Introducing Apache Spark™ 3.2
Now available on Databricks Runtime 10.0
by Gengliang Wang, Wenchen Fan, Hyukjin Kwon, Xiao Li and Reynold Xin
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
We are excited to announce the availability of Apache Spark™ 3.2 on Databricks as part of Databricks Runtime 10.0. We want to thank the Apache Spark community for their valuable contributions to the Spark 3.2 release.
The number of monthly maven downloads of Spark has rapidly increased to 20 million. The year-over-year growth rate represents a doubling of monthly Spark downloads in the last year. Spark has become the most widely-used engine for executing data engineering, data science and machine learning on single-node machines or clusters.
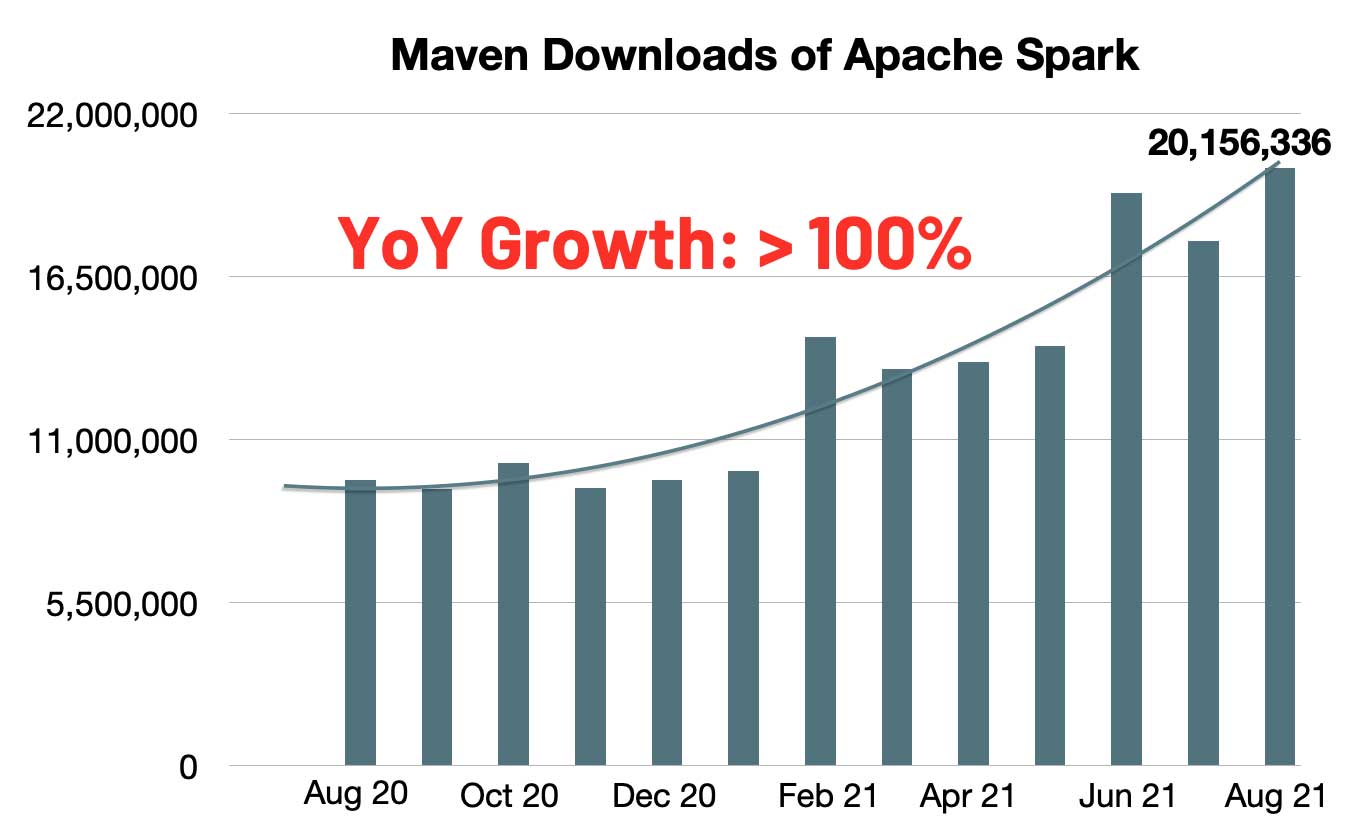
Continuing with the objectives to make Spark even more unified, simple, fast and scalable, Spark 3.2 extends its scope with the following features:
- Introducing pandas API on Apache Spark to unify small data API and big data API (learn more here).
- Completing the ANSI SQL compatability mode to simplify migration of SQL workloads.
- Productionizing adaptive query execution to speed up Spark SQL at runtime.
- Introducing RocksDB statestore to make state processing more scalable.
In this blog post, we summarize some of the higher-level features and improvements. Keep an eye out for upcoming posts that dive deeper into these features. For a comprehensive list of major features across all Spark components and JIRA tickets resolved, please see the Apache Spark 3.2.0 release notes.
Unifying small data API and big data API
Python is the most widely used language on Spark. To make Spark more Pythonic, the pandas API was introduced to Spark, as part of Project Zen (see also Project Zen: Making Data Science Easier in PySpark from Data + AI Summit 2021). Now, the existing users of pandas can scale out their pandas applications with one line change. As shown below, performance can be greatly improved in both single-node machines [left] and multi-node Spark clusters [right], thanks to the sophisticated optimizations in the Spark engine.
![pandas performance can be greatly improved in both single-node machines [left] and multi-node clusters [right], thanks to the sophisticated optimizations in the Spark engine.](https://www.databricks.com/wp-content/uploads/2021/10/Introducing-Apache-Spark-3.2-blog-img-3.jpg)
At the same time, Python users can also seamlessly leverage the unified analytics functionality provided in Spark, including querying data via SQL, streaming processing and scalable machine learning (ML). The new pandas API also provides interactive data visualization powered by the plotly backend.
For more details, see the blog post "Pandas API on Upcoming Apache Spark™ 3.2"
Simplifying SQL migration
More ANSI SQL features (e.g., lateral join support) were added. After more than one year of development, the ANSI SQL mode is GA in this release. To avoid massive behavior-breaking changes, the mode `spark.sql.ansi.enabled` is still disabled by default. The ANSI mode includes the following major behavior changes:
- Runtime error throwing instead of silent ignorance with null results when the inputs to a SQL operator/function are invalid (SPARK-33275). For example, integer value overflow errors on arithmetic operations, or parsing errors on casting string to numeric/timestamp types.
- Standardized type coercion syntax rules (SPARK-34246). The new rules define whether values of a given data type can be promoted to another data type implicitly based on the data type precedence list, which is more straightforward than the default non-ANSI mode.
- New explicit cast syntax rules (SPARK-33354). When Spark queries contain illegal type casting (e.g., date/timestamp types are cast to numeric types) compile-time errors are thrown informing the user of invalid conversions.
This release also includes some new initiatives that have not been fully finished yet. For example, standardize exception messages in Spark (SPARK-33539); introducing ANSI interval type (SPARK-27790) and improving the coverage of correlated subqueries (SPARK-35553).
Speeding up Spark SQL at runtime
Adaptive Query Execution (AQE) is enabled by default in this release (SPARK-33679). For performance improvements, the AQE can re-optimize the query execution plans based on the accurate statistics collected at runtime. Maintenance and pre-collection of statistics are expensive in big data. Lacking accurate statistics often causes inefficient plans, no matter how advanced the optimizer is. In this release, AQE becomes fully compatible with all the existing query optimization techniques (e.g., Dynamic Partition Pruning) to re-optimize the join strategies, skew join and shuffle partition coalescence.
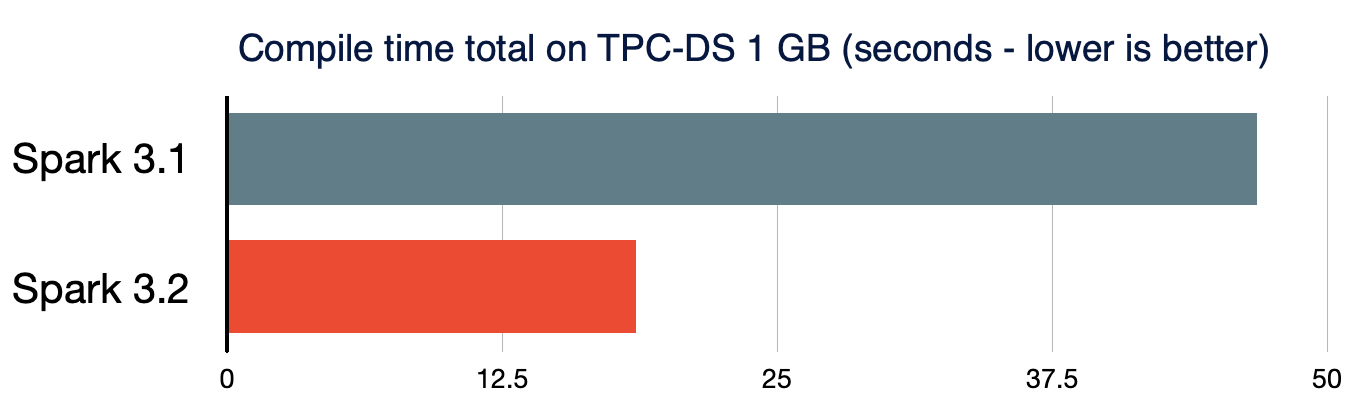
Both small data and big data should be processed in a highly efficient manner in the unified data analytics system. Short query performance becomes also critical. The overhead of Spark query compilation in complex queries is significant when the volume of processed data is considerably small. To further reduce the query compilation latency, Spark 3.2.0 prunes unnecessary query plan traversals in analyzer/optimizer rules (SPARK-35042, SPARK-35103) and speeds up the construction of new query plans (SPARK-34989). As a result, the compile time of TPC-DS queries is reduced by 61%, compared to Spark 3.1.2.
More scalable state processing streaming
The default implementation of state store in Structured Streaming is not scalable since the amount of state that can be maintained is limited by the heap size of the executors. In this release, Databricks contributed to the Spark community RocksDB-based state store implementation, which has been used in Databricks production for more than four years. This state store can avoid full scans by sorting keys, and serve data from the disk without relying on the heap size of executors.
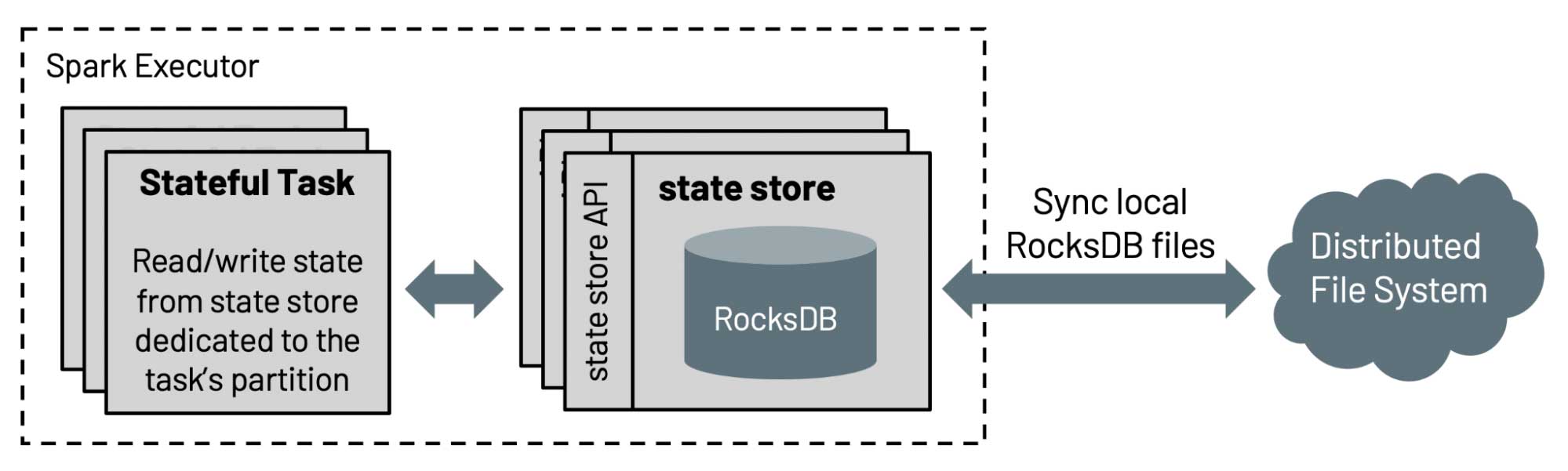
In addition, state store APIs are enriched with the API for prefix match scan (SPARK-35861) for efficiently supporting event time based sessionization (SPARK-10816), which allow users to do aggregations on session windows over eventTime. For more details, please read the blog post "Native support of session window in Apache Spark's Structured Streaming".
Other updates in Spark 3.2
In addition to these new features, the release focuses on usability, stability, and refinement, resolving around 1700 JIRA tickets. It’s the result of contributions from over 200 contributors, including individuals as well as companies such as Databricks, Apple, Linkedin, Facebook, Microsoft, Intel, Alibaba, Nvidia, Netflix, Adobe and many more. We’ve highlighted a number of key SQL, Python and streaming data advancements in Spark for this blog post, but there are many additional capabilities in the 3.2 milestone, including codegen coverage improvements and connector enhancements, which you can learn more about in the release notes.

Get started with Spark 3.2 today
If you want to try out Apache Spark 3.2 in the Databricks Runtime 10.0, sign up for the Databricks Community Edition or Databricks Trial, both of which are free, and get started in minutes. Using Spark 3.2 is as simple as selecting version "10.0" when launching a cluster.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.