Production-Ready and Resilient Disaster Recovery for DLT Pipelines
Implementing Multi-Region or Multi-Cloud Disaster Recovery for Delta Live Tables
by Tony Farias and Alex Ott
Disaster recovery is a standard requirement for many production systems, especially in the regulated industries. As many companies rely on data to make decisions, implementing disaster recovery is also required for data processing pipelines.
In particular, customers in regulated industries are often required to shield their applications from cloud and service outages by deploying in multi-region or multicloud architectures. Multi-region or multicloud patterns require coordination of failover and failback which can often lead to a complex set of steps and data being processed multiple times.
Many Databricks customers have implemented disaster recovery for workloads running on the Databricks Lakehouse Platform, although the implementation complexity heavily depends on the specific cloud providers, technologies and tools used. You can find more information about the general approach for disaster recovery for Databricks in documentation and in a series of blog post.
The goal of this blog is to show how Delta Live Tables (DLT) further simplifies and streamlines Disaster Recovery on Databricks, thanks to its capabilities around automatic retries in case of failures and data ingestion that ensures exactly-once processing. We do this by explaining our tested DR design, including Terraform code for orchestrating the implementation. The ultimate implementation that works best will depend on data sources, data flow patterns and RTO/RPO needs. We point out throughout the blog where this implementation can be generalized to suit customer needs.
Why does Disaster Recovery for Delta Live Tables Matter?
DLT is the first ETL framework that uses a simple declarative approach to building reliable data pipelines. DLT automatically manages your infrastructure at scale so data analysts and engineers can spend less time on tooling and focus on getting value from data.
As such DLT provides the following benefits to developers who use it:
- Accelerate ETL development: Declare SQL/Python and DLT automatically orchestrates the DAG, handles retries, changing data.
- Automatically manage your data & infrastructure: Automates complex tedious activities like recovery, auto-scaling, performance optimization, and data maintenance.
- Ensure high data quality: Deliver reliable data with built-in quality controls, testing, monitoring and enforcement
- Unify batch and streaming: Get the simplicity of SQL with the freshness of streaming with one unified API
Our design provides a streamlined approach to implementing DR policies across most DLT pipelines, further accelerating ETL development and allowing customers to meet their DR policy requirements.
Summary of the Design
When data is ingested using DLT, it is processed exactly once. This is useful for disaster recovery because identical DLT pipelines will produce identical table results if fed the same data stream (assuming that the data pipeline is not environment-dependent, eg, data batches depend on data arrival time). So a pipeline in a separate cloud region can produce the same results in most cases, if the pipeline has:
- The same definition in both primary and secondary regions
- Both pipelines receive the same data
For our solution, we set up a primary and a secondary DLT pipeline across two Databricks workspaces in distinct regions. Each pipeline has a separate landing zone, an append-only source of records that can be read using Auto Loader functionality. We use this layer from the landing zone to build a bronze layer. Subsequent transforms in the pipeline and tables are considered "silver layer" transforms, finishing with an end "gold layer" corresponding to our medallion architecture.
When a new file arrives, it should be copied to both landing zones in primary and secondary regions. How to do so depends on what source is available. In our implementation, the source system for raw data was Amazon DMS, so a DMS replication task was set up to write data to both landing zones. Similar setups could be done with Azure Data Factory or even a scheduled job that copies directly from one bucket to another.
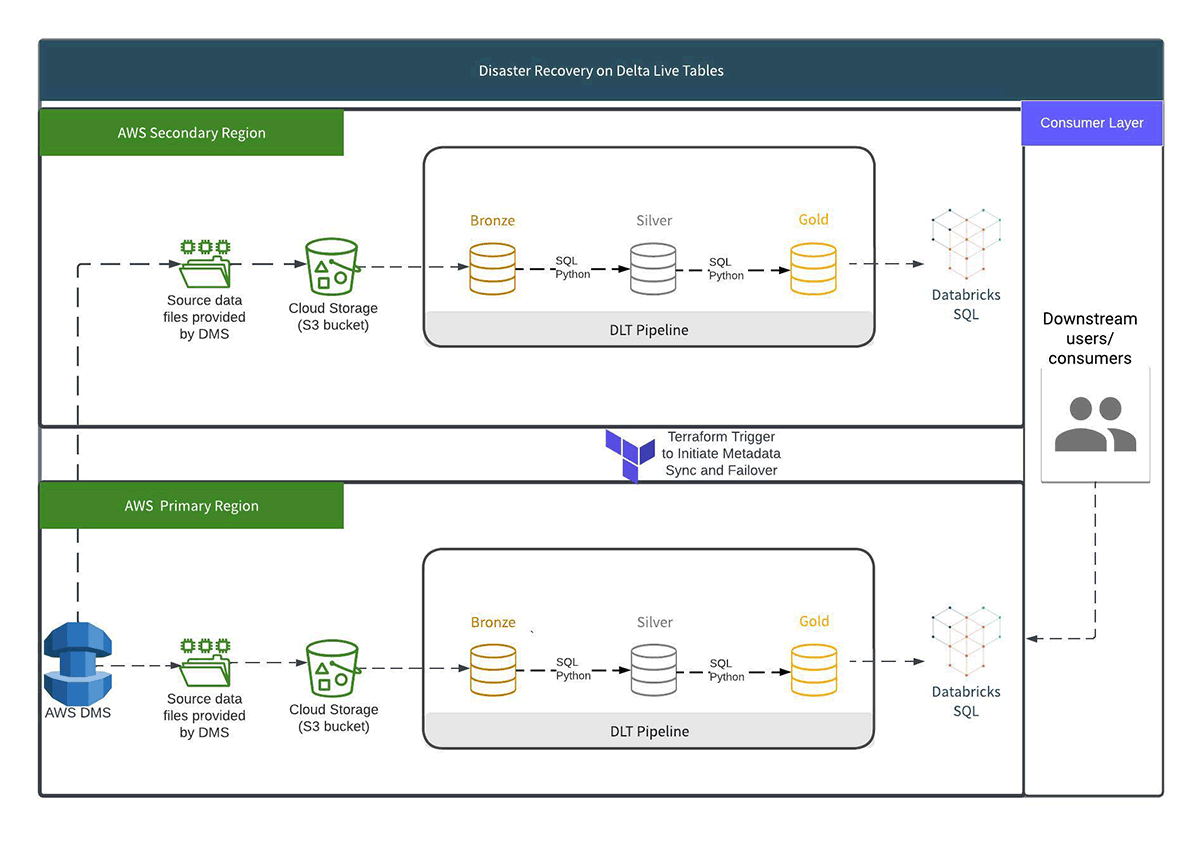
Design Considerations
Our design focuses primarily on regional outages for Databricks and AWS S3, though this same pattern can be generalized to other clouds or even a multicloud design. A full outage for the cloud provider (or a source system outage, like a Kafka cluster or AWS DMS) would require other considerations that would be specific to the cloud provider and the source system.
It is worth noting that this approach does not copy any Delta tables between regions. Rather, it utilizes identical landing zone data sets written to both the primary and secondary regions. The advantage of not copying tables across regions is that:
- the solution is simpler and does not involve any manual copying or scripts that a customer must implement
- table copies mean streaming checkpoints are lost due to underlying cloud infrastructure, so this approach to DR means streaming is still supported.
Finally, in our implementation, the primary pipeline ran continuously and the secondary was triggered at a regular interval but not continuously up. The trigger interval agreed upon was set to meet the customer's RTO/RPO requirements. Customers favor cost over processing times in the secondary region, the secondary pipeline can only be started sporadically - since Auto Loader will load in all of the files that have built up in the landing zone and have yet to be processed.
Illustrating failover and failback
We illustrate a set of steps required for failover and failback:
- During regular operations, data is being written to the primary and secondary landing zones. The primary region is used for regular pipeline operations and serving the processed data to consumers.
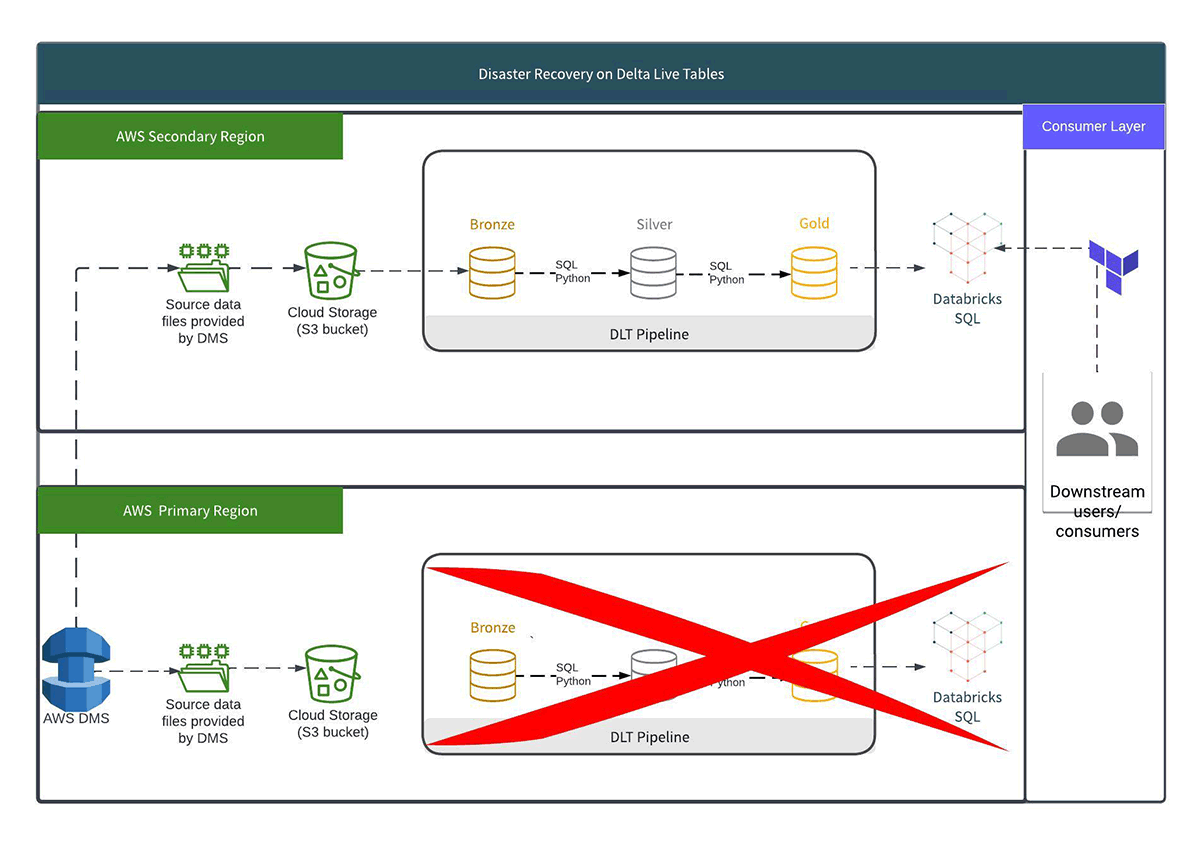
- Failover: After an outage in the primary region, the secondary region must be up. DLT begins processing any data in the landing zone that has not yet been consumed. Auto Loader checkpoints tell the pipeline which files have not yet been processed. Terraform can be used to kickstart the secondary region pipeline and to repoint consumers to the secondary region.
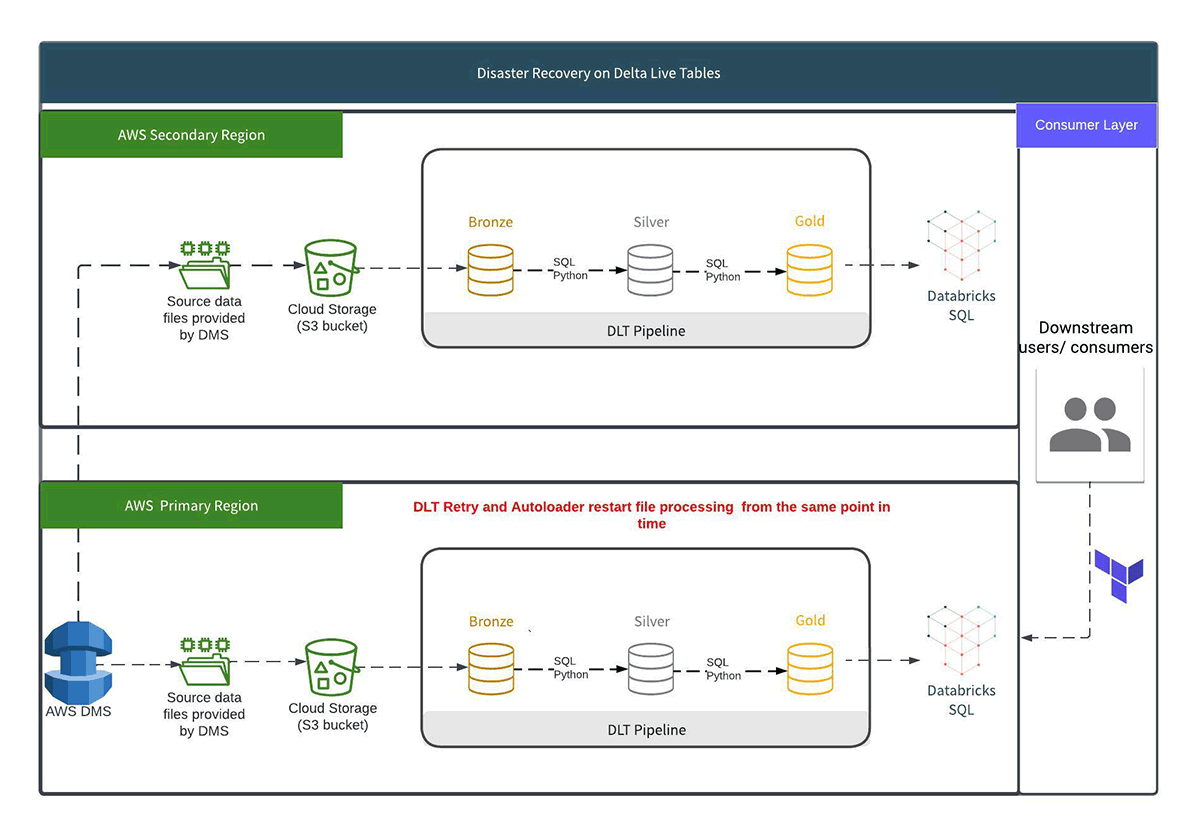
- Failback: When the outage in the primary region is resolved, the DLT pipeline in the primary region is restarted and automatically resumes consuming. Auto Loader checkpoints inform the pipeline which files have yet to be processed, and DLT will restart and auto-retry according to its schedule. The pipeline can be restarted with Terraform, data processed, and consumers directed back to the primary region.
We recommend using a timestamp that is common to both primary and secondary landing zones to detect when processing has caught up after failover/failback. This timestamp was provided by the source database records in our implementation.
For example, the latest message has an event_ timestamp of 2023-02-28T13:00:00Z. Even if event arrives in the primary region 5 minutes later than the secondary region, the message copied in both landing zones will have the same timestamp. The example query below will return the latest event timestamp processed in a region.
This allows you to answer questions like "Has my secondary region processed all events from before the start of the outage?".
Pipeline Consistency and Failover Techniques using Terraform
To prevent any manual work and enforce tracking of the changes in the pipelines, everything is implemented using Terraform as Infrastructure as Code solution. The code is organized as follows:
- DLT Pipeline is defined as a separate Terraform module. The module receives all necessary parameters (notebook paths, storage location, …), plus the
active_regionflag that specifies if the region is active (so the pipeline is running continuously) or not (execution of DLT pipeline is triggered by the Databricks Job). - Each region has its own configuration that uses the Terraform module, passing all necessary parameters, including flag specifying if this region is active or not.
The Terraform code is organized in repository as follows:

In case of failover, the configuration of the secondary region is updated by setting the active_region flag to true, and applying the changes. This will disable the Databricks job that triggers the DLT pipeline, and the pipeline will run continuously.
When failback happens, the configuration of the secondary region is updated again by setting the active_region flag to false and applying the changes. After that, the pipeline is switched back to the triggered mode driven by the Databricks Job.
The code for the Terraform module defining the DLT pipeline is below. It defines resources for Databricks notebooks, job and the pipeline itself:
And then each region calls the given module similar to the following:
Conclusion
Delta Live Tables is a resilient framework for ETL processing. In this blog, we discussed a disaster recovery implementation for Delta Live Tables that makes use of the features like automated retries, simple maintenance and optimization, and compatibility with Auto Loader to read a set of files that have been delivered to both primary and secondary regions. According to the RTO and RPO needs of a customer, pipelines are built up in two environments, and data can be routinely processed in the secondary region. Using the Terraform code we explain, pipelines can be made to start up for failover and failback, and consumers may be redirected. With the support of our Disaster Recovery solution, we intend to increase platform availability for users' workloads.
Make sure that your DLT pipelines aren't affected by service outages & give you access to the latest data. Review & implement a disaster recovery strategy for data processing pipelines!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.