5 Key Steps to Successfully Migrate From Hadoop to the Lakehouse Architecture
by Harsh Narula
The decision to migrate from Hadoop to a modern cloud-based architecture like the lakehouse architecture is a business decision, not a technology decision. In a previous blog, we dug into the reasons why every organization must re-evaluate its relationship with Hadoop. Once stakeholders from technology, data, and the business make the decision to move the enterprise off of Hadoop, there are several considerations that need to be taken into account before starting the actual transition. In this blog, we’ll specifically focus on the actual migration process itself. You’ll learn about the key steps for a successful migration and the role the lakehouse architecture plays in sparking the next wave of data-driven innovation.
The migration steps
Let's call it like it is. Migrations are never easy. However, migrations can be structured to minimize adverse impact, ensure business continuity and manage costs effectively. To do this, we suggest breaking your migration off of Hadoop down into these five key steps:
- Administration
- Data Migration
- Data Processing
- Security and Governance
- SQL and BI Layer
Step 1: Administration
Let’s review some of the essential concepts in Hadoop from an administration perspective, and how they compare and contrast with Databricks.
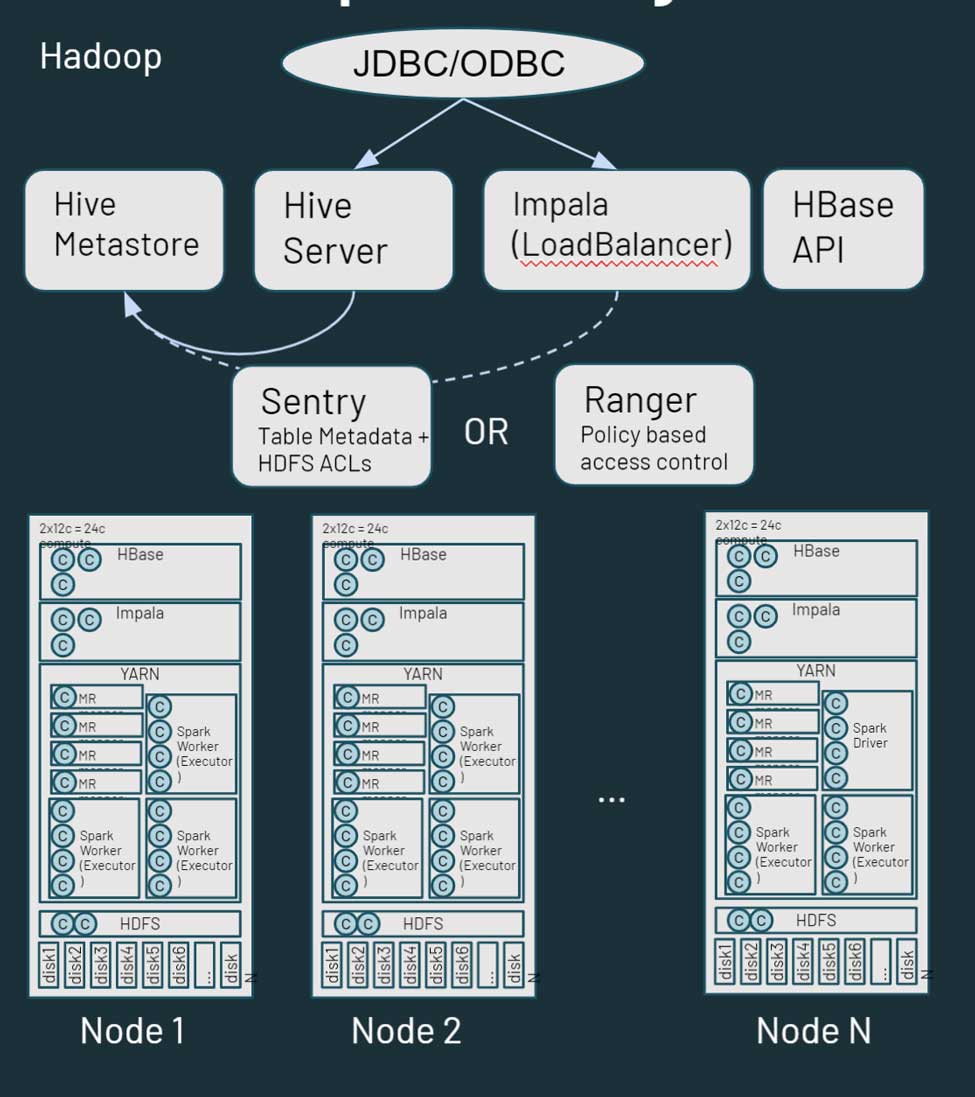
Hadoop is essentially a monolithic distributed storage and compute platform. It consists of multiple nodes and servers, each with their own storage, CPU and memory. Work is distributed across all these nodes. Resource Management is done via YARN, which attempts best efforts to ensure that workloads get their share of compute.
Hadoop also consists of metadata information. There is a Hive metastore, which contains structured information around your assets that are stored in HDFS. You can leverage Sentry or Ranger for controlling access to the data. From a data access perspective, users and applications can either access data directly through HDFS (or the corresponding CLI/API’s) or via a SQL type interface. The SQL interface, in turn, can be over a JDBC/ODBC connection using Hive for generic SQL (or in some cases ETL Scripts) or Hive on Impala or Tez for interactive queries. Hadoop also provides an HBase API and related data source services. More on the Hadoop ecosystem here.
Next, let’s discuss how these services are mapped to or dealt with in the Databricks Lakehouse Platform. In Databricks, one of the first differences to note is that you’re looking at multiple clusters in a Databricks environment. Each cluster could be used for a specific use case, a specific project, business unit, team or development group. More importantly, these clusters are meant to be ephemeral. For job clusters, the clusters’ life span is meant to last for the duration of the workflow. It will execute the workflow, and once it’s complete, the environment is torn down automatically. Likewise, if you think of an interactive use case, where you have a compute environment that’s shared across developers, this environment can be spun up at the beginning of the workday, with developers running their code throughout the day. During periods of inactivity, Databricks will automatically tear it down via the (configurable) auto-terminate functionality that’s built into the platform.
Unlike Hadoop, Databricks does not provide data storage services like HBase or SOLR. Your data resides in your file storage, within object storage. A lot of the services like HBase or SOLR have alternatives or equivalent technology offerings in the cloud. It might be a cloud-native or an ISV solution.
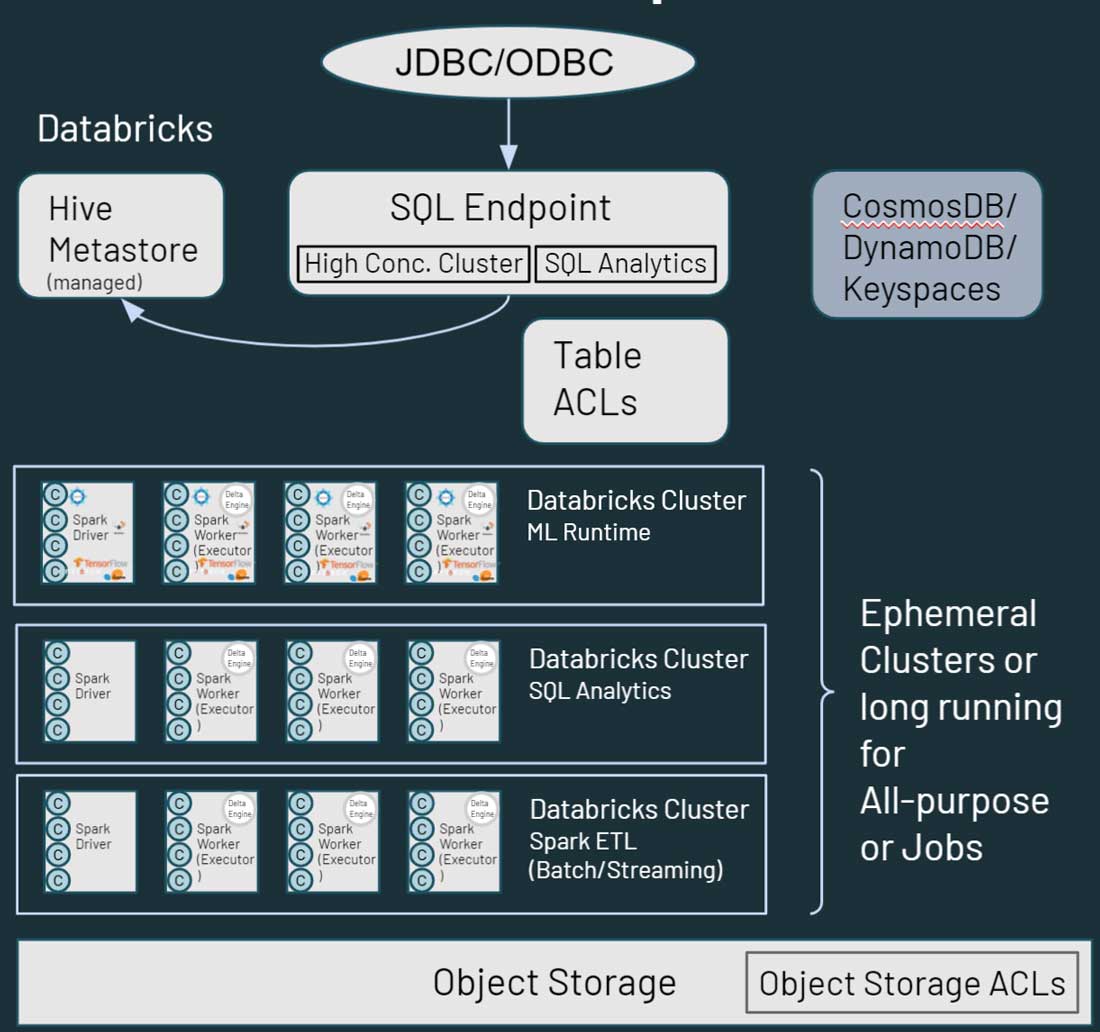
As you can see in the diagram above, each cluster node in Databricks corresponds to either Spark driver or a worker. The key thing here is that the different Databricks clusters are completely isolated from each other. This allows you to ensure that strict SLAs can be met for specific projects and use cases. You can truly isolate streaming or real-time use cases from other, batch oriented workloads, and you don’t have to worry about manually isolating long running jobs that could hog cluster resources for a long time. You can just spin up new clusters as compute for different use cases. Databricks also decouples storage from compute, and allows you to leverage existing cloud storage such as AWS S3, Azure Blob Storage and Azure Data Lake Store (ADLS).
Databricks also has a default managed Hive metastore, which stores structured information about data assets that reside in cloud storage. It also supports using an external metastore, such as AWS Glue, Azure SQL Server or Azure Purview. You can also specify security control such as Table ACLs within Databricks, as well as object storage permissions.
When it comes to data access, Databricks offer similar capabilities to Hadoop in terms of how your users interact with the data. Data stored in cloud storage, can be accessed through multiple paths in the Databricks environment. Users can use SQL Endpoints and Databricks SQL for interactive queries and analytics. They can also use the Databricks notebooks for Data Engineering and Machine Learning capabilities on the data stored in cloud storage. HBase in Hadoop maps to Azure CosmosDB, or AWS DynamoDB/Keyspaces, which can be leveraged as a serving layer for downstream applications.
Step 2: Data migration
Coming from a Hadoop background, I’ll assume most of the audience would already be familiar with HDFS. HDFS is the storage file system used with Hadoop deployments that leverages disks on the nodes of the Hadoop cluster. So, when you scale HDFS, you need to add capacity to the cluster as a whole (i.e. you need to scale compute and storage together). If this involves procurement and installation of additional hardware, there can be a significant amount of time and effort involved.
In the cloud, you have nearly limitless storage capacity in the form of cloud storage such as AWS S3, Azure Data Lake Storage or Blob Storage or Google Storage. There are no maintenance or health checks needed, and it offers built-in redundancy and high levels of durability and availability from the moment it is deployed. We recommend using native cloud services to migrate your data, and to ease the migration there are several partners/ISVs.
So, how do you get started? The most commonly recommended route is to start with a dual ingestion strategy (i.e. add a feed that uploads data into cloud storage in addition to your on-premise environment). This allows you to get started with new use cases (that leverage new data) in the cloud without impacting your existing setup. If you’re looking for buy-in from other groups within the organization, you can position this as a backup strategy to begin with. HDFS traditionally has been a challenge to back up due to the sheer size and effort involved, so backing up data into the cloud can be a productive initiative anyway.
In most cases, you can leverage existing data delivery tools to fork the feed and write not just to Hadoop but to cloud storage as well. For example, if you’re using tools/frameworks like Informatica and Talend to process and write data to Hadoop, it’s very easy to add the additional step and have them write to cloud storage. Once the data is in the cloud, there are many ways to work with that data.
In terms of data direction, the data either be pulled from on-premise to the cloud, or pushed to the cloud from on-premise. Some of the tools that can be leveraged to push the data into the cloud are cloud native solutions (Azure Data Box, AWS Snow Family, etc.), DistCP (a Hadoop tool), other third party tools, as well as any in-house frameworks. The push option is usually easier in terms of getting the required approvals from the security teams.
For pulling the data to the cloud, you can use Spark/Kafka Streaming or Batch ingestion pipelines that are triggered from the cloud. For batch, you can either ingest files directly or use JDBC connectors to connect to the relevant upstream technology platforms and pull the data. There are, of course, third party tools available for this as well. The push option is the more widely accepted and understood of the two, so let’s dive a little bit deeper into the pull approach.
The first thing you’ll need is to set up connectivity between your on-premises environment and the cloud. This can be achieved with an internet connection and a gateway. You can also leverage dedicated connectivity options such as AWS Direct Connect, Azure ExpressRoute, etc. In some cases, if your organization is not new to the cloud, this may have already been set up so you can reuse it for your Hadoop migration project.
Another consideration is the security within the Hadoop environment. If it is a Kerberized environment, it can be accommodated from the Databricks side. You can configure Databricks initialization scripts that run on cluster startup, install and configure the necessary kerberos client, access the krb5.conf and keytab files, which are stored in a cloud storage location, and ultimately execute the kinit() function, which will allow the Databricks cluster to interact directly with your Hadoop environment.
Finally, you will also need an external shared metastore. While Databricks does have a metastore service that is deployed by default, it also supports using an external one. The external metastore will be shared by Hadoop and Databricks, and can be deployed either on-premises (in your Hadoop environment) or the cloud. For example, if you have existing ETL processes running in Hadoop and you cannot migrate them to Databricks yet, you can leverage this setup with the existing on-premises metastore, to have Databricks consume the final curated dataset from Hadoop.
Step 3: Data Processing
The main thing to keep in mind is that from a data processing perspective, everything in Databricks leverages Apache Spark. All Hadoop programming languages, such as MapReduce, Pig, Hive QL and Java, can be converted to run on Spark, whether it be via Pyspark, Scala, Spark SQL or even R. With regards to the code and IDE, both Apache Zeppelin and Jupyter notebooks can be converted to Databricks notebooks, but it’s a bit easier to import Jupyter notebooks. Zeppelin notebooks will need to be converted to Jupyter or Ipython before they can be imported. If your data science team would like to continue to code in Zeppelin or Jupyter, they can use Databricks Connect, which allows you to leverage your local IDE (Jupyter, Zeppelin or even IntelliJ, VScode, RStudio, etc.) to run code on Databricks.
When it comes to migrating Apache Spark™ jobs, the biggest consideration is Spark versions. Your on-premises Hadoop cluster may be running an older version of Spark, and you can use the Spark migration guide to identify what changes were made to see any impacts on your code. Another area to consider is converting RDDs to dataframes. RDDs were commonly used with Spark versions up to 2.x, and while they can still be used with Spark 3.x, doing so can prevent you from leveraging the full capabilities of the Spark optimizer. We recommend that you change your RDDs to dataframes wherever possible.
Last but not least, one of the common gotchas we’ve come across with customers during migration is hard-coded references to the local Hadoop environment. These will, of course, need to be updated, without which the code will break in the new setup.
Next, let’s talk about converting non-Spark workloads, which for the most part involve rewriting code. For MapReduce, in some cases, if you’re using shared logic in the form of a Java library, the code can be leveraged by Spark. However, you may still need to re-write some parts of the code to run in a Spark environment as opposed to MapReduce. Sqoop is relatively easy to migrate since in the new environments you’re running a set of Spark commands(as opposed to MapReduce commands) using a JDBC source. You can specify parameters in Spark code in the same way that you specify them in Sqoop. For Flume, most of the use cases we’ve seen are around consuming data from Kafka and writing to HDFS. This is a task that can be easily accomplished using Spark streaming. The main task with migrating Flume is that you have to convert the config file-based approach into a more programmatic approach in Spark. Lastly, we have Nifi, which is mostly used outside Hadoop, mostly as a drag and drop, self-service ingestion tool. Nifi can be leveraged in the cloud as well, but we see many customers using the opportunity to migrate to the cloud to replace Nifi with other, newer tools available in the cloud.
Migrating HiveQL is perhaps the easiest task of all. There is a high degree of compatibility between Hive and Spark SQL, and most queries should be able to run on Spark SQL as-is. There are some minor changes in DDL between HiveQL and Spark SQL, such as the fact that Spark SQL uses the “USING” clause vs HiveQL’s “FORMAT” clause. We do recommend changing the code to use the Spark SQL format, as it allows the optimizer to prepare the best possible execution plan for your code in Databricks. You can still leverage Hive Serdes and UDFs, which makes life even easier when it comes to migrating HiveQL to Databricks.
With respect to workflow orchestration, you have to consider potential changes to how your jobs will be submitted. You can continue to leverage Spark submit semantics, but there are also other, faster and more seamlessly integrated options available. You can leverage Databricks jobs and Delta Live Tables for code-free ETL to replace Oozie jobs, and define end-to-end data pipelines within Databricks. For workflows involving external processing dependencies, you’ll have to create the equivalent workflows/pipelines in technologies like Apache Airflow, Azure Data Factory, etc. for automation/scheduling. With Databricks’ REST APIs, nearly any scheduling platform can be integrated and configured to work with Databricks.
There is also an automated tool called MLens (created by KnowledgeLens), which can help migrate your workloads from Hadoop to Databricks. MLens can help migrate PySpark code and HiveQL, including translation of some of the Hive specifics into Spark SQL so that you can take advantage of the full functionality and performance benefits of the Spark SQL optimizer. They are also planning to soon support migrating Oozie workflows to Airflow, Azure Data Factory, etc.
Step 4: Security and governance
Let’s take a look at security and governance. In the Hadoop world, we have LDAP integration for connectivity to admin consoles like Ambari or Cloudera Manager, or even Impala or Solr. Hadoop also has Kerberos, which is used for authentication with other services. From an authorization perspective, Ranger and Sentry are the most commonly used tools.
With Databricks, Single Sign On (SSO) integration is available with any Identity Provider that supports SAML 2.0. This includes Azure Active Directory, Google Workspace SSO, AWS SSO and Microsoft Active Directory. For Authorization, Databricks provides ACLs (Access Control Lists) for Databricks objects, which allows you to set permissions on entities like notebooks, jobs, clusters. For data permissions and access control, you can define table ACLs and views to limit column and row access, as well as leverage something like credential passthrough, with which Databricks passes on your workspace login credentials to the storage layer (S3, ADLS, Blob Storage.) to determine if you are authorized to access the data. If you need capabilities like attribute-based controls or data masking, you can leverage partner tools like Immuta and Privacera. From an enterprise governance perspective, you can connect Databricks to an enterprise data catalog such as AWS Glue, Informatica Data Catalog, Alation and Collibra.
Step 5: SQL & BI layer
In Hadoop, as discussed earlier, you have Hive and Impala as interfaces to do ETL as well as ad-hoc queries and analytics. In Databricks, you have similar capabilities via Databricks SQL. Databricks SQL also offers extreme performance via the Delta engine, as well as support for high-concurrency use cases with auto-scaling clusters. Delta engine also includes Photon, which is a new MPP engine built from scratch in C++ and is vectorized to exploit both data level and instruction-level parallelism.
Databricks provides native integration with BI tools such as Tableau, PowerBI, Qlik andlooker, as well as highly-optimized JDBC/ODBC connectors that can be leveraged by those tools. The new JDBC/ODBC drivers have a very small overhead (¼ sec) and a 50% higher transfer rate using Apache Arrow, as well as several metadata operations that support significantly faster metadata retrieval operations. Databricks also supports SSO for PowerBI, with support for SSO with other BI/dashboarding tools coming soon.
Databricks has a built-in SQL UX in addition to the notebook experience mentioned above, which gives your SQL users their own lens with a SQL workbench, as well as light dashboarding and alerting capabilities. This allows for SQL-based data transformations and exploratory analytics on data within the data lake, without the need to move it downstream to a data warehouse or other platforms.
Next steps
As you think about your migration journey to a modern cloud architecture like the lakehouse architecture, here are two things to remember:
- Remember to bring the key business stakeholders along on the journey. This is as much of a technology decision as it is a business decision and you need your business stakeholders bought into the journey and its end state.
- Also, remember you’re not alone, and there are skilled resources across Databricks and our partners who have done this enough to build out repeatable best practices, saving organizations, time, money, resources, and reducing overall stress.
- Download the Hadoop to Databricks Technical Migration guide for step-by-step guidance, notebooks, and code to begin your migration.
To learn more about how Databricks increases business value and start planning your migration off of Hadoop, visit www.databricks.com/solutions/migration.

Migration Guide: Hadoop to Databricks
Unlock the full potential of your data with this self-guided playbook.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.