Welcome to the Haunted Lakehouse
by Sathish Gangichetty and Allison Baker
Halloween is easily one of my favorite holidays – costumes, horror films, candy eating, elaborate decorations – what’s not to love? At Databricks, Halloween is also a big season for our customers. Whether it’s seasonal specials at coffee shops, costumes from retailers, or scary content on streaming platforms (we even did an analysis on horror movies last year), customers use Lakehouse for many strategic use cases across BI, predictive analytics, and streaming.
This inspired me to ask myself: How can we use Databricks to boost our Halloween spirit? In this blog post, I’ll walk through how I built the “Haunted Lakehouse” game, completely powered by open source standards and Databricks, so you can see the amazing possibilities that exist within a lakehouse!
Enter the Haunted Lakehouse
The inspiration for the game is the massive, often daunting, amount of data that organizations must tackle to bring their AI strategies to life. Imagine a monster on the Lakehouse, representing your data, that could be tamed to do things you want it to do. This, in many ways, is what driving AI use cases feels like and is the basis of the game – a hungry monster in the Lakehouse that needs to be fed so it can do what you ask!
The premise: a monster named Lakehmon, short for Lakehouse Monster (and not inspired by pokemon at all), finally escaped the clutches of the warehouse it was locked in for years and is now on the loose in the Databricks Lakehouse. Our task as the user is to get the monster happy and fed so Lakehmon works for us using AI, to recommend movies and costumes.
In the demo below, you can see this concept brought to life:
How Was Lakehmon Built
At the heart of what makes Lakehmon execute these two AI tasks are foundational Databricks Lakehouse Platform capabilities:
- The ability to support the end-to-end machine learning lifecycle, from data engineering to model development to model management and deployment.
- The ability to serve the production models as serverless REST endpoints via Databricks Serverless Real-Time Inference.
Starting with the back end, as we piece together different technologies that enable a capable backend, all of the following Databricks components come into play:
- Notebooks to explore and transform the data and machine learning runtimes for processing embeddings from unstructured text data.
- Experiment and model lifecycle management capabilities, as well as the ability to train, version, track, log and register model runs.
- The ability to generate serverless model endpoints to deliver fast, elastic and scalable real time model interactions.
Typically, in a production setting, everything mentioned above is done with workflows, on a schedule in an automated, seamless manner. Out of the box, Databricks delivers a diverse set of capabilities, complete with governance and observability. In turn, it delivers a significant jump in developer productivity and optimizes workflows while literally delivering the best bang for your buck.
For delivering the frontend, we used the cross-platform open source framework Flutter and the Dart programming language. For the back-end, we use a FastAPI server to enable the frontend to send API requests and, in-turn, send traffic to the appropriate Databricks Serverless Real-Time Inference endpoints. Lakehmon animation and the state changes across all of the monster’s emotions were made possible by tapping into Rive animations and manipulating the state machines there-in. Putting together all of these individual pieces, our technical architecture for this demo app, looks as follows:
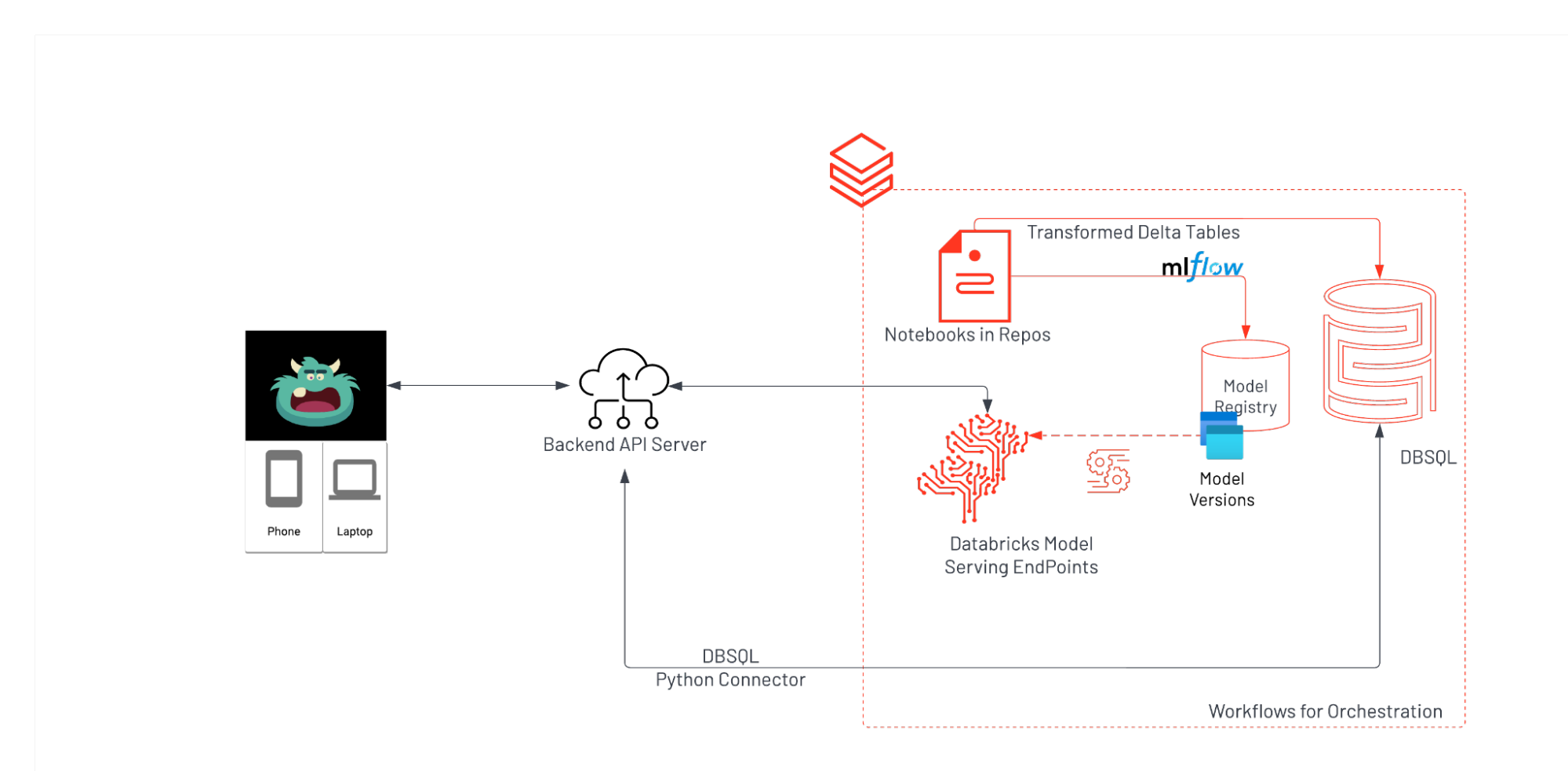
Intelligence at Scale
Databricks enables us to generate the intelligence needed for the application. For this specific demo, we leveraged the sentence-transformers python library to apply a transformer model. This generated embeddings used for horror movie and Halloween costume recommendations. For the uninitiated, embeddings are a way to extract latent semantic meaning from unstructured data.
Thinking beyond our Halloween application, we can apply this exact pattern to other business-critical use cases, including:
- Detecting anomalous events
- Improving product searches based on text and images
- Propping up existing models with contextual unstructured data (such as products purchased or the content of the reviews made on a specific product, etc)
- Driving marketing applications like product recommendations, product affinity predictions, or click/visit predictions based on impressions
Basically, the opportunities with Lakehouse are tremendous. To fulfill the promise of these possibilities, data scientists and data engineers need access to cloud-first Lakehouse platforms that are open, simple and collaborative in addition to supporting unstructured data where legacy warehouses struggle.
In short, when using a proprietary warehouse-first method, organizations lose the ability to operate quickly as state of the art changes. And due to a lack of capability or functions, they’re forced to adopt a disparate technology landscape fraught with vendor risk, as opposed to choosing the best of breed, as is the case with lakehouse vendors like via Databricks Partner Connect.
In addition, product teams need the ability to serve models developed by machine learning engineers in a quick, observable and a cost-efficient manner. Data warehouses fall flat in this area and must outsource this vital function. Conversely, the Databricks Lakehouse Platform supports the entire model lifecycle and, via serverless model serving capabilities, allows users to quickly serve models as REST endpoints. This is how Lakehmon generates recommendations for movies or costumes.
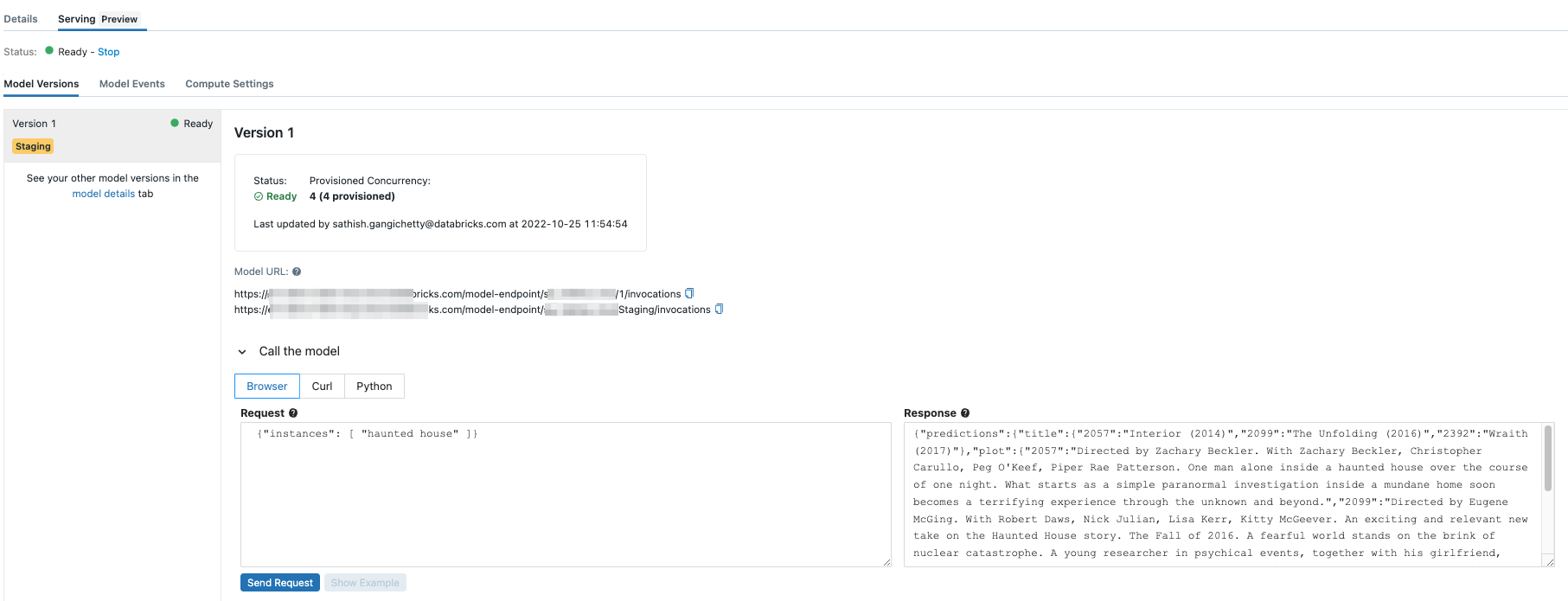
Databricks also automatically captures and provides all the operational metrics around latency, concurrency, RPS, etc. for all the models served. To learn more about Databricks Serverless Serving, please see here.
Closing Thoughts
A fun halloween project like Lakehmon is a reminder that we should always choose our data platforms carefully, especially when focused on future capabilities. Today, most innovation flows from open source ecosystems, so those open standards must be supported as a first class citizen across all data engineering, data science and machine learning. While we only explored a small unstructured data set here, we highlighted how none of this is possible within the confines of a data warehouse, especially when you throw in data pre-processing, code revision management, model tracking, versioning, management and serving. Luckily, the Lakehouse tackles the biggest limitations of data warehouses...and so much more! Interested in giving it a try? See the full Repo here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.