Structured Streaming: A Year in Review
As we enter 2022, we want to take a moment to reflect on the great strides made on the streaming front in Databricks and Apache Spark™ ! In 2021, the engineering team and open source contributors made a number of advancements with three goals in mind:
- Lower latency and improve stateful stream processing
- Improve observability of Databricks and Spark Structured Streaming workloads
- Improve resource allocation and scalability
Ultimately, the motivation behind these goals was to enable more teams to run streaming workloads on Databricks and Spark, make it easier for customers to operate mission critical production streaming applications on Databricks and simultaneously optimizing for cost effectiveness and resource usage.
Goal # 1: Lower latency & improved stateful processing
There are two new key features that specifically target lowering latencies with stateful operations, as well as improvements to the stateful APIs. The first is asynchronous checkpointing for large stateful operations, which improves upon a historically synchronous and higher latency design.
Asynchronous Checkpointing
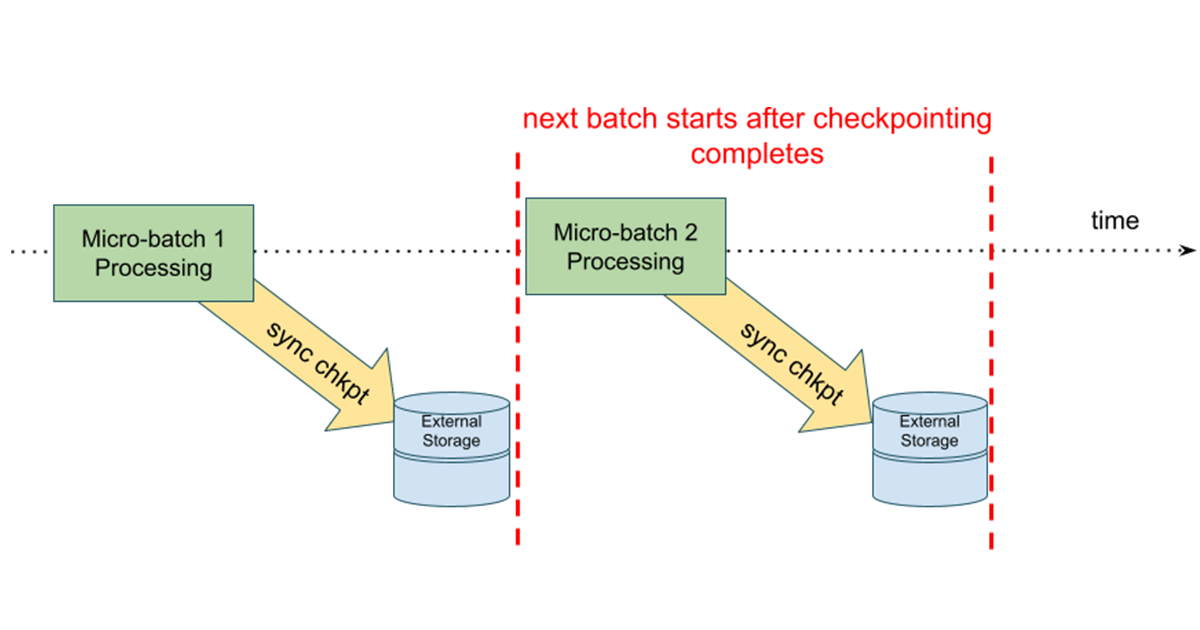
In this model, state updates are written to a cloud storage checkpoint location before the next microbatch begins. The advantage is that if a stateful streaming query fails, we can easily restart the query by using the information from the last successfully completed batch. In the asynchronous model, the next microbatch does not have to wait for state updates to be written, improving the end-to-end latency of the overall microbatch execution.
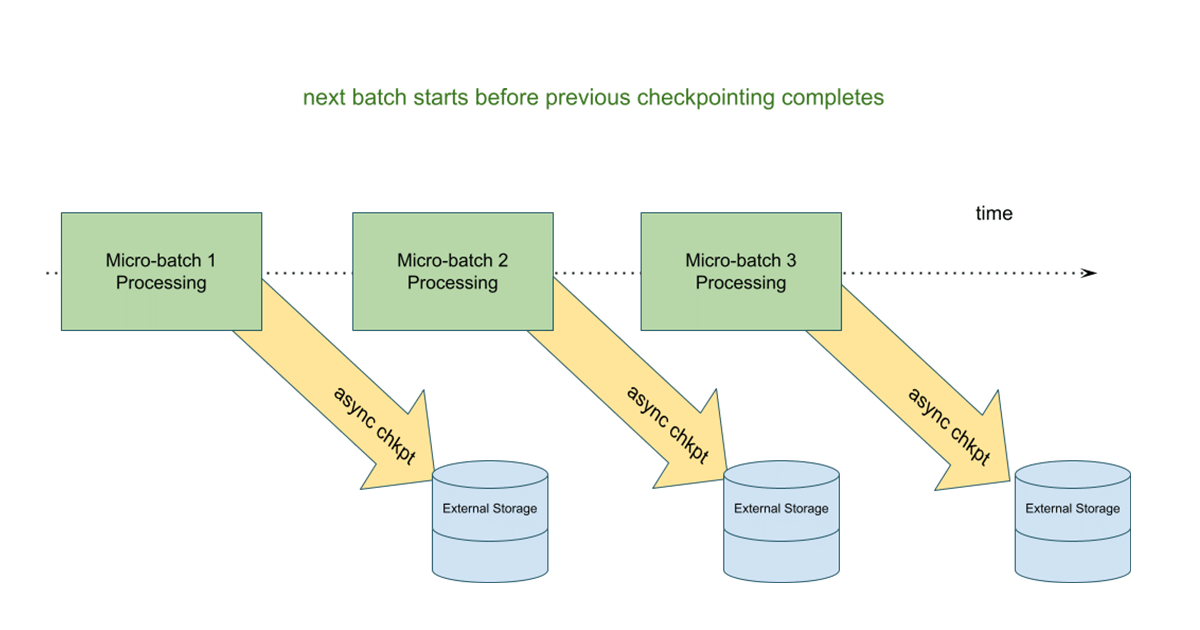
You can learn more about this feature in an upcoming deep-dive blog post, and try it in Databricks Runtime 10.3 and above.
Arbitrary stateful operator improvements
In a much earlier post, we introduced Arbitrary Stateful Processing in Structured Streaming with [flat]MapGroupsWithState. These operators provide a lot of flexibility and enable more advanced stateful operations beyond aggregations. We’ve introduced improvements to these operators that:
- Allow initial state, avoiding the need to reprocess all your streaming data.
- Enable easier logic testing by exposing a new TestGroupState interface, allowing users to create instances of GroupState and access internal values for what has been set, simplifying unit tests for the state transition functions.
Allow Initial State
Let’s start with the following flatMapGroupswithState operator:
This custom state function maintains a running count of fruit that have been encountered.
In this example, we specify the initial state to the this operator by setting starting values for certain fruit:
Easier Logic Testing
You can also now test state updates using the TestGroupState API.
You can find these, and more examples in the Databricks documentation.
Native support for Session Windows
Structured Streaming introduced the ability to do aggregations over event-time based windows using tumbling or sliding windows, both of which are windows of fixed-length. In Spark 3.2, we introduced the concept of session windows, which allow dynamic window lengths. This historically required custom state operators using flatMapGroupsWithState.
An example of using dynamic gaps:
Goal #2: Improve observability of streaming workloads
While the StreamingQueryListener API allows you to asynchronously monitor queries within a SparkSession and define custom callback functions for query state, progress, and terminated events, understanding back pressure and reasoning about where the bottlenecks are in a microbatch were still challenging. As of Databricks Runtime 8.1, the StreamingQueryProgress object reports data source specific back pressure metrics for Kafka, Kinesis, Delta Lake and Auto Loader streaming sources.
An example of the metrics provided for Kafka:
Databricks Runtime 8.3 introduces real-time metrics to help understand the performance of the RocksDB state store and debug the performance of state operations. These can also help identify target workloads for asynchronous checkpointing.
An example of the new state store metrics:
Goal # 3: Improve resource allocation and scalability
Streaming Autoscaling with Delta Live Tables (DLT)
At Data + AI Summit last year, we announced Delta Live Tables, which is a framework that allows you to declaratively build and orchestrate data pipelines, and largely abstracts the need to configure clusters and node types. We’re taking this a step further and introducing an intelligent autoscaling solution for streaming pipelines that improves upon the existing Databricks Optimized Autoscaling. These benefits include:
The new algorithm takes advantage of the new back pressure metrics to adjust cluster sizes to better handle scenarios in which there are fluctuations in streaming workloads, which ultimately leads to better cluster utilization.
While the existing autoscaling solution retires nodes only if they are idle, the new DLT Autoscaler will proactively shut down selected nodes when utilization is low, while simultaneously guaranteeing that there will be no failed tasks due to the shutdown.
- Better Cluster Utilization:
- Proactive Graceful Worker Shutdown:
As of writing, this feature is currently in Private Preview. Please reach out to your account team for more information.
Trigger.AvailableNow
In Structured Streaming, triggers allow a user to define the timing of a streaming query’s data processing. These trigger types can be micro-batch (default), fixed interval micro-batch (Trigger.ProcessingTime(“
Databricks Runtime 10.1 introduces a new type of trigger; Trigger.AvailableNow that is similar to Trigger.Once but provides better scalability. Like Trigger Once, all available data will be processed before the query is stopped, but in multiple batches instead of one. This is supported for Delta Lake and Auto Loader streaming sources.
Example:
Summary
As we head into 2022, we will continue to accelerate innovation in Structured Streaming, further improving performance, decreasing latency and implementing new and exciting features. Stay tuned for more information throughout the year!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.