Building the Trusted Research Environment with Azure Databricks
by Mike Dobing, Miguel Peralvo and Chris Booth
The importance and impact of data in healthcare is greater than it has ever been, with access to truly large-scale datasets and powerful analytical tooling creating the potential to deliver transformative outcomes for society. Such examples include the role of data in response to the COVID-19 pandemic and vaccine development. Take Austin Health, who onboarded 20k+ patients remotely during the pandemic to assess COVID-19 risk. By unlocking all of their data, including their electronic health record (EHR) system, their self-service COVID screen tool provided next-best-action to patients, reducing risk of infection by 85% by informing them to stay home. In reality the use cases are boundless. The Department for Health and Social Care whitepaper, "Data saves lives: reshaping health and social care with data" further highlights the impact that quality data assets can have across health and social care. In brief, it outlines four purposes of how data can be used:
- For the direct care of individuals
- To improve population health through the proactive targeting of services
- For the planning and improvement of services
- For the research and innovation that will power new medical treatments
To support these aims across the health industry, academia, and life sciences there is a need for researchers to access and collaborate on sensitive data. This can range from analysing electronic health records, through to exploring clinical trial results with the aspiration for researchers, analysts, and developers to create consumable outcomes from sensitive data that ultimately improve the life and wellbeing of citizens—without breaching data privacy laws.
However, current approaches often rely on many small projects working in silos with multiple copies of massive datasets being distributed across teams and projects. This leads to costs passed along to the consumer, making health care more expensive and less accessible.
In his paper, Better, broader, safer: using health data for research and analysis, Professor Ben Goldacre details the need for collaboration and highlights the challenges facing the research community caused by current approaches to research. Whilst the main challenge can best be summarised as "How do we facilitate access to NHS data by researchers, commissioners, and innovators, while preserving patient privacy?", there are other challenges beyond security that are caused by data being disseminated across multiple silos:
- Duplication risk – as data is distributed to many siloes, the inherent risk of data breaches and privacy violations is increased
- Limited central oversight – multiple siloes with their own governance layers and controls mean there is no central authority for governance, auditing and access control
- Duplication cost – multiple environments mean multiple technology implementations and costs, along with the associated resources to manage and maintain said environments
- Duplication of effort and complexities around data access, leading to a reduction in analytic quality
Discussed in detail in the Goldacre review, Trusted Research Environments (TREs) are solutions designed to deliver on these requirements and tackle the challenges head on. TREs provide secure environments and data platforms where researchers can collaborate and securely access sensitive data whilst providing the necessary tooling for them to produce valuable outputs and insights.
Although there is a lot of material available about TREs already, two further good resources are provided by HDR UK and NHS England (as NHS X) which go into great detail about the "why we need TREs" and the benefits they drive, with example benefits from NHS England shown below:

In the last few years, the need for such secure development areas for research and innovation has grown significantly, with the COVID-19 pandemic accelerating this shift. Examples of existing TRE programmes include the Scotland Data Safe Haven programme and the UK Secure eResearch Platform in Wales.
Although the need for TREs is well understood, there has not generally been a best approach or "blueprint" that can allow health organisations to deliver such an environment without considerable cost, effort and development. Versions of TREs can differ, with no "standard" approach out there. This has resulted in a plethora of TREs being produced, creating a complex landscape of solutions and approaches.
At a high level though, TREs generally look to adhere to the 5 Safes Framework around the responsible use of data:
- Safe People – Only trained and accredited researchers can access the data
- Safe Projects – Data is only used for ethical, approved research with the potential for clear public benefit
- Safe Settings – Access to data is only possible using secure technology systems
- Safe Data – Researchers only use data that have been de-identified to protect privacy
- Safe Outputs – All research outputs are checked to ensure they cannot be used to identify subjects
The high level architecture and data flow are well described with the graphic below from the Trusted Research Environments Guide for Beginners:
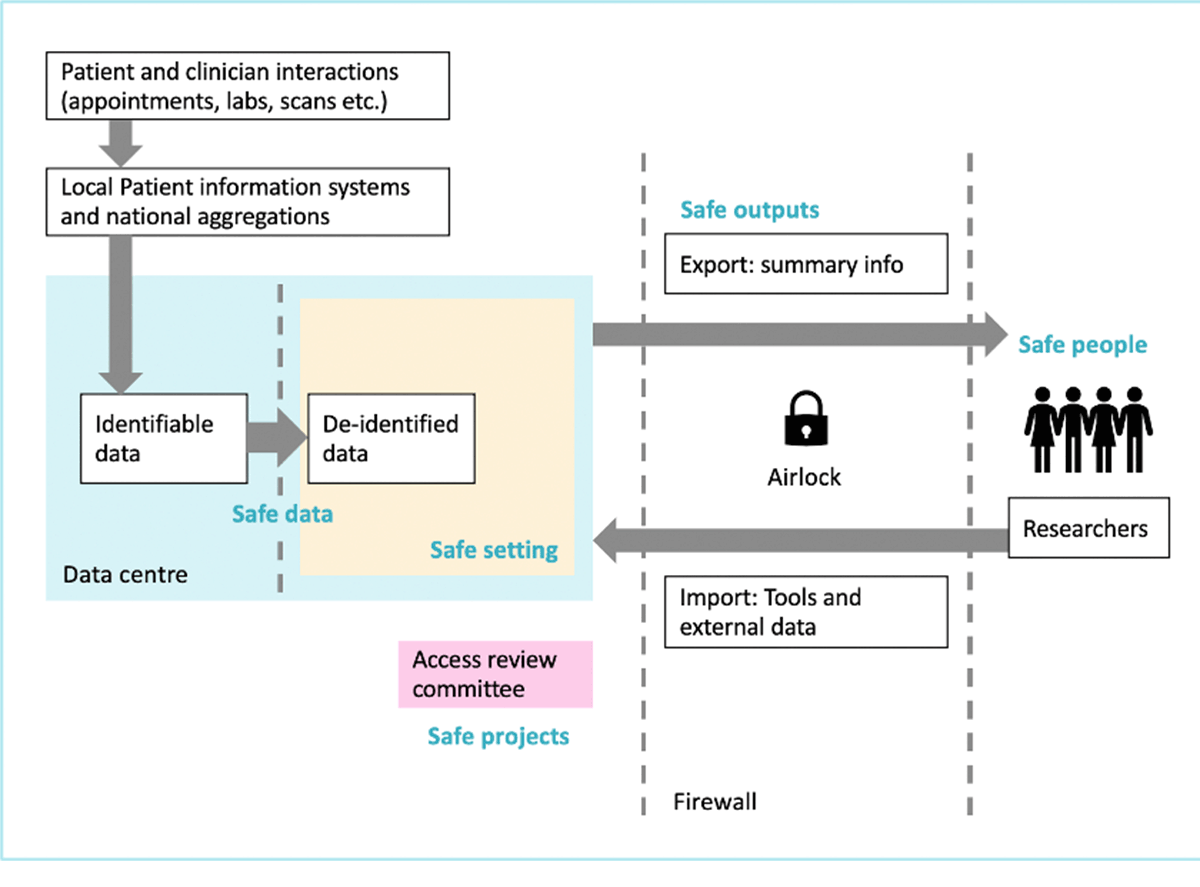
Azure Trusted Research Environment
With the above in mind, and aligning with the 5 Safes Framework, engineers within the Commercial Software Engineering (CSE) team at Microsoft sought to develop a templated approach that delivers the core features as needed for a TRE —but in an infrastructure-as-code method that not only enables TREs to be deployed within Microsoft Azure with ease, but also provides extensibility to allow you to bring your own tooling and platforms.
In short, the Azure TRE project is -
"...an accelerator to assist Microsoft customers and partners who want to build out Trusted Research Environments on Azure. This project enables authorised users to deploy and configure secure workspaces and researcher tooling without a dependency on IT teams."
As TREs are not one-size-fits-all (with different organisations and teams using different tools and platforms) — the Azure TRE provides a number of core features out of the box but has also been designed to be flexible, allowing teams to bring their own tools as required.
Core Technology features of the Azure Trusted Research Environment include the following:
- Airlock
- Self-service for administrators – workspace creation and administration
- Self-service for research teams – research tooling creation and administration
- Package and repository mirroring
- Extensible architecture – build your own service templates as required
- Azure Active Directory integration
- Cost reporting
- Ready to deploy workspace templates including:
- Restricted with data exfiltration control
- Unrestricted for open data
- Ready to go workspace service templates including:
- Virtual Desktops: Windows, Linux
- Azure Databricks
- Azure ML (Jupyter, R Studio, VS Code)
- MLflow, Gitea
Whilst this article doesn't go into the depths of the Azure TRE, a high level architecture of the pattern is shown below:
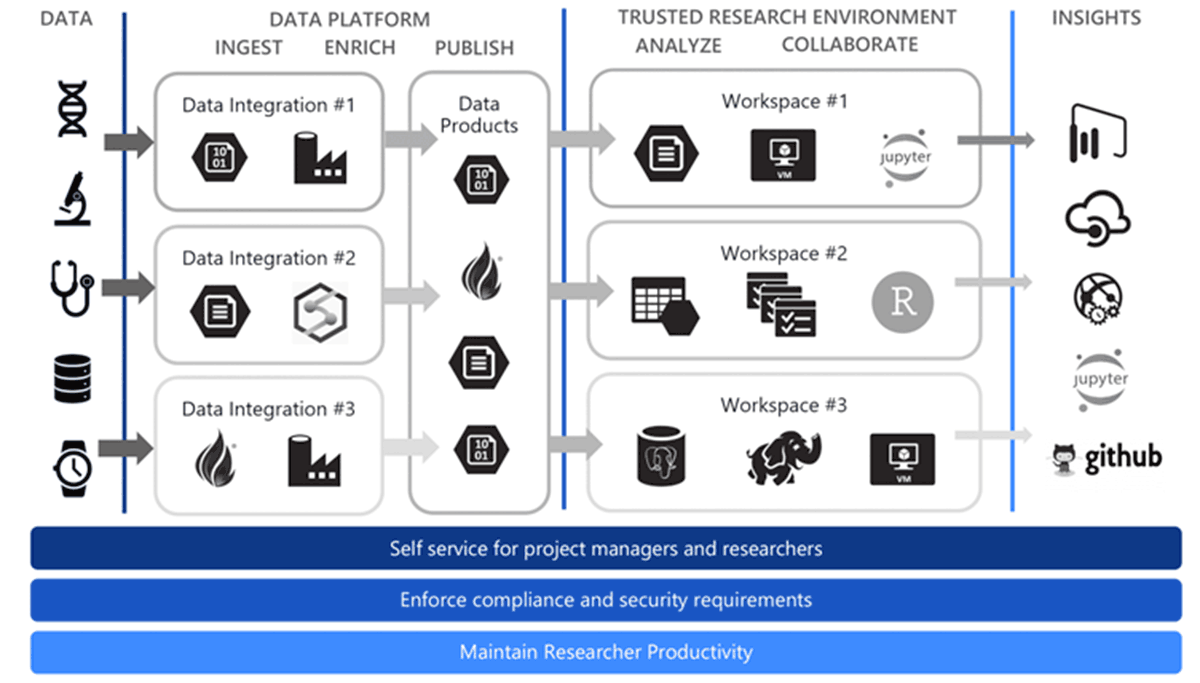
In the above diagram, raw data of different sizes, shapes and structures can be ingested into the platform, transformed using the tooling of your choice before being published into the core TRE where researchers can conduct their analysis and generate their necessary insights. The Azure TRE solution provides "Airlock" capabilities which is a critical feature allowing data to be imported and exported out of the secure boundary of the TRE — more details can be found here.
Workspaces and Workspace Services
The core templates for the Azure TRE provide deployable templates containing key Azure architecture components such as Virtual Networks, Storage Accounts and Key Vault. Although other workspace options can be used, the base template of the Azure TRE provides the necessary foundational components that the associated workspace services can be built on. These Workspace Services provide the actual services within the Workspace that are consumed with the TRE such as Azure ML and Apache Guacamole.
Azure Databricks
At Databricks we already provide powerful solutions for Healthcare and Life Sciences, including 360 degree patient view, population health analytics, real world evidence and more.
Building off our Lakehouse vision, the Databricks Lakehouse for Healthcare and Life Sciences aims to tackle for the four biggest challenges with data in HLS:

With these in mind, Databricks have created a prescriptive architectural vision that provides a unified data and AI platform designed to deliver transformative innovations in patient care and drug research and development:
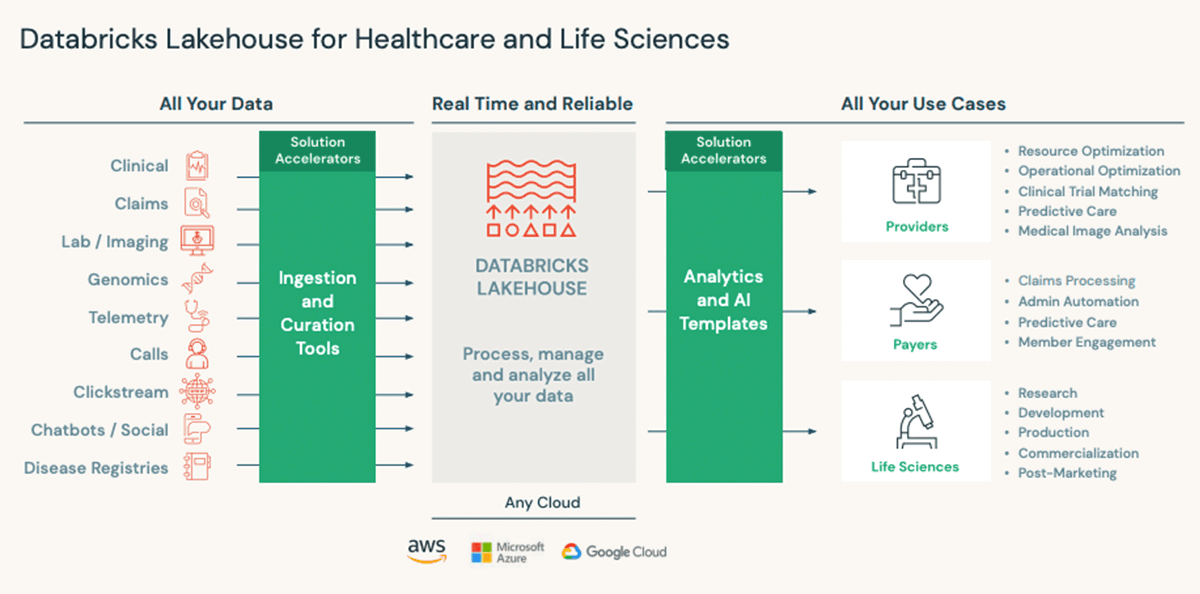
One such customer that has used the Lakehouse for Health and Life Sciences is Providence Health, one of the largest health providers in the United States. They leveraged Azure Databricks to reduce hospital overcrowding and improved their NEDOCS (National Emergency Department Overcrowding Score) by fully automating the pulling in of data from admittance, discharge and transfers, allowing clinicians to make informed, real-time decisions about patient care. Moreover, in an effort to make richer data available for medical research, Providence Health de-identified 700 million patient notes leveraging natural language processing (NLP).
This is just one example of Azure Databricks in Healthcare, with many more examples found here.
Azure TRE and Azure Databricks Together
Fast forward to January 2023, driven by growing use and demand for Azure Databricks in research environments and due to excellent work delivered by the CSE team at Microsoft (specifically Anuj Parashar, Guy Bertental and Marcus Robinson) — We are now pleased to announce that Azure Databricks has now been added into the Azure TRE blueprint as one of the Workspace Services. This means that consumers of the Azure TRE can now benefit from the power of Azure Databricks, including industry-leading Spark, open lakehouse platform with Delta, Notebooks, Machine Learning, SQL and many other features — all deployable "out of the box" by the Azure TRE solution accelerator.
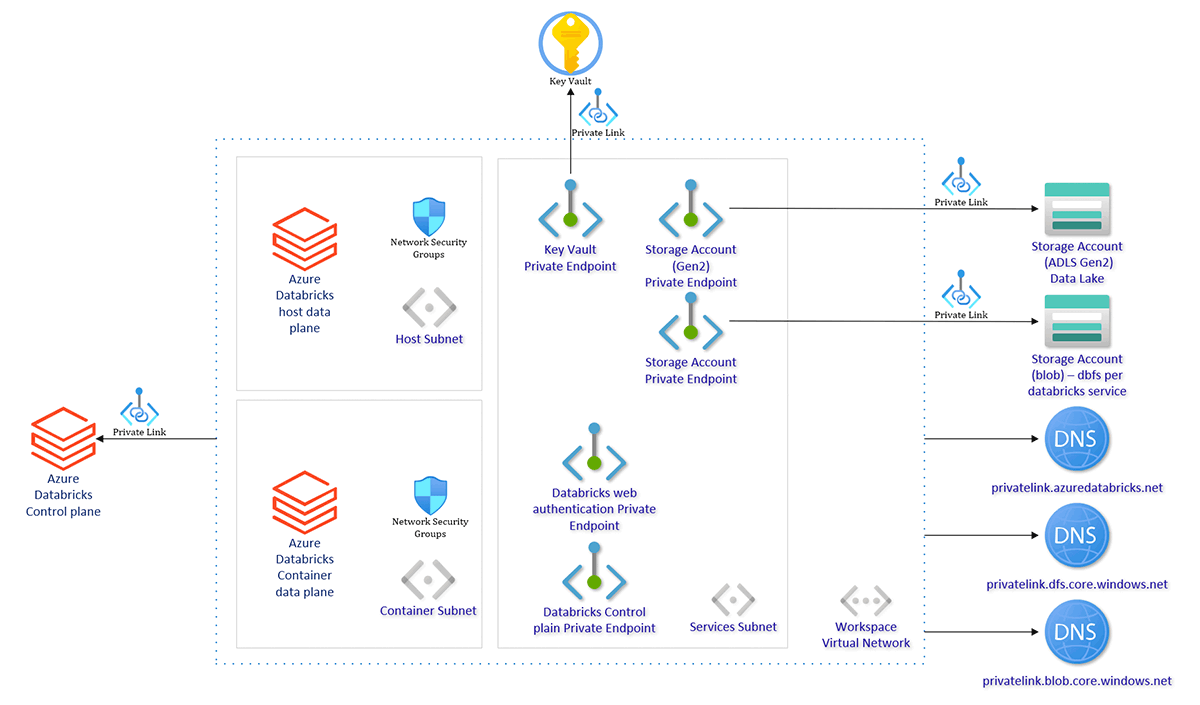
As Azure Databricks is a first party Azure service it readily integrates into the broader Azure ecosystem such as Azure ML and Azure Health Services, providing a complete solution for research and analytical needs of health, academia and industry respectively, whilst providing the capabilities described above in the Databricks Lakehouse for Health and Life Sciences.
By adding Azure Databricks to the Azure TRE, researchers can build rich reports and dashboards, create machine learning models and performed data engineering and transformation on large scale datasets using R, Python, Scala or SQL on an open, extensible big data platform within the secure boundary of the Trusted Research Environment.
University College London Hospital NHS Foundation Trust (UCLH) and the FlowEHR Project
One such early adopter of the Azure TRE is UCLH, part of the National Health Service (NHS) in the UK. As part of their FlowEHR (pronounced like flower) project UCLH are using the Azure TRE and Azure Databricks to provide "an open-source platform for iterative, safe and reproducible development and deployment of data science solutions inside the NHS".
Still in development at the time of writing, the FlowEHR project delivers against the 5 Safes framework and aims to provide:
- Iterative and robust with sustainable development and deployment of cutting-edge digital solutions inside NHS organisations
- Provide an open-source technology and governance platform which allows teams to work higher up the stack where they can focus on improving patient outcomes and health system efficiency
- Offer a well-trodden happy path to NHS organisations which can be adapted to their position on the digital transformation journey
- Contribute to the diverse community of innovators and researchers working on crossing the healthcare AI chasm
The FlowEHR implementation is an excellent example of the Azure TRE's extensibility and with the introduction of Azure Databricks this is now allowing them to build powerful data pipelines on an open platform that can support the aspirations of the programme.
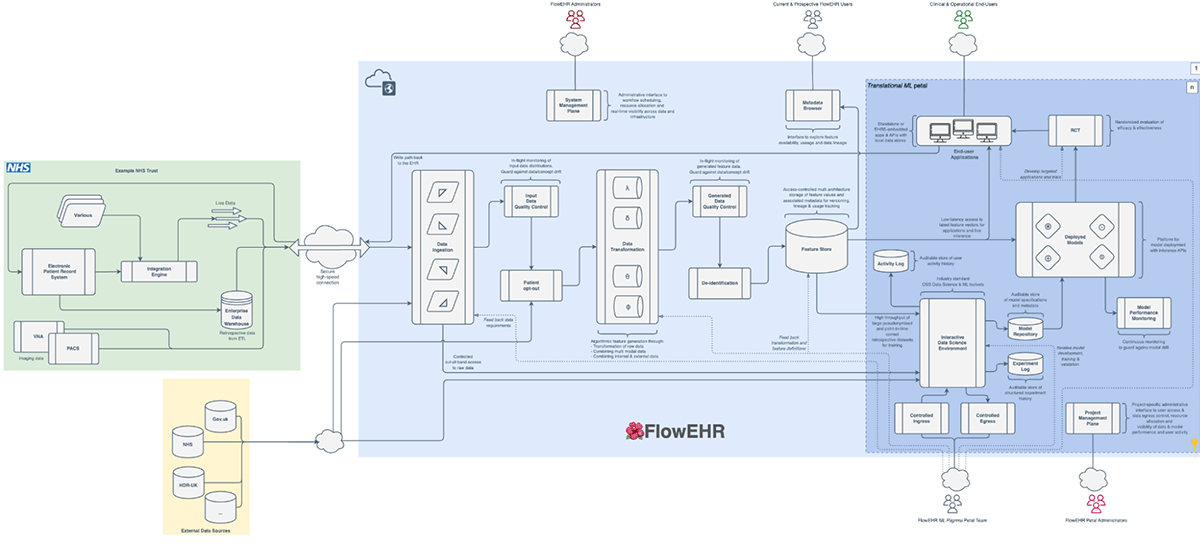
The FlowEHR project is comprised of a team of software engineers, data scientists, clinicians, academic researchers and operational staff based at UCLH - you can read more about the excellent work they're doing here.
Data-driven innovation in health and life sciences is providing more opportunities for improving health services and population health than ever before, with the impact of such initiatives clearly shown in the response to the COVID-19 pandemic. The ability to deploy solution accelerators such as the Azure TRE, now including the market-leading features of Azure Databricks, means that more organisations and researchers can take advantage of these offerings than were previously able.
If you are a healthcare, academic or industry institution looking to deploy a Trusted Research Environment on your own Azure environment, or are already using Azure Databricks but want to incorporate it into a secure research area for collaboration with other organisations, then please check out the Azure TRE solution accelerator.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.