Integration of AWS Data Pipeline with Databricks: Building ETL pipelines with Apache Spark
This is one of a series of blogs on integrating Databricks with commonly used software packages. See the “What’s Next” section at the end to read others in the series, which includes how-tos for AWS Lambda, Kinesis, Airflow and more.
Databricks is a fully managed Apache Spark data platform in the cloud, built to make real-time data exploration and deploying production jobs easy for data engineers, data scientists, or anyone interested in using Spark for data processing.
AWS Data Pipeline is a web service that helps reliably process and move data between different AWS compute and storage services at specified intervals. AWS Data Pipeline helps users to easily create complex data processing workloads that are fault tolerant, repeatable, and highly available.
Databricks is natively deployed to our users’ AWS VPC and is compatible with every tool in the AWS ecosystem. In this blog, I will demonstrate how to build an ETL pipeline using Databricks and AWS Data Pipeline.
How to use Data Pipeline with Databricks
The Databricks REST API enables programmatic access to Databricks instead of going through the Web UI. It can automatically create and run jobs, productionalize a workflow, and much more. It also allows us to integrate Data Pipeline with Databricks, by triggering an action based on events in other AWS services.
Using AWS Data Pipeline, you can create a pipeline by defining:
The “data sources” that contain your data. To ensure that data is available prior to the execution of an activity, AWS Data Pipeline allows you to optionally create data availability checks called preconditions. These checks will repeatedly attempt to verify data availability and will block any dependent activities from executing until the preconditions succeed.
The “activities” or business logic such as launching a Databricks job. One can use the AWS Data Pipeline object ShellCommandActivity to call a Linux curl command to trigger a REST API call to Databricks.
The “schedule” on which your business logic executes. In the case of scheduling a start time in the past, Data Pipeline backfills the tasks. It also allows you to maximize the efficiency of resources by supporting different schedule periods for a resource and an associated activity. For example by reusing the same resources if the scheduling period permits.
Below is an example of setting up a Data Pipeline to process log files on a regular basis using Databricks. AWS Data Pipeline is used to orchestrate this pipeline by detecting when daily files are ready for processing and setting a “precondition” for detecting the output of the daily job and sending a final email notification.
Log Processing Example
Setup the data pipeline:
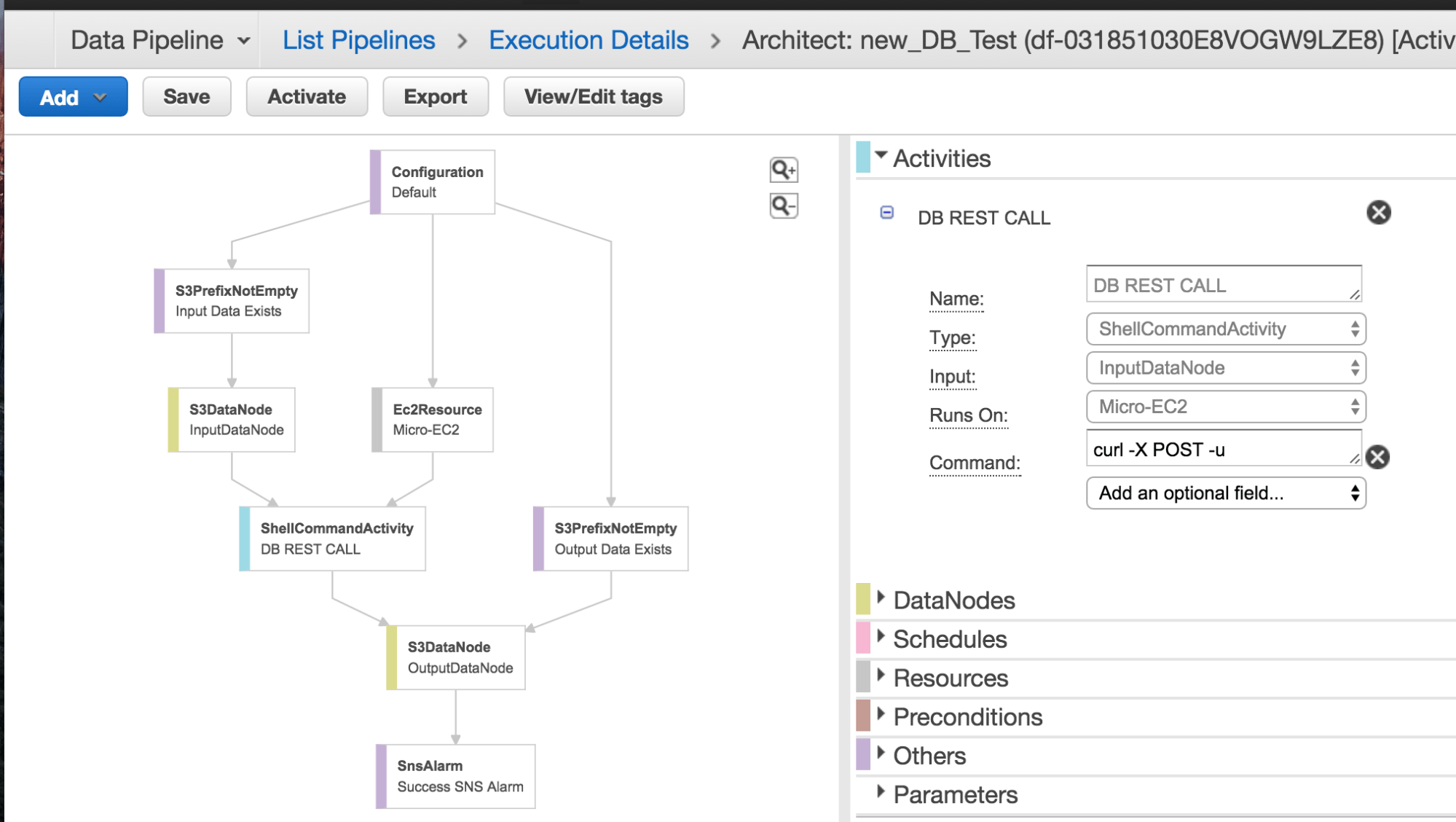
Figure 1: ETL automation: 1) Data lands in S3 from Web servers, InputDataNode, 2) An event is triggered and a call is made to the Databricks via the ShellCommandActivity 3) Databricks processes the log files and writes out Parquet data, OutputDataNode, 4) An SNS notification is sent once as the results of the previous step.
This pipeline has several steps:
1. Input Precondition
Check that the input data exists:
2. Input Data Node
Configure the input as the source for the next step which is the shell script for calling the REST API.
3. Invoke Databricks REST API
Invoke the ShellCommandActivity operator to call the Databricks REST API with the file input and output arguments (For the purposes of illustrating the point in this blog, we use the command below; for your workloads, there are many ways to maintain security):
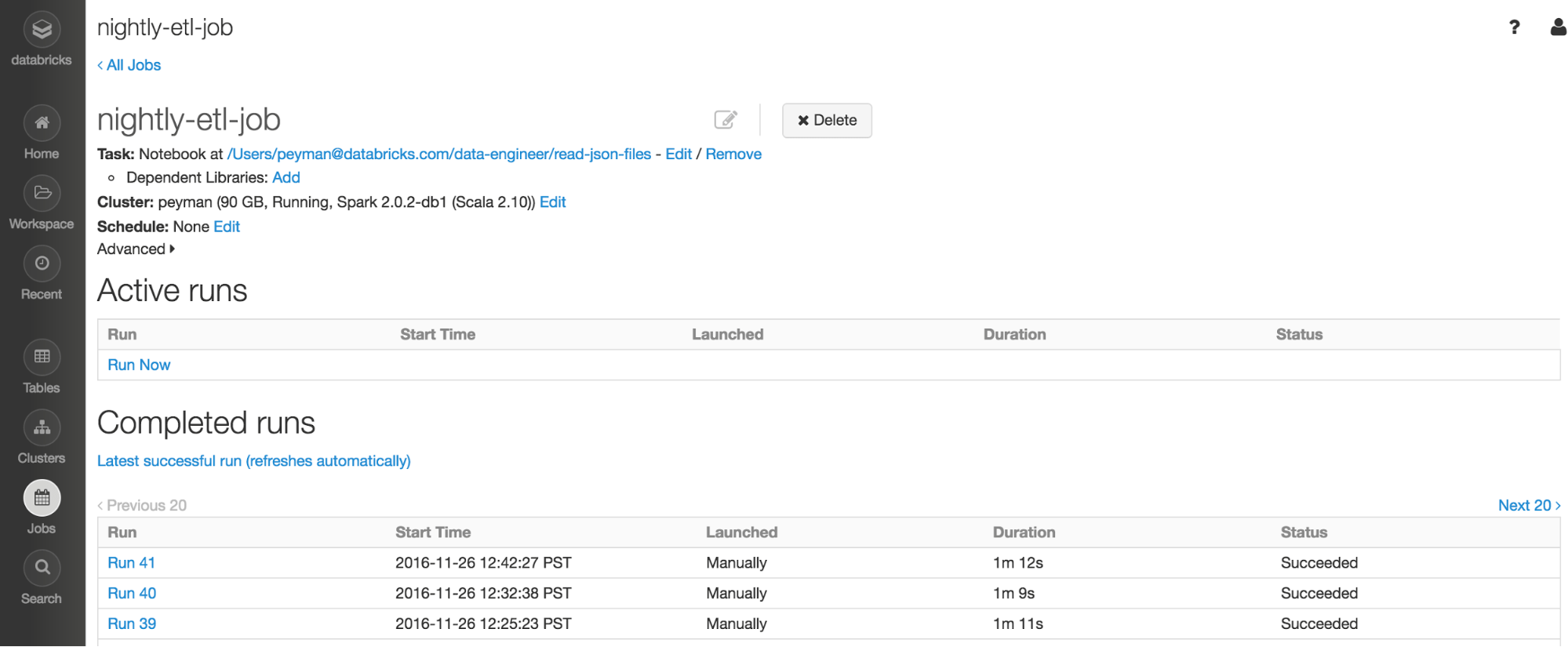
Figure 2: A screenshot of the job within Databricks that is getting called. Note that this job is not scheduled within Databricks, it is getting triggered by Data Pipeline.
4. Databricks Action
Databricks Action involves reading an input log file, creating a schema and converting it into Parquet:
5. Output Precondition
Check that the output data exists:
6. Send Amazon SNS Alarm
As the final step, send out an Amazon SNS alarm when the job is successful. You can subscribe to SNS messages in a variety of ways, e.g. email or text notification push.
What’s Next
We hope this simple example shows how you can use Amazon Data Pipeline and the Databricks API to solve your data processing problems. Data Pipeline integrates with a variety of storage layers in AWS and using ShellCommandActivity it can integrate with the Databricks REST API and parameter arguments can be passed to Databricks’ notebooks or libraries dynamically. To try Databricks, sign-up for a free trial or contact us.
Read other blogs in the series to learn how to integrate Databricks with your existing architecture:
- Integrating Apache Airflow and Databricks
- Oil and Gas Asset Optimization with AWS Kinesis, RDS, and Databricks
- Using AWS Lambda with Databricks for ETL Automation and ML Model Serving
References
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.