Databricks SQL Year in Review (Part I): AI-optimized Performance and Serverless Compute
Reinventing Data Warehousing using AI
by Jeremy Lewallen, Gaurav Saraf, Mostafa Mokhtar, Kevin Clugage and Joe Harris
This is part 1 of a blog series where we look back at the major areas of progress for Databricks SQL in 2023, and in our first post we are focusing on performance. Performance for a data warehouse is important because it makes for a more responsive user experience and better price/performance, especially in the modern SaaS world where compute time drives cost. We have been working hard to deliver the next set of performance advancements for Databricks SQL while reducing the need for manual tuning through the use of AI.
AI-optimized Performance
Modern data warehouses are filled with workload-specific configurations that need to be manually tuned by a knowledgeable administrator on a continuous basis as new data, more users or new use cases come in. These "knobs" range from how data is physically stored to how compute is utilized and scaled. Over the past year, we have been applying AI to remove these performance and administrative knobs in alignment with Databricks' vision for a Data Intelligence Platform:
- Serverless Compute is the foundation for Databricks SQL, providing the best performance with instant and elastic compute that lowers costs and enables you to focus on delivering the most value to your business rather than managing infrastructure.
- Predictive I/O eliminates performance tuning like indexing by intelligently prefetching data using neural networks. It also achieves faster writes using merge-on-read techniques without performance tradeoffs. Early customers have benefited from a remarkable 35x improvement in point lookup efficiency, impressive performance boosts of 2-6x for MERGE operations and 2-10x for DELETE operations.
- Automatic data layout intelligently optimizes file sizes to provide the best performance automatically based on query patterns. This self-manages cost and performance.
- Results caching improves query result caching by using a two-tier system with a local cache and a persistent remote cache across all serverless warehouses in a workspace. These caching mechanisms are automatically managed based on the query requirements and available resources.
- Predictive Optimization (public preview, blog) Databricks will seamlessly optimize file sizes and clustering by running OPTIMIZE, VACUUM, ANALYZE and CLUSTERING commands for you. With this feature, Anker Innovations benefited from a 2.2x boost to query performance while delivering 50% savings on storage costs.
- Liquid Clustering (public preview, blog): automatically and intelligently adjusts the data layout as new data comes in based on clustering keys. This avoids over- or under-partitioning problems that can occur and results in up to 2.5x faster clustering relative to Z-order.
These innovations have enabled us to make significant advances in performance without increasing complexity for the user or costs.
Continued Class-leading Performance and Cost Efficiency for ETL Workloads
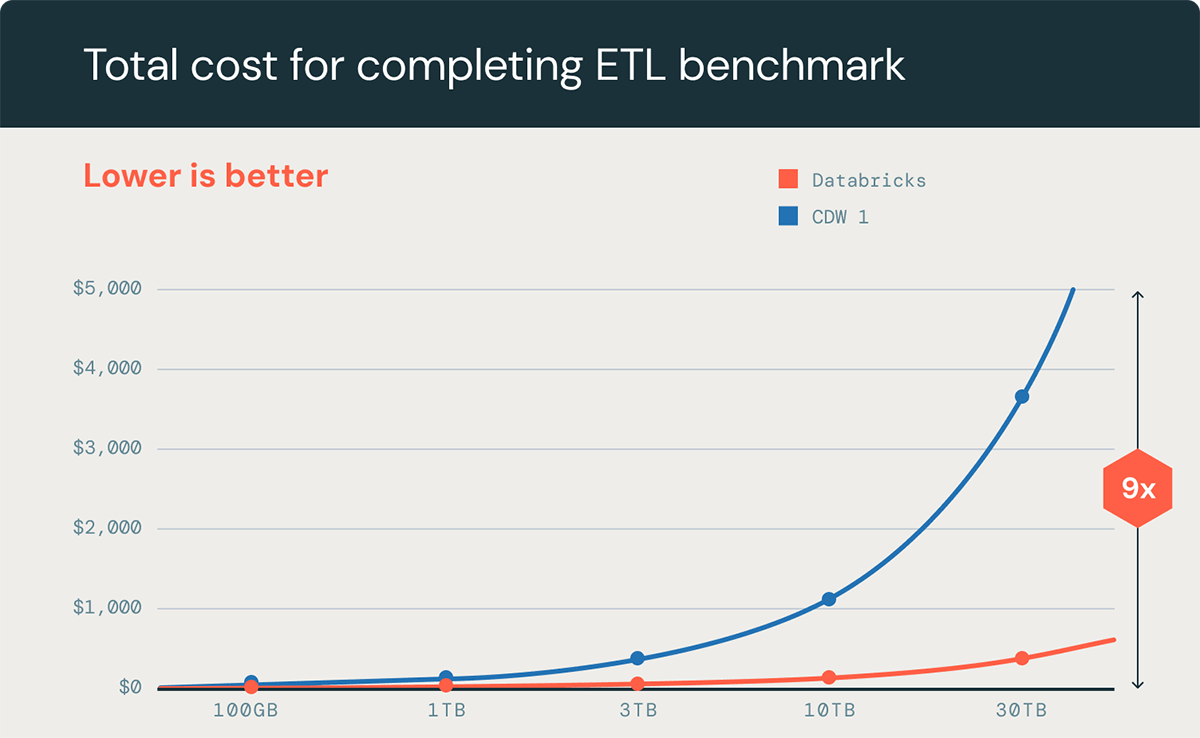
Databricks SQL has long been a frontrunner in terms of performance and cost efficiency for ETL workloads. Our investment in AI-powered features, such as Predictive IO, helps sustain that leadership position and enhance cost advantages as data volumes continue to grow. This is evident in our processing of ETL workloads where Databricks SQL has up to a 9x cost advantage vs. leading industry competition (see benchmark below).
Delivering Low-Latency Performance with Class-Leading Concurrency for BI
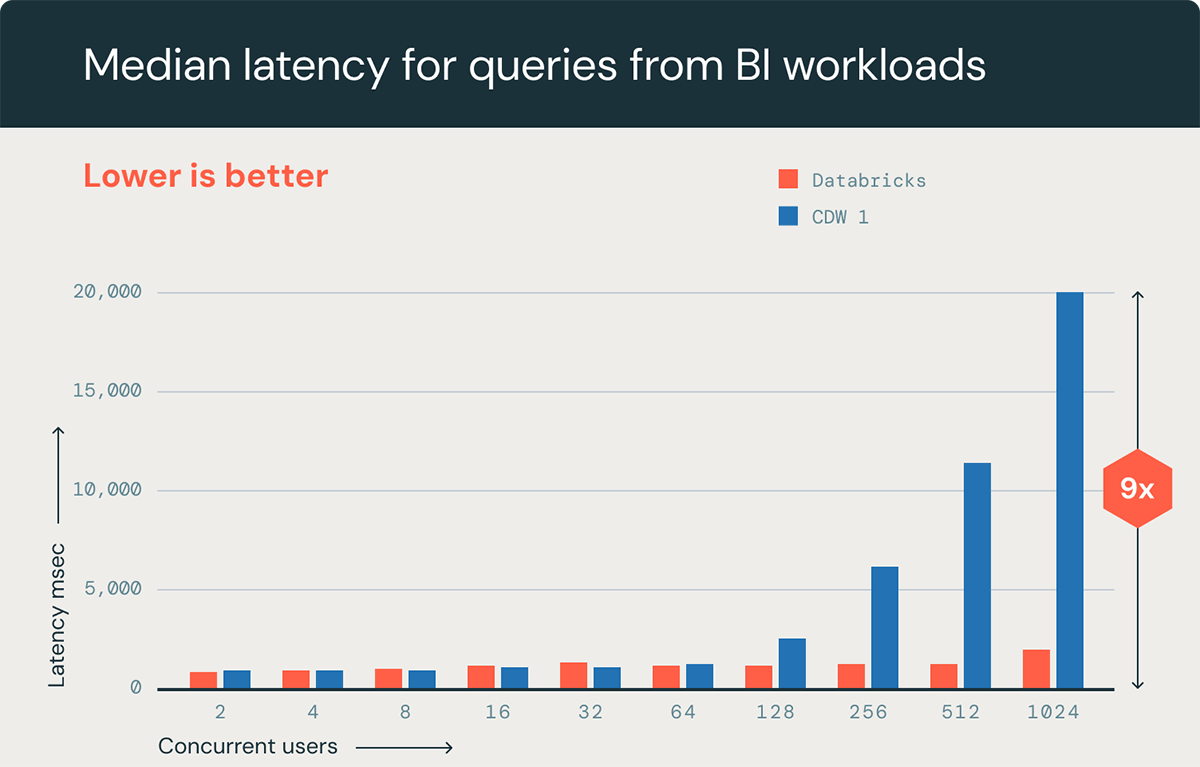
Databricks SQL now matches leading industry competition on low-latency query performance for smaller numbers of concurrent users (< 100) and has 9x better performance as the number of concurrent users grows to over one thousand (see benchmark below). Serverless compute will also start a warehouse in a few seconds right when needed, creating substantial cost savings that avoids running clusters all the time or performing manual shutdowns. When the workload demand lowers, SQL Serverless automatically downscales clusters or shuts down the warehouse to keep costs low.
The Way Forward with AI-optimized Data Warehousing
Databricks SQL has unified governance, a rich ecosystem of your favorite tools, and open formats and APIs to avoid lock-in -- all part of why the best data warehouse is a lakehouse. If you want to migrate your SQL workloads to a cost-optimized, high-performance, serverless and seamlessly unified modern architecture, Databricks SQL is the solution. Talk to your Databricks representative to get started on a proof-of-concept today and experience the benefits firsthand. Our team is ready to help you evaluate if Databricks SQL is the right choice to help you innovate faster with your data.
To learn more about how we achieve best-in-class performance on Databricks SQL using AI-driven optimizations, watch Reynold Xin's keynote and Databricks SQL Serverless Under the Hood: How We Use ML to Get the Best Price/Performance from the Data+AI Summit.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.