Enterprise Cloud Service Public Preview on AWS
by Vinay Wagh and Abhinav Garg
At Databricks, we have had the opportunity to collaborate with companies that have transformed the way people live. Some of our customers have developed life saving drugs, delivered industry-first user experiences, as well as provided edge-of-the-seat entertainment (so needed during shelter in place). These companies transformed their business by building efficiencies in how they operate, delivering delightful customer experiences, and innovating new products and features; all by building a data practice that enables all their engineers, scientists & analysts with the data they need to deliver positive business outcomes.
Our experience shows us that at the core of such a data driven enterprise is a data platform that can support all of their data projects and users globally. So far few companies have had the resources and expertise to build such platforms & capabilities and in doing so have dominated the market in their segment. There are several challenges to building such a platform for broad use - data security & governance at the top, followed by operational simplicity and scalability. Enabling all engineers, scientists & analysts with all the data, while ensuring sensitive data is kept confidential and protected from exfiltration is where the challenge lies.
We encountered some of these challenges first hand while deploying the current generally available version of our platform at scale. We identified a set of architectural changes, security and manageability controls that would form the foundation of the next version of our platform and would significantly enhance the simplicity, scalability and security capabilities.
We are excited to announce the public preview of our Enterprise Cloud Service on AWS. The Enterprise Cloud Service is a simple, scalable and secure data platform delivered as a service that is built to support all data personas for all use cases, globally and at scale. It is built with strong security controls required by regulated enterprises, is API driven so that it can be fully automated by integrating into enterprise specific workflows, and is built for production and business critical operations.
In this article, we will share major features and capabilities that a data team could utilize to massively scale their Databricks footprint on AWS while complying with their enterprise governance policies. The platform is already generally available for Azure Databricks, though some of the aspects mentioned below are new for that product as well.
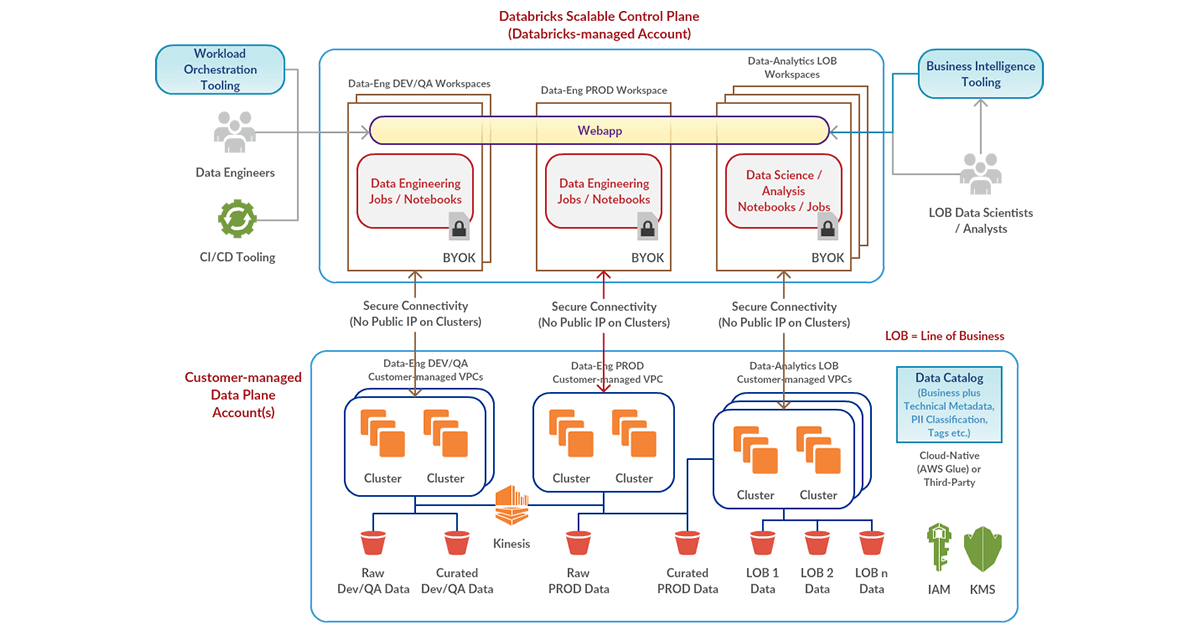
Enterprise Security
Security that Unblocks the True Potential of Your Data Lake
Learn how Databricks helps address the challenges that come with securing a cloud-native data analytics platform.
Customer-managed VPC
Deploy Databricks data plane in your own enterprise-managed VPC, in order to do necessary customizations as required by your cloud engineering & security teams. This feature is in public preview.
Secure Cluster Connectivity
Databricks establishes secure connectivity between the scalable control plane and the clusters in your private VPC. We don’t need a single Public IP in your cluster infrastructure to interact with the control plane. This feature is in public preview.
Customer-managed Keys for Notebooks
Databricks stores customer notebooks in the scalable control plane so as to provide a slick and fast user experience via the web interface. You can now choose to use your own AWS KMS key to encrypt those notebooks. This feature is in private preview.
IAM Credential Passthrough
Access S3 buckets and other IAM-enabled AWS data services using the identity that you use to login into Databricks, either with SAML 2.0 Federation or SCIM. This feature is in public preview.
Simple Administration
Manage a Cloud-scale Enterprise Data Platform with Ease
Deliver cloud-native data environments for your global analytics teams while retaining the visibility, control and scale from a single pane of glass.
Multiple Workspaces at Global Scale
Deploy multiple workspaces in a single VPC, or across multiple VPCs in a single AWS account, or across multiple AWS accounts, all mapping to the same Databricks account. This feature is in public preview.
Trust But Verify with Databricks
Get visibility into relevant cloud platform activity in terms of who’s doing what and when, by configuring Databricks Audit Logs and other related audit logs in the AWS Cloud. See how you could process the Databricks Audit Logs for continuous monitoring.
Cluster Policies
Implement cluster policies across multiple workspaces to make cluster creation interface relevant for different data personas, and to enforce different security and cost controls. This feature is in public preview.
Production Ready
Productionize and Automate your Data Platform at Scale
Create fully configured data environments and bootstrap them with users / groups, cluster policies, clusters, notebooks, object permissions etc. all through APIs.
Create Workspace using Multi-Workspace API
We’ve an API-first approach to building any new feature. The Multi-Workspace API allows you to automate the provisioning of a workspace, and then other APIs allow you to bootstrap it as per your needs. If you use Terraform, you could also utilize the Databricks Terraform Resource Provider to bootstrap and operate a workspace.
CI/CD for your Data Workloads
Streamline your application development and deployment process with integration to DevOps tools like Jenkins, Azure DevOps, CircleCI etc. Use REST API 2.0 under the hood to deploy your application artifacts and provision workspace-level objects.
Databricks Pools
Enable clusters to start and scale faster by creating a managed cache of virtual machine instances that can be acquired for use when needed. This feature is in public preview.
What’s Next?
Attend the Enterprise Cloud Service Webinar to learn more about the above mentioned capabilities & see how we put those into action. If you want to take part in the public preview, please reach out to your Databricks account team or use this form to contact us.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.