MLOps at Walgreens Boots Alliance With Databricks Lakehouse Platform
by Yinxi Zhang, Feifei Wang and Peter Halliday
Standardizing ML Practices on the Lakehouse: Introducing Walgreens MLOps Accelerator
In this blog, we introduce the growing importance of MLOps and the MLOps accelerator co-developed by Walgreens Boots Alliance (WBA) and Databricks. The MLOps accelerator is designed to standardize ML practices, reduce the time to productionize ML model, boost collaboration between data scientists and ML engineers, and generate business values and return of investment on AI. Throughout this post, we explain the applications of MLOps on the Databricks Lakehouse Platform, how WBA automates and standarizes MLOps, and how you can replicate their success.
What is MLOps and why is it necessary?
MLOps, the composition of DevOps+DataOps+ModelOps, is a set of processes and automation to help organizations manage code, data, and models.

But putting MLOps into practice comes with its challenges. In machine learning (ML) systems, models, code, and data all evolve over time, which can create friction around refresh schedules and ML pipelines; meanwhile, model performance may degrade over time as data drifts requiring the model to be retrained. In addition, as data scientists keep exploring the datasets and apply various approaches to improve their models, they might find new features or other model families that work better. Then they update the code and redeploy it.
A mature MLOps system requires a robust and automated Continuous Integration/Continuous Deployment (CI/CD) system that tests and deploys ML pipelines, as well as Continuous Training (CT) and Continuous Monitoring (CM). A monitoring pipeline identifies model performance degradation and can trigger automated re-training.
MLOps best practices allow data scientists to rapidly explore and implement new ideas around feature engineering, model architecture, and hyperparameters – and automatically build, test, and deploy the new pipelines to the production environment. A robust and automated MLOps system auguments the AI initiatives of organizations from ideas to business value boost and generates return of investment on data and ML.
How WBA accelerated ML & Analytics with Lakehouse
Walgreens, one of the largest retail pharmacies and is a leading health and wellbeing enterprise, transitioned to a lakehouse architecture as its ML and analytics needs advanced. Azure Databricks has become the data platform of choice, while Delta Lake is a source for both curated and semantic data used for ML, analytics, and reporting use cases.
In addition to their technology, their methodology for delivering innovations has also changed. Before the transformation, each business unit was independently responsible for ML and analytics. As part of their transformation, Walgreens Boots Alliance (WBA), under the IT organization, established an organization that centralizes the activation of data, including ML and analytics. This platform helps productionize the needs of the business and accelerate turning discoveries into actionable production tools.
There are many examples of the Lakehouse at work within Walgreens to unlock the power of ML and analytics. For instance, RxAnalytics helps forecast stock level and return for individual drug categories and stores. This is critical both for balancing cost savings and customer demand. There are also similar ML applications on the retail side with projects like Retail Working Capital.
WBA's use cases span pharmacy, retail, finance, marketing, logistics, and more. At the center of all these use cases are Delta Lake and Databricks. Their success led us to co-build an MLOps accelerator with established best practices for standardizing ML development across the organization, reducingthe time from project initialization to production from more than 1 year to just a few weeks. We will dive into the design choices for WBA's MLOps accelerator next.
Understanding the Deploy Code Pattern
There are two main MLOps deployment patterns: "deploy model" and "deploy code." For the deploy model, model artifacts are promoted across environments. However, this has several limitations, which The Big Book of MLOps outlines in detail. In contrast, deploy code uses code as the sole source of truth for the entire ML system, including resource configurations and ML pipeline codes, and promotes code across environments. Deploy code relies on CI/CD for automated testing and deployment of all ML pipelines (i.e. featurization, training, inference, and monitoring). This results in models being fit via the training pipeline in each environment, as shown in the diagram below. In summary, deploy code is to deploy the ML pipeline code that can automate the re-training and deployment of models generated from the pipeline.
The monitoring pipeline analyzes data and model drift in production or skew between online/offline data. When data drifts or model performance degrades, it triggers model retraining, whichin essence is just re-running a training pipeline from the same code repository with an updated dataset, resulting in a new version of the model. When modeling code or deployment configuration is updated, a pull request is sent and triggers the CI/CD workflow.
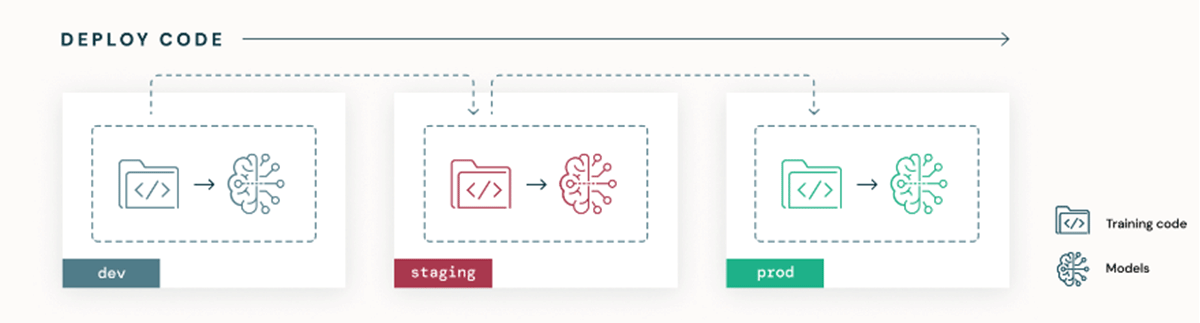
If an organization restricts data scientists' access to production data from dev or staging environments, deploying code allows training on production data while respecting access controls. The steep learning curve for data scientists and relatively complex repository structure are disadvantages, but adopting the deploy code pattern in the long haul will boost collaboration and ensure a seamlessly automated, reproducible process to productionize ML pipelines.
To showcase this deploy code pattern and its benefits, we'll walk through WBA's MLOps accelerator and implementations of infrastructure deployment, CICD workflow, and ML pipelines.
WBA MLOps Accelerator Overview
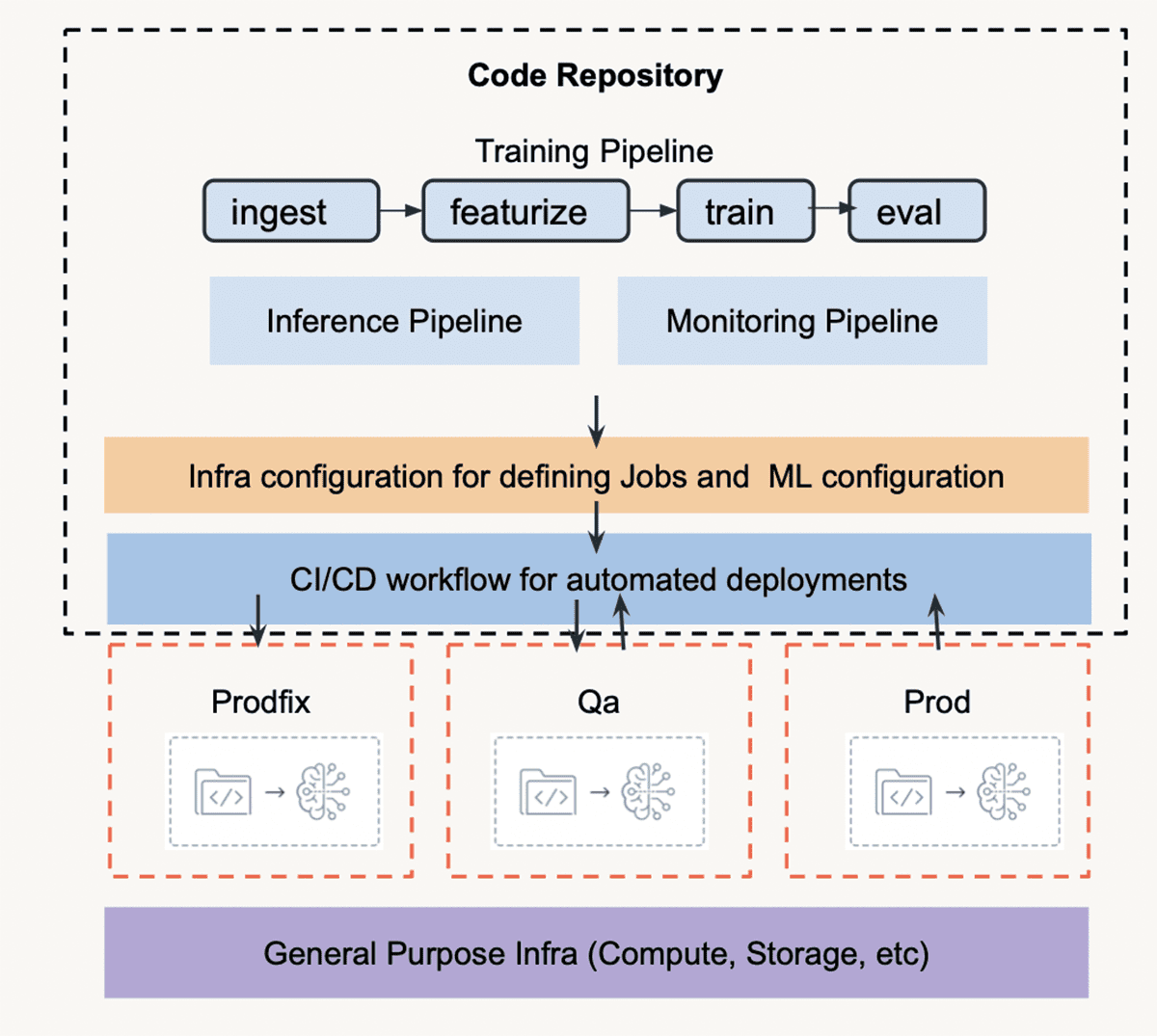
Let's first go over the stack. WBA develops in-house tools to deploy infrastructure and provision Databricks workspaces at scale. WBA leverages Azure DevOps and Azure Repos for CI/CD and version control, respectively. The MLOps accelerator, jointly developed by Databricks and WBA, is a repository that can be forked and integrated with Databricks workspaces to deploy notebooks, libraries, jobs, init scripts and more. It provides predefined ML steps, notebooks that drive the ML pipelines, and pre-built Azure Pipelines for CI/CD, simply requiring an update of configuration files to run out of the box. On the DataOps side, we use Delta Lake and Databricks Feature Store for feature management. The modeling experiments are tracked and managed with MLflow. In addition, we adopted a Databricks preview feature, Model Monitoring, to monitor data drift in the production environment and generalize to experimentation platforms.
The accelerator repository structure, depicted below, has three main components: ML pipelines, configuration files, and CI/CD workflows. The accelerator repository is synchronized to each Databricks workspace in the corresponding environment with the CI/CD workflow. WBA uses Prodfix for development work, QA for testing, and Prod for production. Azure resources and other infrastructure are supported and managed by WBA's in-house tooling suite.
MLOps User Journey
In general, there are two types of teams/personas involved in the entire workflow: ML engineers and data scientists. We will walk you through the user journey in the following sections.
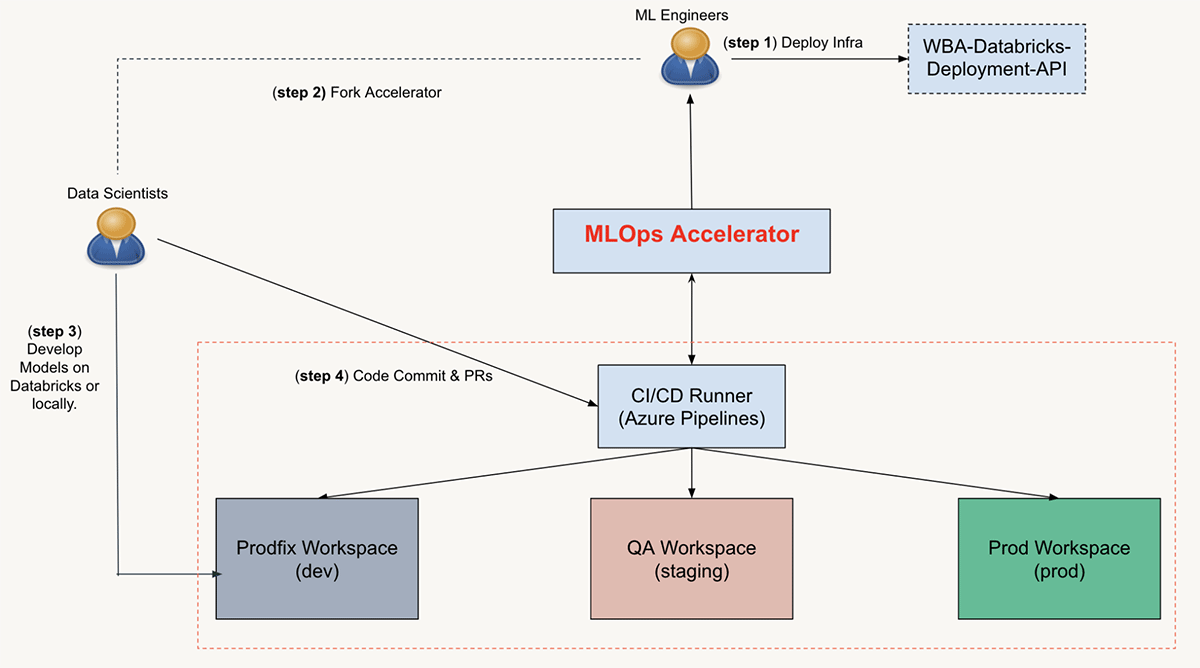
To start a project, the ML engineers will initialize the ML project resources and repository by deploying the infrastructure pipeline, forking the MLOps accelerator repository to an ML project repository, setting up the CI/CD configurations, and sharing the repository with the data science team.
Once the project repository is ready, data scientists can start iterating on the ML modules and notebooks immediately. With commits and PRs, code merging will trigger the CI/CD runner for unit and integration tests, and eventually deployments.
After the ML pipelines are deployed, the ML engineers can update deployment configurations, such as scheduling for batch inference jobs and cluster settings, by committing changes to configuration files and merging PRs. Just like code changes, modifications in configuration files trigger corresponding CI/CD workflow to redeploy the assets in Databricks workspaces.
Managing Lakehouse Infrastructure
The MLOps Accelerator builds on the infrastructure systems that create, update, and configure all Azure and Databricks resources. In this section, we will introduce the systems to perform the first step of the user journey: initializing project resources. With the right tools, we can automate the provisioning of Azure and Databricks resources for each ML project.
Orchestrating Azure Resources
In WBA, all deployments to Azure are governed by a centralized team that creates the required Azure Resource Management (ARM) template and parameter files . They also grant access to and maintain the deployment pipeline for these templates.
WBA has built a FastAPI microservice called the Deployment API that uses environment-specific YAML configuration files to collect all the resources a project needs and its configuration in one place. The Deployment API keeps track of whether the YAML configuration has changed and, therefore, whether it needs to update that resource. Each resource type can utilize post-deployment configuration hooks, which can include additional automation to augment the activities of the central deployment pipeline.
Configuring Databricks
After using the Deployment API to deploy a Databricks workspace, it's a blank slate. To ensure a Databricks workspace is configured according to the project's requirements, the Deployment API uses a post-deployment configuration hook, which sends the configuration of a Databricks workspace to a microsystem that enforces the updates.
The first aspect of configuring a Databricks workspace is synchronizing the users and groups that should access Databricks via the Databricks' SCIM integration. The microsystem performs the SCIM integration by adding and removing users based on their membership in the groups configured to be given access. It gives each group fine-grained access permissions, such as cluster creation privileges and Databricks SQL. In addition to SCIM integration and permissions, the microsystem can create default cluster policies, customize cluster policies, create clusters, and define init scripts for installing in-house python libraries.
Connecting the Dots
The Deployment API, the Databricks Configuration Automation, and the MLOps Accelerator all work together in an interdependent way so projects can iterate, test, and productionize rapidly. Once the infrastructure is deployed, ML engineers fill in the information (e.g. workspace URL, user groups, storage account name) in the project repository configuration files. This information is then referenced by the pre-defined CI/CD pipelines and ML resource definitions.
Automate Deployment with Azure Pipelines
Below is an overview of the code-promoting process. The git branching style and CI/CD workflow are opinionated but adjustable to each use case. Due to the diverse nature of projects in WBA, each team might operate slightly differently. They are free to select components of the accelerator that best fit their purpose and customize their projects forked from the accelerator.
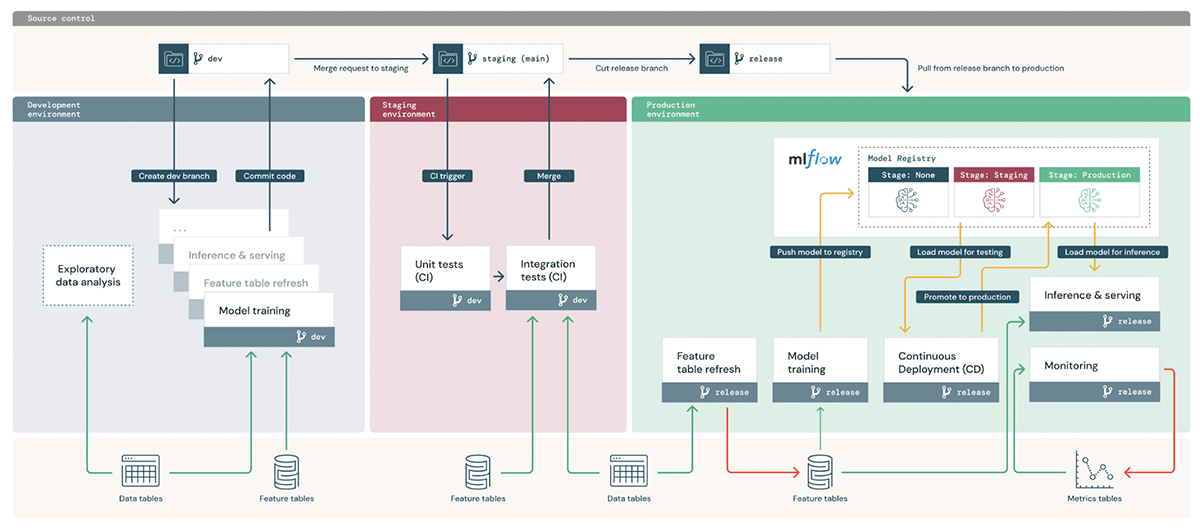
Code Promoting Workflow
The project owner starts by defining a production branch (the "master" branch in our example architecture). Data scientists do all their ML development on non-production branches in the Prodfix workspace. Before sending PRs to the "master" branch, data scientists' code commit can trigger tests and batch job deployment in the development workspace. Once the code is ready for production, a PR is created, and a full testing suite is run in the QA environment. If the tests pass and reviewers approve the PR, the deployment workflow is invoked. In the Prod workspace, the training pipeline will be executed to register the final model, and inference and monitoring pipelines will be deployed. Here's a zoom-in on each environment:
- Prodfix: Exploratory Data Analysis (EDA), model exploration, and training and inference pipelines should all be developed in the Prodfix environment. Data scientists should also design the monitor configurations and analysis metrics in Prodfix because they understand the underpinnings of the models and what metrics to monitor the best.
- QA: Unit tests and integration tests are run in QA. Monitor creation and analysis pipeline must be tested as part of integration tests. An example integration test DAG is shown below. It is optional to deploy training or inference pipelines in QA.
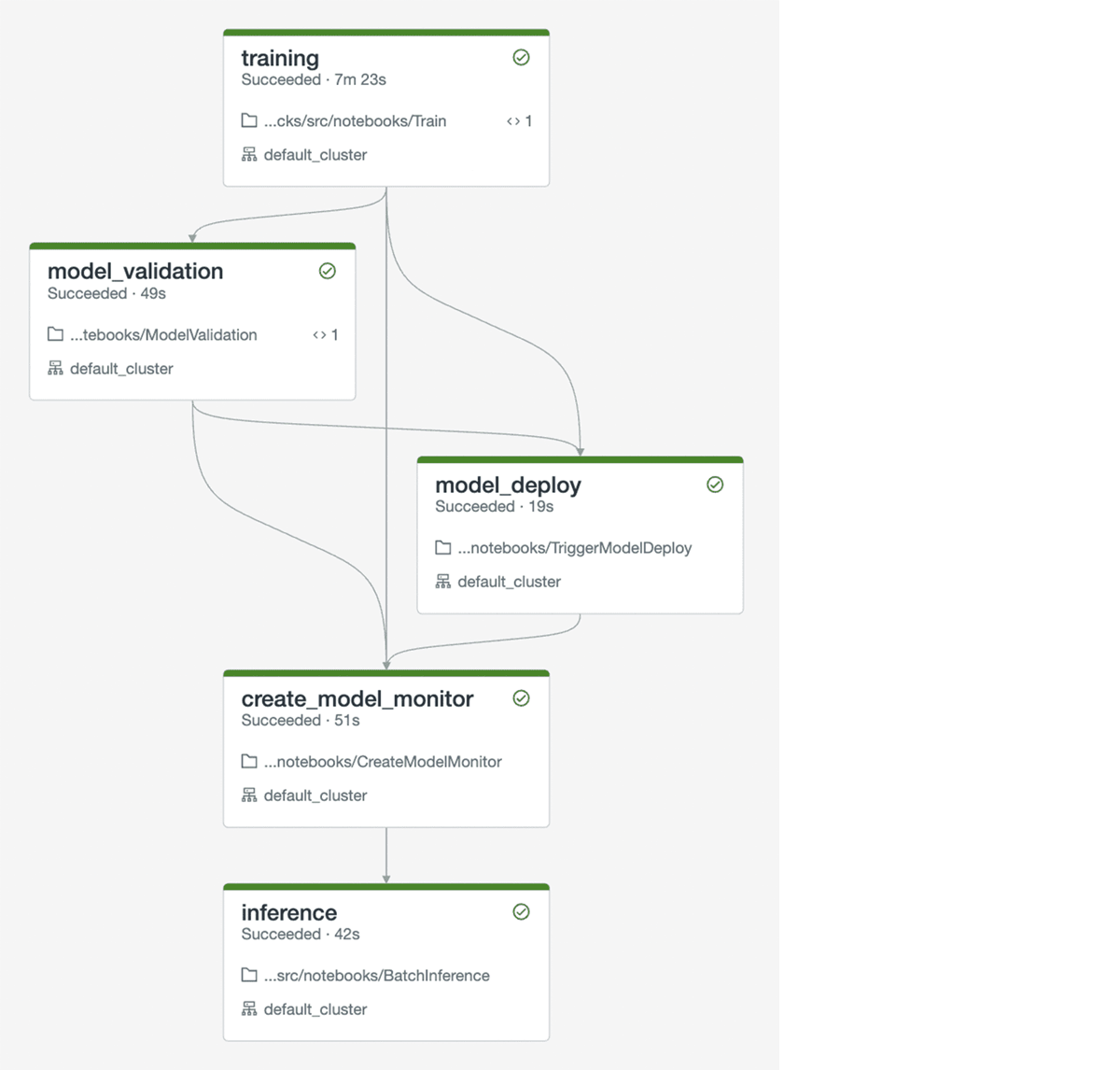
- Prod: Training, inference, and monitoring pipelines are deployed to the production environment with the CD workflow. Training and inference are scheduled as recurring jobs with Notebook Workflows. The monitoring pipeline is a Delta Live Table (DLT) pipeline.
Managing Workspace Resources
Besides code, ML resources like MLflow experiments, models, and jobs are configured and promoted by CI/CD. Because integration tests are executed as job runs, we need to build a job definition for each integration test. This also helps organize historical tests and investigate test results for debugging. In the code repository, the DLT pipelines and job specifications are saved as YAML files. As mentioned, the accelerator uses WBA's in-house tools to manage workspace resource permissions. The DLT, job, and test specifications are supplied as payloads to Databricks APIs but used by a custom wrapper library. Permission controls are configured in the environment profiles YAML files in the "CICD/configs" folder.
The high-level project structure is shown below.
For example, below is a simplified "training.yml" file in the "/jobs" folder. It defines how the training pipeline is deployed as a notebook job named "training" and runs the "Train" notebook at US Central time midnight every day using a cluster with 11.0 ML Runtime and 1 worker node.
Here are the steps to synchronize the repository:
- Import the repository to the Databricks workspace Repos
- Build the designated MLflow Experiment folder and grant permissions based on the configuration profiles
- Create a model in MLflow Model Registry and grant permissions based on the configuration profiles
- Run tests (Tests use MLflow experiments and model registry, so it needs to be executed after steps 1-3. Tests must be run before any resources get deployed.)
- Create DLT pipelines
- Create all jobs
- Clean up deprecated jobs
Standardize ML pipelines
Having pre-defined ML pipelines helps data scientists create reusable and reproducible ML code. The common ML workflow is a sequential process of data ingestion, featurization, training, evaluation, deployment, and prediction. In the MLOps Accelerator repository, these steps are modularized and used in Databricks notebooks. (See Repos Git Integration for details). Data scientists can customize the "steps" for their use cases. The driver notebooks define pipeline arguments and orchestration logic. The accelerator includes a training pipeline, an inference pipeline, and a monitoring pipeline.
Data & Artifact Management
Now let's talk about data and artifact management of the ML pipelines, as data and models are constantly evolving in an ML system. The pipelines are Delta and MLflow centric. We enforce input and output data in Delta format and use MLflow to log experiment trials and model artifacts.
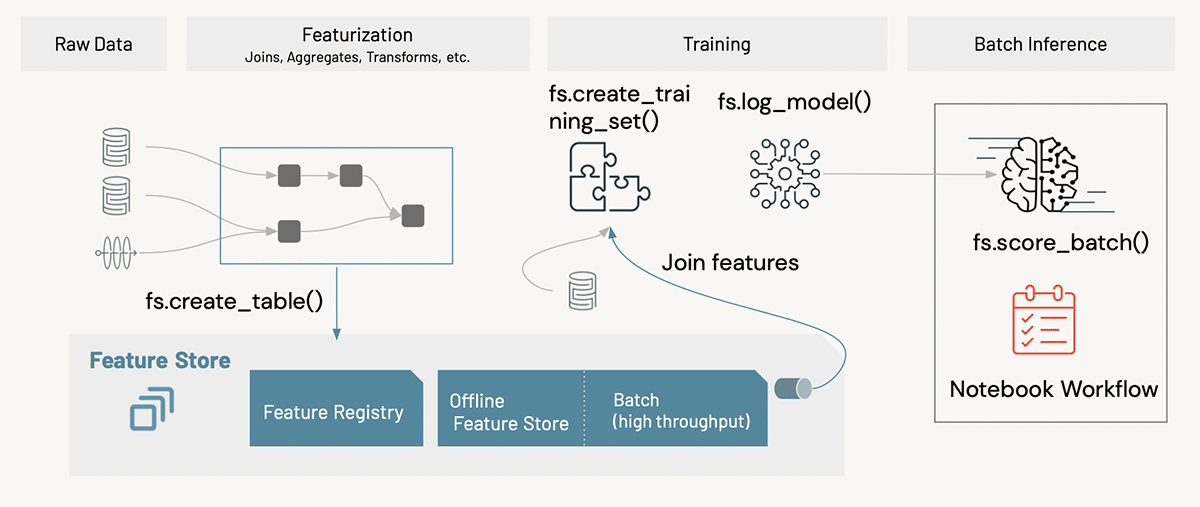
In the WBA MLOps Accelerator, we also use the Databricks Feature Store, which is built on Delta and MLflow, to track both model upstream lineage (i.e., from data sources and features to models) and downstream lineage (i.e., from models to deployment endpoints). Pre-computed features are written to project-specific feature tables and used together with context features for model training. The inference process uses the batch scoring functionality available with the Databricks Feature Store API. In deployment, feature tables are written as a step of the training pipeline. This way, the production model is always loading from the latest version of features.
Pipeline Orchestration
As described, training and inference are batch jobs, while monitoring is deployed as a DLT pipeline. The training pipeline first loads data from Delta tables stored in ADLS, then engineers and writes features and to the workspace Feature Store. Then, it generates a training dataset from the feature tables, fits an ML model with the training dataset, and logs the model with Feature Store API. The final step of the training pipeline is model validation. If the model passes, it automatically promotes the model to the corresponding stage("Staging" for the QA environment and "Production" for Prod).
The inference pipeline calls `fs.score_batch()` to load the model from the model registry and generate predictions. Users don't need to provide complete feature sets for scoring data, just feature table keys. The Feature Store API looks up pre-computed features and joins them with context features for scoring.
In the development stage, data scientists determine the configuration for model monitoring, such as which metrics need to be be tracked to evaluate model performance (e.g., minimum, max, mean, median of all columns, aggregation time windows, model-quality metrics, and drift metrics).
In the production environment, the inference requests (model inputs) and the corresponding prediction results are logged to a managed Delta table tied to the monitoring process. The true labels usually arrive later and come from a separate ingestion pipeline. When labels are available, they should be added to the request table, as well to drive model evaluation analysis. All monitoring metrics are stored back into separate Delta tables in the Lakehouse and visualized in a Databricks SQL dashboard. Alerts are set based on chosen drift metric threshold. The monitoring framework also enables model A/B testing and fairness and bias studies for future use cases.
Conclusion
MLOps is an emerging field in which folks in the industry are developing tools that automate the end-to-end ML cycle at scale. Incorporating DevOps and software development best practices, MLOps also unfolds DataOps and ModelOps. WBA and Databricks co-developed the MLOps accelerator following the "deploy code" pattern. It guardrails the ML development from day 1 of project initialization and drastically reduces the time it takes to ship ML pipelines to production from years to weeks. The accelerator uses tools like Delta Lake, Feature Store, and MLflow for ML lifecycle management. Those tools intuitively support MLOps. For infrastructure and resource management, the accelerator relies on WBA's internal stack. Open-source platforms like Terraform provide similar functionality too. Do not let the complexity of the accelerator scare you away. If you are interested in adopting production ML best practices discussed in this article, we provide a reference implementation for creating a production-ready MLOps solution on Databricks. Please submit this request to get access to the reference implementation repository.
If you are interested in joining this exciting journey with WBA, please check out Working at WBA. Peter is hiring a Principal MLOps Engineer!
About the Authors
Yinxi Zhang is a Senior Data Scientist at Databricks, where she works with customers to build end-to-end ML systems at scale. Prior to joining Databricks, Yinxi worked as an ML specialist in the energy industry for 7 years, optimizing production for conventional and renewable assets. She holds a Ph.D. in Electrical Engineering from the University of Houston. Yinxi is a former marathon runner, and is now a happy yogi.
Feifei Wang is a Senior Data Scientist at Databricks, working with customers to build, optimize, and productionize their ML pipelines. Previously, Feifei spent 5 years at Disney as a Senior Decision Scientist. She holds a Ph.D co-major in Applied Mathematics and Computer Science from Iowa State University, where her research focus was Robotics.
Peter Halliday is a Director of Machine Learning Engineering at WBA. He is a husband and father of three in a suburb of Chicago. He has worked on distributed computing systems for over twenty years. When he's not working at Walgreens, he can be found in the kitchen making all kinds of food from scratch. He's also a published poet and real estate investor.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.