Strategies for Modernizing Investment Data Platforms
The appetite for investment was at a historic high in 2020 for both individual and institutional investors. One study showed that "retail traders make up nearly 25% of the stock market following COVID-driven volatility". Moreover, institutional investors have piled on investments in cryptocurrency, with 36% invested in cryptocurrency, as outlined in Business Insider . As investors gain access to and trade alternative assets such as cryptocurrency, trading volumes have skyrocketed and created new data challenges. Moreover, cutting edge research is no longer restricted to institutional investors on Wall Street -- today's world of investing extends to digital exchanges in Silicon Valley, data-centric market makers, and retail brokers that are investing increasingly in AI-powered tools for investors. Data lakes have become standard for building financial data products and research, but they come with a unique set of challenges:
- Lack of blueprints for how to build an enterprise data lake in the cloud
- Organizations are still struggling to guarantee both reliability and timeliness of their data, leading to sub-optimal processes and diluted insights
As a result, scalable AI (such as volatility forecasting) is difficult to achieve due to high maintenance costs and the lack of a blueprint for scale and hence trading profitability. As part of our suggested blueprint, we recommend standardization on Delta Lake, which is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads. A table in Delta Lake is both a batch table, as well as a streaming source and sink. Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box. In particular, since raw market data is delivered in real-time and must be used in near real-time to support trading decisions, Delta Lake is critical to support trading use cases.
This blog has 2 main sections. The first covers detailed options for landing financial market data into Delta Lake. The second section covers a blueprint for productionalizing use cases such as financial product volatility forecasting as well as market surveillance on Delta Lake. Notably, as part of the use cases, we introduce an open-source time-series package developed as part of Databricks Labs, which helps build the foundation for the use cases above.
How to build a market Delta Lake
In this blog, through a series of design patterns and real-world examples, we will address the data challenges from the previous section. As a visual guide, the reference architecture below will be the basis for how to build out data lake sources and curate datasets for end reporting, trading summaries, and market surveillance alerts.
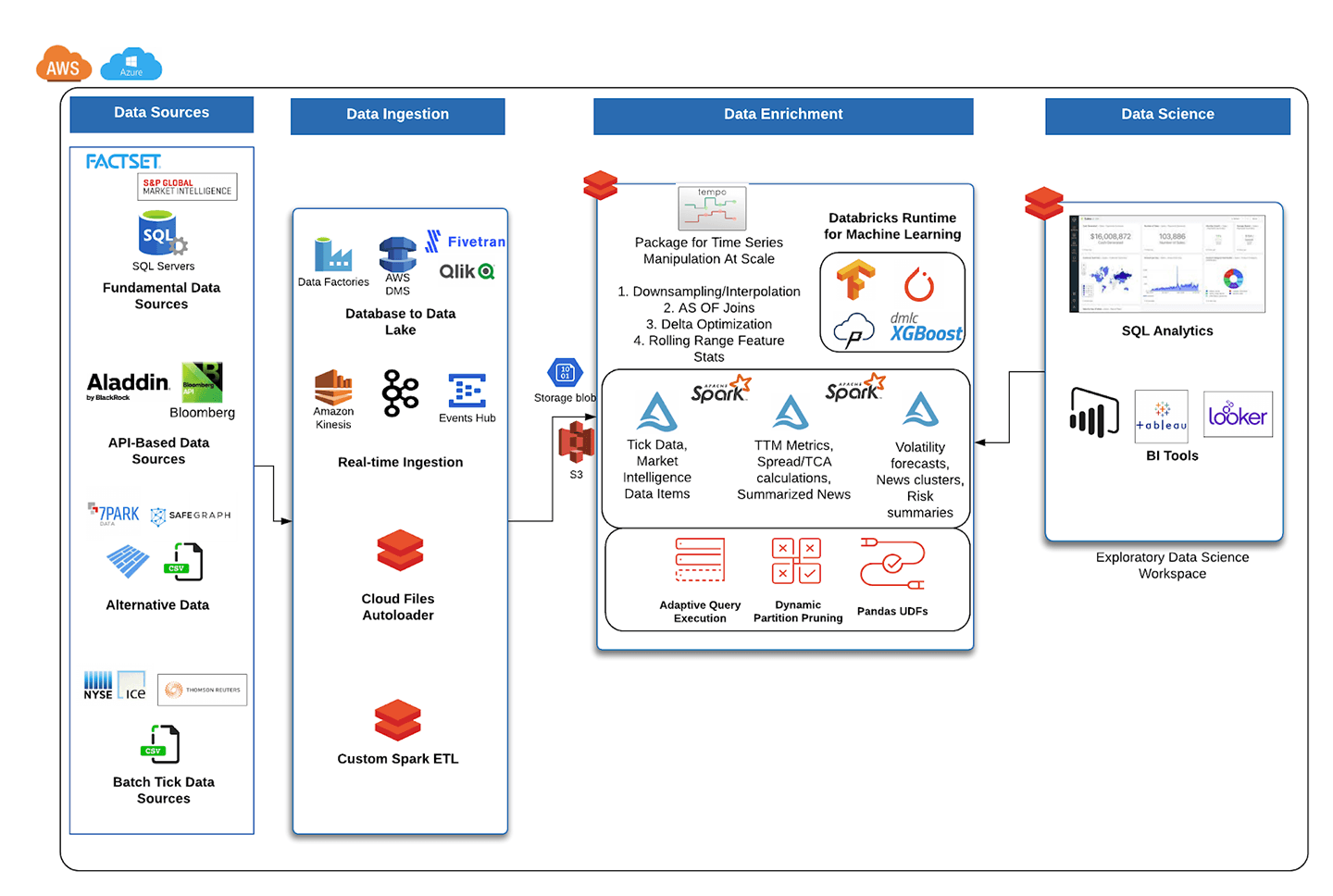
Fundamental data source ingestion
Fundamental data, (positioned at the top left in Figure 1) loosely defined as economic and financial factors used to measure a company's intrinsic value, is available today from most financial data vendors. Two of the most common sources include Factset and S&P Market Intelligence Platform. Both of these sources make data available via FTP, API, and a SQL Server database. Since data is available via a database for factor analysis, there are three easy options for ingestion into Delta Lake:
Option 1 - Partner ingestion network
Databricks has partnered with six companies which make up the "Data Ingestion Network of Partners." Our partners have capabilities to ingest data from a variety of sources, including FTP, CRMs, marketing sources, and database sources. Since financial vendors allow financial clients to host databases, our partner tools can be used to pull out data to store directly in Delta Lake. Full documentation on how to ingest using this network and a listing of partners is located at Databricks' documentation, Partner data integrations.
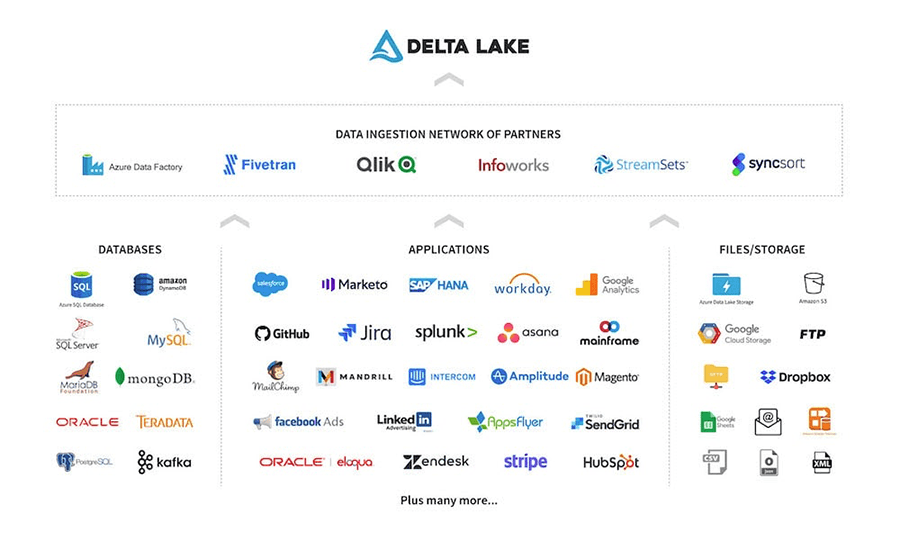
Option 2 - Use native cloud-based ingestion tools
Cloud service providers also have existing tools for database replication into Delta Lake. Below are two options for ingesting from databases (on-prem or cloud) into Delta Lake.
AWS
AWS offers a solution, Database Migration Services, which allows organizations to set up a Change Data Capture (CDC) process to replicate database changes to cloud data lakes. We outlined a specific method for replicating database changes to Delta Lake in our blog, "Migrating Transactional Data to a Delta Lake using AWS DMS." Since Xpressfeed S&P data, for example, has hundreds of sources, ranging from ESG risk scores and alternative data to fundamental earnings and news sentiment datasets, an automated way to replicate these to Delta Lake is critical. The AWS solution mentioned above provides a simple way to set this up.
Azure
One of Azure's most popular services is Azure Data Factory (ADF) and with good reason. ADF allows copying from many different data sources, including databases, FTP and even cross-cloud sources such as BigQuery. In particular, there are two methods of writing data to Delta Lake from a SQL database:
- ADF offers a simple 'Copy To' factory that simply copies database tables to blob storage (Blob or ADLS Gen2), and Delta Lake is a valid target table for this copy functionality.
- For a more customized transformation from a database to Delta Lake, ADF is flexible enough to read all tables from a database using an information schema as shown here. From here, one can simply configure a Databricks notebook which uses the input table name from the information schema and copies each table by executing a Databricks notebook which reads from the database using JDBC. Examples are here.
API-based data source ingestion
Bloomberg is one of the industry standards for market data, reference data, and hundreds of other feeds. In order to show an example of API-based ingestion (middle left in Figure 1) from a Bloomberg data subscription, the B-PIPE (Bloomberg data API for accessing market data sources) emulator will be used. The Java market data subscription client code in the original emulator has been modified in the code below to publish events into a Kinesis real-time stream using the AWS SDK.
Write B-PIPE market data to streaming service
Write data from Kinesis stream to Delta Lake
Transform and read records

Tick data source ingestion
Tick data (positioned in bottom left of Figure 1), which is the general term for high resolution intraday market data, typically comes from data vendors as batch sources in CSV, JSON or binary formats. Types of tick data include trade, quote, and contracts data, and an example of delivery is the tick data history service offered by Thomson Reuters. The easiest way to continuously land data into Delta Lake from these sources is to set up the Databricks autoloader to read from a bucket and redirect data into a separate Delta Lake table. From here, various ETL processes might curate each message type into refined or aggregated Delta tables. The benefits of autoloader are twofold:
- Reliability and Performance inherited from Delta Lake
- Lower costs due to underlying use of SQS (AWS ) or AQS (Azure) to avoid re-listing input files as well as a managed checkpoint to avoid manual selection of the most current unread files.
From Delta Lake to financial services use case productionization
Beyond the data collection challenges that surface when building any data platform, investment management firms increasingly need to address the incorporation of AI into product suites, as well as managing costs for feature engineering. In particular:
- Both retail and institutional investment firms need to also be able to query and run ETL on data lakes in a cost-effective manner and minimize the amount of maintenance costs associated with enriching and querying data lakes.
- Retail investors expect AI-powered offerings and insights in subscriptions. The optimal solution will host the AI infrastructure in such a way that users can create AI-powered applications and dashboards where time spent on the setup of libraries and elastic compute infrastructure is minimized, and the underlying processing can be scaled to billions of data points that come in daily from transactional data sources (customer transactions and tick quotes alike).
Now that we've presented reliable, efficient approaches for landing financial datasets into a cloud data lake, we want to address some of the existing gaps between financial datasets in the cloud and AI-powered products.
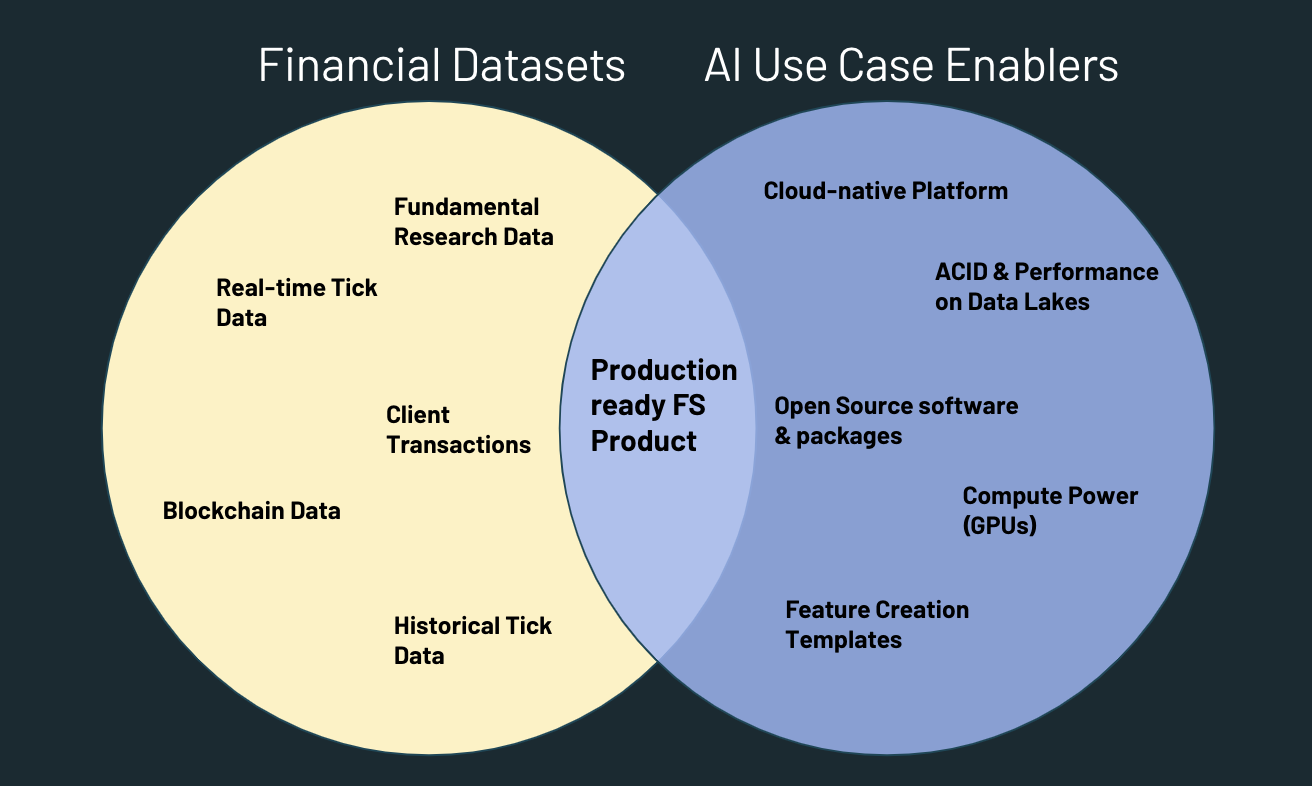
The image above shows how datasets and siloed infrastructure are not enough to deliver investment analysis products in production. Most FSIs have adopted nearly all of the AI use case enablers on the right-hand side but have failed to maximize the volume-weighted overlap of these with core datasets. The Databricks Unified Data Analytics Platform subsumes the first four AI use case enablers out of the box. To make productionization more concrete, we'll show how to use a new Databricks open-sourced package tempo for manipulating time series at scale. Then we'll dive into the following use case feature creation templates which use tempo and show how to get the best of both worlds in the Venn diagram above.
- Retail investing details using fundamental data to inform daily volatility predictions.
- Market surveillance details a process for summarizing price improvement and detecting spoofing.
Tempo - Time Series Package
In financial services, time series are ubiquitous, and we find that our customers struggle with manipulating time series at scale. In the past, we have outlined a few approaches to scaling time-series queries. Now, Databricks Labs has released a simple common set of time-series utilities to make time-series processing simpler in an open-source package called tempo. This package contains utilities to do the following:
- AS OF joins to merge up to millions of irregular time series together
- Feature creation with rolling aggregations of existing metrics
- Optimized writes to Delta Lake ideal for ad-hoc time-series queries
- Volume-weighted average price (VWAP) calculations
- Resampling
- Exponential Moving Average calculations
By combining the versatile nature of tick data, reliable data pipelines and open source software like tempo, organizations can unlock exponential value from a variety of use cases at minimal costs and fast execution cycles. The next section walks through two recurring themes in capital markets which utilize tempo: volatility forecasting and market surveillance.
Volatility forecasting methodology with fundamental and technical data
S&P Global Market Intelligence provides fundamental data that can be ingested using a mechanism called Xpressfeed (covered earlier in this guide). Some important points about this feed are that:
- It covers thousands of fundamental data metrics
- It covers hundreds of thousands of globally listed and unlisted equities
- Reporting frequency is daily – there is a filing date that can be used for point-in-time analyses
Although we do not cover the curation process for the tick ETL (contact Databricks sales for more information on this use case), we outline the processing from standard tick formats to a final forecasting object using the tempo library; our implementation is in the links reported in the bottom of this blog. The high-level details are as follows:
- Create Point-in-time Calendar - Merge the latest fundamental data onto the latest calendar date using the filing date (fundamental data point filing date as of trade date). Commonly referred to as AS-OF join, this operation is usually expensive and subject to technical bottlenecks in a highly imbalanced dataset. tempo will guarantee this operation to be evenly distributed to leverage at best the cloud elasticity (and its associated costs).
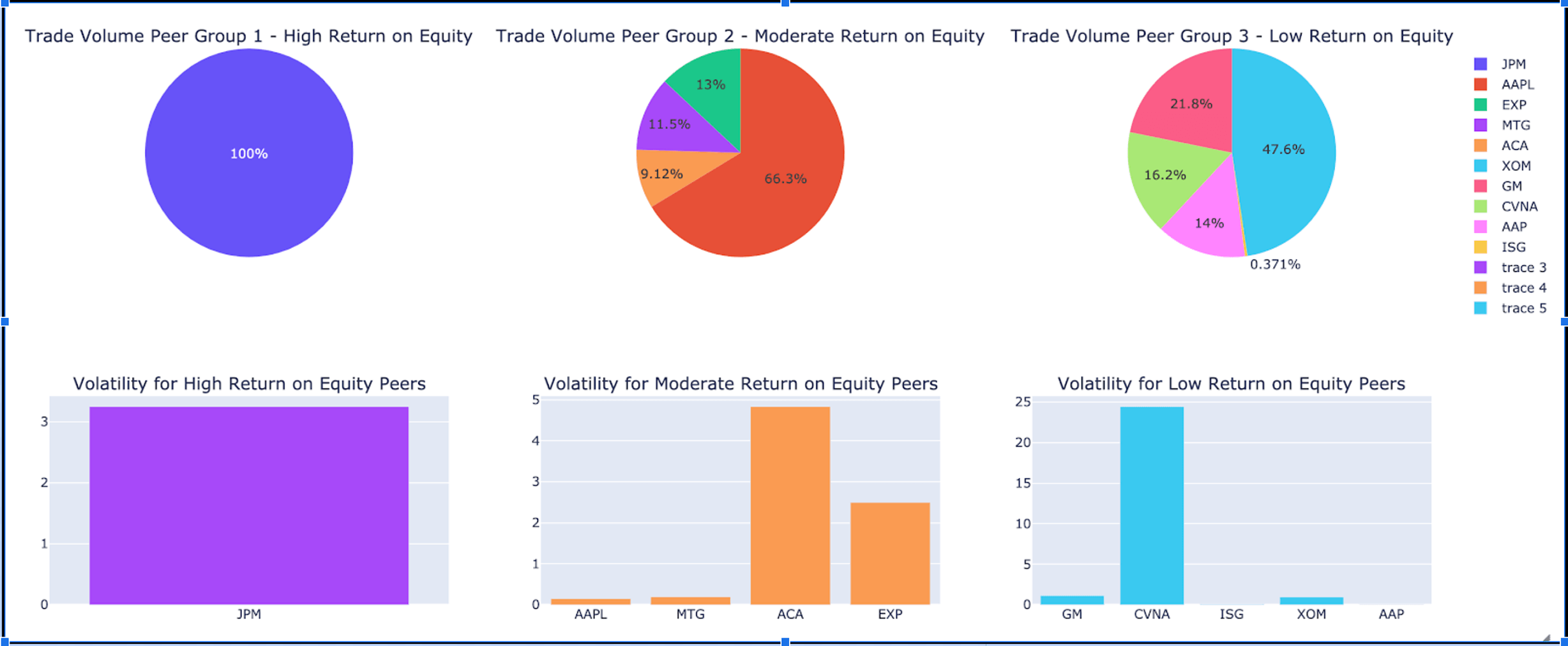
- Create peer groups - using meaningful fundamental data items such as EPS, return on equity, float % (to represent stakeholder holdings), form peer groups based on each metric. Note that the data item values need to be pivoted to perform meaningful feature engineering here.
- Resample tick data to the hour (or whatever granularity desired). Hourly is chosen due to the fact that daily aggregation does not provide enough granularity for a good forecast on volatility.
- Forecast market volatility on Databricks using the runtime for machine learning.
- Aggregate forecasting results to find max / min volatility companies based on securities being evaluated.

One of the noteworthy aspects of this data architecture is the last transitions when creating gold forecasting tables. In particular,
- We have incorporated ML as part of the feature engineering processing. This means we should apply full rigor for CI/CD as part of ML governance. Here is a template for accomplishing this in full rigor.
- We have chosen to highlight the importance of GPUs for forecasting volatility. In the notebook example at the end of this blog, we have chosen to use xgboost and simple range statistics on various quote metrics as part of our features. By leveraging the gpu_hist tree method and fully-managed GPU clusters and runtime, we can save 2.65X on costs (and 2.27X on runtime), both exhibiting the hard cost reduction and productivity savings for data teams. These metrics were obtained on 6 months of tick data from a major US exchange.
Ultimately, with the help of tempo and Databricks Runtime for Machine Learning, retail brokerages can service their clients with dashboards unifying fundamental and technical analysis using AI techniques. Below is the result of our peer group forecasts.
Market surveillance methodology with tick data
Market surveillance is an important part of the financial services ecosystem, which aims to reduce market manipulation, increase transparency, and enforce baseline rules for various assets classes. Some examples of organizations, both governmental and private, that have broad surveillance programs in place include NASDAQ, FINRA, CFTC, and CME Group. As the retail investing industry gets larger with newer and inexperienced investors (source), especially in the digital currency space, it is important to understand how to build a basic surveillance program that reduces financial fraud and increases transparency in areas such as market volatility, risk, and best execution. In the section below, we show how to build basic price improvement summaries, as well as putting a basic spoofing implementation together.
Price improvement
Price improvement refers to the amount of improvement on the bid (in the case of a sell order) or the ask (in the case of a buy order) that brokers provide clients. This is important for a retail broker because it often contributes to perceived quality of a broker if it consistently saves clients money on a set of trades over time. The basic concept of price improvement is:
- Maria places a market order at 10:00 AM for stock XYZ for 100 shares at which the best bid/ask is $10/$11
- Broker A routes the order to an exchange to get an execution price of $10.95 per share
- The savings is $0.05 * 100 = $5.00 on this execution, representing some modest price improvement
Even though the improvement is small, over time, these savings can add up over hundreds of trades. Some brokers display this information in-app also for transparency and to showcase the ability to route to appropriate market centers or market makers to get good prices.
Calculating price improvement
Price improvement is really a special case of slippage (how much the execution price shifts from the best bid/ask at order arrival time). It affects digital currency as much as traditional equities, arguably more so since there is a high amount of volatility and order-volume fluctuation. For example, here are some insights on finance market depth and slippage. Below is a basic blueprint for how to calculate slippage using tempo (detailed code is available in the attached notebook):
- Ingest market order messages (orders placed)
- Ingest execution messages
- Perform AS OF join to order arrival time using tempo
- Perform AS OF join to execution time using tempo
- Measure the difference in the execution price and the bid/ask available at order arrival time
- Summarize by firm and serve up in SQL analytics and/or BI dashboards
Ingestion of order book data to get orders and executions is typically available in JSON or other flat file formats from internal systems or OMS (order management systems). Once this data is available, the AS OF join operates on a pair of data frames as described in the official tempo documentation here:
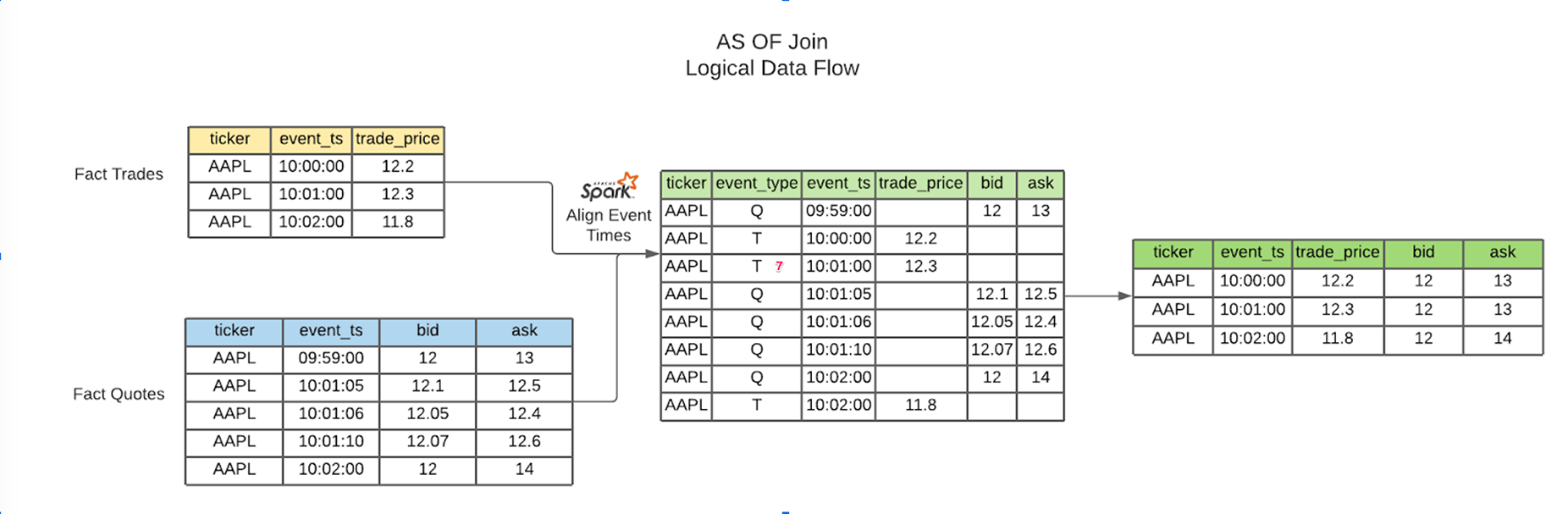
Below we display the code which performs the join.
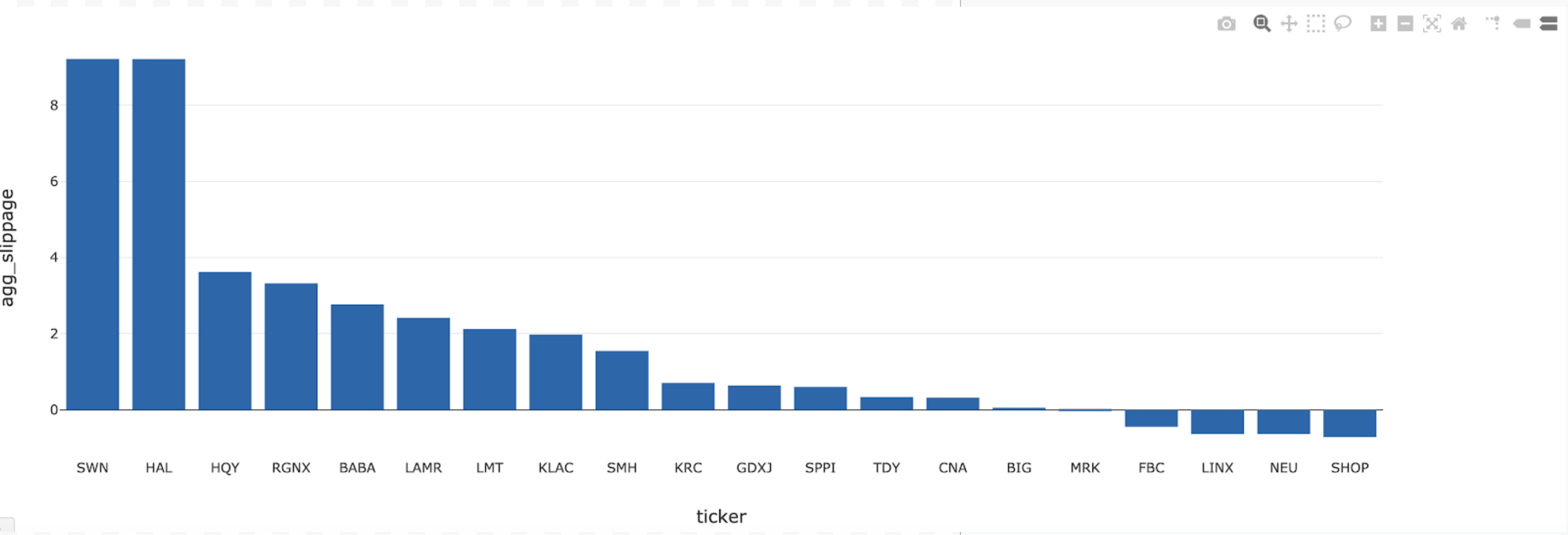
Once this data is available in Delta Lake, it can be sliced in various ways to get a summary of those securities that have prominent slippage. See the example below, which summarizes the log of the aggregate slippage for a slice of time on a trading day.
Spoofing
Spoofing refers to a market manipulation pattern which involves entry of artificial interest (via fake order placement) followed by execution on the opposite side to take advantage of best bid/ask changes, which were falsely influenced by the original artificial interest. The spoofing order of events typically involves cancellation of orders as well - we outline a simple example below.
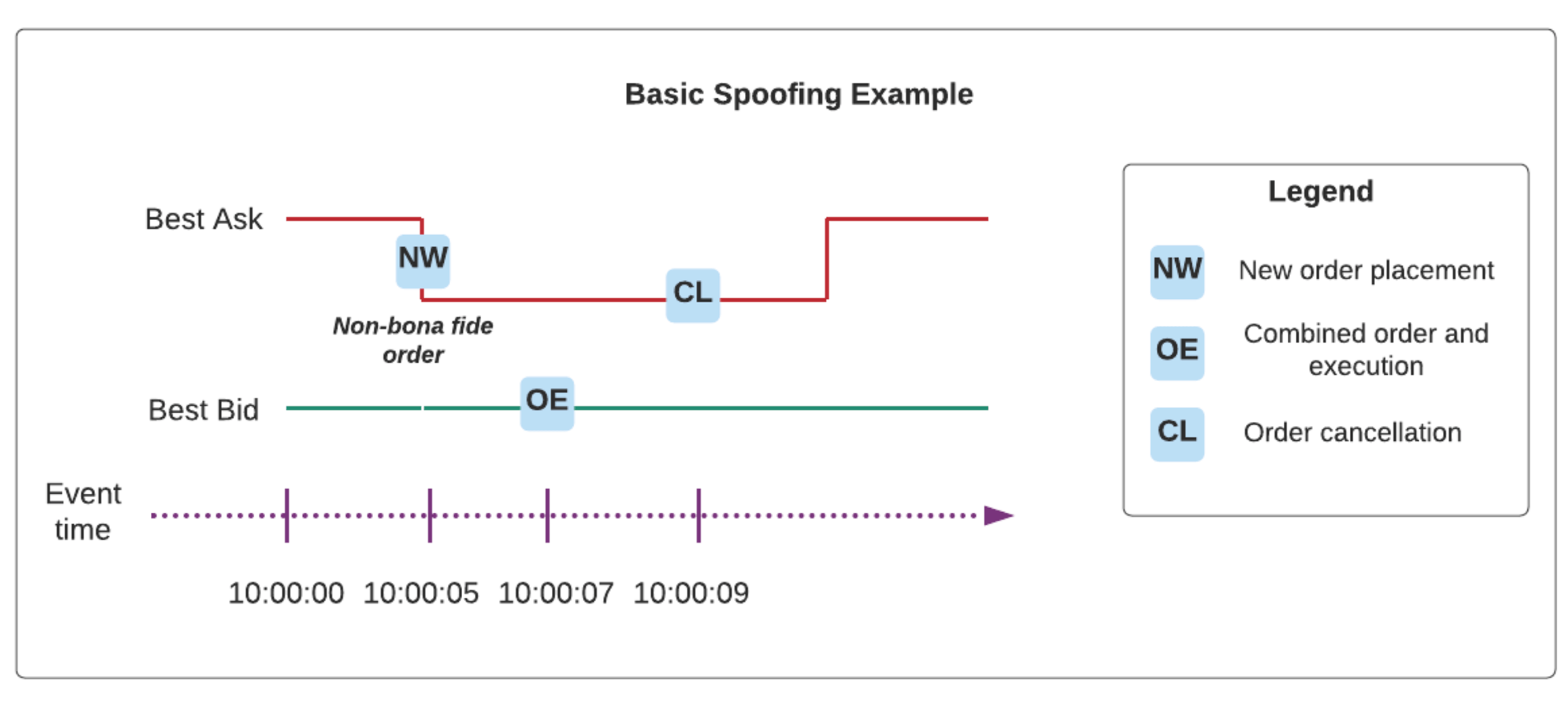
Spoofing is one of the hundreds of different market manipulation techniques and occurs in many different asset classes. In particular, it has been part of most market surveillance programs for equities, but due to increased demand in digital currencies such as bitcoin and Ether, it is of increased importance. In fact, since the volatility of cryptocurrencies is so variable, it is critical to protect clients from potential spoofing activities to secure trust in crypto platforms, whether they be exchanges or DeFi frameworks.
Sample pattern
The sequence of steps to detect spoofing applies to other manipulation patterns (e.g. front-running, layering, etc), so we've outlined a simple approach to highlight some underlying techniques.
- Save order placement information - key on ORDER ID and sequence number
- Save cancellation information for all orders (comes equipped with ORDER ID)
- Record NBBO at order arrival time (order_rcvd_ts in data below) as well as the NBBO prior to order arrivalJoin orders and cancellations (look for full cancellations) and record sequences of the following form:
- NBBO change at limit order placement from seconds prior to order placement (for a sell order, decrease in best ask)
- Cancellation at order placement (we refer to a fake order as a non-bonafide order)
- Execution on the opposite side of the order placement above
- Wash trade (self-trade) activity by the same market participant (or as a nuance, this could represent different MPIDs under the same CRD)
Sample pattern for capturing the NBBO (quote as a proxy here) information using the tempo AS OF join:
Below, we visualize the downward motion of the NBBO for a few sample orders, which validates the pattern we are looking for in the NBBO change.
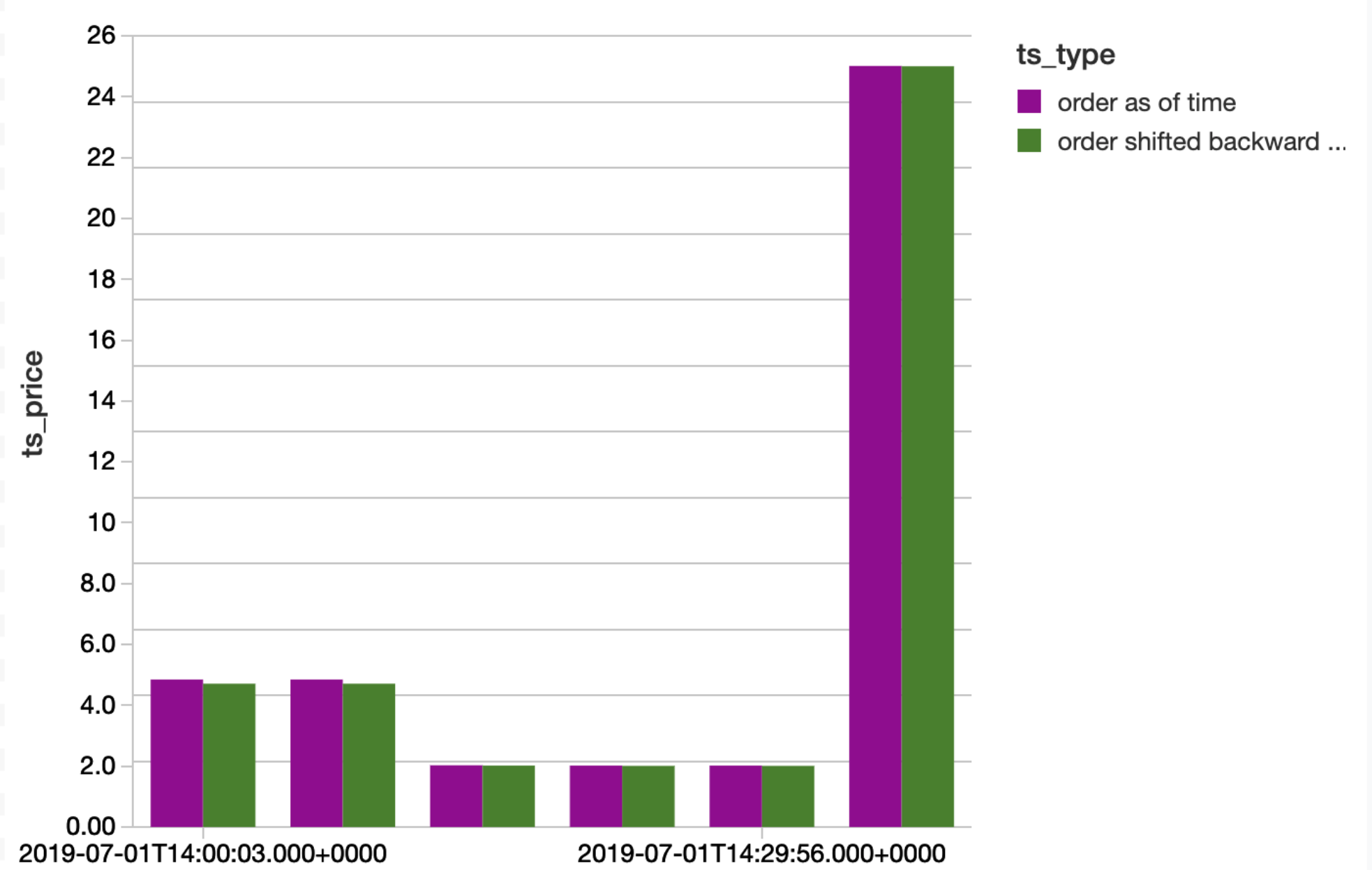
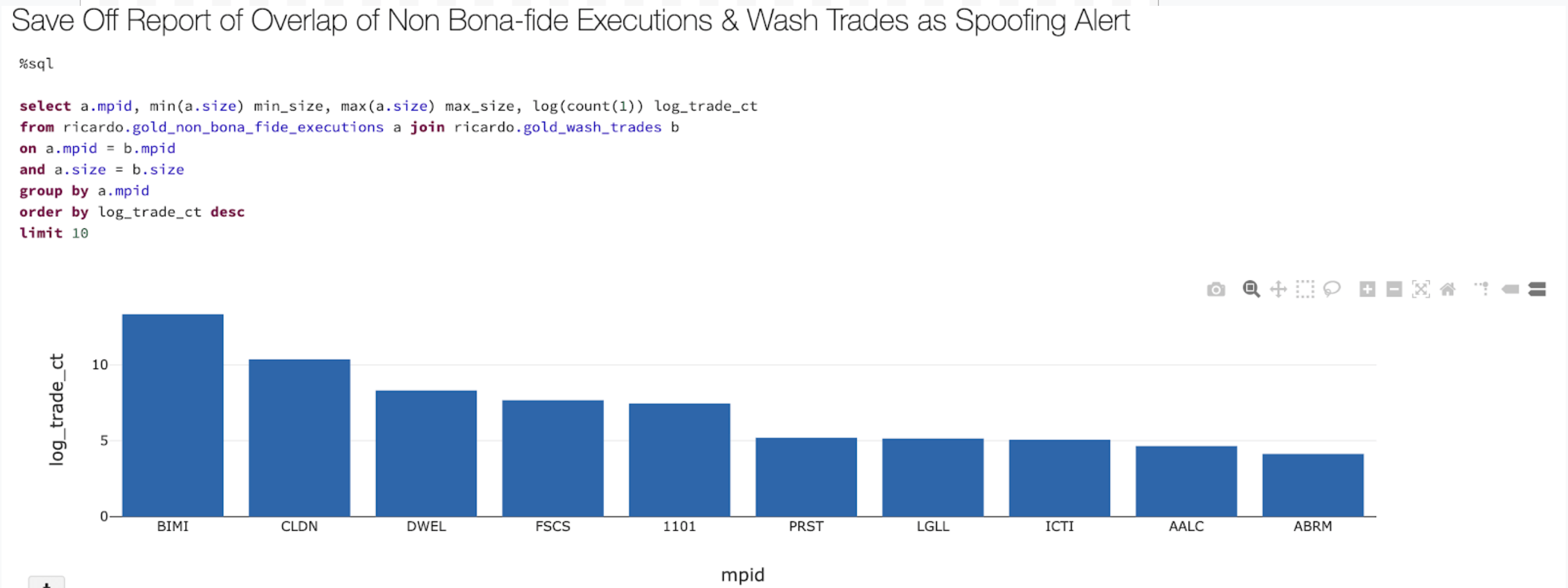
Finally, we save off the report of firms with non-bonafide executions that happen to coincide with some wash trading activity.
Conclusions
In this blueprint, we've focused on the ingestion of common datasets into Delta Lake as well as strategies for productionizing pipelines on Delta Lake objects. Utilizing Delta Lake enables FSIs to focus on product delivery for customers, ultimately resulting in increased AUM, decreased financial fraud, and increased subscriptions as the world of investing expands to more and more retail investors. From a technical perspective, all the use cases above are made possible by core tenets of a modern data architecture with help from the newly released tempo library:
- Support for open-source packages and integration with industry-accepted frameworks
- Infrastructure support for AI use cases
- Feature creation templates
- Time-series analyses support
We have documented these approaches and provided feature creation templates for a few popular use cases in the notebook links below. In addition, we've introduced tempo and its applications within these templates as a foundation for investment data platforms.
Try the below notebooks on Databricks to accelerate your investment platforms today and contact us to learn more about how we assist customers with similar use cases.
Bloomberg API Ingestion Notebook
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.