Data Warehouse

What is a data warehouse?
A data warehouse is a data management system that stores current and historical data from multiple sources in a business-friendly manner for easier insights and reporting. Data warehouses are typically used for business intelligence (BI), analytics, reporting, data applications, preparing data for machine learning (ML) and data analysis.
Data warehouses make it possible to quickly and easily analyze business data uploaded from operational systems such as point-of-sale systems, inventory management systems, or marketing or sales databases. Data may pass through an operational data store and require data cleansing to ensure data quality before it can be used in the data warehouse for reporting.
Here’s more to explore


What are data warehouses used for?
Data warehouses are used in BI, analytics, reporting, data applications, preparing data for machine learning, and data analysis to extract and summarize data from operational databases. Information that is difficult to analyze directly from transactional databases can be analyzed via data warehouses — for example, if management wants to know the total revenues generated by each salesperson on a monthly basis for each product category. Transactional databases may not capture this data, but the data warehouse does.
What are the types of data warehouses?
- Traditional data warehouse: This type of data warehouse stores only structured data. The structure of a data warehouse enables users to quickly and easily access data for reporting and analytics.
- Intelligent data warehouse: This is a modern type of data warehouse that is built on a lakehouse architecture and that has an intelligent and automatically optimizing platform. An intelligent data warehouse not only provides access to AI and ML models but also uses AI to assist with queries, dashboard creation, and performance and sizing optimization.
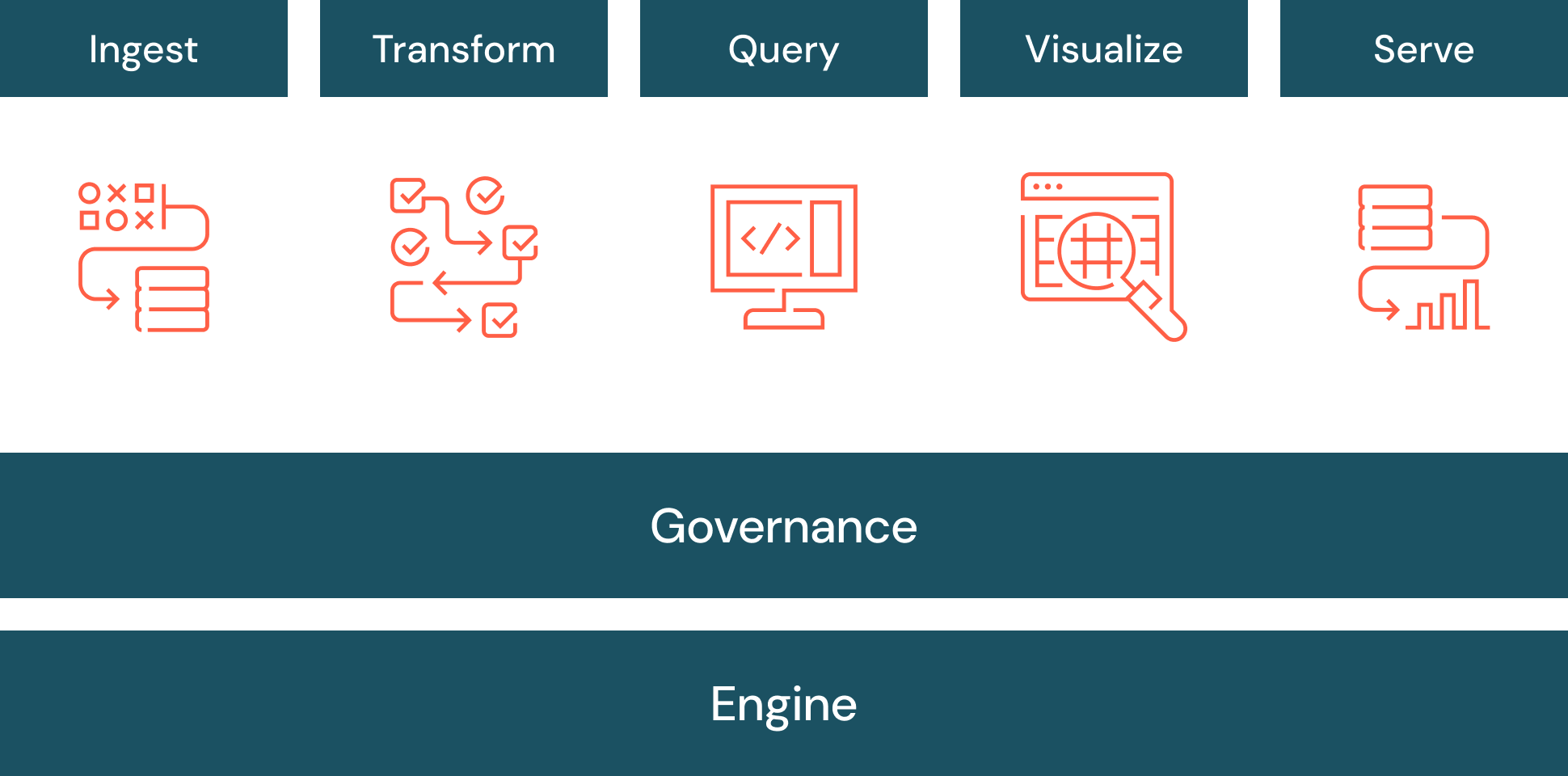
Data warehouse architecture
A common model for data warehousing architecture is multitiered. This architecture was created by Bill Inmon, the computer scientist often considered the father of the data warehouse.
Bottom tier
The bottom tier of a data warehouse architecture is comprised of data sources and data storage. This tier includes data access methods, like APIs, gateways, ODBC, JDBC and OLE-DB. Data ingestion or ETL is also included in the bottom tier.
Middle tier
The middle tier of a data warehouse architecture is comprised of an OLAP server, which is either relational (ROLAP) or multidimensional (MOLAP). These two types can be combined into a hybrid OLAP (HOLAP).
Top tier
The top tier of a data warehouse architecture is comprised of the front-end clients for querying, BI, dashboarding, reporting and analysis.
What are the three variations of a data warehouse?
- Enterprise data warehouse (EDW): A centralized data warehouse that is used by many different teams in an organization. It is often the single source of truth for BI, analytics and reporting.
- Operational data store (ODS): A type of data warehouse that focuses on the latest operational or transactional data.
- Data mart: A simplified version of the data warehouse that serves a single line of business (LOB) or a single project. A data mart is smaller than an EDW, but the number of data marts typically grows as an organization grows, and LOBs want to self-service.
Data lake vs. database vs. data warehouse
What is the difference between a data lake and a data warehouse?
Data lakes and data warehouses are two different approaches to managing and storing data.
A data lake is an unstructured or semi-structured data repository that allows for the storage of vast amounts of raw data in its original format. Data lakes are designed to ingest and store all types of data — structured, semi-structured or unstructured — without any predefined schema. Data is often stored in its native format and is not cleansed, transformed or integrated, making it easier to store and access large amounts of data.
A traditional data warehouse, on the other hand, is a structured repository that stores data from various sources in a well-organized manner, with the aim of providing a single source of truth for business intelligence and analytics. Data is cleansed, transformed and integrated into a schema that is optimized for querying and analysis.
An intelligent data warehouse, which uses the lakehouse architecture, also provides a single source of truth for business intelligence and analytics. It extends a traditional data warehouse by storing structured, semi-structured or unstructured data. Data management capabilities like data quality and threshold alerts are included.
What is the difference between a data warehouse and a database?
A database is a collection of structured data, extending beyond text and numbers to images, videos and more. Many refer to this database management system by its acronym: DBMS. A DBMS is the storage system for data that feeds applications and analytics.
A traditional data warehouse, on the other hand, is a structured repository that provides data for business intelligence and analytics. Data is cleansed, transformed and integrated into a schema that is optimized for querying and analysis, including adding common aggregations.
What is the difference between a data lake, a data warehouse and a data lakehouse?
A data lakehouse is a hybrid approach that combines the best of both worlds. It is a modern data architecture that integrates the capabilities of a traditional data warehouse and a data lake in a unified platform. It allows for the storage of raw data in its original format like a data lake while also providing data processing and analytics capabilities like a data warehouse.
In summary, the main difference between a data lake, a traditional data warehouse and a data lakehouse is their approach to managing and storing data. A traditional data warehouse stores structured data in a predefined schema, a data lake stores raw data in its original format, and a data lakehouse is a hybrid approach that combines the capabilities of both.
Data lake | Data lakehouse | Traditional data warehouse | |
|---|---|---|---|
Types of data | All types: structured data, semi-structured data, unstructured (raw) data | All types: structured data, semi-structured data, unstructured (raw) data | Structured data only |
Cost | $ | $ | $$$ |
Format | Open format | Open format | Closed, proprietary format |
Scalability | Scales to hold any amount of data at low cost, regardless of type | Scales to hold any amount of data at low cost, regardless of type | Scaling up becomes exponentially more expensive due to vendor costs |
Intended users | Limited: data scientists | Unified: data analysts, data scientists, machine learning engineers | Limited: data analysts |
Reliability | Low quality, data swamp | High quality, reliable data | High quality, reliable data |
Ease of use | Difficult: Exploring large amounts of raw data can be difficult without tools to organize and catalog the data | Simple: Provides simplicity and the structure of a data warehouse with the broader use cases of a data lake | Simple: Structure of a data warehouse enables users to quickly and easily access data for reporting and analytics |
Performance | Poor | High | High |
Can a data lake replace a data warehouse?
Not really. A data lake and a data warehouse are two different approaches to managing and storing data, each with its own strengths and weaknesses. While a data lake can complement a data warehouse by providing raw data for advanced analytics, it cannot in its traditional sense fully replace a data warehouse. Instead, a data lake and a data warehouse can complement each other, with the data lake serving as a source of raw data for advanced analytics, and the data warehouse providing a structured, organized and trustworthy source of business data for reporting and analysis.
A data lake is foundational for a data lakehouse, which can replace a traditional data warehouse, with reliability and performance on open data formats such as Delta Lake and Apache Iceberg™.
Can a data lakehouse replace a traditional data warehouse?
Yes. A data lakehouse is a modern data architecture that combines the benefits of a data warehouse and a data lake into a unified platform. A data lakehouse is built on an open data lake and can serve as a replacement for a traditional data warehouse because it provides the capabilities of both a data lake and a data warehouse in a single platform.
A data lakehouse allows for the storage of raw data in its original format like a data lake while also providing data processing and analytics capabilities like a data warehouse. It also provides a schema-on-read approach, which allows for flexibility in data processing and querying. The combination of a data lake and a data warehouse in a single platform provides increased flexibility, scalability and cost-effectiveness.
What is a modern data warehouse?
Data warehousing continues to evolve. A modern data warehouse is also known as an intelligent data warehouse because it uses newer technologies like AI. An intelligent data warehouse leverages the open data lakehouse architecture instead of the traditional data warehouse architecture. An intelligent data warehouse understands the uniqueness of your data and auto-optimizes the platform to scale for low latency and high concurrency. An intelligent data warehouse also needs unified governance for security, controls and workflow. An intelligent data warehouse uses AI to generate queries, correct mistakes, suggest visualizations and more.
What is ETL in a data warehouse?
A data warehouse requires data. That data must be loaded into the data warehouse (or referenced, with a concept called lakehouse federation). The process of extracting data from source systems, transforming the data and then loading the data into the data warehouse is called ETL (extract, transform, load). ETL is typically used for integrating structured data from multiple sources into a predefined schema.
Query federation is a style of ETL that is used to run queries against data sources from multiple sources and across multiple clouds. You can view and query all the data from one place without needing to migrate all data to a unified system. Sometimes this concept is called data virtualization, too.
What is a dimension in a data warehouse?
A data warehouse dimension is used to describe the data with structured labeling information. A dimension uses the information to filter, group and label. For example, a dimension could be business entities such as a customer or product.
What is a fact in a data warehouse?
A data warehouse fact is used to quantify the data with numbers. For example, a fact could be customer orders or financial data.
What is dimensional modeling in a data warehouse?
Dimensional modeling is a data warehousing technique that organizes data into dimensions and facts. Dimension modeling identifies important business process and then models the data warehouse to support those business processes.
What is a star schema in a data warehouse?
A star schema is a multidimensional data model used to organize data in a database so that it is easy to understand and analyze. Star schemas can be applied to data warehouses, databases, data marts and other tools. The star schema design is optimized for querying large datasets.
Introduced by Ralph Kimball in the 1990s, star schemas are efficient at storing data, maintaining history and updating data by reducing the duplication of repetitive business definitions, making it fast to aggregate and filter data in the data warehouse.
What data warehouse benefits can businesses expect?
- The consolidation of data obtained from many sources. A data warehouse can become a single point of access for all data, rather than requiring users to connect to dozens or even hundreds of individual data stores.
- Historical intelligence. A data warehouse integrates data from many sources to show historical trends.
- Separate analytics processing from transactional databases, improving the performance of both systems
- Data quality, consistency and accuracy. A well-formed data warehouse uses a standard set of semantics around data, including consistency in naming conventions, codes for various product types, languages, currencies, and so on.
- Anyone can discover answers from the data, including users without SQL expertise
Challenges with data warehouses
No matter the type of data warehouse that you use, challenges remain:
- Disjointed tools across data and AI assets create a fragmented approach, which compromises data governance
- Users need specialized skills and training to write queries, understand data structures, find and connect to the best data sources, and so on
- As data warehouses grow, they slow down — and in the cloud, that gets expensive quickly with cloud compute costs
Scalability and performance
With growing data volumes, a lakehouse architecture distributes computing features, independent of storage, aiming to maintain consistent performance at optimal costs. You need a platform that is designed for elasticity, allowing organizations to scale their data operations as needed. Scalability extends across various dimensions:
- Serverless: The platform should enable workloads to adjust and scale elastically based on the required computing capacity. Such dynamic resource allocation guarantees rapid data processing and analysis, even during peak demand.
- Concurrency: The platform should leverage serverless compute and AI-driven optimizations to facilitate concurrent data processing and query execution. This ensures that multiple users and teams can undertake analytics tasks concurrently without performance constraints.
- Storage: The platform should seamlessly integrate with data lakes, facilitating the cost-effective storage of extensive data volumes while ensuring data availability and reliability. It should also optimize data storage for enhanced performance, reducing storage expenses.
Scalability, though essential, is complemented by performance. The platform should use a variety of AI-driven optimizations to optimize performance:
- Optimized query: The platform should use machine learning optimization techniques to accelerate query execution. It leverages automatic indexing, caching and predicate pushdown to ensure queries are processed efficiently, resulting in rapid insights.
- Autoscaling: The platform should intelligently scale serverless resources to match your workloads, ensuring that you pay only for the compute you use, all while maintaining optimal query performance.
- Fast query performance: The platform should provide extremely fast query performance at low cost — from data ingestion, ETL, streaming, data science and interactive queries — directly on your data lake.
- Delta Lake: The platform should use AI models to solve common challenges with data storage so you get faster performance without having to manually manage tables, even as they change over time.
- Predictive optimization: This automatically optimizes your data for the best performance and price. It learns from your data usage patterns, builds a plan for the right optimizations to perform and then runs those optimizations on hyper-optimized serverless infrastructure.
Challenges with traditional data warehouses
Traditional data warehouses have an additional set of challenges:
- Limited to no support for unstructured data like images, text, IoT data, or messaging frameworks like HL7, JSON and XML. Traditional data warehouses are only capable of storing clean and highly structured data, even though Gartner estimates that up to 80% of an organization’s data is unstructured. Organizations that want to use their unstructured data to unlock the power of AI have to look elsewhere.
- No support for AI and machine learning: Data warehouses are purpose-built and optimized for common data warehouse workloads, including historical reporting, BI and querying — they were never designed for or intended to support machine learning workloads.
- SQL only: Data warehouses typically offer no support for Python or R, the languages of choice for app developers, data scientists and machine learning engineers.
- Duplicated data: Many enterprises have data warehouses and subject-area or (departmental) data marts in addition to a data lake, which results in duplicated data, lots of redundant ETL and no single source of truth.
- Tough to keep in sync: Keeping two copies of the data synchronized between the lake and the warehouse adds complexity and fragility that is tough to manage. Data drift can cause inconsistent reporting and faulty analysis.
- Closed, proprietary formats increase vendor lock-in: Most enterprise data warehouses use their own proprietary data format rather than formats based on open source and open standards. This increases vendor lock-in, makes it difficult or impossible to analyze your data with other tools and makes it more difficult to migrate your data.
- Expensive: Commercial data warehouses charge you for storing your data, and also for analyzing it. Storage and compute costs are therefore still tightly coupled together. Separation of compute and storage with a lakehouse means you can independently scale either as needed.
- Separate reporting solutions: Many times you need to ask simple questions of your data without the full features of a separate reporting solution — such as, “What is the sales revenue for Q3?”
- Table format lock-in: You need flexibility across lines of business and use cases, but data warehouses sometimes lock you in to a particular table format (for example, Apache Iceberg).
Proprietary table formats
The table format is the primary technology that brings the advantages of data warehouses to data lakes. Table formats organize data and metadata in a way that represents the state of a table over time.
Proprietary table formats are typically used in cloud environments, where efficient access to large datasets is crucial for tasks like analytics, reporting and machine learning. Specific vendors will create file formats or structures to address specific issues, such as reducing storage size, reducing read/writer speeds or adding version control.
Databricks’ proprietary format, Delta Lake, is an open source, open format data management and governance layer that combines the best of both data lakes and data warehouses. Some of the key features include:
- ACID transactions: Delta Lake enables consistent data even while running concurrent operations like updates, deletes and insertions. This ensures your data is always up to date and consistent.
- Scalable metadata: As datasets grow, Delta Lake scales with it and allows users to store metadata in tables. This results in data changes that are easier to track and share.
- Schema enforcement: Delta Lake ensures that all of your data adheres to a specific format in a table.
- Compatibility with Apache Spark™: Since Delta Lake is open source, it is compatible with Apache Spark APIs. You can use Delta Lake in your existing Spark applications without modifying your code.
To avoid open table format (OTF) lock-in, or having to choose between Delta Lake and Apache Iceberg, you can use a universal format like Delta Lake UniForm.
Multicloud
Your organization may have data spread across two or more cloud providers to optimize costs or to fit the particular needs of your dataset. This can create problems if data is managed on different networks and with different schema for storing data.
A modern lakehouse architecture can manage data across multiple cloud service providers instead of being tied to a single cloud system. This allows your organization to:
- Distribute data: With data across different cloud platforms, your business can find the collection of services that best work with your budget or compliance concerns.
- Enhance resilience: Multicloud environments improve data availability by spreading workloads and backups across several providers. This can be crucial if any one cloud service experiences an outage or unexpected downtime.
- Data integration: A data warehouse that supports multicloud can also integrate data from across these sources in real time, giving you access to quality data and better decisions.
- Compliance: Multicloud architecture can help you meet specific legal and regulatory requirements that may dictate where your data is stored geographically, or how it is stored across multiple cloud services.
Challenges with intelligent data warehouses
Intelligent data warehouses have a different set of challenges:
- This modern approach is still evolving, so you need an organization willing to evolve their strategy
- AI policies: Your organization should set policies governing which people and systems should be able to use the AI features in an intelligent data warehouse
What solutions does Databricks have for data warehousing?
Databricks provides an intelligent data warehouse, Databricks Lakehouse, which is built on the open data lakehouse architecture. Databricks Lakehouse is part of an integrated platform, the Data Intelligence Platform, that includes ML, data governance, workflows and more. By using an open, unified foundation for all your data, you get ML/AI, streaming, orchestration, ETL and real-time analytics, data warehousing, unified security, governance and cataloging, as well as unified data storage for reliability and sharing in the same platform. In addition, because the Databricks Data Intelligence Platform is built on an open data lakehouse architecture, you can store all raw data like logs, texts, audio, video and images.
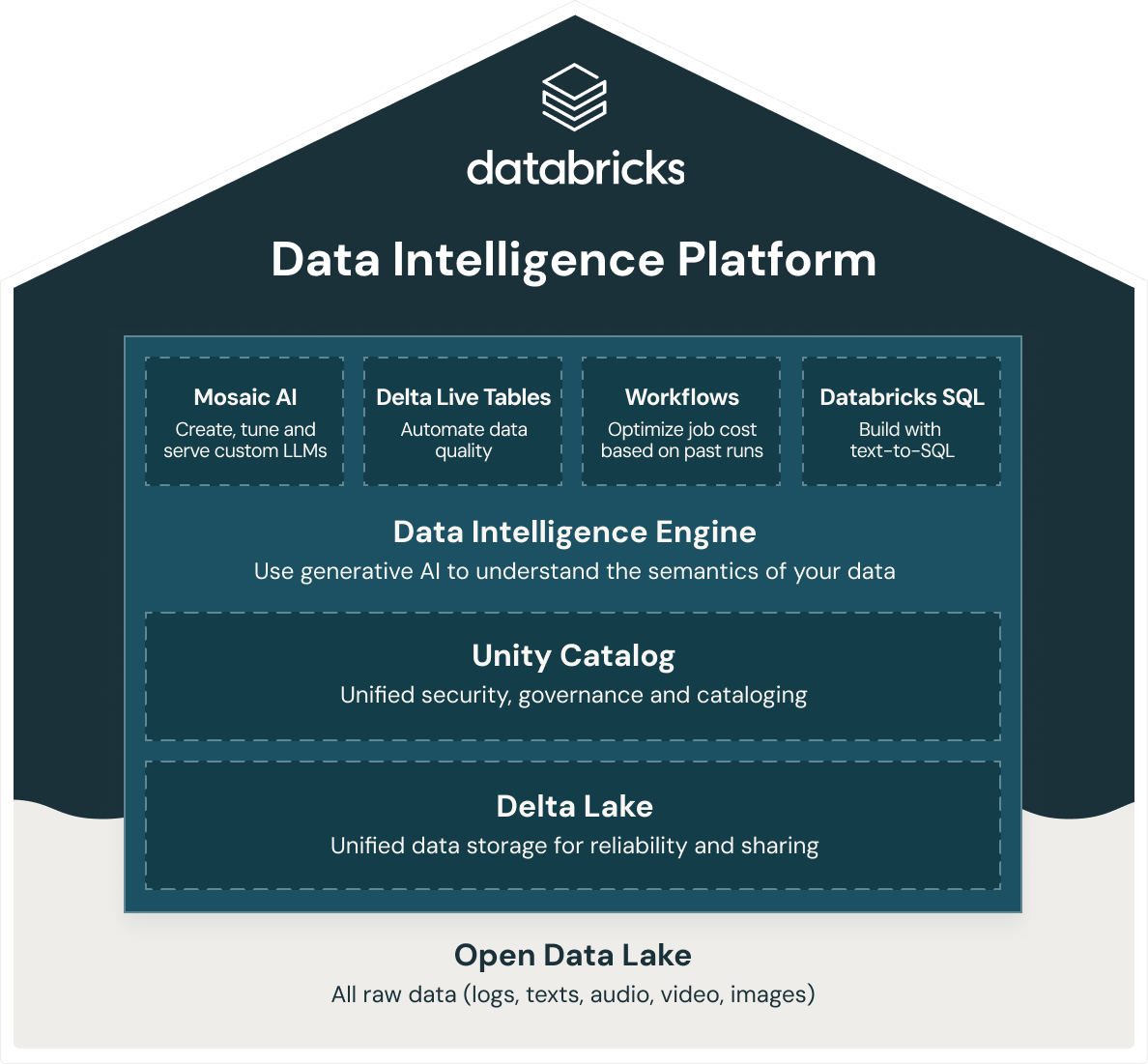
To build a successful lakehouse, organizations have turned to Delta Lake, an open source, open format data management and governance layer that combines the best of both data lakes and data warehouses. The Databricks Data Intelligence Platform uses Delta Lake to give you:
- World-record data warehouse performance at data lake economics
- Serverless SQL compute that eliminates the need for infrastructure management
- Seamless integration with the modern data stack, like dbt, Tableau, Power BI and Fivetran to ingest, query and transform data in place
- A first-class SQL development experience for every data practitioner across your organization with ANSI-SQL support
- Fine-grained governance with data lineage, table/row-level tags, role-based access controls and more
- AI-powered data intelligence engine to understand the semantics of your data