Introducing Databricks Machine Learning: a Data-native, Collaborative, Full ML Lifecycle Solution
by Clemens Mewald and Stephanie Liu
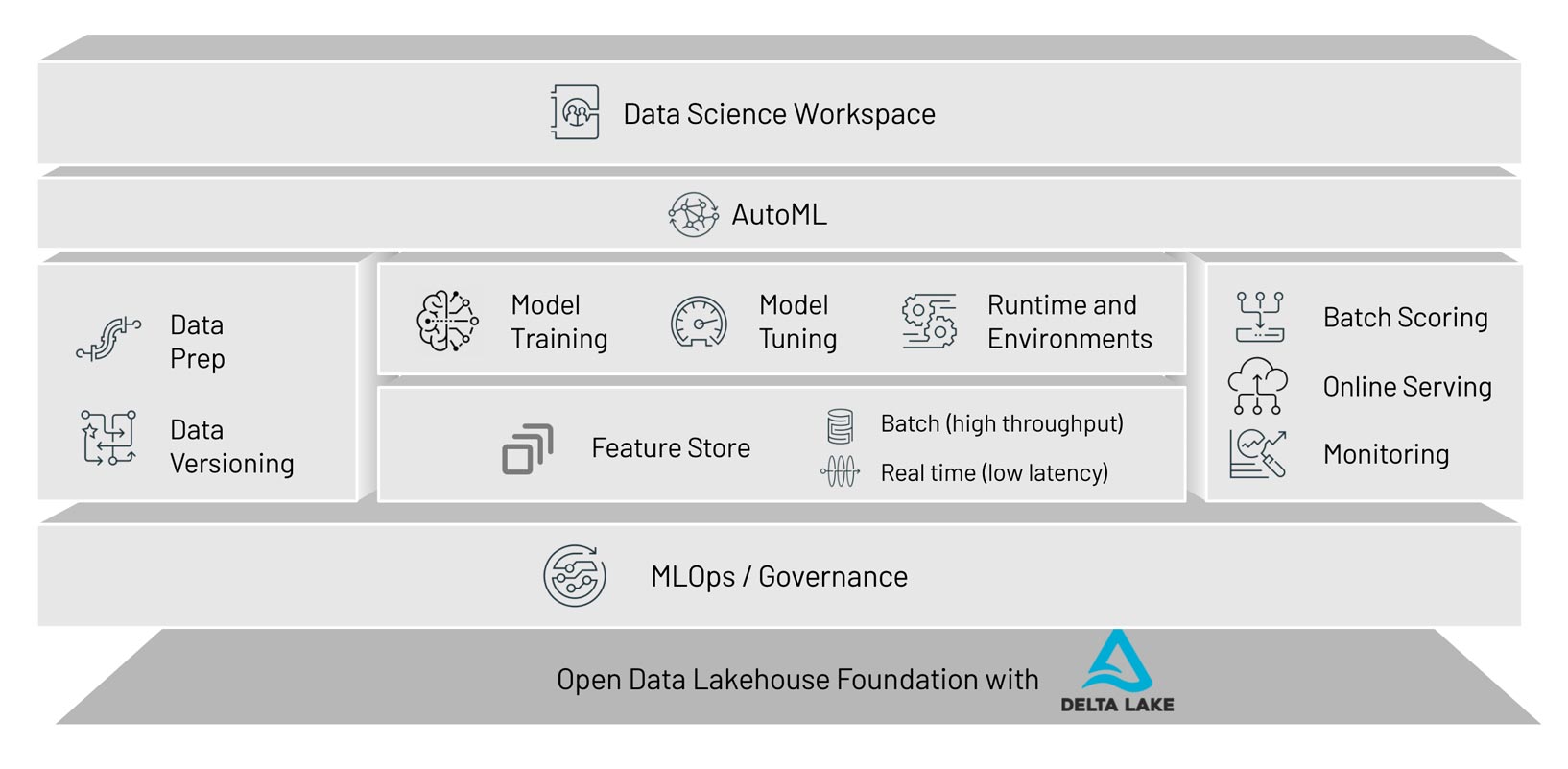
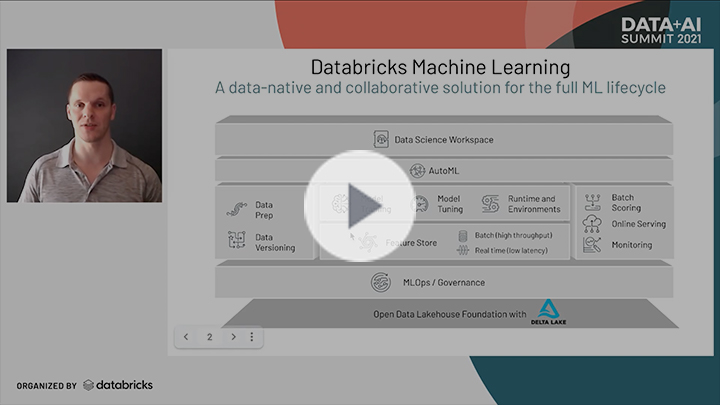
Today, we announced the launch of Databricks Machine Learning, the first enterprise ML solution that is data-native, collaborative, and supports the full ML lifecycle. This launch introduces a new purpose-built product surface in Databricks specifically for Machine Learning (ML) that brings together existing capabilities, such as managed MLflow, and introduces new components, such as AutoML and the Feature Store. Databricks ML provides a solution for the full ML lifecycle by supporting any data type at any scale, enabling users to train ML models with the ML framework of their choice and managing the model deployment lifecycle - from large-scale batch scoring to low latency online serving.
The hard part about AI is data
Many ML platforms fall short because they ignore a key challenge in ML: they assume that high-quality data is ready and available for training. That requires data teams to stitch together solutions that are good at data but not AI, with others that are good at AI but not data. To complicate things further, the people responsible for data platforms and pipelines (data engineers) are different from those that train ML models (data scientists), who are different from those who deploy product applications (engineering teams who own business applications). As a result, solutions for ML need to bridge gaps between data and AI, the tooling required and the people involved.
The answer is a data-native and collaborative solution for the full ML lifecycle
Data-native
ML models are the result of “compiling” data and code into a machine learning model. However, existing tools used in software development are inadequate for dealing with this interdependency between data and code. Databricks ML is built on top of an open data lakehouse foundation, which makes it the first data-native ML solution. Capabilities include:
- Any type of data, at any scale, from any source: With the Machine Learning Runtime, users can ingest and process images, audio, video, tabular or any other type of data – from CSV files to terabytes of streaming IoT sensor data. With an open source ecosystem of connectors, data can be ingested from any data source, across clouds, from on prem or from IoT sensors.
- Built-in data versioning, lineage and governance: Integrating with the time travel feature of Delta Lake, Databricks ML automatically tracks the exact version of data used to train a model. Combined with other lineage information logged by MLflow, this provides full end-to-end governance to facilitate robust ML pipelines.
Collaborative
Fully productionizing ML models requires contributions from data engineers, data scientists and application engineers. Databricks ML facilitates collaboration for all members of a data team by both supporting their workflows on Databricks and by providing built-in processes for handoffs. Key features include:
- Multi-language notebooks: Databricks Notebooks support Python, SQL, R and Scala within the same notebook. This provides flexibility for individuals who want to mix and match, and also collaboration across individuals who prefer different languages.
- Cloud-native collaborative features: Databricks Notebooks can be shared and jointly worked on in real time. Users can see who is active in a notebook from the co-presence indicator and watch their changes in real time. Built-in comments further facilitate collaboration.
- Model lifecycle management: The Model Registry is a collaborative hub in which teams can share ML models, collaborate on everything from experimentation to online testing and production, integrate with approval and governance workflows, and monitor ML deployments and their performance.
- Sharing and managed access: To enable secure collaboration, Databricks provides fine-grained access controls on all types of objects (Notebooks, Experiments, Models, etc.).
Full ML lifecycle
MLOps is a combination of DataOps, DevOps and ModelOps. To get MLops right, there is a vast ecosystem of tools that need to be integrated. Databricks ML takes a unique approach to supporting the full ML lifecycle and true MLOps.
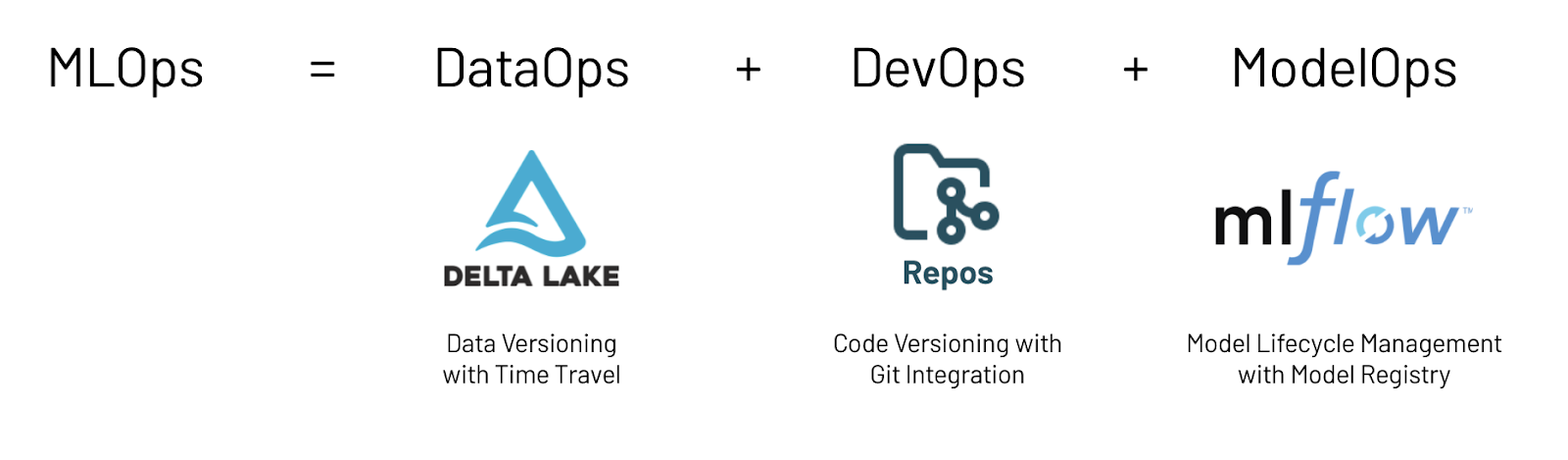
- DataOps: Through its data-native nature, Databricks ML is the only ML platform that provides built-in data versioning and governance. The exact version of the data is logged with every ML model that is trained on Databricks.
- DevOps: Databricks ML provides native integration with Git providers through its Repos feature, enabling data teams to follow best practices and integrate with CI/CD systems.
- ModelOps: With managed MLflow, Databricks ML provide a full set of features from tracking ML models with their associated parameter and metrics, to managing the deployment lifecycle, to deploying models across all modes (form batch to online scoring) on any platform (AWS, Azure, GCP, on-prem, or on-device).
- Full reproducibility: Providing a well-integrated solution for the full ML lifecycle means that work on Databricks ML is fully reproducible: data, parameters, metrics, models, code, compute configuration and library versions are all tracked and can be reproduced at any time.
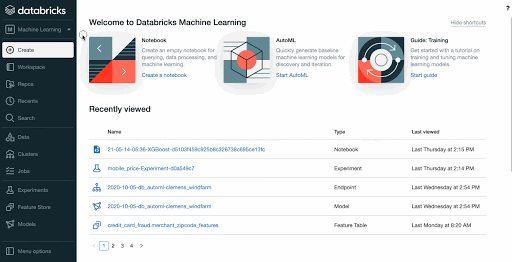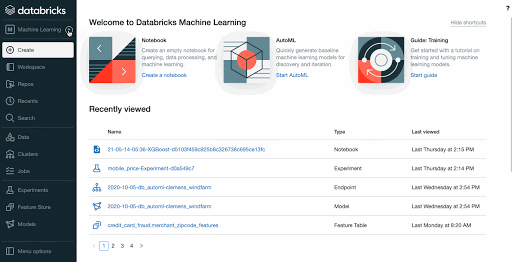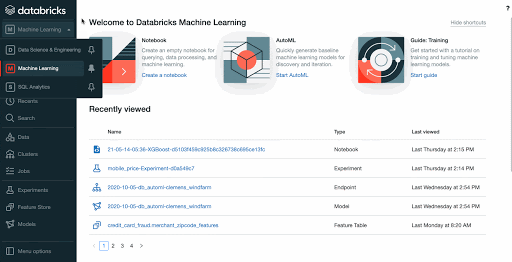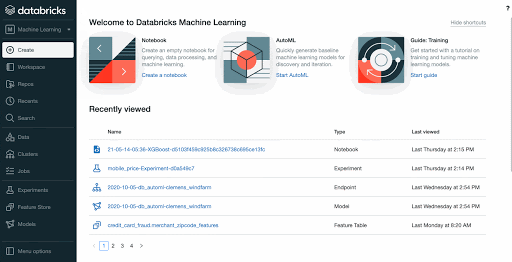
New persona-based navigation and machine learning dashboard
To simplify the full ML lifecycle on Databricks, we introduce a new persona-based navigation. Machine Learning is a new option, alongside Data Science & Engineering and SQL. By selecting Machine Learning, users gain access to all of the tools and features to train, manage and deploy ML models. We also provide a new ML landing page where we surface recently accessed ML assets (e.g. Models, Features, Experiments) and ML-related resources.
Introducing: Feature Store and AutoML
The latest additions to Databricks Machine Learning further underscore the unique attributes of a data-native and collaborative platform:
Feature Store
Our Feature Store is the first feature store that is co-designed with a data and MLops platform. It facilitates reuse of features with a centralized Feature Registry and eliminates the risk for online/offline skew by providing consistent access to features offline (for training and batch scoring) and online (for model serving).
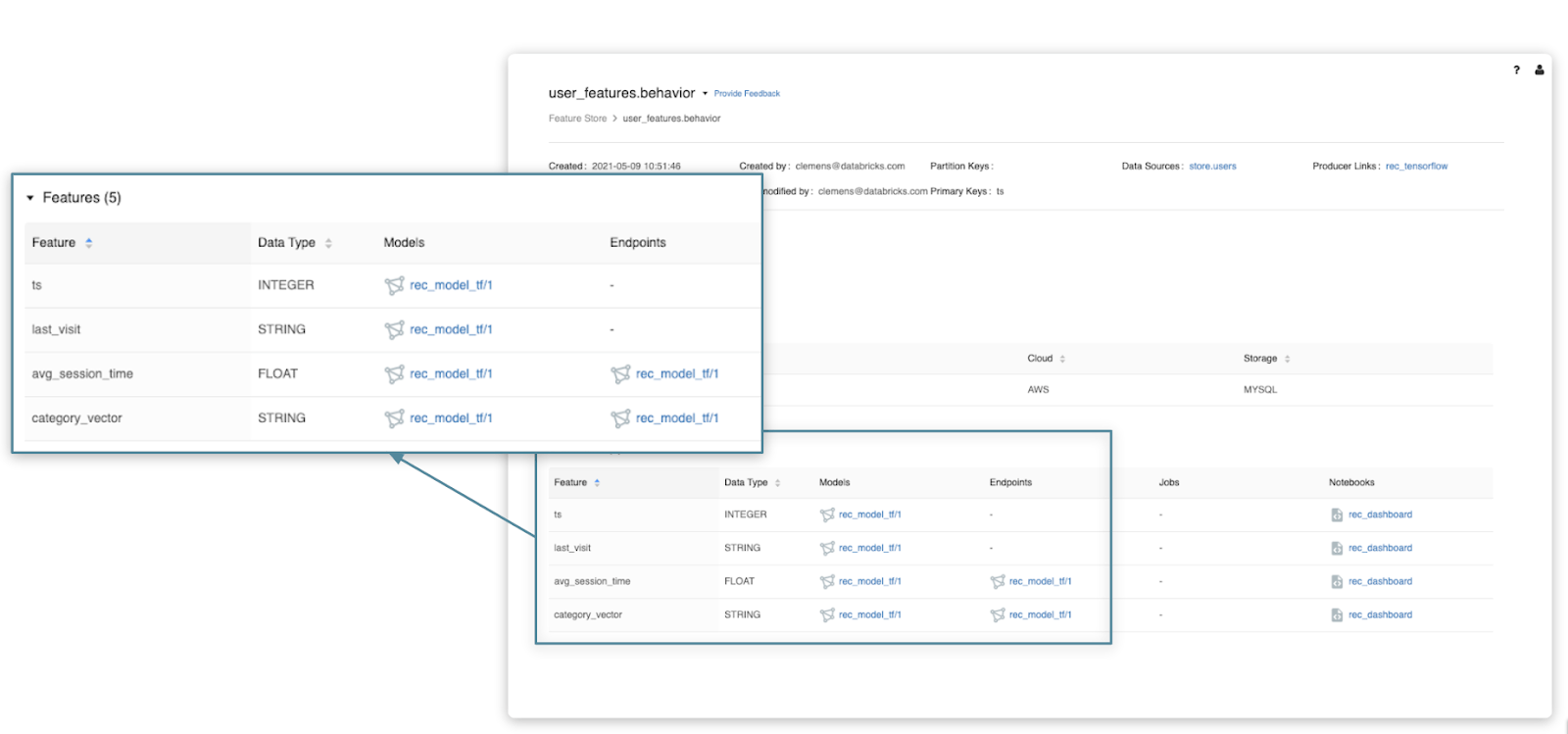
- To facilitate end-to-end lineage and lineage-based search, the Feature Registry tracks all Feature Tables, the code that produces them, the source data used to compute features and all consumers of features (e.g. Models and Endpoints). This provides full lineage from raw data, to which feature tables are computed based on that raw data, and which models consume which feature tables.
- To ensure feature consistency between training and serving and eliminate offline/online skew, the feature provider makes features available at high throughput and low latency. The feature provider also integrates with MLflow, simplifying the model deployment process. The MLflow model format stores information about which features the model consumed from the Feature Store, and at deployment, the model takes care of feature lookup, allowing the client application that calls the model to entirely ignore the existence of a feature store
Read more about our Feature Store product in the Feature Store launch blog post.
AutoML
Our AutoML product takes a glass box approach that provides a UI-based workflow for citizen data scientists to deploy recommended models. AutoML also generates the training code that a data scientist would write if they developed the same model themself. This transparency is critical in highly regulated environments and for collaboration with expert data scientists.
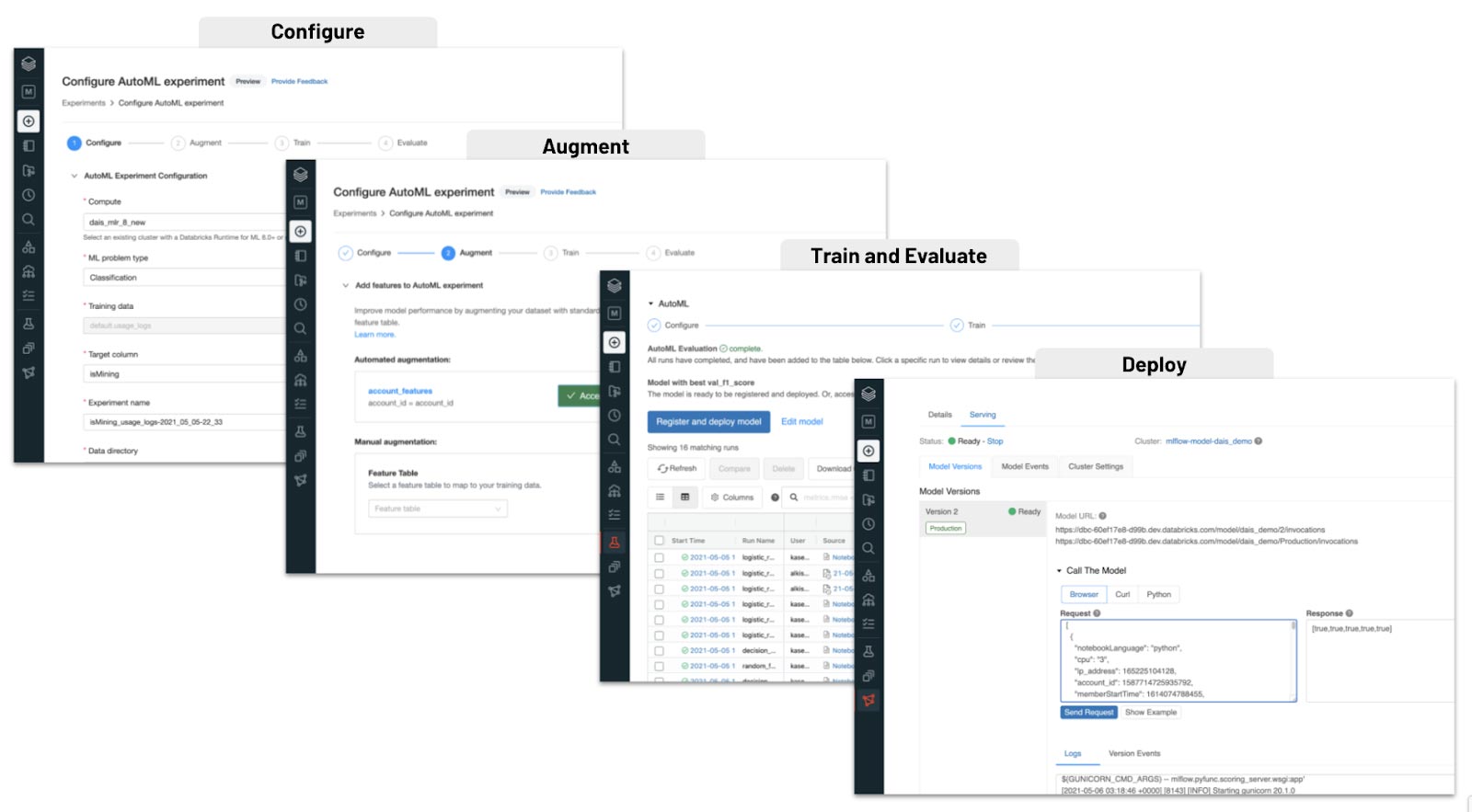
- In highly regulated environments, auditability and reproducibility is often a hard requirement. Most AutoML products are opaque-boxes that only provide a model artifact, making it hard to meet regulatory requirements like providing visibility into what type of model was trained, etc. Because Databricks AutoML generates the full Python notebook with the training code, we provide full visibility for regulators.
- For collaboration with expert data scientists, the generated code is a starting point that can be used to either adjust the model using domain expertise. In practice, AutoML is often used for a baseline model, and once a model shows promise, experts can refine it.
Read more about our AutoML product in the AutoML launch blog post.
Getting Started
Databricks Machine Learning is available to all Databricks customers starting today. Simply click on the new persona switcher and select Machine Learning. The new navigation bar will give you access to all ML features, and the ML Dashboard will guide you through relevant resources and provide access to your recently used ML artifacts. Learn more in our documentation for AWS, Azure and GCP.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.