Fast, Secure and Reliable: Enterprise-grade LLM Inference
by Linden Li, Jeffrey Chen, Megha Agarwal, Margaret Qian and Daya Khudia
Introduction
After a whirlwind year of developments in 2023, many enterprises are eager to adopt increasingly capable generative AI models to supercharge their businesses. An essential component of this push requires the ability to query state-of-the-art large language models and incorporate them into existing enterprise workstreams. The workhorse of these projects is an inference API - an easy-to-use interface for users to send requests to models residing in a secure environment and quickly receive responses.
We’ve developed a state-of-the-art inference system tailored to the demands of real-time interactions. Building such a system requires a different set of principles - from innovative scheduling techniques to new considerations including security and reliability. In this blogpost, we discuss how our thought processes have evolved as we brought lessons learned from our previous blog into the inference API.
Online Inference and What Matters for User Experience
To maximize performance, inference requests are executed on AI accelerators like NVIDIA’s A100s & H100s, AMD’s MI300, Intel’s Gaudi, or AWS’ Inferentia. Due to current GPU server costs and supply limitations, user requests need to be processed concurrently. A simple strategy is to utilize batching, where several requests are run simultaneously through a single model forward pass. However, given the diverse nature of user workloads and traffic in production, this approach has its limitations:
First, requests from users vary in characteristics and typically do not arrive simultaneously. A strategy that waits for requests to come in so that they can be batched together imposes a heavy latency penalty. Requests within a batch can only start generating until the latest request arrives, leading the time to first token to spike. When requests have different input and output lengths in a batch, this can also lead to suboptimal GPU utilization. Consider the case where user A submits a request asking to generate a long story and user B asks a simple yes or no question. While user B’s request can be serviced quickly, it will need to wait for A’s request to be completed since they are in the same batch. The solution to both of these problems is to utilize a continuous batching strategy, which breaks down generation at the iteration level.
Second, increasing the batch size can increase throughput, but slow down latency. Initially, at low batch sizes, performance is limited by how fast GPU memory feeds data to the compute units. As the batch size increases to accommodate more users, the limitation shifts to the processor’s computational speed after a certain threshold batch size. In these scenarios, it is crucial to differentiate server throughput—the number of requests processed per second—from request latency—the time it takes for a single request to complete. Increasing the batch size will often increase the overall throughput, but could come at a latency hit for sufficiently large batch sizes. While developers monitor throughput to measure a server’s aggregate performance, user experience is driven primarily by latency. Figure 1 shows the typical throughput latency curve with increasing batch size. There are a few interesting things to note from this plot: 1) Up to a certain point, a 2x increase in traffic increases throughput by 2x but doesn’t increase latency by 2x. 2) we can find the maximum throughput we can achieve at the given latency, for example, while staying in the 1000ms budget the maximum throughput we can achieve is 11500 output tokens per second.
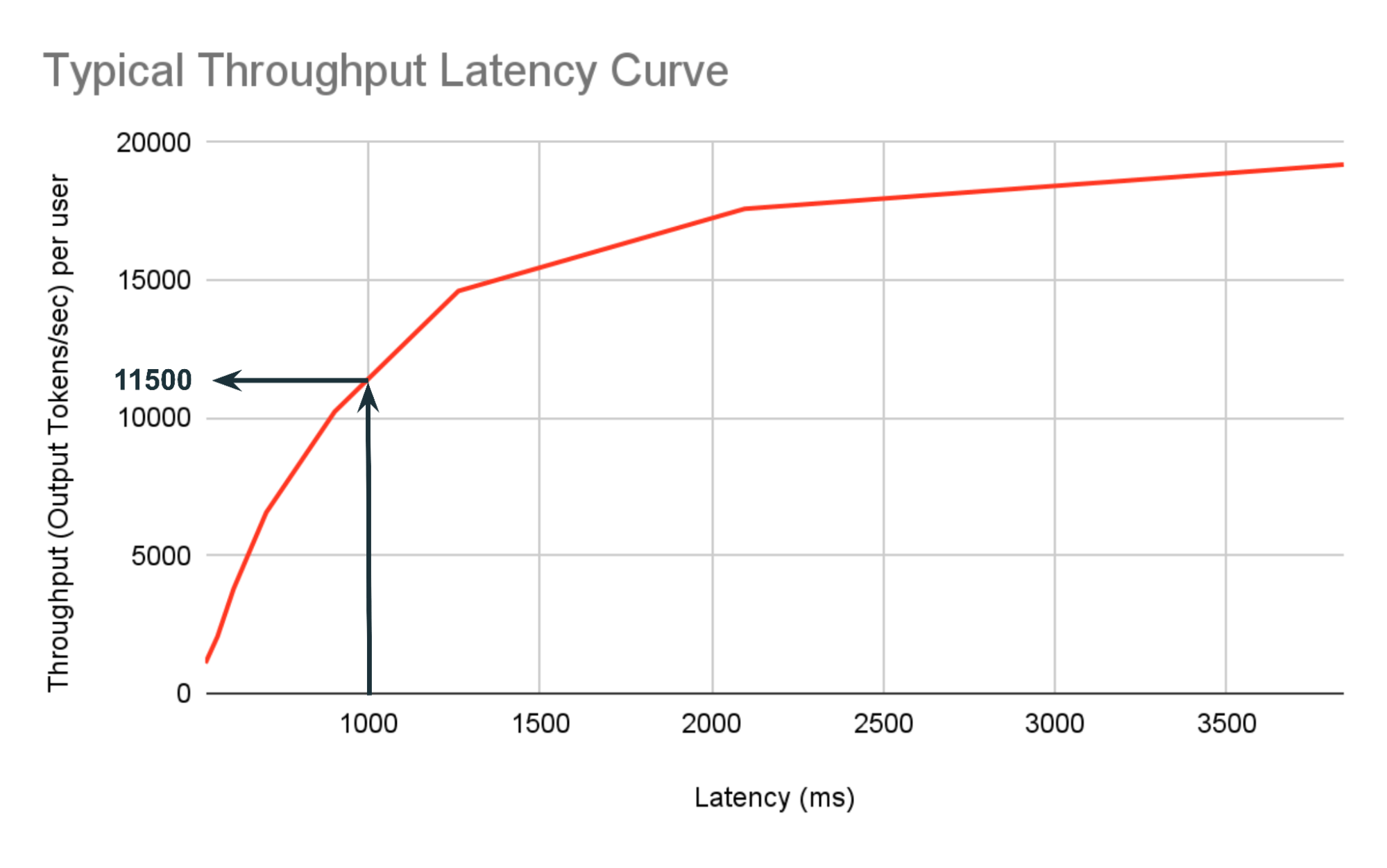
This phenomenon additionally means that benchmarks at low batch sizes often do not properly simulate what users will expect in real-time, high traffic settings. Many optimization techniques in the literature will try to optimize for heavily memory bandwidth-bound low batch sizes, but these are not suitable in production service settings. GPUs are in limited supply and expensive; running at low batch sizes might lead to faster speed but ends up underutilizing GPUs and makes operating costs go up.
Third, users want to support high context lengths. The recent trend among proprietary models is towards longer context lengths (e.g., Claude 3 with 200K context length and Gemini 1.5 Pro with one million tokens) and open models will catch up soon. For example, Mixtral-8x7b, already supports context lengths of up to 32 thousand tokens. This has enabled a whole host of new applications, from generating coherent long-form text to enabling retrieval-augmented generation pipelines to be done over longer documents. Longer contexts introduce greater challenges to serving, since they produce KV caches that are memory intensive. Memory management with long contexts becomes challenging: KV cache takes up significantly more space (17 GB total for Mixtral at batch size 4) and these caches cannot be evicted mid-request, limiting the maximum batch size. In addition, long prompts introduce greater computational pressure on the server, which now has to allocate significantly more compute to each request.
Fourth, users will want to send a high number of requests to support production workloads. Certain chat-based or data wrangling applications will send many queries per second, necessitating additional control. To ensure fair access to resources, it is important to not let certain user workloads dominate the queue. A solution to this is rate limits, but these cannot be set too low to not meet user requirements.
Metrics for Online Performance
An arbitrarily large number of users can hit the inference API at any point in time, who all expect consistently low latency and high availability. The latency of a response is influenced by two factors:
- The queueing delay and the prefill time (i.e. the time to process all of the input tokens), both of which contribute to the time to first token (TTFT).
- The decoding speed, measured via the time per output token (TPOT).
For interactive applications, users prefer having outputs streamed back to them from the inference server. These metrics describe streaming performance, indicating how much time users will wait for the first token and between two output tokens on an average — similar to a chatbot style application.
To ensure a consistent experience for all users, it is important to monitor the distribution of response times similar to traditional serving systems. For each of these metrics, we monitor p90 and p95 statistics in high traffic environments that simulate real world usage patterns; details are in the benchmarking section below.
Optimization Strategies for Enterprise Workloads
Our inference service is performant, reliable, and scalable. In this section, we detail some of the techniques and design choices that we have running in production.
Scheduling
In high traffic settings, where a single request can include tens of thousands of tokens, LLM inference presents significant challenges to memory management. Maintaining state (e.g., KV cache) for several requests in GPU memory must be done carefully to avoid running into runtime out of memory errors (OOMs) in production. There are several techniques that we use to maintain high performance in these cases, while maintaining fairness among requests.
Our server receives requests and asynchronously pushes them to a request pool. The request scheduler then makes a decision of which requests to run for the next forward pass. To determine which requests can be run, the scheduler looks at the current GPU memory utilization of currently running requests in addition to the properties of currently queued requests.
Many concurrent requests can introduce memory pressure, since for a given request all the key and value representations need to be cached. Managing the KV cache efficiently presents a challenge in online settings. We utilize the PagedAttention algorithm inspired by vLLM. Simply put, this algorithm enables far more efficient memory utilization by reducing fragmentation - it does this by allocating “token blocks” for the KV cache dynamically. As a result, the request scheduler can scale up the number of concurrent requests processed, subject to the constraint that the allocator does not run out of memory. This enables us to achieve higher request throughput, but to maintain suitable latency we cap the maximum batch size.
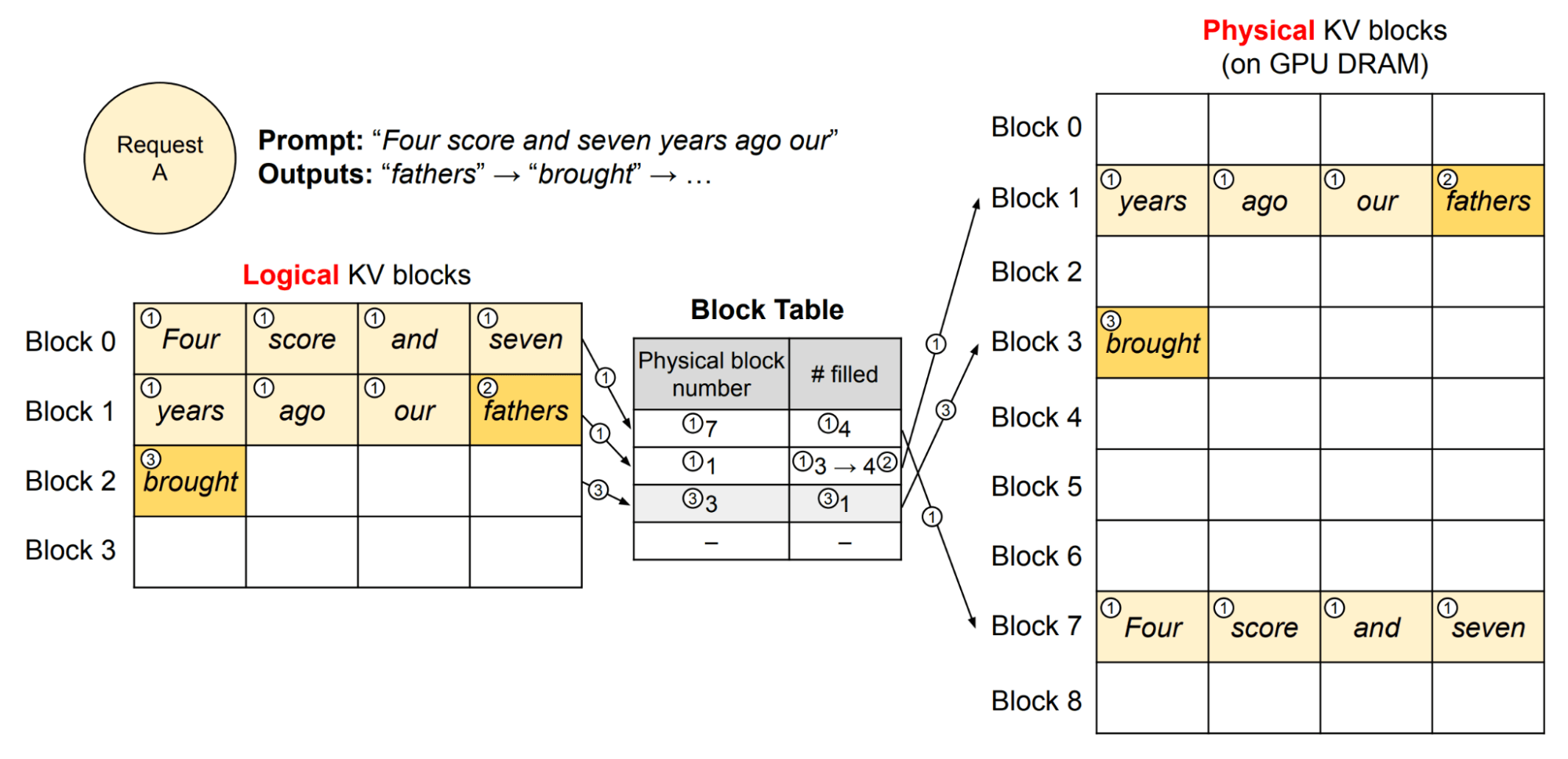
A load balancer will evenly route requests to different replicas, where the scheduler chooses which requests to serve. At this point, there are different scheduling algorithms to choose from, each having their own tradeoffs. One option, to maximize GPU utilization, is to select the requests with the largest sequence lengths and evict shorter sequences currently in flight; larger sequence lengths produce better utilization of the tensor cores, since more tokens are processed in parallel. However, this would cause poor response times for existing requests and unfairly prioritize longer requests. We choose a policy that does not evict requests for this reason.
Overlaying prefill and decode
To make best use of the GPU’s computing capabilities, it is best to batch as many tokens together as possible when running a forward pass. This is especially true with long contexts, where many tokens can be processed in parallel.
When requests come in sporadically, prompt processing of the prefill stage first can obstruct decoding speeds, since there is idle time waiting for prompts to complete. A strategy around this is to overlay the prefill and decoding stages to happen concurrently - this enables better long context support. Aggregating prefill and decode is done subject to a constraint—the maximum number of batched tokens, which represents the maximum number of prefill and decode tokens that can be overlaid simultaneously in the same batch. This number is tuned to the point where the workload becomes compute bound and saturates the tensor cores; beyond this point, packing additional tokens would not lead to higher throughput.
Quantization
We showed in our recent blog post that quantizing the model—its weights and KV cache—to lower precision (int8 or fp8) significantly bolster throughput at the same latency with negligible effects on model quality. With the research and testing done on this, we are looking forward to offering quantized deployments of our foundation models in a future service update.
Speed: We observe a 2.2x boost in throughput with nearly the same latency per user. Quantization allows us to double the maximum batch size that can fit on the same hardware while maintaining the same latency budget. For the same batch sizes, we're seeing a 25-30% decrease in token generation time with fp8 in comparison to fp16 on H100.
Quality: To measure the impact on quality, we put our quantized model (Llama-70B) to the test with the mosaicML Gauntlet Evaluation suite. Across 34 diverse benchmarks (including MMLU, BigBench, Arc, and HellaSwag), the results show negligible impact on quality. This will be shipped to production in the coming days, enabling us to serve at higher batch sizes while maintaining latency or reduce latency in the low batch size regime. Please read our blog for more details.
Foundation Models API: Databricks’ approach to serving
We’ve found that enterprise users care about maximizing throughput for a fixed latency budget. As a result, we often want to guarantee a certain latency target in mind by fixing a TTFT and TPOT that we would like the user to achieve at minimum (hence, the P90 and P95 statistics). If the maximum traffic we can support makes this latency unacceptably high, then we consider increasing the number of replicas. To support different use cases, Databricks serving supports Foundation Model APIs (FMAPIs) which allow you to access and query state-of-the-art open models from a serving endpoint. The Foundation Model APIs are provided in two modes: pay-per-token and provisioned throughput. There have been many customers that have used the pay-per-token before transitioning to the Databricks provisioned throughput offering which guarantees a threshold of throughput that fits an enterprise user's latency requirements. This principle has been a primary driver of how we design an enterprise inference offering to provide users with the best experience possible.
On the pay-per-token side, we optimize to provide high throughput under latency constraints to use the hardware most efficiently. Based on the setting described above, we care about compute bound optimizations over the memory bound optimizations up to a certain latency threshold. Optimizing and publishing benchmarks at high batch sizes more properly simulates the latency users would see for any system that is running in real-time, with high traffic.
From a cost perspective, it is not affordable to heavily underutilize GPUs in the long run and run at low batch sizes. From an availability perspective, we also care about user’s getting as much throughput per GPU so that our system can serve as much of the demand that we see as possible and continue to scale since it is not practical to just increase replicas everytime. Therefore, given our load of enterprise customers, and that each of these enterprise customers is looking for high throughput, user requests must be multiplexed into a system which can efficiently process many requests concurrently.
Security, Reliability and Availability
We care about ensuring that customers’ AI workloads are protected and trusted. In this section, we highlight some of the security and reliability features that we have built into the pay-per-token Foundation Model endpoints.
Security: We provide customers with flexible access controls to the Foundation Model endpoints in each workspace. Admins can tune the rate limits on the endpoints to control the allowed traffic volume from the users in their organization. Endpoint creators can control which users have access to deployed endpoints. Traffic through each endpoint is also completely contained within a customer’s cloud, so they can ensure that their data will not leave a trusted environment. Each request is authenticated, logically isolated, and encrypted. We also ensure that customer data is not stored or accessed for purposes other than preventing, detecting, and mitigating abuse or harm. If stored, customer data is retained for up to 30 days, and will be stored in the same region as the customer workspace. The Provisioned Throughput offering is HIPAA compliant on AWS and Azure, with additional compliance levels coming soon.
Reliability: We frequently make new releases to our Foundation Model APIs to ensure that customers are getting the best performance out of our endpoints. To ensure that our service is reliable, our engineering team has designed a suite of regression tests that run for every release, and our deployment pipeline is built to ensure that updates are rolled out with no downtime. These regression tests ensure that model quality will not be degraded in a new release and that we maintain a consistent bar for performance targets with each update. Our deployment pipeline is developed to roll out updates in a multi-stage, health-mediated fashion so that we can catch regressions as soon as possible. Each of our deployments runs on replicas spread over multiple nodes to ensure uptime in the face of node failures. In addition, we have also built a suite of monitoring tools to ensure that no errors go undetected in our endpoints as they are running in production. Metrics such as error rates and request latency allow us to make sure our endpoints are running at their full capacity.
Benchmarking Results
We use the following benchmarking procedure to profile our system under realistic production settings:
- High traffic: We simulate a different number of concurrent users hitting the system at the same time. This allows us to get a sense of what performance will look like in low traffic settings as well as what will happen when requests flood the system.
- Users submitting at irregular intervals: Users are spawned at a rate of 1 per second in an initial ramp up period. This produces an offset to ensure that users are not submitting requests at the same regularity, exercising the continuous batching capabilities.
- Different request characteristics: We simulate longer prompts and short generations, since these are the most common use cases in production (e.g., RAG, summarization). The prompts are randomized by sampling prompt lengths with an average input token length and a specified standard deviation.
We display the end-to-end performance metrics as well as prefill and decode specific metrics. Benchmarks were performed with 16-bit precision on an 8x H100 system. We benchmark end-to-end performance to exercise the entire system and provide a helpful comparison point across other inference providers. Prefill and decode metrics are also displayed to provide a realistic sense of streaming performance.
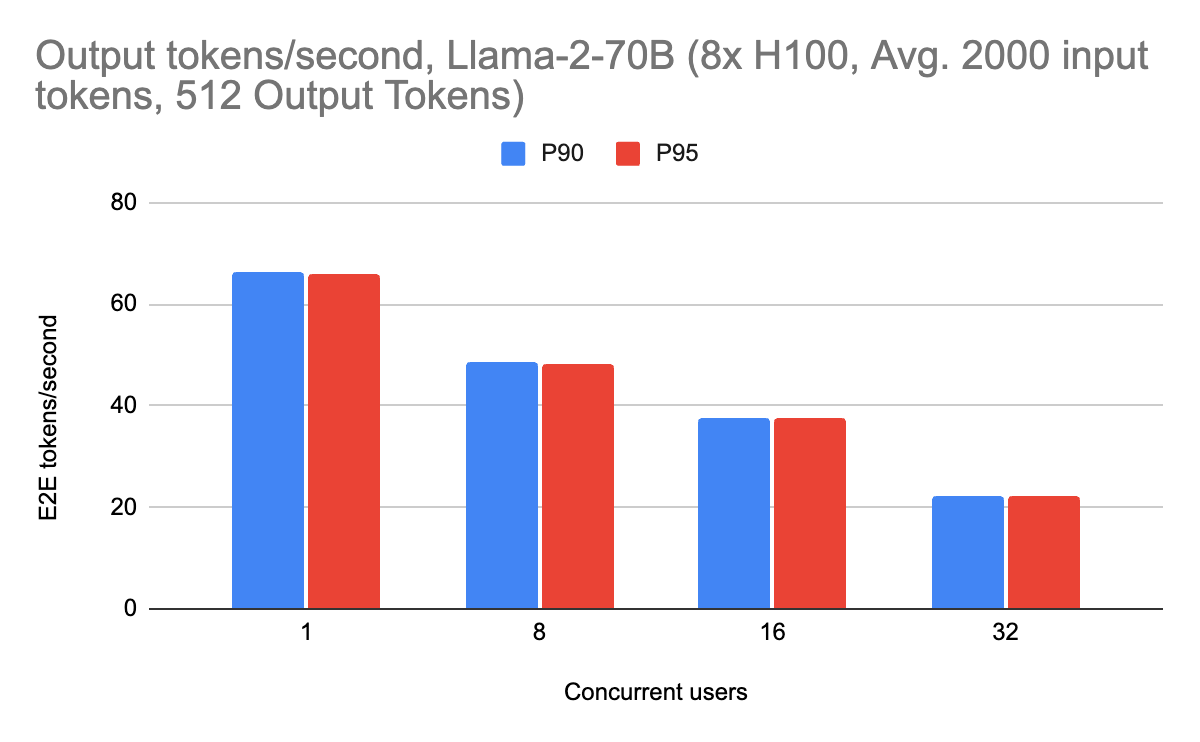
For Llama-2-70B, we are able to achieve a maximum of 69 output tokens per second per user, with 165 end-to-end tokens per second with approximately 700 input tokens, which is approximately a couple of paragraphs of text. We benchmark end-to-end performance to profile the entire system and split up prefill and decode metrics to benchmark the individual components.
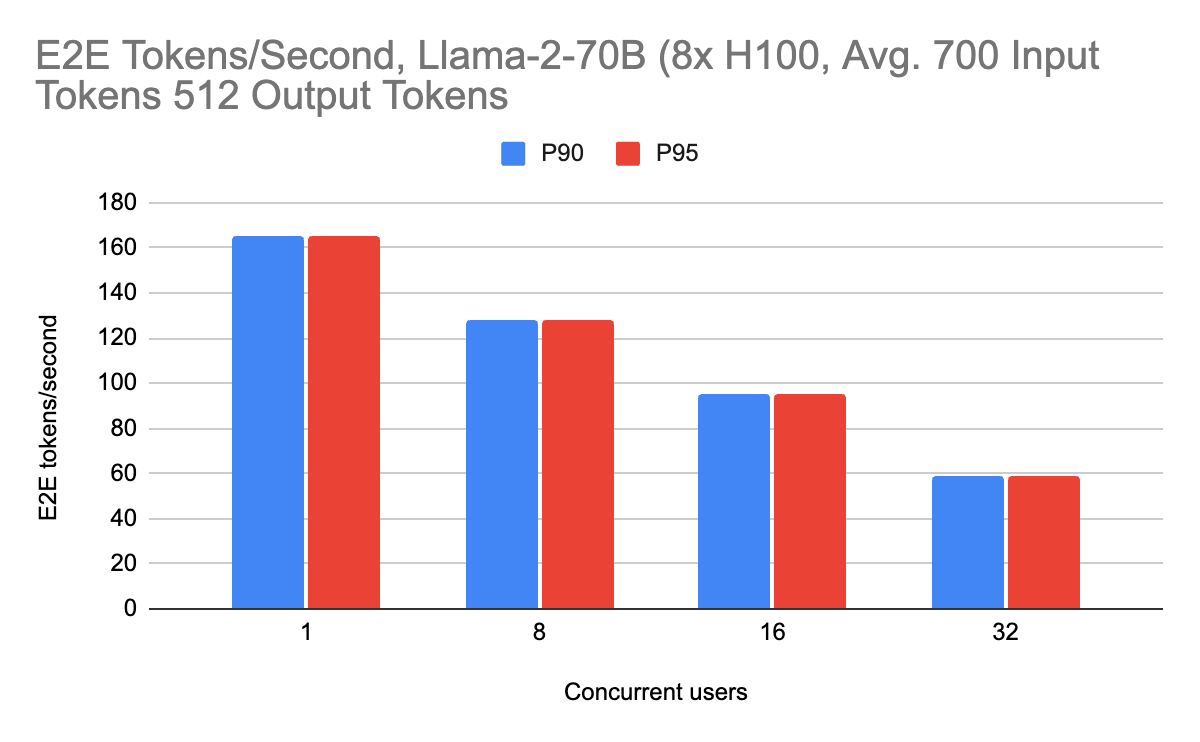
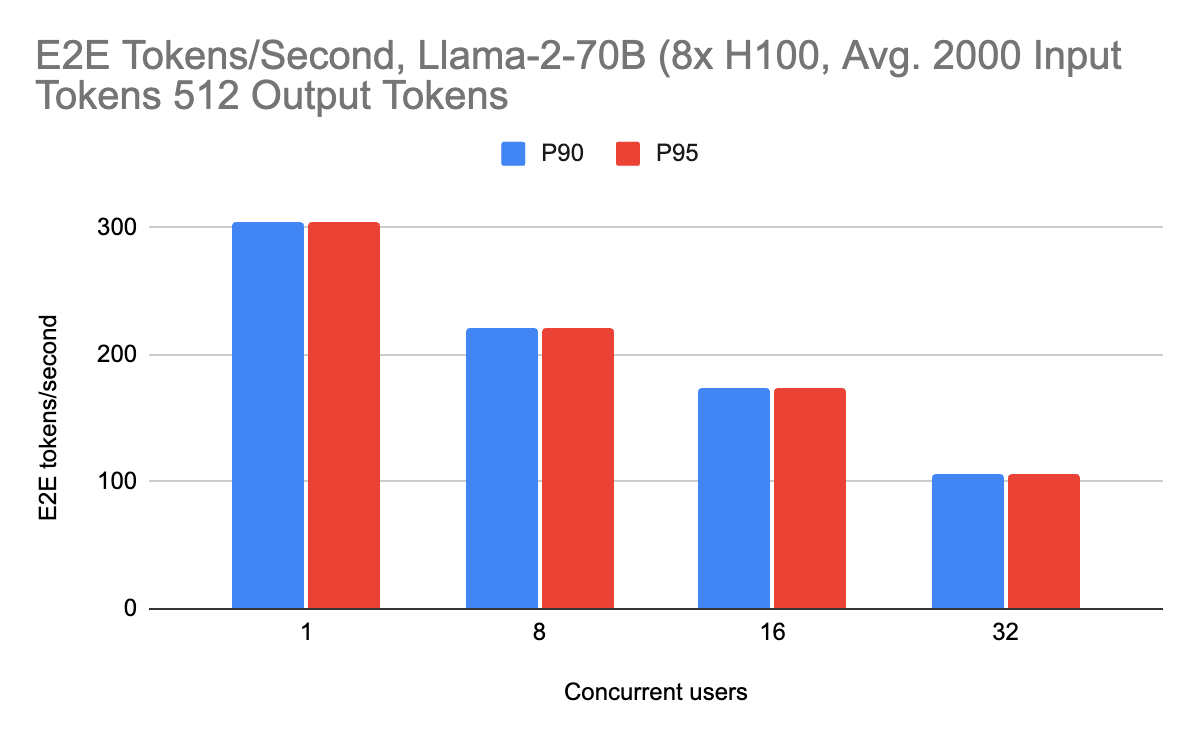
The streaming performance experienced by users is given by the output tokens per second when streaming outputs (the decoding performance). We report these numbers below:
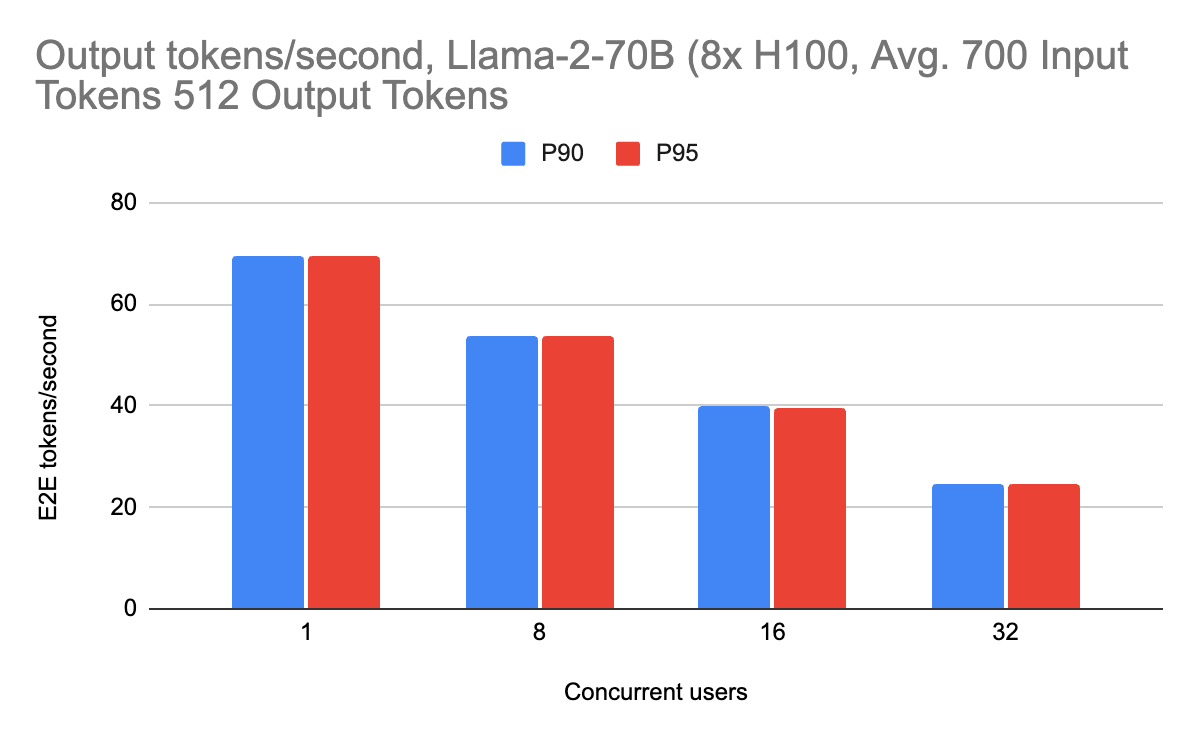
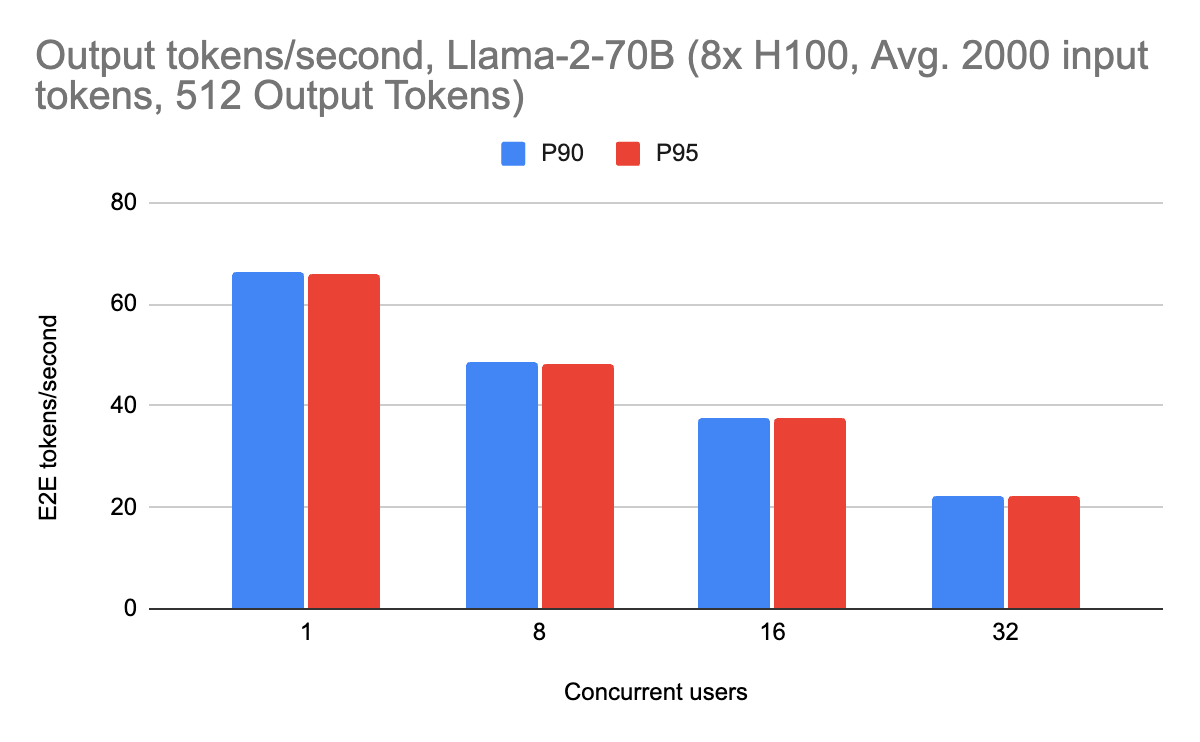
The streaming performance achieves roughly 70 output tokens per second at peak. There is also consistently high performance across different workloads as well, including with 2000 input tokens (suitable for RAG workloads). Long context requests do not slow the server down due to the overlaying, showing consistently high performance. This is especially important as users scale their input prompts.
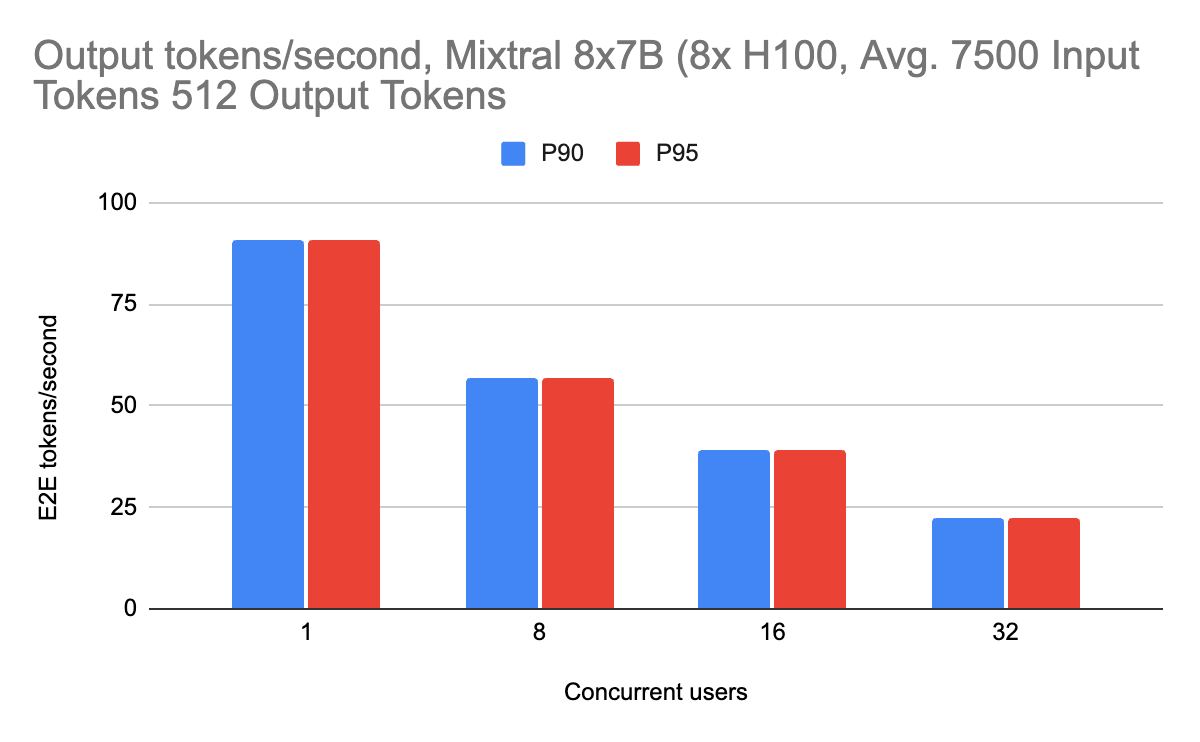
Inference performance works well with mixture-of-experts models as well. This model architecture utilizes sparsity to scale parameter count without correspondingly large increases in inference time. We choose to serve these models with tensor parallelism (as opposed to expert parallelism) to ensure even distribution of work across GPUs, even if tokens are not properly load balanced across experts. We benchmark on two input lengths: 4000 and 7500 input tokens, which can fit a long document of text in the context.
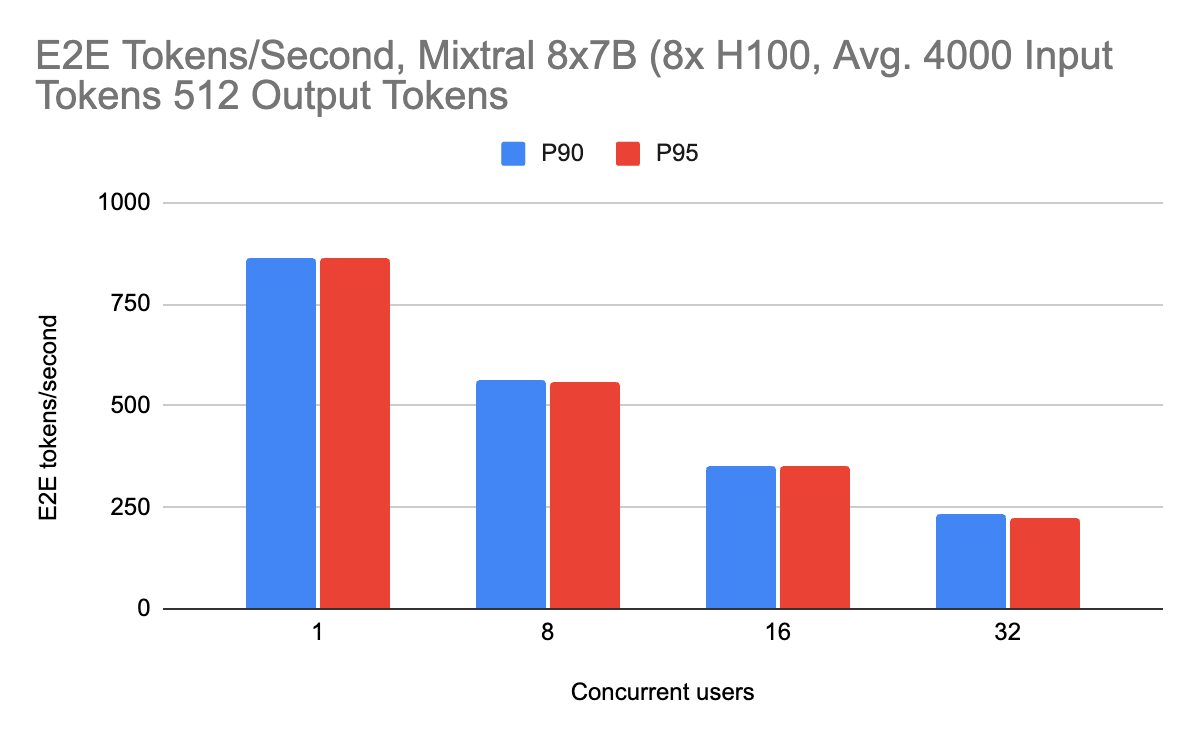
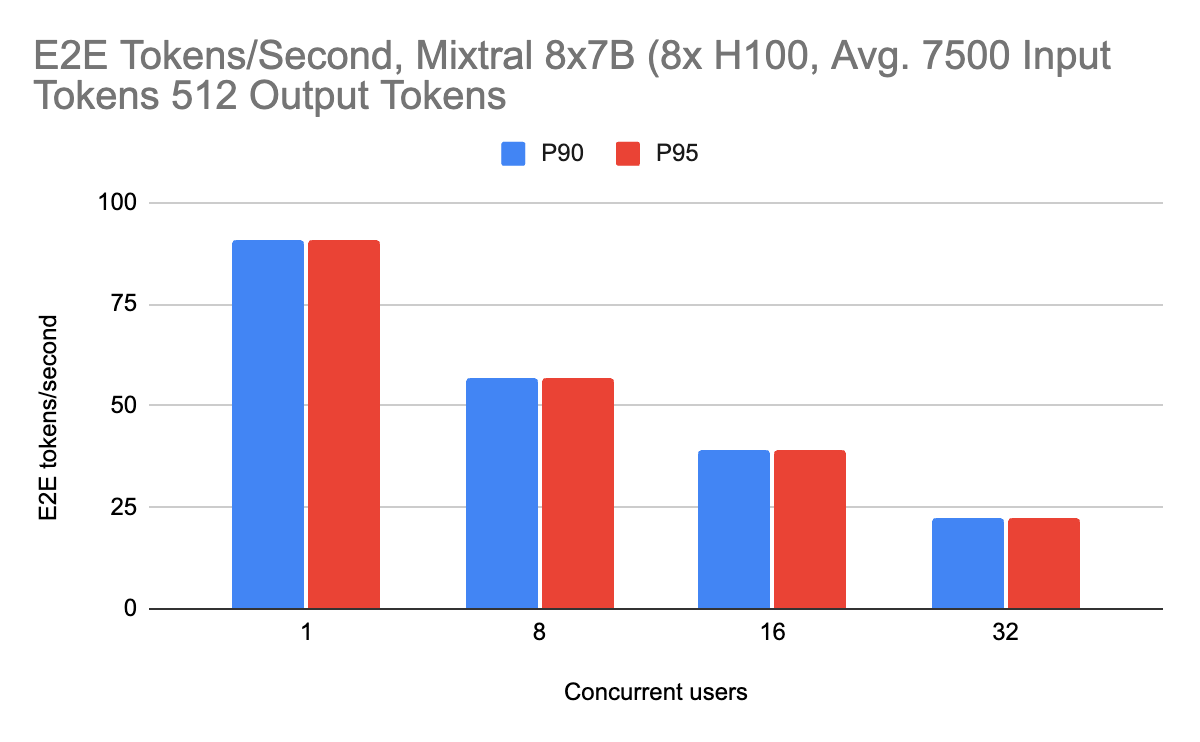
Mixtral performance on output lengths also scales well with higher input lengths, with a minimal performance penalty.
Concluding Thoughts and What’s Next
In this blog post, we explore the intricacies of online serving and articulate why our product stands out as the top-tier solution for LLM inference for enterprises. We're excited to share that, thanks to the integration of TRT-LLM as our backend, our inference endpoints now boast a remarkable speed improvement. Our current Foundation Model endpoints operate at a rate that's 1.5 to 1.7 times faster than our previous APIs. Moreover, we’ll soon be introducing even more advancements, including FP8 precision and KV-Cache sharing, promising further enhancements in these APIs.
Additionally, we're proud to emphasize the built-in features of our inference solution that cater to enterprise needs: robust security, unwavering reliability, and consistent availability. These elements ensure that our product is not only fast and efficient but also secure and dependable for enterprise use. Stay tuned as we continue to innovate and lead in the area of LLM inference.
Of course, the best introduction to our inference service is trying it out. If you’re a Databricks customer, you can start experimenting in seconds via our AI Playground (currently in public preview). Just log in and find the Playground item in the left navigation bar under Machine Learning. If you aren’t yet a Databricks customer, sign up for a free trial!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.