From Lakehouse to Digital Mind: Architecting a Multi-Agent AI Ecosystem on Databricks Agent Bricks
See how Edmunds reimagined its data lakehouse into an intelligent, multi-agent AI platform with Agent Bricks for activation, automation, and continuous innovation.
- Edmunds built an AI-native multi-agent ecosystem on Databricks Agent Bricks, moving from passive data storage to real-time, intelligent automation across car shopping functions.
- Specialized agents like DataDave achieve 95% accuracy in complex analytics, while marketing offers improved conversion rates using insights from the unified lakehouse.
- The architecture enables scalable automation, agent collaboration, and proactive, personalized experiences for both internal teams and car buyers.
In today's enterprise, having a vast, unified data lakehouse is critical for activating data. With a lakehouse, organizations can transform a passive repository into a dynamic, intelligent engine that anticipates needs, automates specialized knowledge, and drives more informed decisions. At Edmunds, this priority led to the launch of Edmunds Mind, our initiative to build a sophisticated multi-agent AI ecosystem directly on the Databricks Data Intelligence Platform.
This architectural evolution is fueled by a pivotal moment in the automotive industry. Three key trends have converged:
- The rise of large language models (LLMs) as powerful reasoning engines
- The scalability and governance of platforms like Databricks as a secure foundation
- The emergence of robust agentic frameworks to orchestrate automation. These factors enable systems that would have seemed unimaginable just a few years ago
This transformation is not just about adding another AI tool, but also about fundamentally redesigning our organization to operate as an AI-native one. The principles, components, and strategies behind this intelligent core are detailed in our architectural blueprint below.
“Databricks gives us a secure, governed foundation to run multiple models like GPT-4o, Claude, and Llama and switch providers as our needs evolve, all while keeping costs in check. That flexibility lets us automate review moderation and improve content quality faster, so car shoppers get trusted insights sooner.”—Gregory Rokita, VP of Technology, Edmunds
Transforming from Data-Rich to Insights-Driven
Our vision is to evolve from a data-rich company to an insights-driven organization. We leverage AI to build the industry's most trusted, personalized, and predictive car shopping experience.
This is realized through four key strategic pillars:
- Activate Data at Scale: Transition from static dashboards to dynamic, conversational interaction with data.
- Automate Expertise: Codify the invaluable logic of our domain experts into reusable, autonomous agents.
- Accelerate Product Innovation: Provide our teams with a toolkit of intelligent agents to build next-generation features.
- Optimize Internal Operations: Drive significant efficiency gains by automating complex internal workflows.
At the heart of this vision is our most significant competitive advantage: the Edmunds Data Moat. This powerful foundation of automotive data is led by our industry-leading used vehicle inventory, the most comprehensive set of expert reviews, and best-in-class pricing intelligence, complemented by extensive consumer reviews and new vehicle listings. This entire ecosystem is unified and managed within our Databricks environment, creating a singular, powerful asset. Edmunds Mind is the engine we've built to unlock its full potential.
Inside the Digital Agent Framework
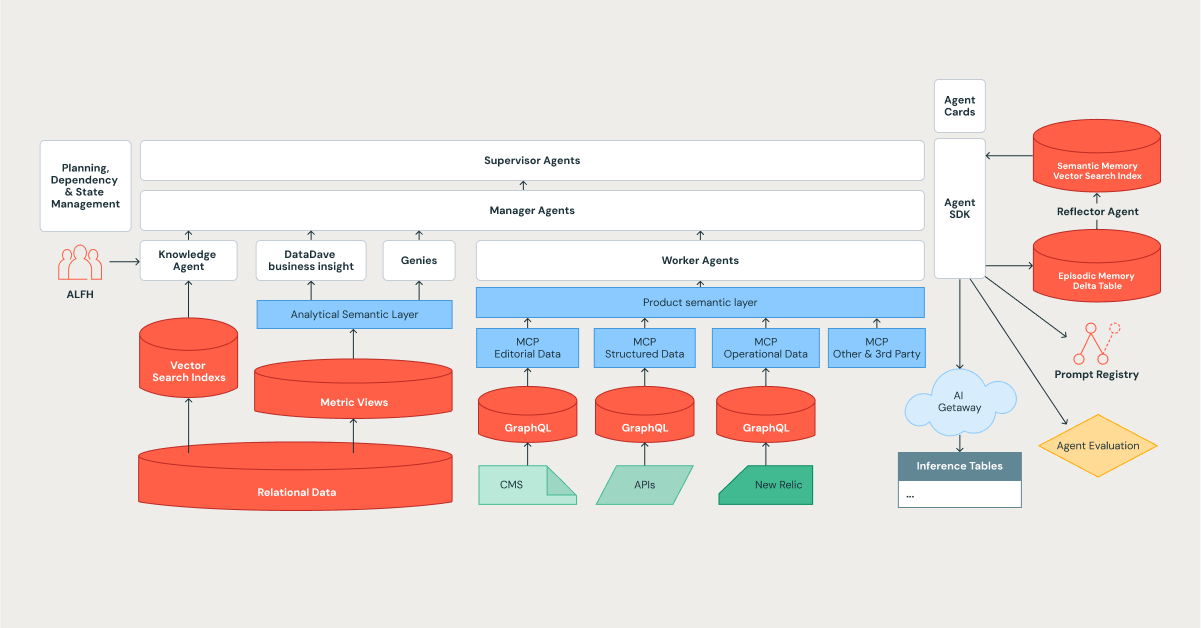
The architecture of Edmunds Mind is a hierarchical, cognitive system designed for complexity, learning, and scale, with the Databricks Platform serving as its foundation.
The Agent Hierarchy: An Organization of Digital Specialists
We designed our system to mirror an efficient organization, using a tiered structure where tasks are decomposed and delegated. This aligns perfectly with the orchestrator patterns in modern frameworks, such as Databricks Agent Bricks.
- Supervisor Agents: The strategic leaders. They perform long-term planning, manage dependencies, and orchestrate complex, multi-stage tasks.
- Manager Agents: The team leads. They coordinate a team of specialized agents to accomplish a specific, well-defined goal.
- Worker and Specialized Agents: These are the individual contributors who provide specialized expertise. They are the system's workhorses and include a growing roster of specialists, such as the Knowledge Assistant, DataDave, and various Genies.
Inter-agent communication is governed by a standardized protocol, ensuring that task delegations and data handoffs are structured, typed, and auditable, which is critical for maintaining reliability at scale.
The hierarchy is also designed for graceful failure. When a Manager Agent determines that its team of specialists cannot resolve a task, it escalates the entire task context back to the Supervisor, including the failed attempts stored in its episodic memory. The Supervisor can then re-plan with a different strategy or, crucially, flag this as a novel problem that requires human intervention to develop a new capability. This makes the system robust and a learning tool that helps us identify the boundaries of its competence.
Deep Dive 1: Automated Data Enrichment Workflow
Historically, resolving vehicle data inaccuracies, such as incorrect colors on a Vehicle Detail Page, was a labor-intensive process that required manual coordination across multiple teams. Today, the Edmunds Mind AI ecosystem automates and resolves these challenges in near real time. This operational efficiency is achieved through our centralized Model Serving, which consolidates our diverse AI agent capabilities into a single, cohesive environment that autoscales based on demand. This architecture liberates our teams from operational overhead, allowing them to focus on delivering value to our users rapidly.
The resolution process is executed through a governed, multi-agent workflow. When a user or an automated monitor flags a potential data discrepancy, a Supervisor Agent immediately triages the event. It assesses the issue, routes it to the appropriate specialized team, and validates task permissions through Unity Catalog for robust data governance. A dedicated Manager Agent then orchestrates a sequence of specialized Worker Agents to perform tasks ranging from VIN decoding and image retrieval to AI-powered color analysis and final database updates. Human data stewards remain integral for critical review, shifting their focus from manual intervention to the high-value approval stage. Every interaction and decision is systematically logged, building a comprehensive foundation for continuous learning and future process optimization.
This example illustrates how the whole ecosystem handles a real-world data quality and enrichment task from end to end.
- Event Trigger: A user complaint or an automated monitor flags a potential data quality issue (e.g., an incorrect vehicle color) on a Vehicle Description Page.
- Triage and Orchestration: A Supervisor Agent ingests the event, creates a trackable task, and assesses its priority based on predefined business rules.
- Delegation to Manager: The Supervisor delegates the task to the Vehicle Data Manager Agent after confirming its permissions to access and modify vehicle data in Unity Catalog.
- Coordinated Task Execution: The Manager Agent orchestrates a sequence of specialized Worker Agents to resolve the issue: a VIN Decoding Agent, an Image Retrieval Agent to pull photos from our media library, an AI-Powered Color Analysis Agent to determine the correct color from the images, and a Data Correction Agent to update the vehicle build database.
- Human-in-the-Loop Review: Before the change goes live, the Manager Agent flags the automated change and notifies a human data steward via a Slack integration for final validation.
- Learning and Closure: Once the steward approves the task, the Supervisor marks it as complete. The entire interaction—including the final human approval—is traced and logged to Long-Term Memory for future learning and auditing.
Deep Dive 2: Knowledge Assistant: Real-Time Answers, Trusted Brand Voice
Where customers once navigated multiple Edmunds dashboards or contacted Edmunds support for answers, the Knowledge Assistant now delivers instant, conversational responses by drawing on the full spectrum of Edmunds’ data. This RAG agent is tuned to the Edmunds brand voice, weaving together insights from expert and consumer reviews, vehicle specs, media, and real-time pricing. As a result, customers experience faster, more satisfying interactions, and support staff spend less time fielding basic requests.
Key capabilities include:
- Brand Voice Personification: The agent is meticulously tuned to communicate in the lively, helpful, and trusted voice Edmunds customers have known for decades.
- Real-Time Data Synthesis: In a single query, the Assistant can retrieve, synthesize, and present information from our disparate, real-time data sources, including expert and consumer reviews, vehicle specifications, transcribed video content, and the latest pricing and incentives.
- Advanced RAG Capabilities: We are actively working with Databricks using AI Search to push the boundaries of our RAG implementation. We focus on enhancing content recency prioritization and sophisticated metadata filtering to ensure the most relevant and timely information is always surfaced first.
Deep Dive 3: DataDave's "Generate-and-Critique" Workflow
DataDave now fields complex analytics that previously depended on time-intensive manual work. This agent orchestrates a rigorous workflow, with each stage critiqued by a specialist agent, to deliver 95% accuracy on the most challenging queries. DataDave can proactively identify opportunities (such as flagging underserved dealerships for the Edmunds Sales Team) by synthesizing website traffic and demographic data. This empowers Edmunds' leadership to confidently move from reporting “what happened” to deciding “what we should do next.”
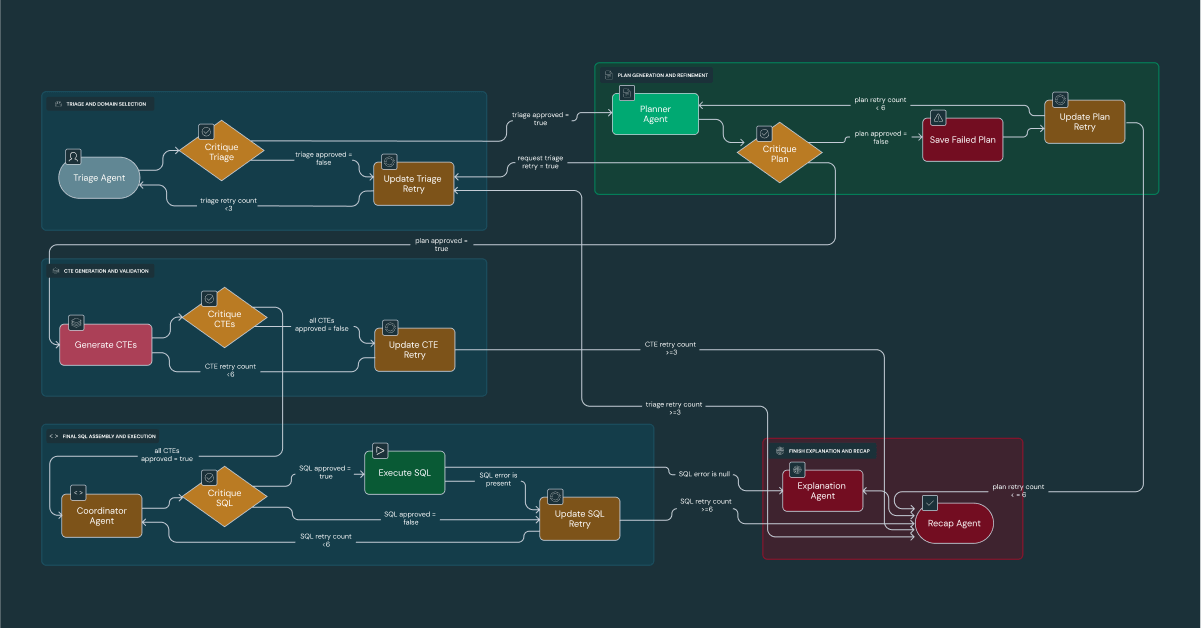
The internal workflow is a five-phase process of Triage, Planning, Code Generation, Execution, and Synthesis, with a dedicated Critique agent validating the output of each phase. Beyond simply analyzing internal metrics, DataDave's true power lies in its ability to synthesize our proprietary data with generalized world knowledge to generate strategic recommendations. For instance, by correlating Edmunds' website traffic data with geographical and demographic data, DataDave can identify dealerships in underserved areas and proactively recommend them to our sales team as "low-hanging fruit."
Deep Dive 4: Specialization in Pricing
At Edmunds, we operate on a core principle: a price is not just a number; it's a conclusion that requires context and justification to be trusted. Leveraging our reputation for the most accurate pricing in the U.S. market, our agent architecture is designed to deliver this confidence at scale.
Our experience evolving a monolithic "Pricing Expert" into a coordinated team of specialists demonstrates this principle. This team—orchestrated by a Manager Agent and including experts like a True Market Value Agent, a Depreciation Agent, and a Deal Rating Agent—produces more than just a sticker price. The final output is a comprehensive, contextualized pricing story that explains why a vehicle is valued a certain way.
This transforms the role of our pricing analysts from manual data aggregation to strategic oversight and guidance. By leveraging Databricks Agent Bricks, our pricing statisticians can configure these hierarchical agent teams with limited coding, dramatically increasing their productivity and lowering maintenance overhead. This empowers them to focus on what truly matters: the "why" behind the numbers.
The Cognitive Core: An Architecture for Compounding Intelligence
Our journey toward a truly intelligent AI ecosystem began with a practical challenge. While deploying specialist agents like DataDave for business analytics, we discovered they were uncovering critical, time-sensitive business truths that remained siloed within their operational context. For example, an agent might detect an anomalous downtrend in a key marketing channel, but this vital insight needs to be communicated effectively to other entities, both agents and humans, to trigger a coordinated response. This highlighted a fundamental need: a shared memory system that could capture these emergent learnings and make them accessible as input to the entire agentic system. We envisioned a cognitive layer where this knowledge could accumulate, grow, and be leveraged to make our entire ecosystem progressively smarter. Consequently, our latest thinking and design is as follows.
- Episodic Memory ("What Happened"): A high-fidelity log of every agent action and observation, serving as the system's ground truth.
- Semantic Memory ("What Was Learned"): A vector index containing generalized insights and successful strategies synthesized from episodic events. This will be the library of actionable knowledge.
- Automated Memory Consolidation: A background "Reflector" agent periodically reviews episodic memory to identify and consolidate key learnings into semantic memory.
- Hierarchical Memory Access: Higher-level agents can access the memories of their subordinates, allowing a Manager Agent to analyze team performance and optimize future strategies. This feedback loop is central to our system's antifragility; every novel failure escalated by the hierarchy is not just a problem to be solved, but a signal that trains the entire ecosystem, making it progressively more intelligent and resilient.
Implementation: mem0 + Databricks
Our implementation will be powered by Databricks AI Search using a Delta Sync Index, which is fully compatible with the mem0 interface. Given that mem0 interacts with vector databases, we will innovate by storing both episodic and semantic memories within a single, powerful backend. Raw, unsummarized events ("what happened") and synthesized learnings ("what was learned") will coexist as distinct vector types within the same source Delta table, which then seamlessly and automatically populates the AI Search index.
This unified architecture creates an efficient workflow. The Reflector agent can query the index for recent episodic entries, perform its synthesis, and write the new, generalized semantic vectors back into the source Delta table. The Delta Sync Index then automatically ingests these new learnings, making them available for querying. By leveraging the source Delta table as the single point of entry, we eliminate data pipeline complexity and gain the scalable, serverless, and low-latency foundation required for a truly intelligent agentic system.
Example Workflow with Edmunds Pulse
- Log: The 'DataDave' agent detects a sales anomaly and logs the event to its Episodic Memory via the mem0 API. This action writes a new vector entry into our source Delta table.
- Synthesize: The Reflector agent processes this event, generates a generalized insight (e.g., "Product X sales dip on weekends"), and converts it into a vector embedding.
- Index: The new insight is written back to the source Delta table, but flagged as a synthesized learning. Databricks AI Search automatically syncs this new entry, indexing it into the semantic memory.
- Deliver: Finally, a dedicated Edmunds Pulse agent, which constantly monitors the semantic memory for high-priority intelligence, proactively delivers this synthesized finding to a human stakeholder. Drawing a parallel to the ChatGPT Pulse release, which aims to provide a more ambient and aware AI assistant, our Edmunds Pulse will act as the live 'pulse' of the business, ensuring critical insights are not just stored but actively communicated to drive timely and intelligent action.
The Data and Knowledge Layer: A Governed Foundation of Truth
AI agents rely on the quality of their data. The Edmunds data layer is purpose-built for consistency, governance, and flexibility, with Unity Catalog serving as the cornerstone to ensure that all information remains accurate and well-managed.
Deep Dive 5: GraphQL Data Access and Interactivity Patterns
The Edmunds Model Context Protocol (MCP) framework securely connects AI agents to real-time context from all core data sources, such as vehicle specs, reviews, inventory, and operational metrics from systems like New Relic. This is achieved through a unified GraphQL API gateway, which abstracts away the underlying complexity and offers a strongly typed, self-documenting schema.
Instead of agents or engineers struggling with fragmented data, mismatched schemas, or slow troubleshooting, the system now supports three primary interactivity patterns, each tuned for a different use case:
- Dynamic Schema Introspection: Agents can dynamically explore new or unfamiliar queries by introspecting the GraphQL schema itself. When a customer asks a unique question—such as whether a car’s value is affected by recent safety recalls—the agent can discover new data types on the fly and craft precise queries to fetch relevant answers. This flexibility enables the organization to quickly adapt to new business requirements without requiring manual API changes.
- Granular Mapped Tools: Each agent tool is mapped directly to a specific GraphQL query or mutation for routine operations. For example, updating a vehicle’s color is as simple as extracting the VIN and new color, with the agent handling the mutation. This approach increases reliability and reduces manual intervention, streamlining daily team tasks.
- Persistent Queries: High-traffic, performance-critical functions, such as real-time inventory dashboards, leverage pre-registered queries for maximum efficiency. The agent sends a lightweight hash and variables, and the system returns results instantly with reduced bandwidth and enhanced security.
Edmunds has dramatically improved the speed, flexibility, and reliability of data operations across product and support functions by giving AI agents structured access to all business data through a single, robust API layer. Tasks that previously required custom development or cross-team debugging are now handled in real-time, allowing customers and internal teams to benefit from richer insights and more agile responses.
Deep Dive 6: The Semantic and Knowledge Layers
This crucial layer serves as the bridge between raw data and agent comprehension. It abstracts away the complexity of underlying data stores. It enriches the data with business context, ensuring agents operate on a consistent, governed, and understandable view of the Edmunds universe.
- Unity Catalog: The Governance Backbone: At the core of our data ecosystem, Unity Catalog provides centralized governance, security, and lineage for all data and AI assets. It ensures that every piece of data accessed by an agent is subject to fine-grained access controls and that its journey is fully auditable, forming the non-negotiable foundation for a secure and compliant AI platform.
- Product Semantic Layer: Real-Time Business Context: This layer provides agents with a real-time, object-oriented view of our core product entities (e.g., vehicles, dealers, reviews). Critically, it is sourced directly from the same GraphQL schemas that power the Edmunds website. This ensures absolute consistency; when an agent discusses a "vehicle," it is referencing the same data model and business logic that a consumer sees on the website, eliminating any risk of data drift between our external products and our internal AI.
- Analytical Semantic Layer: The Single Source of Truth for KPIs: This layer provides a consistent and trusted view of all business performance metrics. It is sourced directly from our curated Delta Metric Views, which is the same source that feeds all executive and operational dashboards. This alignment guarantees that when DataDave or other agents report on business KPIs (like session traffic, leads, or appraisal rates), they use identical definitions and data sources as our established business intelligence tools, ensuring a single source of truth across the organization.
- Databricks AI Search - The Engine for RAG: This component is the high-performance retrieval engine for our unstructured and semi-structured data. By converting our vast corpus of reviews, articles, and transcribed content into vector embeddings, we enable agents like the Knowledge Assistant to perform lightning-fast semantic searches, retrieving the most relevant context to answer user queries in a Retrieval-Augmented Generation (RAG) pattern.
From Cost Center to Value Engine: Measuring Our AI ROI
A visionary architecture is only as good as its execution. Our approach is grounded in a phased roadmap and a deep commitment to treating our AI ecosystem as a core, value-generating engine. We achieve this by directly linking our technical framework for observability, governance, and ethics to key business outcomes. Our goal isn't just to build powerful AI; it's to quantify its impact on our bottom line.
Accelerating Business Velocity
We've built a holistic system to measure both sides of the ROI equation. On the return side, our framework connects AI performance directly to business KPIs. For example:
- Our DataDave agent delivers complex, actionable analytics in minutes, a task that previously took human Edmunds analysts hours to complete. This dramatically accelerates data-driven decision-making.
- Our pricing agents respond instantly to inquiries, eliminating hours of manual research and freeing up our teams to focus on strategic, high-value work.
While we are still quantifying the precise impact on metrics like campaign conversion rates, this framework provides the real-time data needed to draw those correlations.
Optimizing for Cost
We practice smart economic governance through our AI Gateway. High-stakes agents like DataDave are routed to our most powerful models to ensure accuracy, while routine tasks are automatically assigned to more cost-effective models. This model tiering strategy allows us to precisely manage our LLM and compute spend, ensuring every dollar invested is aligned with the business value it creates.
“Databricks lets us run the right model for the right task–securely and at scale. That flexibility powers our agents and delivers smarter car shopping experiences.” —Greg Rokita, VP of Technology, Edmunds
Organizational Enablement: Empowering Every Employee
To bring this vision to life, we are fostering a culture of innovation across Edmunds. We aim to support a full spectrum of human-AI interaction, from fully autonomous tasks to human-in-the-loop reviews and fully collaborative problem-solving.
To support this, we provide a robust Agent SDK for engineers and champion a "Citizen Developer" movement through our Agent Bricks platform. This initiative was kicked off with our company-wide "AI Agents @ Edmunds" tech conference and is nurtured by an active LLM Agents Guild, ensuring that every employee has the tools and support to contribute to our AI-driven future.
The Road Ahead: From Proactive Intelligence to True Autonomy
Our journey to becoming a truly AI-native organization is a marathon, not a sprint. The "Edmunds Mind" architecture serves as our blueprint for that journey, and its next evolutionary step is to develop proactive agents that not only answer questions but also anticipate business needs. We envision a future where our agents identify market opportunities from real-time data streams and deliver strategic insights to stakeholders before they even ask.
Ultimately, our roadmap leads to a system where agents can self-optimize—proposing new tools, refining critique mechanisms, and even suggesting architectural improvements. This marks a transition from a system we simply operate to a true cognitive partner, evolving our roles from operators to the overseers, ethicists, and strategists of a new, intelligent workforce.
Learn more about how Edmunds is building an AI-driven car buying experience with the help of Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.