Behind the Scenes: Setting a Baseline for Image Segmentation Speedups
We establish a new semantic segmentation baseline of 45.56 mIoU on the ADE20k segmentation benchmark in 3.5 hours on a system with 8x NVIDIA A100 GPUs.
At MosaicML, we demonstrated that Composer can train a ResNet model on ImageNet 7x faster. Next, we set our sights on demonstrating speedups on more complex computer vision tasks. In this blog, we will describe the foundation for our future speedups on semantic segmentation.
What is Semantic Segmentation?
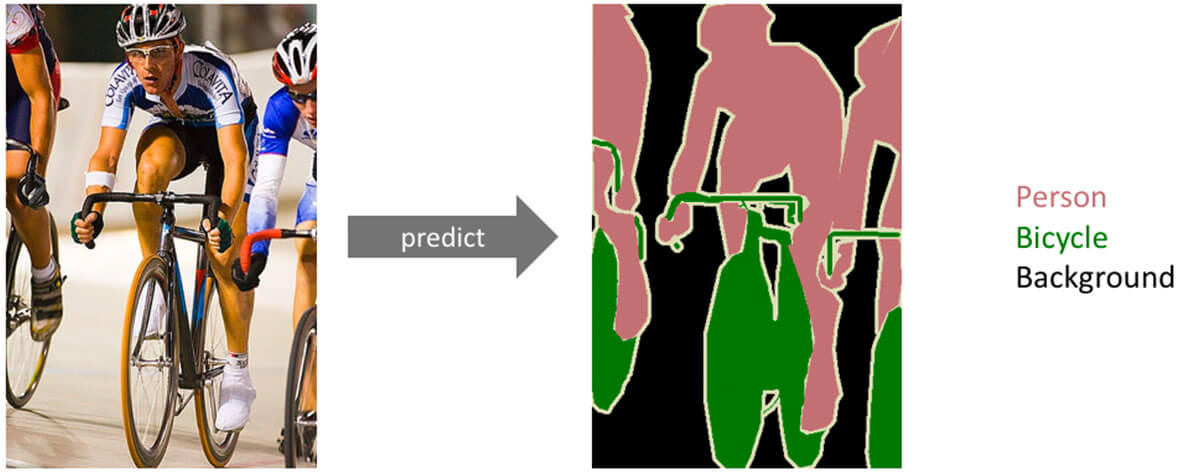
Semantic segmentation is a computer vision task where the goal is to assign a single class label to each pixel in an image (see figure 1). There are three major domains where semantic segmentation is used:
- Scene imagery: images people tend to observe day-to-day.
- Medical imagery: a variety of imagery used to assess diseases e.g. x-ray, MRI, etc.
- Satellite imagery: images from overhead satellites.
Semantic segmentation maps provide precise semantic and spatial information about an image. This information is key to several industry use cases such as navigating a car through busy city streets, diagnosing diseases captured in medical imaging or assessing building damage after a natural disaster in satellite imagery.
Establishing a Strong Baseline
When we start on a project to increase training efficiency, the first question is: how do we know we’re delivering a valuable improvement? How do we evaluate performance? The answer: establishing a strong baseline. A common pitfall for efficiency research is to test against “weak” baselines, i.e., baselines that can be improved through simple tweaks like larger batch sizes or optimized hyperparameters.
Establishing strong baselines is particularly important in semantic segmentation because this task does not have significantly tuned baselines. With that in mind, we want to define our baseline very clearly, and account for the latest improvements in the state of the art, before evaluating speedup methods. In this fast-moving space, our 2022 research should not measure its success relative to a performance benchmark from 2018.
Choosing the benchmark task, metrics and model
We focus on the ADE20k scene parsing benchmark since this is a popular semantic segmentation benchmark and its relatively small training set size allows for fast experimentation. Similarly, DeepLabv3+ was picked as the baseline model since it is a widely used and well understood architecture for segmentation tasks.
We evaluate the performance on the validation dataset using the mean Intersection-over-Union (mIoU) metric, which is conventionally used with the ADE20k dataset. This choice allows for easier comparison of our results to previous papers that use ADE20k.
Our starting point consists of PyTorch’s version 1 ImageNet pre-trained weights and hyperparameters based on MMsegmentation’s DeepLabv3+ baseline. With this initial setup, DeepLabv3+ achieves 44.17 mIoU on ADE20k, replicating baseline performance reported in previous papers.
Strengthening the baseline
We apply and test four changes to the starting point to strengthen the baseline:
- Update the pre-trained weights
- Decouple the learning rate and weight decay
- Use a cosine decay learning rate schedule
- Increase the batch size
Step 1: Updated pre-trained weights
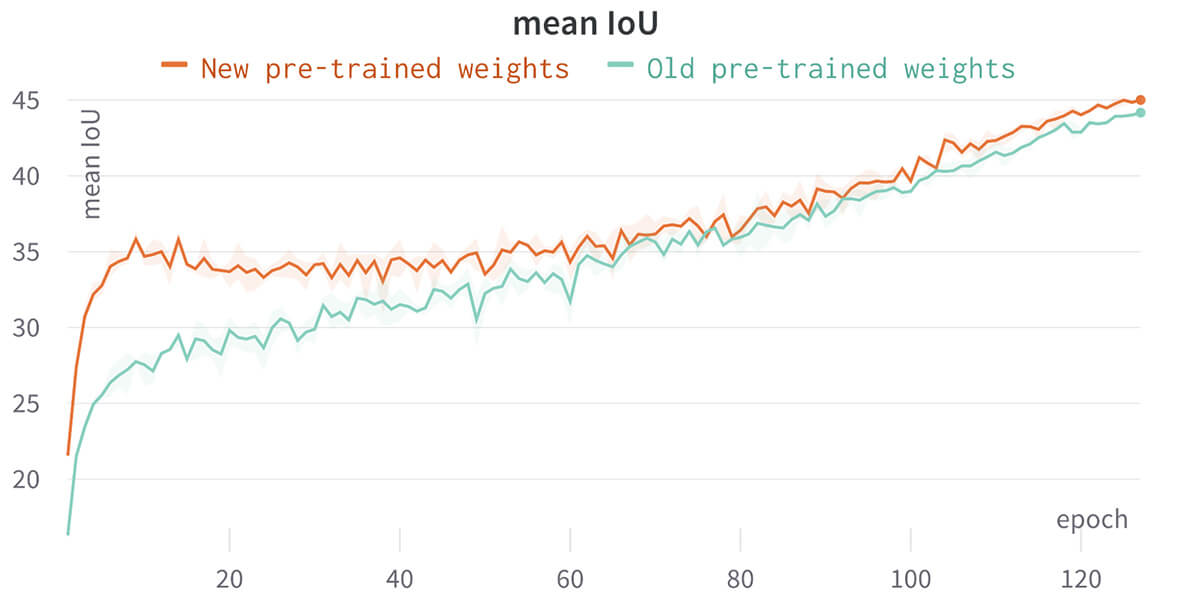
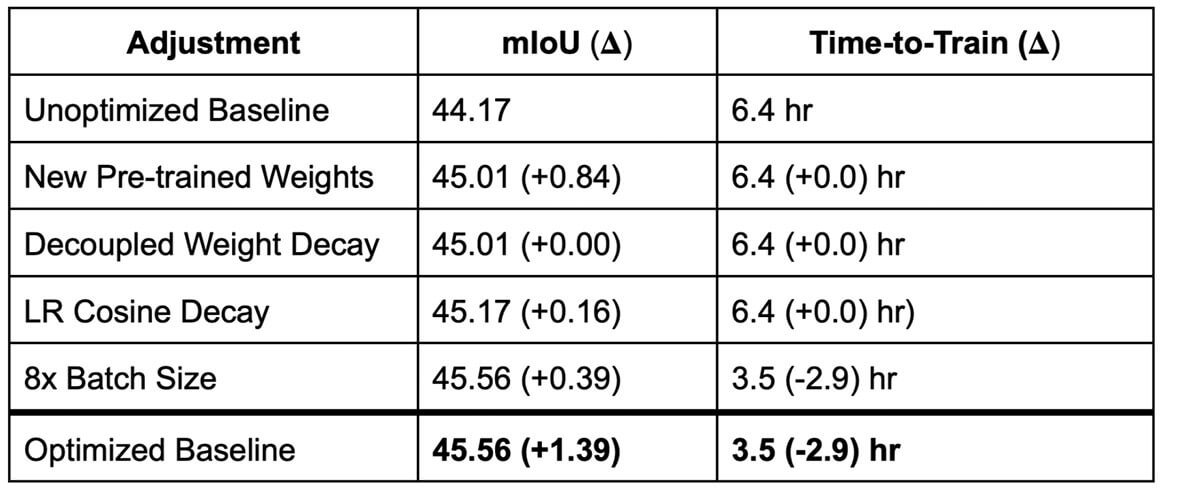
Several works have pushed ResNet accuracy on ImageNet using only algorithmic improvement to the training recipe. For example, PyTorch's recent ResNet-101 weights reach 81.886% accuracy on ImageNet while the previous weights reach 77.374% accuracy, a staggering 4.5% difference in accuracy. We test if these new ResNet-101 weights improve performance on ADE20k without any hyperparameter tuning as suggested in this paper. We find the new weights improve the final mIoU by 0.84, reaching 45.01 mIoU. We note the mIoU peaks early in training, then slightly degrades, and finally increases again. We suspect this training curve may indicate suboptimal hyperparameters when using the new pre-trained weights.
Step 2: Decoupling learning rate and weight decay
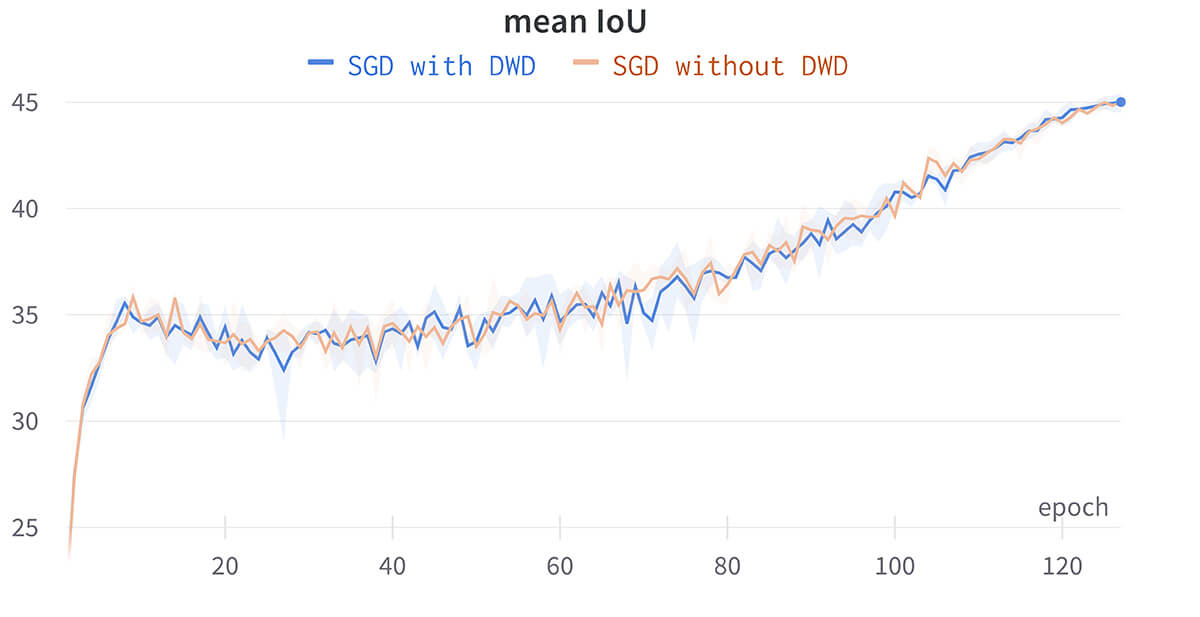
We swap the standard PyTorch stochastic gradient descent (SGD) optimizer for an optimizer with decoupled weight decay (DWD). DWD removes an explicit dependency between learning rate and weight decay hyperparameters. Without DWD, changing the learning rate will also change the effective weight decay which adds an unnecessary dependency when changing either hyperparameter. When switching to DWD, the original weight decay value needs to be scaled by LR / (1 - momentum) to have a similar effective weight decay. We find that DWD has minimal impact on performance, but could make future hyperparameter changes easier.
Step 3: Cosine decay learning rate schedule
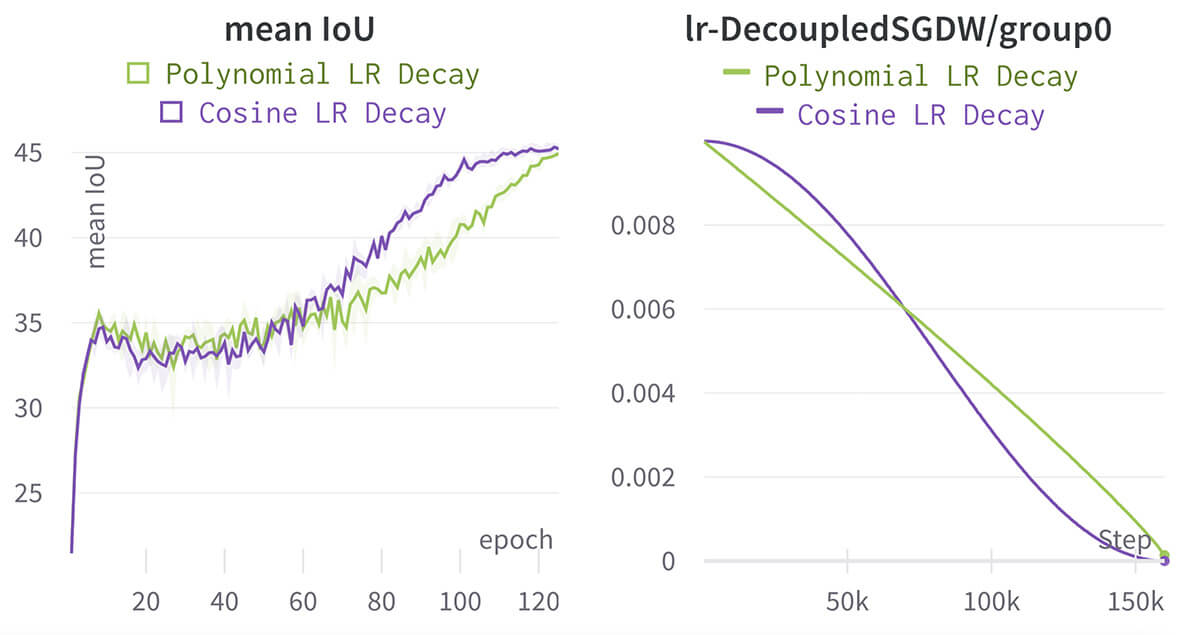
The original DeepLabv3+ paper recommends using a polynomial learning rate schedule with a power of 0.9. We test using a cosine decay schedule instead, due to its ubiquity and the fact that it will simplify configuration by eliminating the power hyperparameter. We find that the cosine decay increases mIoU by 0.18 and almost cuts the standard deviation in half, but the difference is within the noise of multiple seeds.
Step 4: Increase batch size
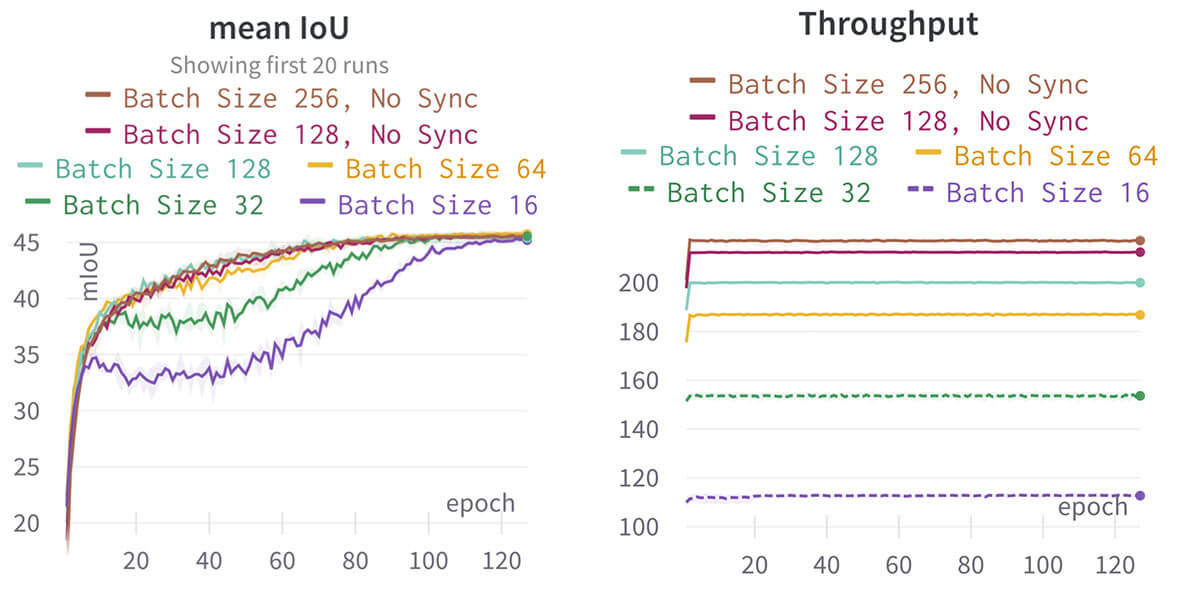
Most training recipes for ADE20k use a batch size of 16 and train for 160k iterations. Given a system with sufficient parallelization, a larger batch size will reduce time-to-train since the additional computation can be performed, at least partially, in parallel. Additionally, when training on an 8 GPU system with a sufficiently small batch size, models with batch normalization must sync batch statistics across GPUs, since a small per-GPU batch size can lead to performance degradation. Synchronized batch normalization decreases throughput by 15% for DeepLabv3+ with a batch size of 16 on a 8xA100 system. Increasing the batch size should allow us to remove the sync batch normalization requirement, improving throughput.
We incrementally double the batch size and learning rate until we hit a decrease in mIoU at a batch size of 128 samples. One potential reason for the decreased mIoU is the reduced regularization from batch normalization with larger batch sizes. Now that the batch size is 128, we remove the sync batch normalization to increase regularization and find that the mIoU is increased by 0.2 while the throughput is increased by 5%. Increasing the batch size from 128 to 256 seems to have similar performance at 127 epochs, but the performance is more sensitive to the number of training epochs than batch size 128. As a result, we settle on batch size 128 with no batch normalization sync, which results in 1.8x faster training, and +0.37 mIoU, as compared to the baseline.
Results Summary
For this baseline, we train the DeepLabv3+ model architecture on the ADE20k dataset and evaluate the model’s performance using its scene parsing benchmark. In particular, we update the previous DeepLabv3+ baseline by using the improved PyTorch pre-trained weights and increasing the batch size for additional computational efficiency. By the end, we demonstrate a DeepLabv3+ baseline on ADE20k with +1.4 mean intersection-over-union and a 1.8x faster training time than previously published baselines.
In the table below, we summarize the improvements to the performance of DeepLabv3+ on ADE20k that we achieve with the four changes we apply. With Composer, we have additively applied all of these modifications; each result in the table lists the change in mIoU score and time-to-train relative to its immediate predecessor. In every case, the numbers are an average of three seeds:
Conclusion
We use the steps outlined above to set a new semantic segmentation baseline of achieving 45.56 mIoU on the ADE20k segmentation benchmark in 3.5 hours, but it is important to remember that setting this baseline is just the beginning of the journey. This new baseline will be useful in two specific ways. First, it is important for comparing the speedup of future training recipes on the DeepLabv3+ architecture. Second, thinking past DeepLabv3+ alone, this baseline is particularly valuable when comparing semantic segmentation backbones, because the core metrics – mIoU and wall clock time – are agnostic to the model architecture. We consider wall-clock time to be a centrally important metric for efficiency – please see our Methodology blog post for details about this choice.
Beyond semantic segmentation (and CV in general), we will also be seeking out strong baselines for other domains. In the coming weeks and months, stay tuned to find out more about how we establish baselines for language models, and look to push the efficiency frontiers for those tasks.
And, in the meantime, we invite you to download Composer and try it out for your training tasks. As you try it out, come be a part of our community by engaging with us on Twitter, joining our Slack community or just giving us a star on Github.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.