Building a Modern Clinical Trial Data Intelligence Platform
by Oleksandra Bovkun and Neha Pande
In an era where data is the lifeblood of medical advancement, the clinical trial industry finds itself at a critical crossroads. The current landscape of clinical data management is fraught with challenges that threaten to stifle innovation and delay life-saving treatments.
As we grapple with an unprecedented deluge of information—with a typical Phase III trial now generating a staggering 3.6 million data points, which is three times more than 15 years ago, and more than 4000 new trials authorized each year—our existing data platforms are buckling under the strain. These outdated systems, characterized by data silos, poor integration, and overwhelming complexity, are failing researchers, patients, and the very progress of medical science. The urgency of this situation is underscored by stark statistics: about 80% of clinical trials face delays or premature termination due to recruitment challenges, with 37% of research sites struggling to enroll adequate participants.
These inefficiencies come at a steep cost, with potential losses ranging from $600,000 to $8 million each day a product's development and launch is delayed. The clinical trials market, projected to reach $886.5 billion by 2032 [1], demands a new generation of Clinical Data Repositories (CDR).
Reimagining Clinical Data Repositories (CDR)
Typically, clinical trial data management relies on specialized platforms. There are many reasons for this, starting from the standardized authorities’ submission process, the user’s familiarity with specific platforms and programming languages, and the ability to rely on the platform vendor to deliver domain knowledge for the industry.
With the global harmonization of clinical research and the introduction of regulatory-mandated electronic submissions, it's essential to understand and operate within the framework of global clinical development. This involves applying standards to develop and execute architectures, policies, practices, guidelines, and procedures to manage the clinical data lifecycle effectively.
Some of these processes include:
- Data Architecture and Design: Data modeling for clinical data repositories or warehouses
- Data Governance and Security: Standards, SOPs, and guidelines management together with access control, archiving, privacy, and security
- Data Quality and Metadata management: Query management, data integrity and quality assurance, data integration, external data transfer, including metadata discovery, publishing, and standardization
- Data Warehousing, BI, and Database Management: Tools for data mining and ETL processes
These elements are crucial for managing the complexities of clinical data effectively.
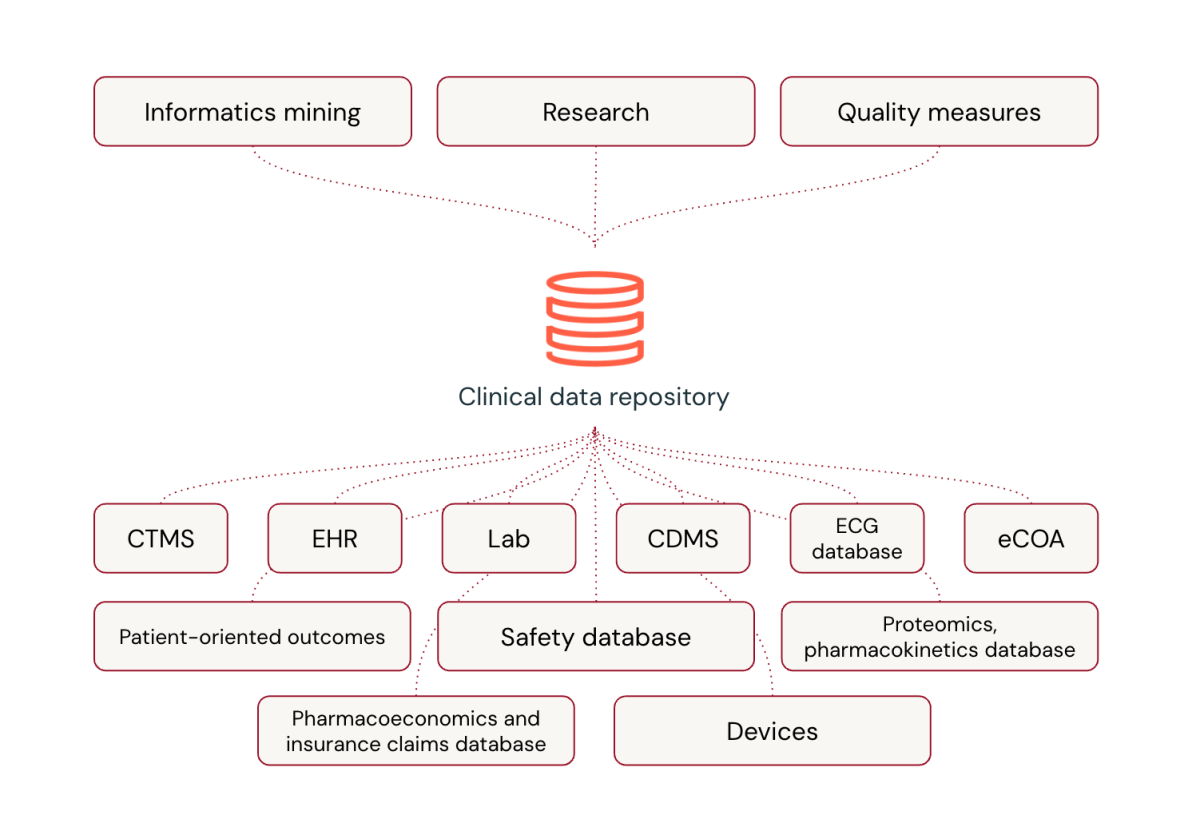
Universal platforms are transforming clinical data processing in the pharmaceutical industry. While specialized software has been the norm, universal platforms offer significant advantages, including the flexibility to incorporate novel data types, near real-time processing capabilities, integration of cutting-edge technologies like AI and machine learning, and robust data processing practices refined by handling massive data volumes.
Despite concerns about customization and the transition from familiar vendors, universal platforms can outperform specialized solutions in clinical trial data management. Databricks, for example, is revolutionizing how Life Sciences companies handle clinical trial data by integrating diverse data types and providing a comprehensive view of patient health.
In essence, universal platforms like Databricks are not just matching the capabilities of specialized platforms – they're surpassing them, ushering in a new era of efficiency and innovation in clinical trial data management.
Leveraging the Databricks Data Intelligence Platform as a foundation for CDR
The Databricks Data Intelligence Platform is built on top of lakehouse architecture. Lakehouse architecture is a modern data architecture that combines the best features of data lakes and data warehouses. This corresponds well to the needs of the modern CDR.
Although most clinical trial data represent structured tabular data, new data modalities like imaging and wearable devices are gaining popularity. They are the new way of redefining the clinical trials process. Databricks is hosted on cloud infrastructure, which gives the flexibility of using cloud object storage to store clinical data at scale. It allows storing all data types, controlling costs (older data can be moved to the colder tiers to save costs but accommodate regulatory requirements of keeping data), and data availability and replication. On top of this, using Databricks as the underlying technology for CDR allows one to move to the agile development model where new features can be added in controlled releases in opposition to Big Bang software version updates.
The Databricks Data Intelligence Platform is a full-scale data platform that brings data processing, orchestration, and AI functionality to one place. It comes with many default data ingestion capabilities, including native connectors and possibly implementing custom ones. It allows us to integrate CDR with data sources and downstream applications easily. This ability provides flexibility and end-to-end data quality and monitoring. Native support of streaming allows to enrich CDR with IoMT data and gain near real-time insights as soon as data is available. Platform observability is a big topic for CDR not only because of strict regulatory requirements but also because it enables secondary use of data and the ability to generate insights, which ultimately can improve the clinical trial process overall. Processing clinical data on Databricks allows for implementation of the flexible solutions to gain insight into the process. For instance, is processing MRI images more resource-consuming than processing CT test results?
Implementing a Clinical Data Repository: A Layered Approach with Databricks
Clinical Data Repositories are sophisticated platforms that integrate the storage and processing of clinical data. Lakehouse medallion architecture, a layered approach to data processing, is particularly well-suited for CDRs. This architecture typically consists of three layers, each progressively refining data quality:
- Bronze Layer: Raw data ingested from various sources and protocols
- Silver Layer: Data conformed to standard formats (e.g., SDTM) and validated
- Gold Layer: Aggregated and filtered data ready for review and statistical analysis
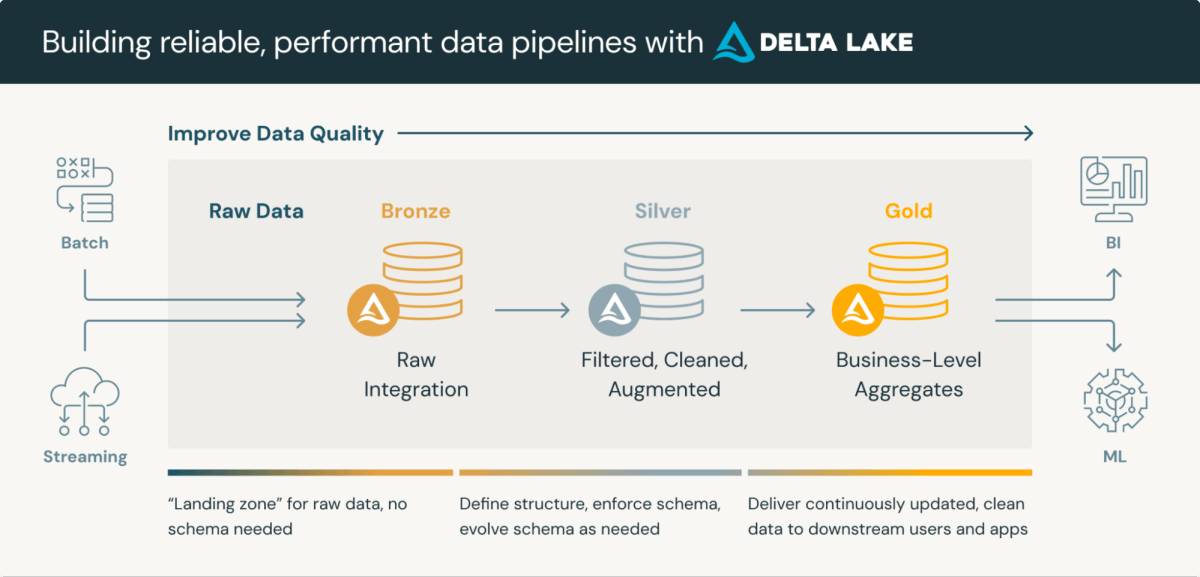
Utilizing Delta Lake format for data storage in Databricks offers inherent benefits such as schema validation and time travel capabilities. While these features need enhancement to fully meet regulatory requirements, they provide a solid foundation for compliance and streamlined processing.
The Databricks Data Intelligence Platform comes equipped with robust governance tools. Unity Catalog, a key component, offers comprehensive data governance, auditing, and access control within the platform. In the context of CDRs, Unity Catalog enables:
- Tracking of table and column lineage
- Storing data history and change logs
- Fine-grained access control and audit trails
- Integration of lineage from external systems
- Implementation of stringent permission frameworks to prevent unauthorized data access
Beyond data processing, CDRs are crucial for maintaining records of data validation processes. Validation checks should be version-controlled in a code repository, allowing multiple versions to coexist and link to different studies. Databricks supports Git repositories and established CI/CD practices, enabling the implementation of a robust validation check library.
This approach to CDR implementation on Databricks ensures data integrity and compliance and provides the flexibility and scalability needed for modern clinical data management.

The Databricks Data Intelligence Platform inherently aligns with FAIR principles of scientific data management, offering an advanced approach to clinical development data management. It enhances data findability, accessibility, interoperability, and reusability while maintaining robust security and compliance at its core.
Challenges in Implementing Modern CDRs
No new approach comes without challenges. Clinical data management relies heavily on SAS, while modem data platforms mainly utilize Python, R, and SQL. This obviously introduces not only technical disconnect but also more practical integration challenges. R is a bridge between two worlds — Databricks partners with Posit to deliver first-class R experience for R users. At the same time, integrating Databricks with SAS is possible to support migrations and transition. Databricks Assistant allows users who are less familiar with the particular language to get the support required to write high-quality code and understand the existing code samples.
A data processing platform built on top of a universal platform will always be behind in implementing domain-specific features. Strong collaboration with implementation partners helps mitigate this risk. Additionally, adopting a consumption-based price model requires extra attention to costs, which need to be addressed to ensure the platform's monitoring and observability, proper user training, and adherence to best practices.
The biggest challenge is the overall success rate of these types of implementations. Pharma companies are constantly looking into modernizing their clinical trial data platforms. It’s an appealing area to work on to shorten the clinical trial duration or discontinue trials that are not likely to become successful faster. The amount of data collected now by the average pharma company contains a vast amount of insights that are only waiting to be discussed. At the same time, the majority of such projects fail. Although there is no silver bullet recipe to ensure a 100% success rate, adopting a universal platform like Databricks allows implementing CDR as a thin layer on top of the existing platform, removing the pain of common data and infrastructure issues.
What’s next?
Every CDR implementation starts with the inventory of the requirements. Although the industry follows strict standards for both data models and data processing, understanding the boundaries of CDR in every organization is essential to ensure project success. Databricks Data Intelligence Platform can open many additional capabilities to CDR; that’s why understanding how it works and what it offers is required. Start with exploring Databricks Data Intelligence Platform. Unified governance with Unity Catalog, data ingestion pipelines with Lakeflow, data intelligence suite with AI/BI and AI capabilities with Databricks shouldn’t be unknown terms to implement a successful and future-proof CDR. Additionally, integration with Posit and advanced data observability functionally should open up the possibility of looking at CDR as a core of the Clinical data ecosystem rather than just another part of the overall clinical data processing pipeline.
More and more companies are already modernizing their clinical data platforms by utilizing modern architectures like Lakehouse. But the big change is yet to come. The expansion of Generative AI and other AI technologies is already revolutionizing other industries, while the pharma industry is lagging behind because of regulatory restrictions, high risk, and price for the wrong outcomes. Platforms like Databricks allow cross-industry innovation and data-driven development to clinical trials and create a new way of thinking about clinical trials in general.
Get started today with Databricks.
Citation:
[1] Clinical Trials Statistics 2024 By Phases, Definition, and Interventions
[2] Lu, Z., & Su, J. (2010). Clinical data management: Current status, challenges, and future directions from industry perspectives. Open Access Journal of Clinical Trials, 2, 93–105. https://doi.org/10.2147/OAJCT.S8172
Learn more about the Databricks Data Intelligence Platform for Healthcare and Life Sciences.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.