Cybersecurity Lakehouses Best Practices Part 4: Data Normalization Strategies
Lessons learned in the field: Strategies for normalizing cybersecurity data into a common information model
by Derek King
In this four-part blog series "Lessons learned from building Cybersecurity Lakehouses," we are discussing a number of challenges organizations face with data engineering when building out a Lakehouse for cybersecurity data, and offer some solutions, tips, tricks, and best practices that we have used in the field to overcome them.
In part one, we began with uniform event timestamp extraction. In part two, we looked at how to spot and handle delays in log ingestion. And in part three, we tackled how to parse semi-structured, machine-generated data. In this final part of the series, we discuss one of the most important aspects of cyber analytics: data normalization using a common information model.
By the end of this blog, you will have a solid understanding of some of the issues faced when normalizing data into a Cybersecurity Lakehouse and the techniques we can use to overcome them.
What is a Common Information Model (CIM)?
A Common Information Model (CIM) is needed for cyber security analytics engines to facilitate effective communication, interoperability, and understanding of security-related data and events across disparate systems, applications, and devices within an organization.
Organizations have different systems and applications that generate logs and events in different structures and formats. A CIM provides a standardized model that defines common data structures, attributes, and relationships. This standardization allows analytics engines to normalize and harmonize data collected from disparate sources, making it easier to process, analyze, and correlate information effectively.
Why use a Common Information Model?
Organizations use a variety of security tools, applications, and devices from different vendors, which generate logs specific to their respective technologies. Normalizing data into a known set of structures with consistent and understandable naming conventions is crucial to enable data correlation, threat detection, and incident response functions.
As a working example, suppose we wanted to know which systems and applications user 'Joe' has successfully authenticated against within the last 30 days.
To answer this question without a single model to interrogate, an analyst would be required to craft queries to search tens or hundreds of logs. Each log file reports the username and the result of any authentication results (success or failure) as different field names with different values. The app field name could also be different as well as the event time. This is not a workable solution. Enter the Common Information Model and the normalization process!
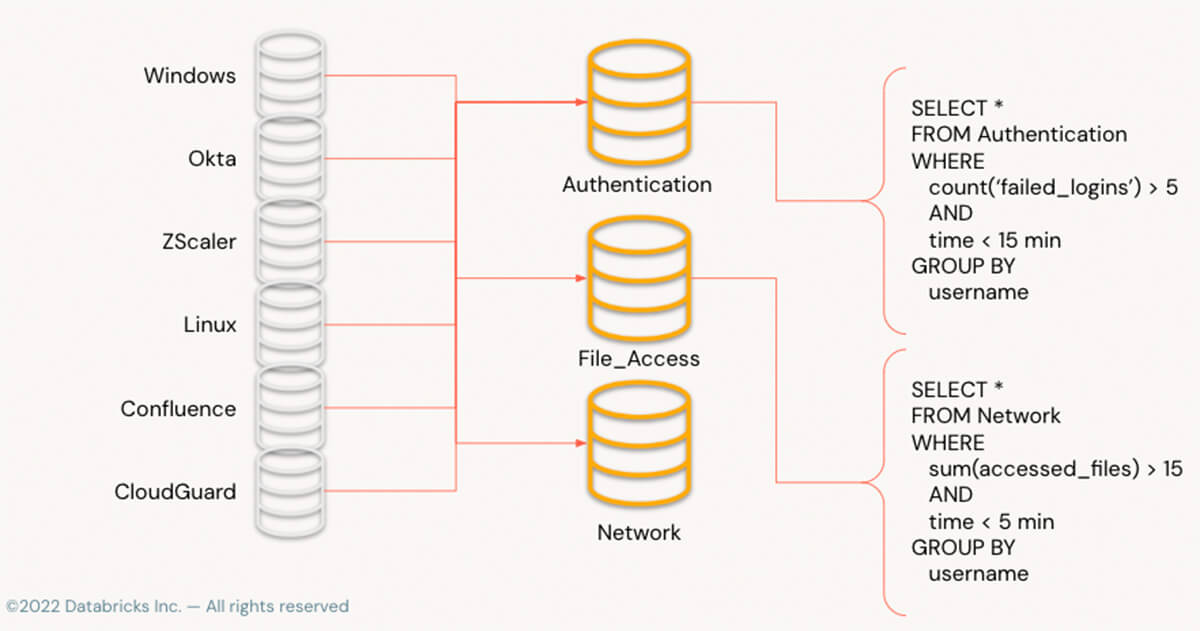
The image above shows how disparate logs from many sources filter events into event-specific tables, using known column names, allowing a single simple query to answer the question once data has been normalized.
Things to consider when normalizing data
There are a number of conditions that should be accounted for when normalizing disparate data sources into a single CIM-compliant table:
Differing Column Types: Unifying disparate data sources and specific events into the CIM (event-driven) table may have clashing data types.
Derived Fields: The normalization process often requires new fields to be derived from one or more source columns.
Missing Fields: Fields may unexpectedly not exist or contain null values. Ensure the CIM caters to missing or null value data types.
Literal Fields: Data to support a target CIM field may need to be created, or the field may need to be set to a literal value such as "Success" or "Failure" to ensure a unified search capability. For example (where action="Success")
Schema Evolution: Both data and the CIM may evolve over time. Ensure you have a mechanism to provide backward compatibility, especially within the CIM tables, to cater for changes in data.
Enrichment: CIM data is often enriched with other context such as threat data and asset information. Consider how to add this information to provide a comprehensive view of the events collected.
Which model should I choose?
There are many common Information models to choose from when building out a Cybersecurity Lakehouse, from open source models to vendor-specific publically available models. The decision on what to use depends mainly on your individual use case.
Some considerations are:
- Are you augmenting Delta Lake with another SIEM or SOAR product? Does it make sense to adopt that one for easier integration?
- Are you only building a Cybersecurity Lakehouse for a specific use case? For instance, do you only want to analyze Microsoft endpoint data? If so, does it make sense to align with Microsoft ASIM model?
- Are you building out a Lakehouse as your organization's predominant cyber analytics platform? Does it make sense to align with an open source model like OCSF or OSSEM or build your own?
Ultimately, the choice is organizational-specific, depending on your needs. Another consideration is the completeness of the model you choose. Models are generic and will likely require some adaptation to fit your needs; however they should mainly support your data and requirements before you begin adopting the model, as model changes after the fact are time-consuming.
Tips and best practices
Regardless of the model you choose, there are a few tips to ensure gaps do not exist in your overall security posture.
- Most queries rely heavily on entities. Source host, destination host, source user, and application used are likely the most searched for columns in any table. Ensure these are well-mapped and normalized.
- Models typically provide guidance on field coverage (mandatory, recommended, optional). Ensure at a minimum that mandatory fields are mapped and have data integrity checks applied tfor a consistent search environment.
Conclusion
Common Information Model-based tables are a cornerstone of an effective cyber analytics platform. The model you adopt when building out a Cybersecurity Lakehouse is organization-specific, but any model should largely be suitable for your organization's needs before you begin. Databricks has previously solved this problem for customers using the principles outlined in the blog.
Get in Touch
If you want to learn more about how Databricks cyber solutions can empower your organization to identify and mitigate cyber threats, contact cybersecurity@databricks.com and check out our Lakehouse for Cybersecurity Applications webpage.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.