Confluent Streaming for Databricks: Build Scalable Real-time Applications on the Lakehouse
by Hiral Jasani
For many organizations, real-time data collection and data processing at scale can provide immense advantages for business and operational insights. The need for real-time data introduces technical challenges that require skilled expert experience to build custom integration for a successful real-time implementation.
For customers looking to implement streaming real-time applications, our partner Confluent recently announced a new Databricks Connector for Confluent Cloud. This new fully-managed connector is designed specifically for the data lakehouse and provides a powerful solution to build and scale real-time applications such as application monitoring, internet of things (IoT), fraud detection, personalization and gaming leaderboards. Organizations can now use an integrated capability that streams legacy and cloud data from Confluent Cloud directly into the Databricks Lakehouse for business intelligence (BI), data analytics and machine learning use cases on a single platform.
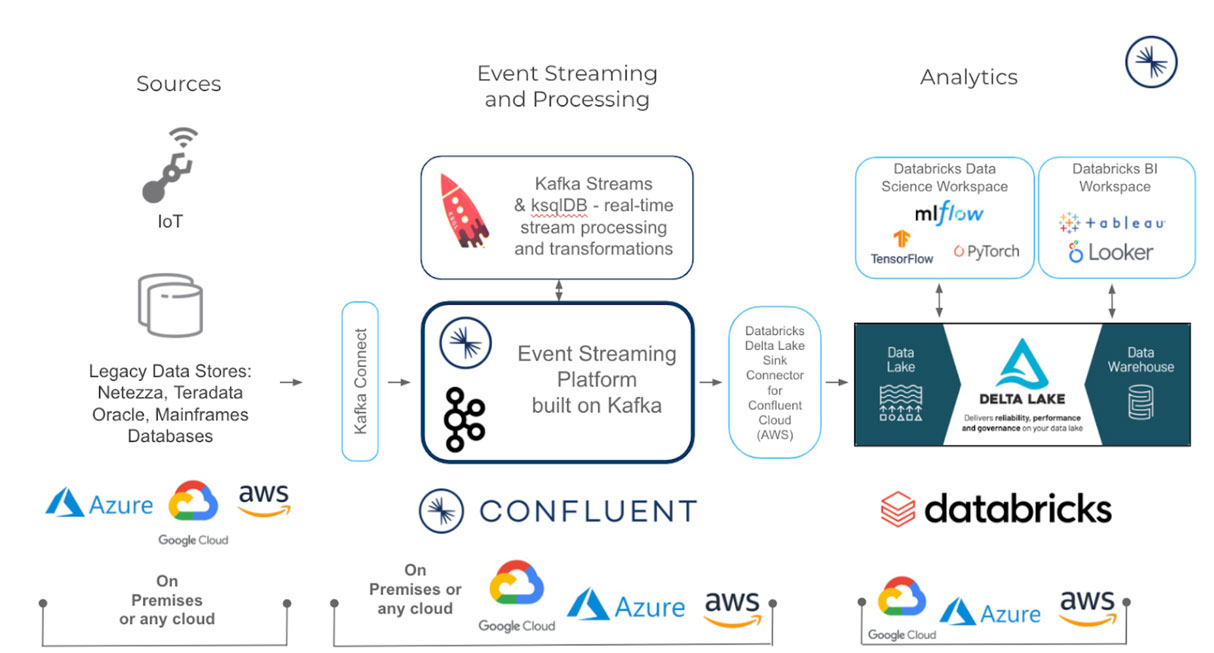
Utilizing the best of Databricks and Confluent
Streaming data through Confluent Cloud directly into Delta Lake on Databricks greatly reduces the complexity of writing manual code to build custom real-time streaming pipelines and hosting open source Kafka, saving hundreds of hours of engineering resources. Delta Lake provides reliability that traditional data lakes lack, enabling organizations to run analytics directly on their data lake for up to 50x faster time-to-insights. Once streaming data is in Delta Lake, you can unify it with batch data to build integrated data pipelines to power your mission-critical applications.
1. Streaming on-premises data for cloud analytics
Data teams can migrate from legacy data platforms to the cloud or across clouds with Confluent and Databricks. Confluent leverages its Apache Kafka footprint to reach into on-premises Kafka clusters from Confluent Cloud to create an instant cluster to cluster solution or provides rich libraries of fully-managed or self-managed connectors for bringing real-time data into Delta Lake. Databricks offers the speed and scale to manage your real-time application in production so you can meet your SLAs, improve productivity, make fast decisions, simplify streaming operations and innovate.
2. Streaming data for analysts and business users using SQL analytics
When it comes to building business-ready BI reports, querying data that is fresh and constantly updated is a challenge. Processing data at rest and in motion requires different semantics and often takes different skill sets. Confluent offers CDC connectors for multiple databases that import the most current event datastreams to consume as tables in Databricks. For example, a grocery delivery service needs to model a stream of shopper availability data and combine it with real-time customer orders to identify potential shipping delays. Using Confluent and Databricks, organizations can prep, join, enrich and query streaming data sets in Databricks SQL to perform blazingly fast analytics on stream data.
With up to 12x better price-performance than a traditional data warehouse, Databricks SQL unlocks thousands of optimizations to provide enhanced performance for real-time applications. The best part? It comes with pre-built integrations with popular BI tools such as Tableau and Power BI so the stream data is ready for first-class SQL development, allowing data analysts and business users to write queries in a familiar SQL syntax and build quick dashboards for meaningful insights.
3. Predictive analytics with ML models using streaming data
Building predictive applications using ML models to score historical data requires its own toolset. Add real-time streaming data into the mix and the complexity becomes multifold as the model now has to make predictions on new data as it comes in against static, historical data sets.
Confluent and Databricks can help solve this problem. Transform streaming data the same way you perform computations on batch data by feeding the most updated event streams from multiple data sources into your ML model. Databricks’ collaborative Machine Learning solution standardizes the full ML lifecycle from experimentation to production. The ML solution is built on Delta Lake so you can capture gigabytes of streaming source data directly from Confluent Cloud into Delta tables to create ML models, query and collaborate on those models in real-time. There are a host of other Databricks features such as Managed MLflow that automates experiment tracking and Model Registry for versioning and role-based access controls. Essentially, it streamlines cross-team collaboration so you can deploy real-time streaming data based operational applications in production -- at scale and low latency.
Getting Started with Databricks and Confluent Cloud
To get started with the connector, you will need access to Databricks and Confluent Cloud. Check out the Databricks Connector for Confluent Cloud documentation and take it for a spin on Databricks for free by signing up for a 14-day trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.