5x Faster Image Segmentation Training with MosaicML Recipes
Can't stop, won't stop. Earlier this year, we shared a new baseline for semantic segmentation (basically, classifying an image at the pixel level) using DeepLabv3+ model architecture on the ADE20k dataset. Now, we're introducing recipes for training semantic segmentation models that either reduce time-to-train by up to 5.4x or improve quality by up to +4.6 mIoU. If you want to train your segmentation models on the best ML training platform available, learn more at mosaicml.com/cloud

When we take a picture, the image is represented by raw pixel values - a matrix of numbers without meaning. Semantic segmentation tells us what we are seeing and what each part of the image represents. It's used in applications like:
- Analyzing medical images to help radiologists identify tumors
- Identifying objects captured by autonomous vehicle cameras
- Object-centric video/image editing to remove harmful or offensive content
For all of these use cases, performance is essential (obviously), but that performance comes at a cost. And if you're paying by the hour (or minute) for compute, speed is everything. That's why we built a set of recipes to optimally trade-off training time and model quality.
We developed and benchmarked these recipes by training a standard semantic segmentation model (DeepLabv3+ model with a ResNet-101 backbone) on the ADE20k dataset. These recipes can easily be adapted to new models and datasets using our Composer example training script and public Docker images – try for yourself!
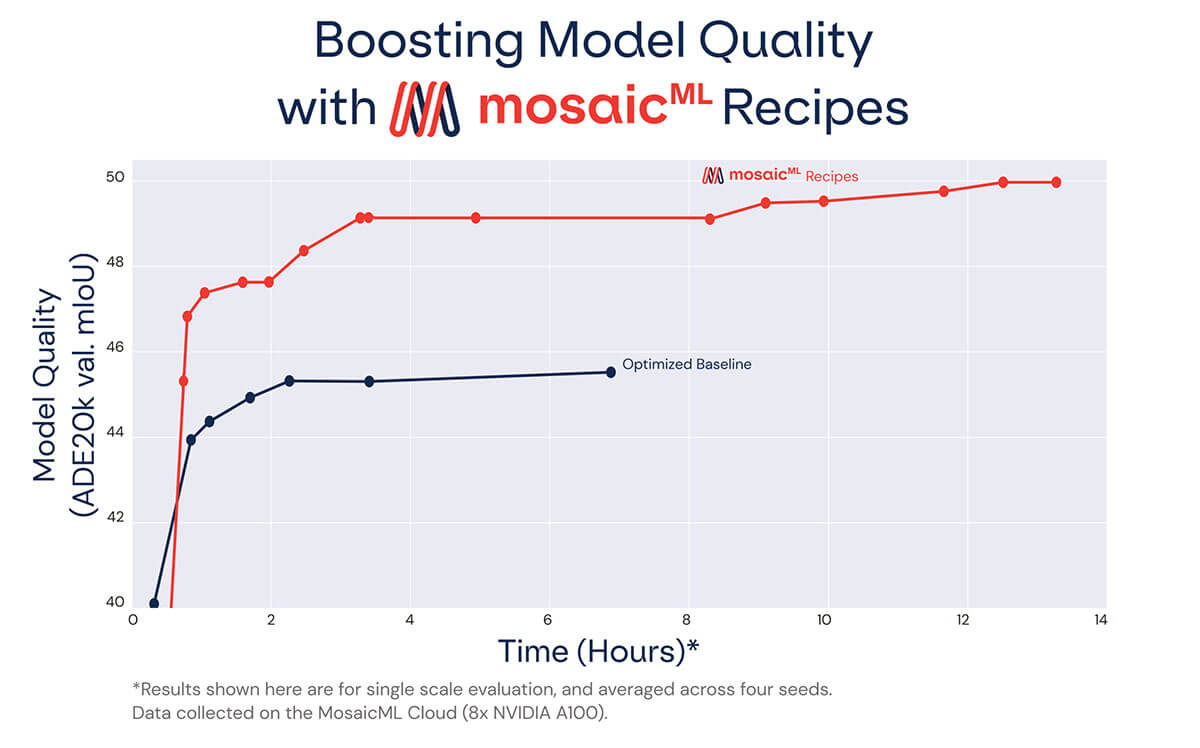
Introducing our recipes
All About that Base(Line)
Establishing a strong baseline is a critical first step for efficiency research. In our previous blog, we showed that common settings for training ResNet101+DeepLabV3+ on ADE20k (the unoptimized baseline) are inefficient, so we developed the optimized baseline. Through simple hyperparameter tuning and better pretrained weights, we reduced the runtime from 6.4 hours to 3.5 hours (a 1.8x speedup), while increasing the mIoU from 44.17 to 45.33. This optimized baseline was our new target to beat with our recipes.
To develop the recipes, we evaluated a number of different speedup methods that change the way models are trained. The beneficial methods were then composed to form the training recipes we present in this blog. We evaluated the resulting models for quality (by comparing their mIoU on the validation set) and for speed (by comparing training time to our optimized baseline)1.
Similar to our recipes for ResNet-50, we targeted three scenarios with different performance goals and developed a training recipe for each of these scenarios.
Drumroll please…our three recipes (with rankings inspired by Taco Bell) are:
- (Mild) Minimize training cost given a baseline mIoU target (45.48 mIoU in 39 minutes vs. 3.5 hours for the baseline)
- (Medium) Maximize quality given a baseline training cost (49.32 mIoU in 3.55 hours vs 45.33 mIoU for the baseline)
- (Hot) Highest quality with no constraint on training cost (49.91 mIoU in 13.5 hours)
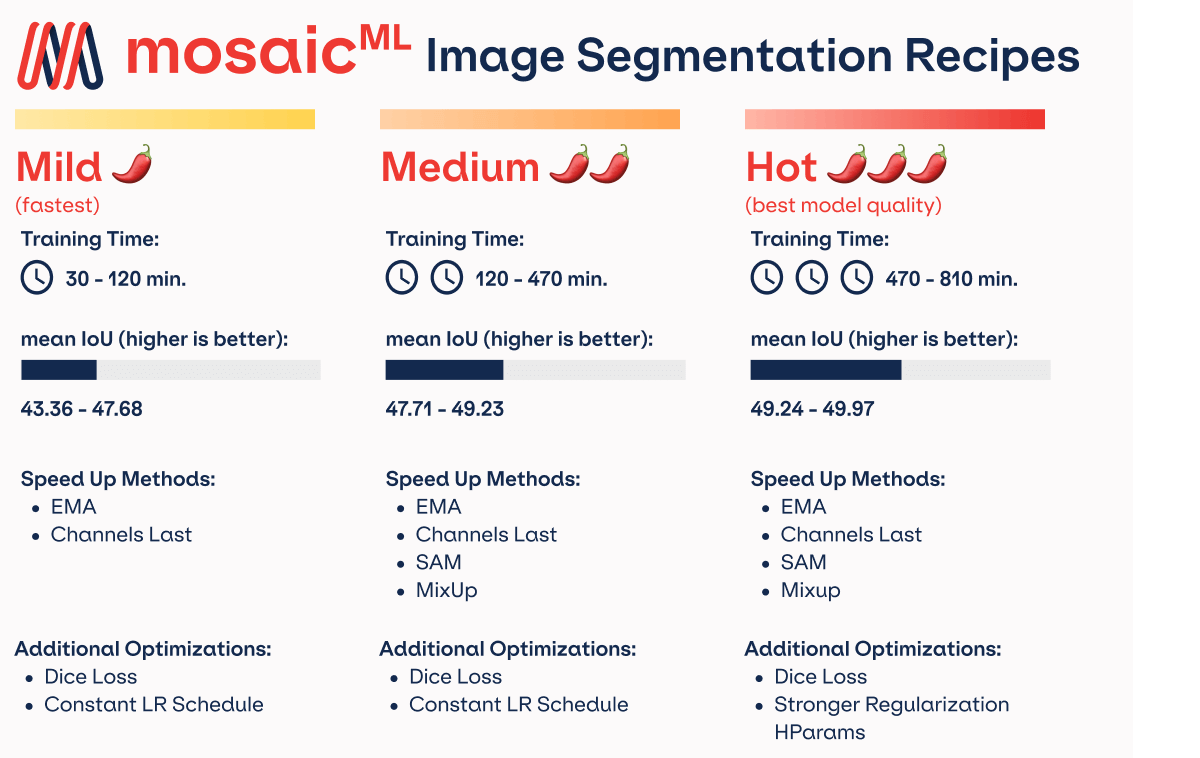
Mild (fastest)
For the mild recipe, speed is the name of the game. Our goal was to reach baseline performance of 45.33 mIoU as fast as possible. To make this happen, we were able to reduce the number of training epochs by more than 5x by using an exponential moving average (EMA) of model weights with a half-life of 1000 batches (default) and an update interval of 10 batches. EMA has a small impact on throughput which can be offset with the channels last memory format, resulting in a total throughput improvement of 1.07x. The end result: this recipe reaches target accuracy 5.4x faster than our baseline2.
Medium
With our medium recipe, quality is the goal. We wanted to improve model performance by increasing mIoU using the same computational resources as the baseline. Since speed wasn't our main concern, we used extra regularization in the form of MixUp with default hyperparameters. Because of the smaller number of samples in ADE20k, we also used an aggressive sharpness aware minimization (SAM) with rho=0.3 and interval=2. This recipe achieves an mIoU of 49.32 when training for the same amount of time as our optimized baseline, a +4.0 mIoU improvement, and is optimal for training durations between 50 and 140 epochs.
Hot (best model quality)
No limits, no mercy: our goal with the "hot" recipe was to reach the highest possible mIoU without any constraint on the training time. Again, we found that increasing regularization led to the biggest improvements in quality. We did not add any additional algorithms, but doubled the EMA half-life and increased the MixUp alpha parameter by 2.5x. We also found it beneficial to run EMA and SAM on every training iteration instead of on a subset of iterations. The hot recipe is trained for 2x more epochs than the baseline to realize the improvement from the additional regularization. The final result is a mIoU of 49.91 in 13.47 hours, a +4.58 mIoU improvement over our baseline!
Secret Menu Items
Apologies to Taco Bell fans, we're not talking about the Enchirito. For all recipes, we included a Dice loss term in the objective function in addition to the standard cross entropy loss. Dice loss improved mIoU by +0.85 but reduced throughput by 0.9x when compared to the baseline. We found that Dice loss delivered significant improvement for short training durations and helped increase the improvement from methods such as EMA, SAM and MixUp.
For the mild and medium recipes, we used a constant learning rate schedule without any impact on performance. This is likely due to using EMA and a short training duration. With a constant learning rate, we can increase or decrease the training duration without having to train from scratch for each desired training duration.
Test Results
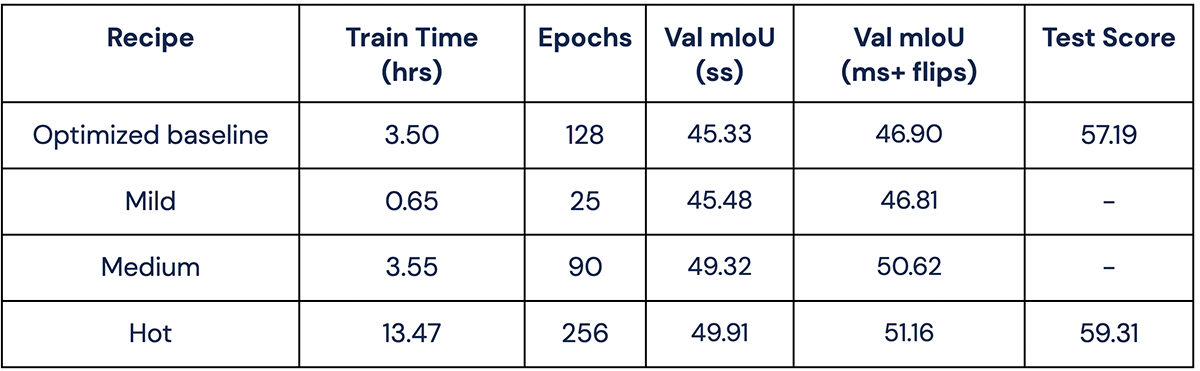
After developing and training with our recipes, we decided to go the extra mile and test them in more challenging settings. First, we measured mIoU with standard test-time augmentations (TTA) - our results for single scale (ss) and multiscale + horizontal flips (ms + flips) are below. As the ultimate challenge for DeepLabV3+, we submitted our Hot recipe results to the ADE20k test leaderboard. The leaderboard submission calculates a "Test Score" which is the average of per-pixel accuracy and mIoU on a test set without publicly available labels.
Better Recipes ≧ More Data, Bigger Models?
To improve performance of semantic segmentation, researchers typically use one of three methods:
- more pre-training data
- a larger model size with more parameters
- a new model architecture
There's a fourth way: better training recipes. With with our recipes, we show that algorithmic changes to the training loop can make an architecture from 2018 competitive with more modern architectures.
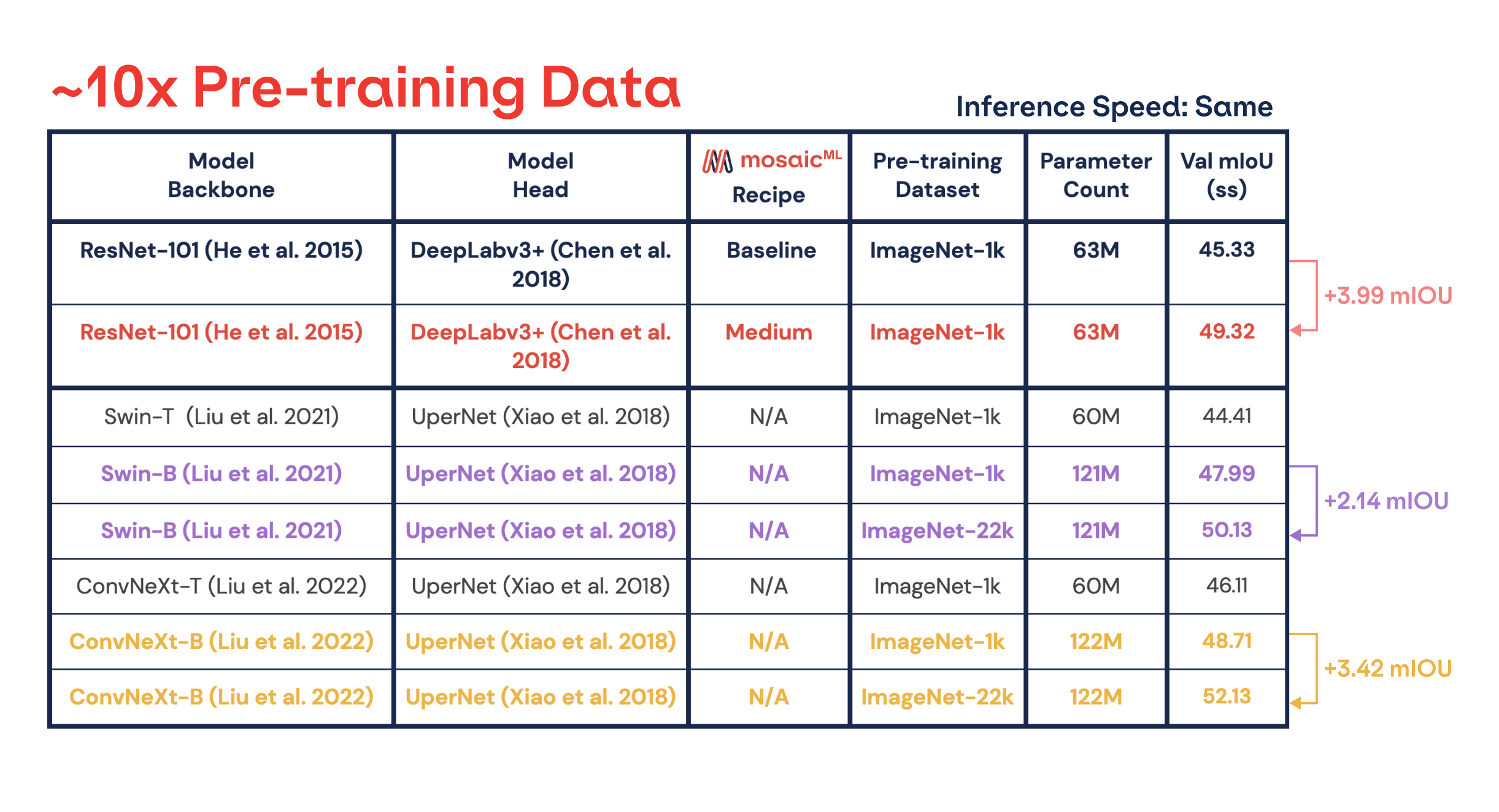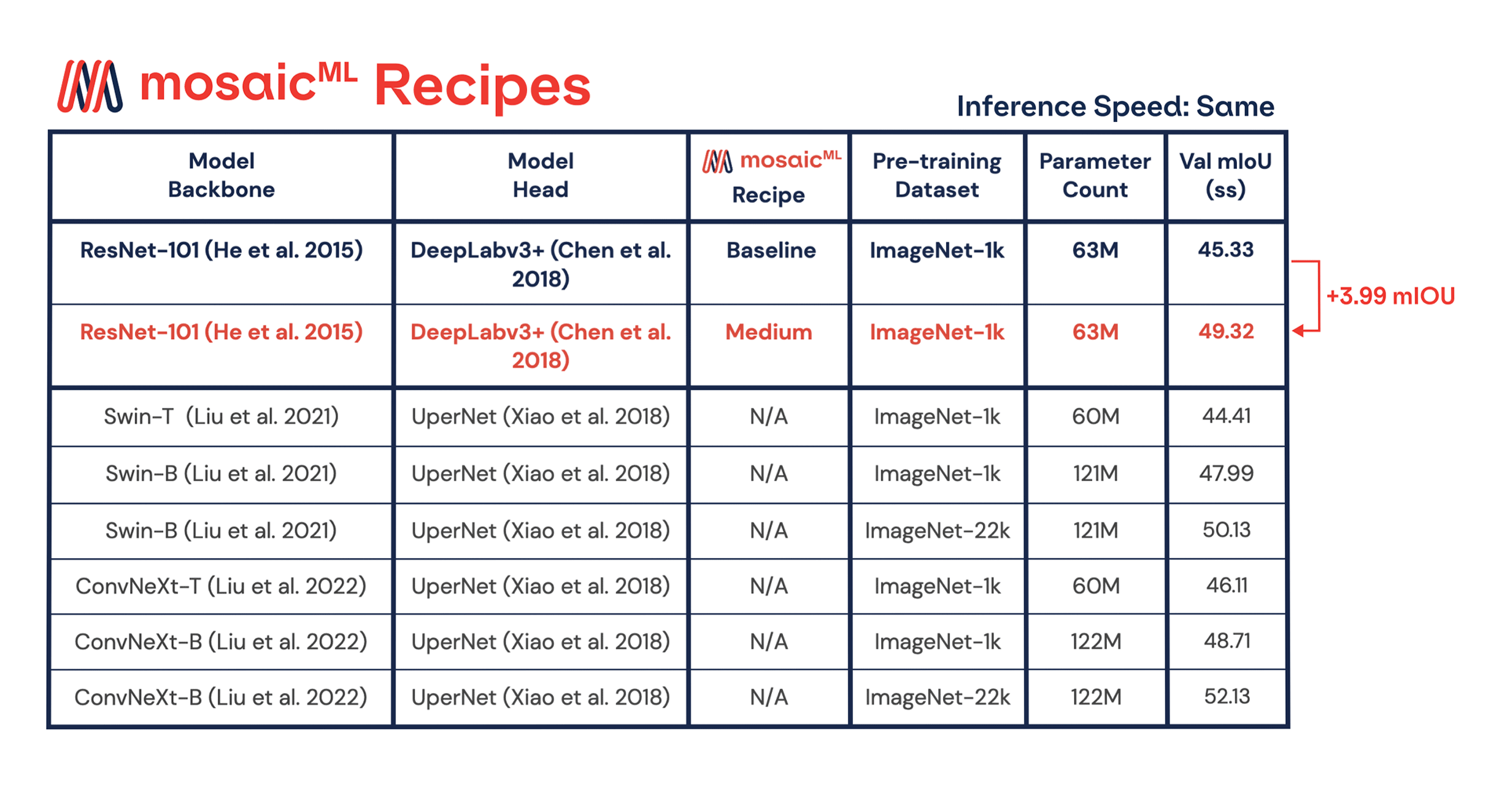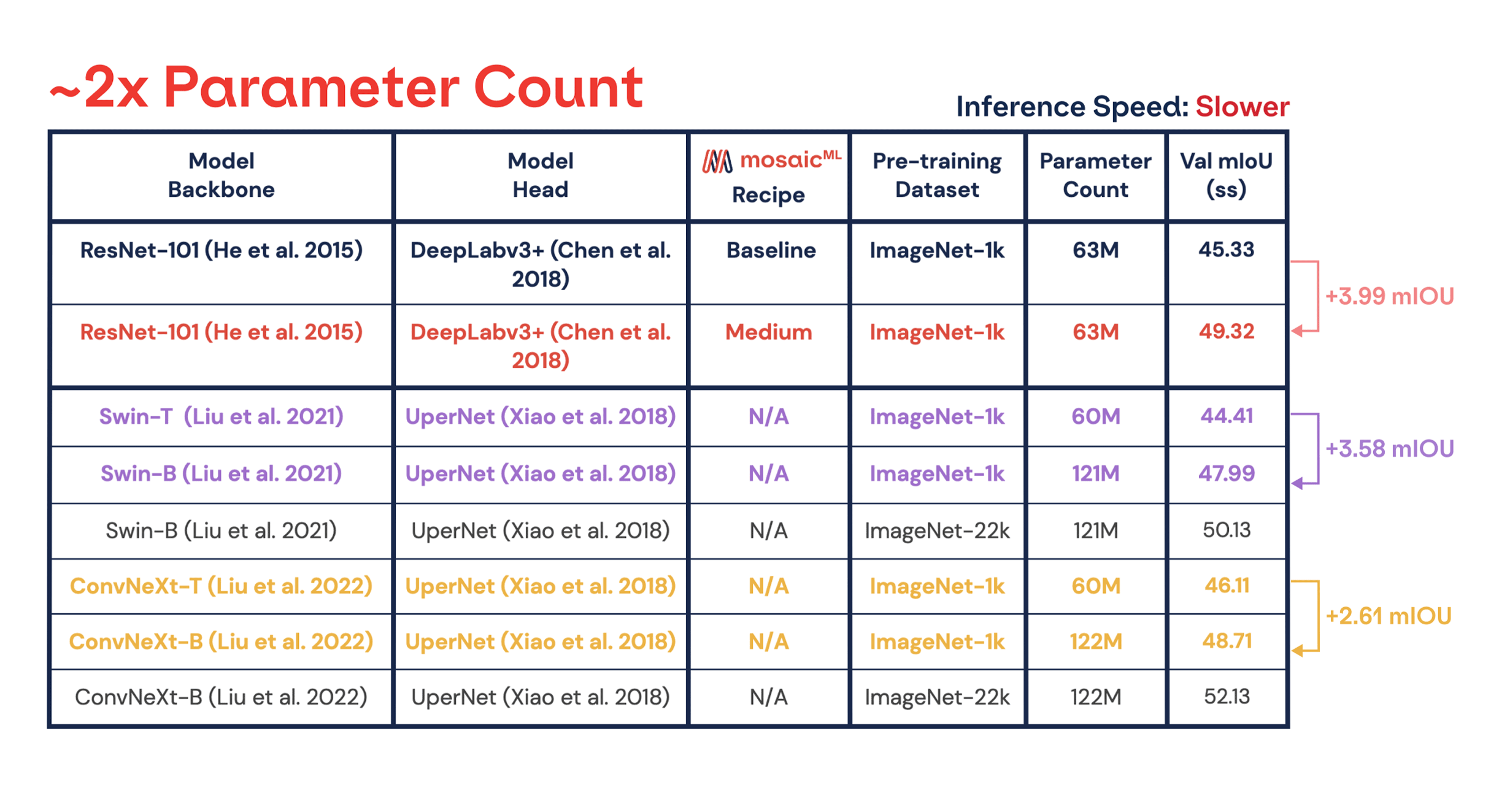
In Figure 4, we have shown a +3.99 mIoU improvement without impacting time-to-train by using our medium recipe. Previous works improved mIoU performance by scaling the pre-training dataset size and model size, but better training recipes have largely been neglected in the segmentation space. We examine the impact of scaling on two recent architectures: Swin and ConvNeXt. From Figure 5, doubling the number of model parameters leads to +2.6-3.6 improvement in mIoU. Similarly, using 10x pre-training data leads to +2.1-3.4 improvement in mIoU. Although our recipe improvements were measured on a different architecture, we conjecture that improvements from recipes are comparable to increasing the model size or the amount of pre-training data. Neglecting to use an optimized recipe leaves substantial performance on the table. In the end, all of these improvements can be applied simultaneously for the highest performance.
Get a Taste of the MosaicML Platform
Going forward, we're investigating how these recipes will transfer to other segmentation models or datasets. For example, using these recipes on satellite imagery datasets lead to significant reduction in training time (expect to hear soon from us soon on that front)!
Looking to train your own segmentation models on your domain-specific data? We developed these recipes and baked them into the MosaicML platform to help our customers achieve high quality vision models faster. Schedule a demo today!
1 We do not modify the baseline hyperparameters, so the batch size, learning rate, weight decay, etc. from the baseline are fixed. When additional hyperparameters are introduced, such as when we add a training method like mixup, we use Composer's default hyperparameter where appropriate, and tune from there to improve performance.
2 The Mild recipe works best on training durations between 20 and 50 epochs, as there is a short initial period of roughly 20 epochs where Mild performs worse than the baseline due to the moving average warmup time.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.