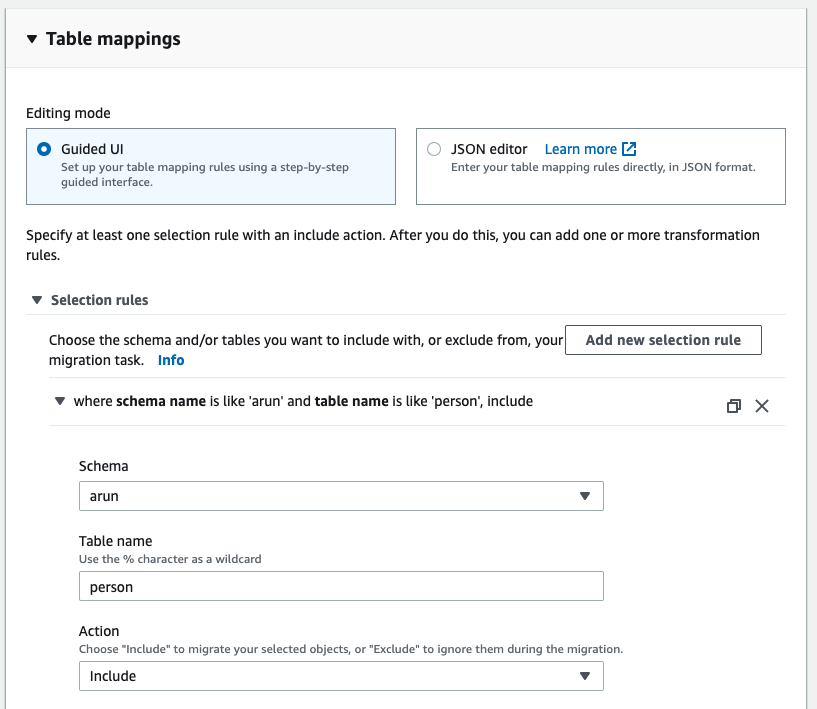
In the DMS console, choose Tasks, Create Tasks. Fill in the fields as shown in the following screenshot:
- Migration Task for Initial Load:
- Migration Task for CDC:
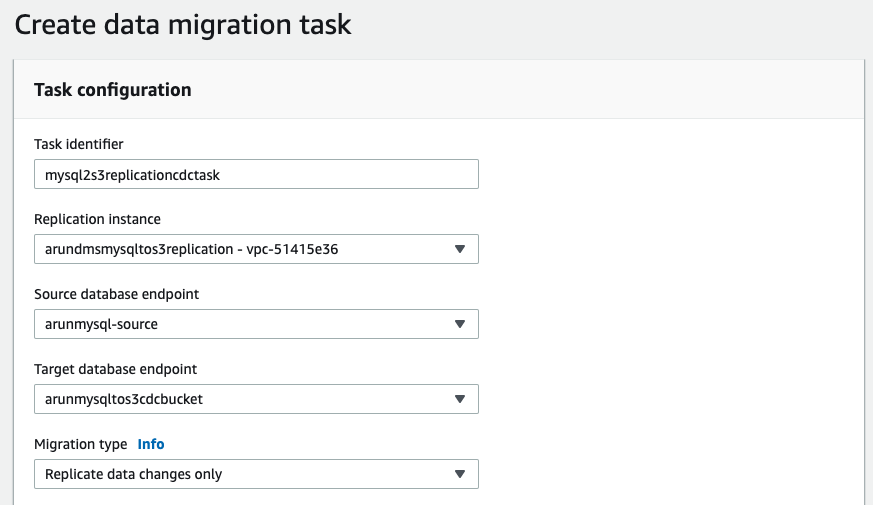
Note that given the source is RDS MySQL and you chose to migrate data and replicate ongoing changes, you need to enable bin log retention. Other engines have other requirements and DMS prompts you accordingly. For this particular case, run the following command:
call mysql.rds_set_configuration('binlog retention hours', 24);
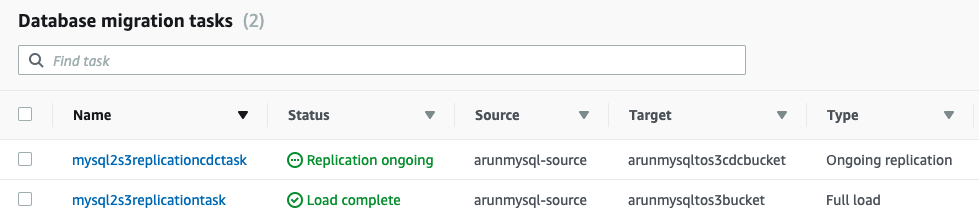
After both tasks have successfully completed, the Tasks tab now looks like the following:
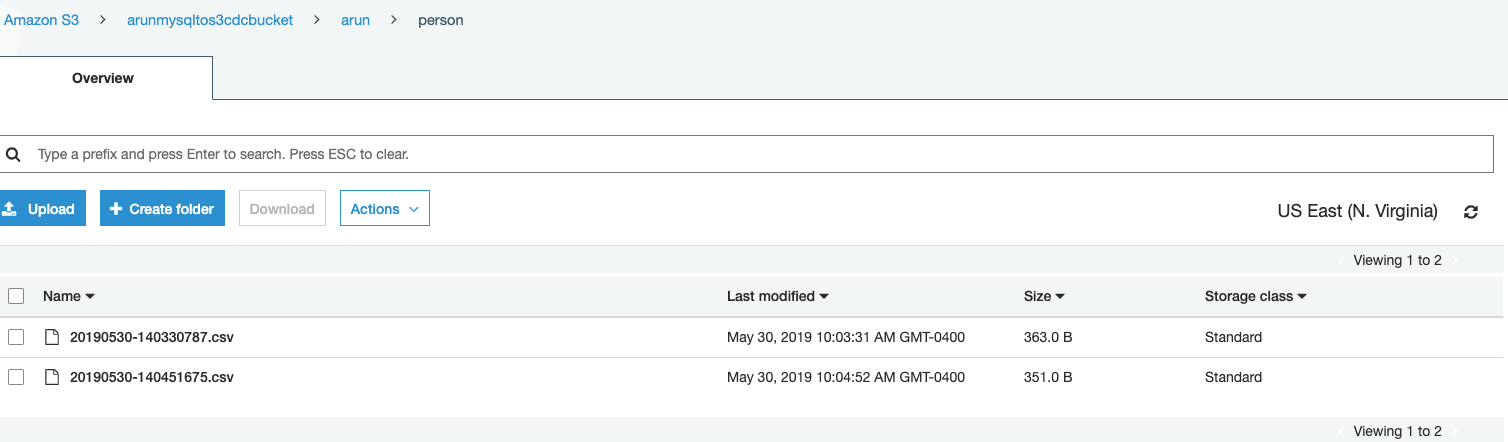
Ensure that data migration is working:
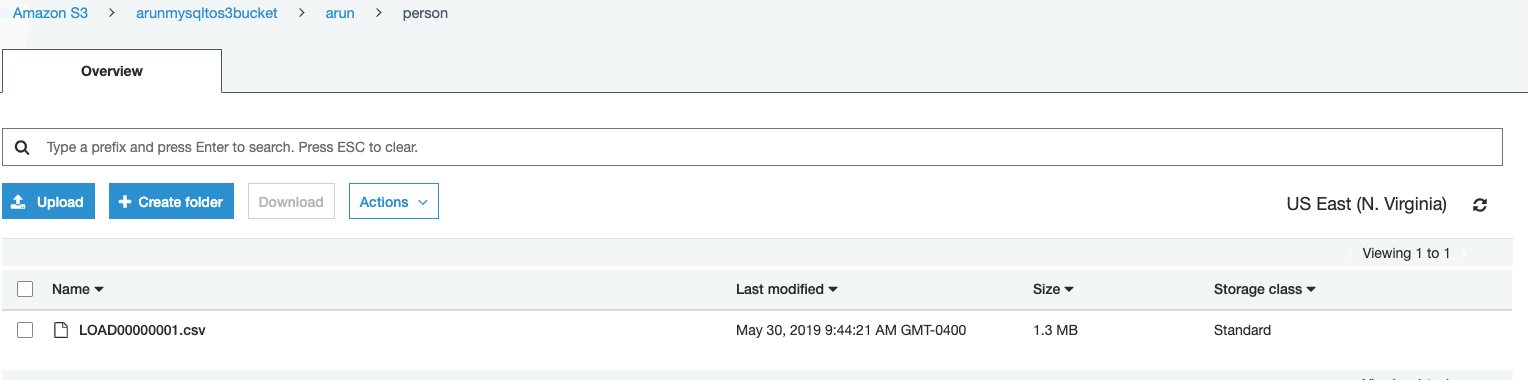
- Check that initial data is loaded to S3 bucket:
Example Row:

INSERT into person(id,first_name,last_name,email,gender,dob,address,city,state) values ('1001','Arun','Pamulapati','cadhamsrs@umich.edu','Female','1959-05-03','4604 Delaware Junction','Gastonia','NC'); UPDATE person set state = 'MD' where id=1000; DELETE from person where id = 998; UPDATE person set state = 'CA' where id=1000;

Load initial migration data into Delta Lake
We will be creating Delta Lake table from the initial load file , you can use Spark SQL code and change the format from parquet, csv, json, and so on, to delta. For all file types, you read the files into a DataFrame and write out in delta format:
personDF = spark.read.option("Header",True).option("InferSchema",True).csv("/mnt/%s/arun/person/" % initialoadMountName) personDF.write.format("delta").save("/delta/person")spark.sql("CREATE TABLE person USING DELTA LOCATION '/delta/person/'")
Merge incremental data into Delta Lake
We will be using Delta merge into capability to capture change logs into Delta Lake.
personChangesDF = (spark.read.csv("dbfs:/mnt/%s/arun/person" % changesMountName, inferSchema=True, header=True, ignoreLeadingWhiteSpace=True, ignoreTrailingWhiteSpace=True)) personChangesDF.registerTempTable("person_changes") MERGE INTO person target USING (SELECT Op,latest_changes.id,first_name,last_name,email,gender,dob,address,city,state,create_date,last_update FROM person_changes latest_changes INNER JOIN ( SELECT id, max(last_update) AS MaxDate FROM person_changes GROUP BY id ) cm ON latest_changes.id = cm.id AND latest_changes.last_update = cm.MaxDate) as source ON source.id == target.id WHEN MATCHED AND source.Op = 'D' THEN DELETE WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *

Note:
1) You can use Databricks Jobs functionality to schedule CDC merges based on your SLAs and move the changelogs from cdc S3 bucket to an archive bucket after a successful merge to keep your merge payload to most recent and small. A job in Databricks platform is a way of running a notebook or JAR either immediately or on a scheduled basis. You can create and run jobs using the UI, the CLI, and by invoking the Jobs API. Similarly, you can monitor job run results in the UI, using the CLI, by querying the API, and through email alerts.
2) For a performant initial load of large tables prefer to take advantage of Spark native parallelism using JDBC reads or employ DMS best practices to use AWS Database Migration Service (AWS DMS) most effectively.
Conclusion build a simpler data pipeline and a reliable Delta Lake
In this post, we showed the use of Delta Lake to ingest and incrementally capture changes from RDBMS data source using AWS DMS to build easy, reliable, and economical data lakes with simple configuration and minimal code. You also used Databricks notebooks to create a data visualization on the dataset to provide you with additional insights.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.