What is LLMOps?
Practices and tools for developing, deploying, and managing LLMs in production, addressing fine-tuning, prompt engineering, evaluation, and AI governance
- LLMOps extends MLOps practices to large language models so organizations can build, deploy and manage LLM powered applications in a reliable, governed way.
- LLMOps focuses on areas like data pipelines, evaluation, prompt and configuration management, cost control and monitoring to keep LLM applications accurate, safe and efficient.
- The Databricks Data Intelligence Platform supports LLMOps with capabilities such as vector search, evaluation tooling and governance integrated into the lakehouse.

What Is LLMOps?
Large Language Model Ops (LLMOps) encompasses the practices, techniques and tools used for the operational management of large language models in production environments.
The latest advances in LLMs, underscored by releases such as OpenAI’s GPT, Google’s Bard and Databricks’ Dolly, are driving significant growth in enterprises building and deploying LLMs. That has led to the need to build best practices in how to operationalize these models. LLMOps allows for the efficient deployment, monitoring and maintenance of large language models. LLMOps, like traditional Machine Learning Ops (MLOps), requires a collaboration of data scientists, DevOps engineers and IT professionals. You can learn how to build your own LLM with us here.
Large language models (LLMs) are a new class of natural language processing (NLP) models that have leaped far ahead of the previous state of the art at a range of tasks, from open question-answering to summarization to following near-arbitrary instructions. The operational requirements of MLOps typically apply to LLMOps as well, but there are challenges with training and deploying LLMs that require a unique approach to LLMOps.

How is LLMOps different from MLOps?
For the purpose of adjusting MLOps practices, we need to consider how machine learning (ML) workflows and requirements change with LLMs. Key considerations include:
- Computational resources: Training and fine-tuning large language models typically involves performing orders of magnitude more calculations on large data sets. To speed this process up, specialized hardware like GPUs is used for much faster data-parallel operations. Having access to these specialized compute resources becomes essential for both training and deploying large language models. The cost of inference can also make model compression and distillation techniques important.
- Transfer learning: Unlike many traditional ML models that are created or trained from scratch, many large language models start from a foundation model and are fine-tuned with new data to improve performance in a more specific domain. Fine-tuning allows state-of-the-art performance for specific applications using less data and fewer compute resources.
- Human feedback: One of the major improvements in training large language models has come through reinforcement learning from human feedback (RLHF). More generally, since LLM tasks are often very open ended, human feedback from your application’s end users is often critical for evaluating LLM performance. Integrating this feedback loop within your LLMOps pipelines both simplifies evaluation and provides data for future fine-tuning of your LLM.
- Hyperparameter tuning: In classical ML, hyperparameter tuning often centers on improving accuracy or other metrics. For LLMs, tuning also becomes important for reducing the cost and computational power requirements of training and inference. For example, tweaking batch sizes and learning rates can dramatically change the speed and cost of training. Thus, both classical ML models and LLMs benefit from tracking and optimizing the tuning process, but with different emphases.
- Performance metrics: Traditional ML models have very clearly defined performance metrics, such as accuracy, AUC, F1 score, etc. These metrics are fairly straightforward to calculate. When it comes to evaluating LLMs, however, a whole different set of standard metrics and scoring apply — such as bilingual evaluation understudy (BLEU) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE), which require some extra consideration when implementing.
- Prompt engineering: Instruction-following models can take complex prompts, or sets of instructions. Engineering these prompt templates is critical for getting accurate, reliable responses from LLMs. Prompt engineering can reduce the risk of model hallucination and prompt hacking, including prompt injection, leaking of sensitive data and jailbreaking.
- Building LLM chains or pipelines: LLM pipelines, built using tools like LangChain or LlamaIndex, string together multiple LLM calls and/or calls to external systems such as vector databases or web search. These pipelines allow LLMs to be used for complex tasks such as knowledge base Q&A, or answering user questions based on a set of documents. LLM application development often focuses on building these pipelines, rather than building new LLMs.
Why do we need LLMOps?
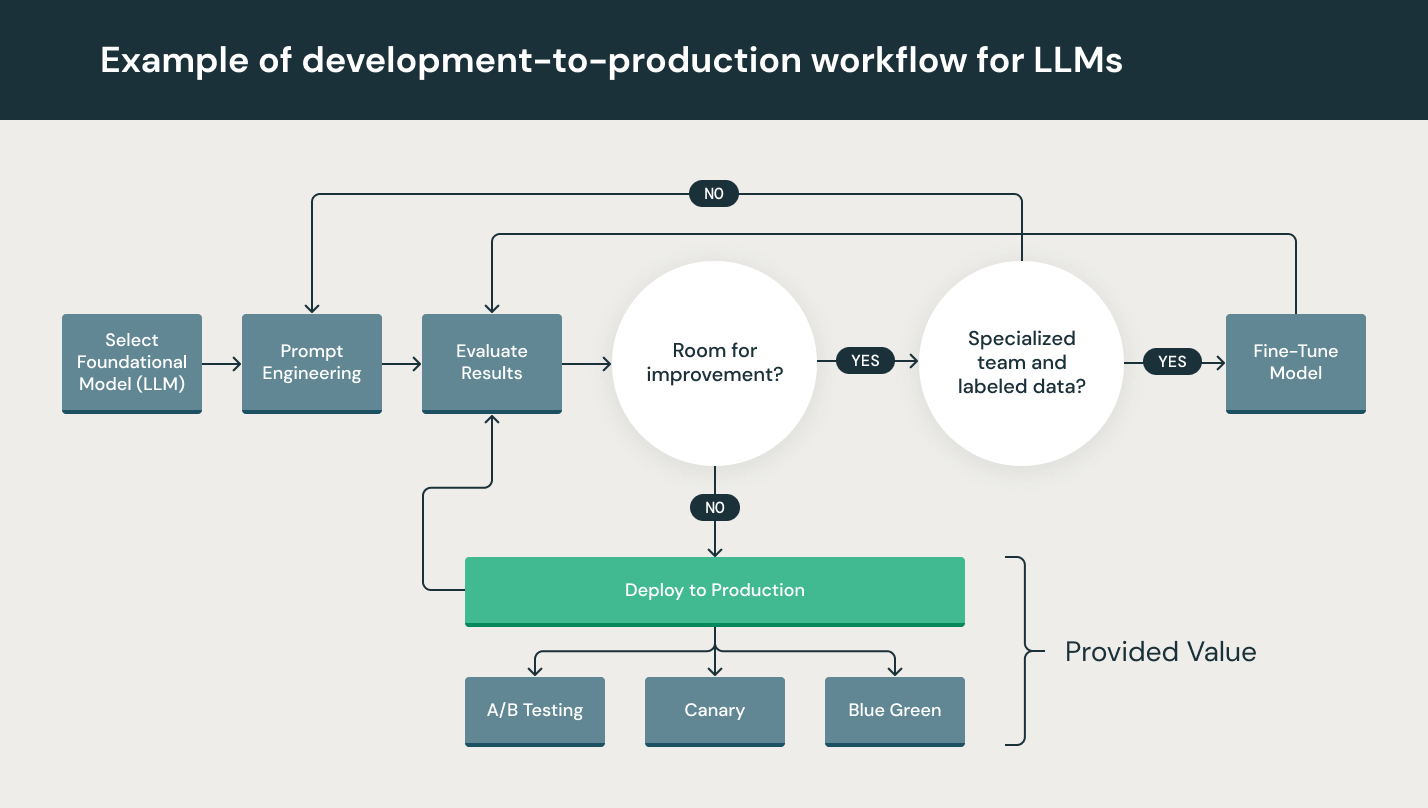
Although LLMs are particularly simple to use in prototyping, using an LLM within a commercial product still presents challenges. The LLM development lifecycle consists of many complex components such as data ingestion, data prep, prompt engineering, model fine-tuning, model deployment, model monitoring, and much more. It also requires collaboration and handoffs across teams, from data engineering to data science to ML engineering. It requires stringent operational rigor to keep all these processes synchronous and working together. LLMOps encompasses the experimentation, iteration, deployment and continuous improvement of the LLM development lifecycle.
What are the benefits of LLMOps?
The primary benefits of LLMOps are efficiency, scalability and risk reduction.
- Efficiency: LLMOps allows data teams to achieve faster model and pipeline development, deliver higher-quality models, and deploy to production faster.
- Scalability: LLMOps also enables vast scalability and management where thousands of models can be overseen, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment. Specifically, LLMOps provides reproducibility of LLM pipelines, enabling more tightly coupled collaboration across data teams, reducing conflict with DevOps and IT, and accelerating release velocity.
- Risk reduction: LLMs often need regulatory scrutiny, and LLMOps enables greater transparency and faster response to such requests and ensures greater compliance with an organization’s or industry’s policies.
The agentic AI playbook for the enterprise

What are the components of LLMOps?
The span of LLMOps in machine learning projects can be as focused or expansive as the project demands. In certain cases, LLMOps can encompass everything from data preparation to pipeline production, while other projects may require implementation of only the model deployment process. A majority of enterprises deploy LLMOps principles across the following:
- Exploratory data analysis (EDA)
- Data prep and prompt engineering
- Model fine-tuning
- Model review and governance
- Model inference and serving
- Model monitoring with human feedback
What are the best practices for LLMOps?
The best practices for LLMOps can be delineated by the stage at which LLMOps principles are being applied.
- Exploratory data analysis (EDA): Iteratively explore, share, and prep data for the machine learning lifecycle by creating reproducible, editable, and shareable data sets, tables, and visualizations.
- Data prep and prompt engineering: Iteratively transform, aggregate, and de-duplicate data, and make the data visible and shareable across data teams. Iteratively develop prompts for structured, reliable queries to LLMs.
- Model fine-tuning: Use popular open source libraries such as Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow and JAX to fine-tune and improve model performance.
- Model review and governance: Track model and pipeline lineage and versions, and manage those artifacts and transitions through their lifecycle. Discover, share and collaborate across ML models with the help of an open source MLOps platform such as MLflow.
- Model inference and serving: Manage the frequency of model refresh, inference request times and similar production specifics in testing and QA. Use CI/CD tools such as repos and orchestrators (borrowing DevOps principles) to automate the preproduction pipeline. Enable REST API model endpoints, with GPU acceleration.
- Model monitoring with human feedback: Create model and data monitoring pipelines with alerts both for model drift and for malicious user behavior.
What is an LLMOps platform?
An LLMOps platform provides data scientists and software engineers with a collaborative environment that facilitates iterative data exploration, real-time coworking capabilities for experiment tracking, prompt engineering, and model and pipeline management, as well as controlled model transitioning, deployment, and monitoring for LLMs. LLMOps automates the operational, synchronization and monitoring aspects of the machine learning lifecycle.
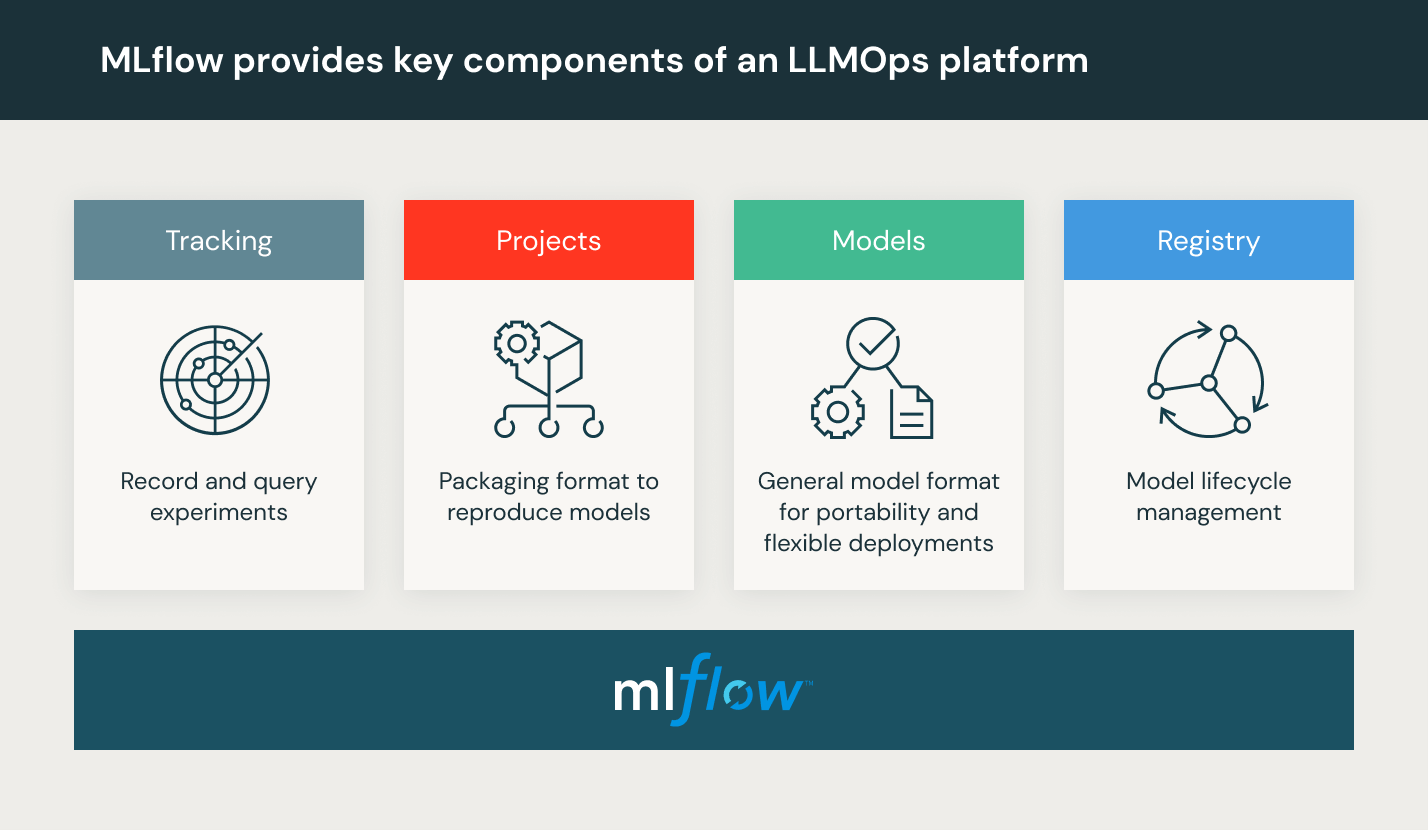
Databricks provides a fully managed environment including MLflow — the world’s leading open MLOps Platform. Try Databricks Machine Learning
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.