Building High-Quality and Trusted Data Products with Databricks
by Amr Ali, Bernhard Walter, Fran Medina Castro, Glenn Wiebe, Karthik Subbarao, Lexy Kassan, Magnus Pierre and Pawarit Laosunthara
Introduction
Organizations aiming to become AI and data-driven often need to provide their internal teams with high-quality and trusted data products. Building such data products ensures that organizations establish standards and a trustworthy foundation of business truth for their data and AI objectives. One approach for putting quality and usability at the forefront is through the use of the data mesh paradigm to democratize the ownership and management of data assets. Our blog posts (Part 1, Part 2) offer guidance on how customers can leverage Databricks in their enterprise to address data mesh's foundational pillars, one of which is "data as a product".
Though the idea of treating data as products may have gained popularity with the emergence of data mesh, we have observed that applying product thinking resonates even with customers who haven't chosen to embrace data mesh. Regardless of organizational structure or data architecture, data-driven decision-making remains a universal guiding principle. Data quality and usability are paramount to ensure these data-driven decisions are made on valid information. This blog will outline some of our recommendations for building enterprise-ready data products, both generally and specifically with Databricks.
Data products ultimately deliver value when users and applications have the right data at the right time, with the right quality, in the right format. While this value has traditionally been realized in the form of more efficient operations through lower costs, faster processes and mitigated risks, modern data products can also pave the way for new value-adding offerings and data sharing opportunities within an organization's industry or partner ecosystem.
Data Products
While data products can be defined in various ways, they typically align with the definition found in DJ Patil's Data Jujitsu: The Art of Turning Data into Product: "To start, ..., a good definition of a data product is a product that facilitates an end goal through the use of data". As such, data products are not restricted to tabular data; they can also be ML models, dashboards, etc. To apply such product thinking to data, it is strongly recommended that each data product should have a data product owner.
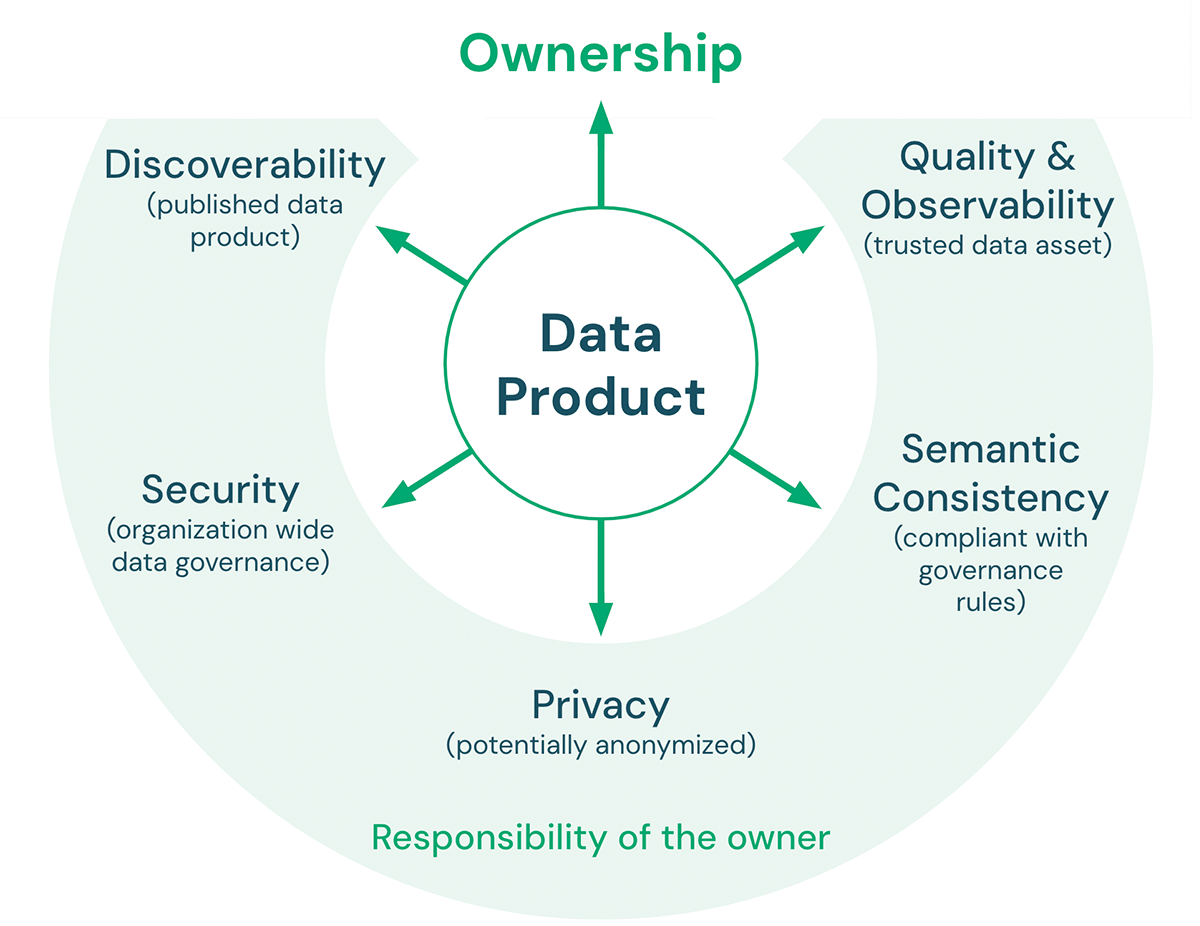
Data product owners manage the development and monitor the use and performance of their data products. To do so, they must understand the underlying business and be able to translate the requirements of data consumers into a design for a high-quality, easy-to-use data product. Together with others in the organization, they bridge the gap between business and technical colleagues like data engineers. The data product owner is accountable for ensuring that the products in their portfolio align with organizational standards across characteristics of trustworthiness.
There are five key characteristics that a data product must meet:
- Quality and Observability: Data quality includes accuracy, consistency, reliability, timeliness, as well as clarity of documentation. Defined quality metrics about the data product can be monitored and exposed to ensure that the expected data quality is maintained over time. The overall goal is to make the data product a trusted source for data consumers.
- Semantic consistency: The goal of a lakehouse architecture is to make working with data easy. Therefore, data products that are meant to be used together should be semantically consistent. In other words, they should follow the agreed governance rules and have shared definitions of terminology in order for consumers to combine these data products in a meaningful and correct way.
- Privacy: Privacy is about the confidentiality and security of information, concerning how data is collected, shared, and used. Data privacy is typically governed by regulations and laws (e.g. GDPR, CCPA). Complying with data privacy rules can include topics such as anonymization, encryption, data residency, data tagging (e.g. PII), limiting storage to specific environments, and minimizing access to a small number of employees.
- Security: In addition to having an infosec-approved data platform in place, data product owners still need to define, for example, access permissions (who can access the data, which partners can the data be shared with, etc.) and acceptable use policies for their data products.
- Discoverability: Data products need to be published in a way that everyone in the organization can find them. This can include places such as a central data catalog or an internal data marketplace. Data product owners should include assets with the published product that make it easy to understand the data and how to combine it with other data products (e.g. sample notebooks, dashboards, etc.).
Data Product Lifecycle
A typical data product lifecycle consists of the following phases:
- Inception - This is where business value for a desired data product is defined and an owner is assigned. Performance and quality metrics should also be defined for monitoring purposes.
- Design - In this phase, concrete details such as the design specification and data contracts are created, ensuring consistency with other data products.
- Creation - Creating the actual data product can include schemas, tables, views, models, arbitrary files (volumes), dashboards, etc., along with the pipelines that create them. This phase also includes testing the resulting data product against the defined data contract.
- Publish - The creation and publishing of a data product are often treated as the same but they are quite different. This phase includes activities such as the deployment of models, publishing a schema to a shared catalog, managing the access permissions as per the data contract, etc. Publishing should involve release management to version changes to published data products.
- Operate and Govern - Operations involve persistent activities like monitoring the quality, permissions, and usage metrics. The governance part includes handling compliance-related requests and auditing data product access etc.
- Consume and Value Creation - The data product is used in the business to solve a variety of problems. Consumers may provide feedback to the data product owner based on their experience of using the product and recommend enhancements that could facilitate further value creation in the future.
- Retirement - There can be several reasons to retire a data product, such as a lack of usage, the data product being no longer compliant, etc. In any case, the data product should be gracefully retired. This means deprecating the product, informing the consumers, archiving assets, and cleaning up resources. Here, visibility over downstream usage will often be important and is significantly eased if lineage is automatically captured.
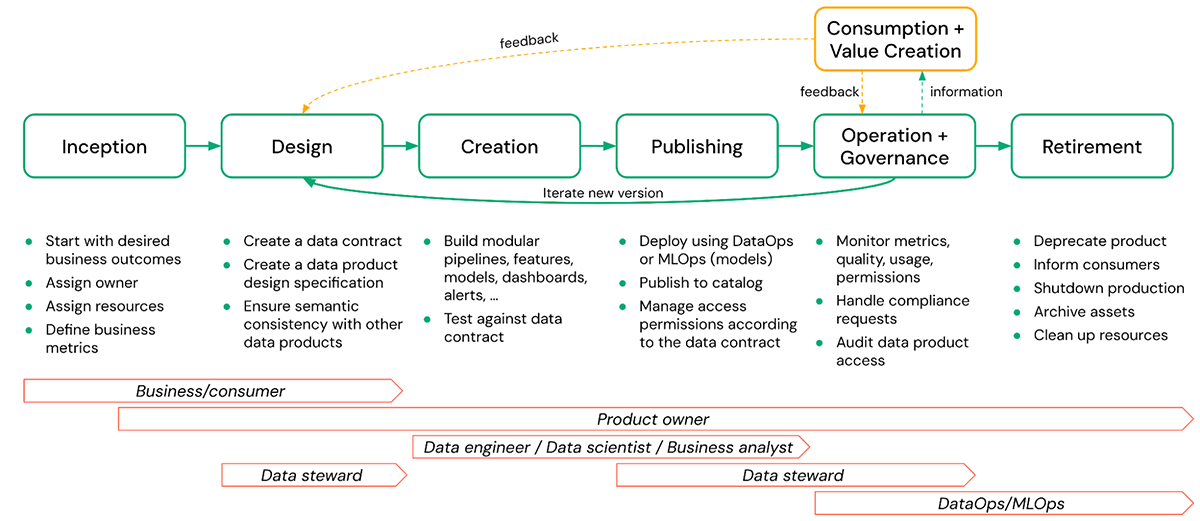
In the figure above, the data product owner is accountable for all of the phases, beginning from the inception until the retirement of a data product. Nevertheless, the responsibility for individual tasks can be shared with other stakeholders such as data stewards, data engineers, etc.
Best practices for data product implementation
Implementing high-quality data products with Databricks requires a thoughtful approach beyond just technical execution. Start by establishing clear ownership, with dedicated data product owners who understand both business needs and technical requirements. Define comprehensive data contracts upfront that include quality metrics, schema definitions, usage policies and security parameters to ensure alignment between producers and consumers.
When building pipelines, utilize Delta Live Tables (DLT) with quality controls implemented directly in your code, leveraging built-in expectations and constraints to validate data at each stage. Implement a staged development approach with separate development, testing and production environments to ensure quality before publication. Automate monitoring using Lakehouse Monitoring, setting up alerts for quality metric thresholds to catch issues early.
Document extensively within Unity Catalog, using both technical specifications and business context to help users understand and correctly utilize your data products. For governance efficiency, standardize naming conventions and metadata across data products to improve discoverability and interoperability. Finally, implement a formal feedback loop with consumers to continuously improve your data products based on actual usage patterns and user needs.
The Databricks Data Intelligence Platform can be leveraged for several of the activities involved in the data product lifecycle:
- ETL Pipelines - Delta Live Tables (DLT) can be employed to build robust and quality-controlled data pipelines. Auto Loader and streaming tables can be used to incrementally land data into the Bronze layer for DLT pipelines or Databricks SQL queries.
- Governance - Databricks Unity Catalog is feature-rich and built to enable simple and unified governance across an enterprise. Catalog Explorer can be used for data discovery and access control mechanisms facilitate publishing the data products to the intended consumers. Lineage and System Tables are automatically tracked and vital to operational governance.
- Monitoring - Lakehouse Monitoring provides a single and unified solution for monitoring the quality of data and AI assets. Such a proactive approach is necessary to satisfy the data contract terms.
For some of the data product lifecycle activities, such as designing the data product and data contract, Databricks does not currently have features to support it. These processes should be done outside of the Databricks Platform and the results then be documented in Unity Catalog once the data product has been published.
Data Contracts
A data contract is a formal way to align the domains and implement federated governance. The data producer should provide it; however, it should be designed with the consumer in mind. The contract should be framed in a way that is consumable by all types of users.
A typical data contract has the following attributes
- Data description (name, description, source systems, attribute selection, …)
- Data schema (tables, columns, anonymization and encryption info, filter, masks, …) and data formats (semi-structured and unstructured data)
- Usage policies (tags, PII, guidelines, data residency, …)
- Data quality (applied quality checks and constraints, quality metrics, …)
- Security (who is allowed to use the data product)
- Data SLAs (last update, expiration dates, retention time, …)
- Responsibilities (owner, maintainer, escalation contact, change process, …)
In addition, supporting assets such as notebooks, dashboards, etc. can be provided in order to help the consumer understand and analyze the data product, thus facilitating easier adoption.
Data Governance Team
A data governance team in an enterprise usually consists of representatives from different groups such as business owners, compliance and security experts, and data professionals. This team should act as Center of Excellence (CoE) for compliance and data security topics and support the data product owner who is accountable for the data product. They play a crucial role in framing the data contract by extending the usage policies as well as influencing the decision of who is allowed to use the data product. For large organizations, such a team can help with steering and standardizing the data contract framing process in alignment with global functions such as a data management office.
Publishing and Certification
Despite established data contracts, the governance of data products remains a broad subject, encompassing aspects such as access controls, Personally Identifiable Information (PII) classification, and various usage policies, all of which can differ between organizations. However, one consistent trend we have observed concerns the publication of data products. As consumers encounter an increasing number of datasets, they often require assurance that the data is curated, standardized, and officially approved for use. For instance, a reporting or master data management use case within a large organization might necessitate a high degree of semantic consistency and interoperability between diverse data assets in the enterprise.
This is where the concept of data product 'certification' can become valuable for certain data products. In this process, data producers can first propose a data contract specification, typically subject to review by a data governance steward or team. Upon approval, Continuous Integration/Continuous Deployment (CI/CD) processes can be run to deploy production pipelines that physically write data to the customer's cloud storage accounts. This data can then be published and easily discovered through Unity Catalog tables, views, or even volumes for non-tabular data. In this context, Unity Catalog supports the use of tags as well as markdown to indicate the certification status and details of a data product.
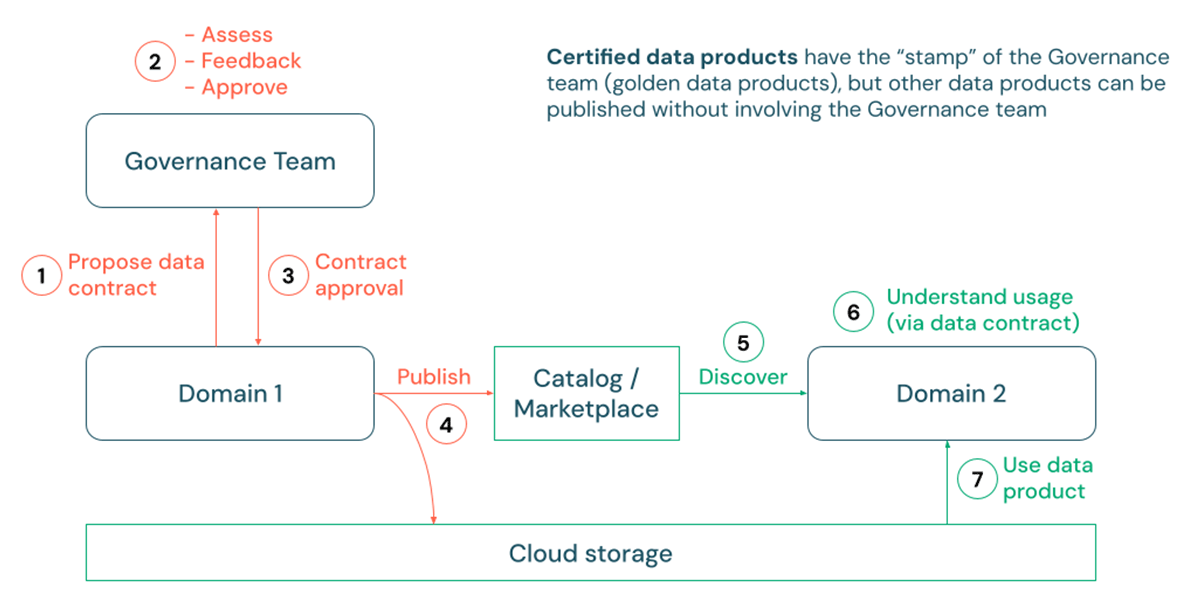
Some customers may even choose to promote their certified data products by publishing a corresponding private listing in the Databricks Marketplace with comprehensive guides and usage examples. Furthermore, Databricks' REST APIs and integrations with enterprise catalog solutions such as Alation, Atlan, and Collibra also facilitate the easy discoverability of certified data products through multiple channels, even those outside of Databricks.
Use Cases and Success Stories
Automotive: Rivian's Vehicle Intelligence Platform
Rivian, the electric vehicle manufacturer, utilizes Databricks to process IoT sensor data from over 25,000 vehicles on the road, each generating terabytes of data daily. Their advanced driver-assistance systems (ADAS) team uses this platform to analyze telemetric data including information about pitch, roll, speed, suspension and airbag activity, which helps Rivian understand vehicle performance and driving patterns. By leveraging the Databricks Lakehouse Platform, they've achieved a 30%-50% increase in runtime performance, leading to faster insights and improved model accuracy. This data-driven approach enables Rivian to implement predictive maintenance, optimize component reliability and continuously improve the customer driving experience.
Healthcare: Walgreens' Prescription Personalization
Walgreens, one of America's largest pharmacy chains, transformed its patient experience using Databricks to process prescription data at massive scale. With more than 825 million prescriptions filled annually across nearly 9,000 locations, Walgreens built their Information, Data and Insights (IDI) platform on Databricks to process 40,000 data events per second. This has optimized their supply chain by right-sizing inventory levels to save millions of dollars and increased pharmacist productivity by 20%. The platform enables pharmacists to provide better care with robust patient profiles that include drug interaction alerts, changes in drug profiles and other critical information for safer prescription management.
Manufacturing: Mahindra's AI-Powered Analytics
Mahindra & Mahindra Limited, a global manufacturing conglomerate, has implemented enterprise-level AI solutions using Databricks to enhance operations across their business. Their GenAI bot for financial analysts has led to a 70% reduction in time spent on routine tasks, enabling teams to focus on higher-value strategic initiatives. The company is leveraging the Databricks Data Intelligence Platform for multiple use cases, including a Voice of the Customer chatbot built with the Databricks DBRX open source LLM that integrates both internal data via Delta Lake and external data from websites and social media. This comprehensive approach is helping Mahindra drive growth, enhance customer experiences and optimize operational efficiency.
Telecommunications: T-Mobile's Data Mesh Architecture
T-Mobile has successfully implemented a data mesh architecture using Databricks to democratize data access while maintaining security and governance. The telecommunications giant integrated its lakehouse into a Data Mesh using Unity Catalog and Delta Sharing, enabling teams across the enterprise to access and utilize data while maintaining a rational and easily understood security model. This approach has empowered domain teams to create and manage their own data products while ensuring consistent governance, accelerating analytics initiatives across the organization and improving data-driven decision making.
Future Trends in Data Products
The future of data products is being shaped by several emerging trends that will impact how organizations leverage platforms like Databricks. Real-time data products are gaining prominence as businesses require increasingly current insights, with streaming architectures becoming standard for critical operational data products. We’re also seeing the rise of self-service data product creation, with business domain experts using low-code/no-code interfaces to define and build data products while maintaining governance guardrails.
AI-enriched data products that automatically incorporate machine learning features and insights are becoming more common, blurring the line between traditional data and AI assets. Data mesh architectures are maturing, with organizations implementing federated computational governance that balances central standards with domain autonomy. Cross-organizational data products that safely span enterprise boundaries are emerging, with data clean rooms and privacy-preserving computation enabling new collaborative insights.
Data contracts are evolving to include more sophisticated quality guarantees, privacy controls and usage rights, becoming executable specifications rather than static documentation. Embedded analytics within operational applications is growing, with data products designed specifically to power in-app insights rather than separate analytical environments. Finally, sustainably metrics are being incorporated into data products, tracking environmental impact alongside traditional business KPIs to support ESG reporting and green initiatives.
Conclusion
Formulating data products and data contracts can become intricate exercises within a large enterprise setting. Given the emergence of new technologies for interfacing with data, coupled with modern business and regulatory requirements, specifications for data products and contracts are continuously evolving. Today, Databricks Marketplace and Unity Catalog serve as core components for the data discovery and onboarding experience for data consumers. For data producers, Unity Catalog offers essential enterprise governance functionality including lineage, auditing, and access controls.
As data products extend beyond simple tables or dashboards to encompass AI models, streams, and more, customers can benefit from a unified and consistent governance experience on Databricks for all major user personas.
The key aspects of enterprise data products highlighted in this blog can serve as guiding principles as you approach the topic. To learn more about constructing high-quality data products using the Databricks Data Intelligence Platform, reach out to your Databricks representative.
FAQ
What is the difference between a data product and a regular dataset?
A data product goes beyond just providing data; it's designed with specific user needs in mind, includes quality guarantees, documentation and support elements. Unlike a regular dataset, a data product has clear ownership, defined SLAs and is actively managed throughout its lifecycle to ensure it continues to meet consumer needs.
Who should own data products in our organization?
Data products should be owned by individuals who understand both the business domain and technical aspects of the data. These data product owners are accountable for quality, usability and alignment with business goals. Depending on your organizational structure, they might sit within business domains (in a data mesh approach) or within a central data team.
How do we measure the success of our data products?
Success metrics should include both technical aspects (quality, availability, performance) and business impact measures. Track usage patterns, user satisfaction, time-to-insight for consumers and direct business outcomes enabled by the data product. Establish baseline metrics before implementation and measure improvements over time.
What role does Unity Catalog play in managing data products?
Unity Catalog serves as the foundation for governance of data products by providing centralized metadata management, access controls, lineage tracking and discovery capabilities. It enables you to implement data contracts through features like tagging, comments and schema definitions, while providing auditability and compliance controls necessary for enterprise data products.
How do we handle changes to published data products?
Implement formal versioning and change management processes for data products. Communicate changes to consumers in advance, maintain backward compatibility where possible and provide migration paths for breaking changes. Use Unity Catalog's features to track versions and manage the transition between them.
Can we create data products without adopting a full data mesh architecture?
Absolutely. While data mesh emphasizes domain ownership of data products, you can apply product thinking to your data assets regardless of your organizational structure. Focus on user needs, quality and usability of your data and implement clear ownership and governance — these principles create value even without a complete data mesh implementation.
How do we ensure our data products remain compliant with evolving regulations?
Build compliance into your data product lifecycle, with regular reviews by your governance team. Implement metadata-driven controls in Unity Catalog to enforce policies automatically, and use lineage features to understand the impact of regulatory changes on your data products. Document compliance requirements in your data contracts and monitor adherence through audit logs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.