Personalizing the Customer Experience with Recommendations
by Rob Saker, Bryan Smith, Bilaji Raman, Ye Wang, Yiyan Zhang and Terry Tang
Go directly to the Recommendation notebooks referenced throughout this post.
Retail made a giant leap forward in the adoption of e-commerce in 2020, E-commerce as a percentage of total retail saw multiple years of progress in one year. Meanwhile, COVID, lockdowns and economic uncertainty have completely disrupted how we engage and retain customers. Companies need to rethink personalization to effectively compete in this period of rapid change.
In 2020, we saw a rapid shift in consumer behavior, not just in the adoption of e-commerce. Store brands saw increased consumer adoption. Staple goods saw a resurgence in demand. Customers not only rethought their relationships with specific products but retailers as well, spreading their spend across multiple retail partners. The relevance of in-store displays, features and promotions was challenged by leading retailers capable of driving 35% of their revenue through personalized recommendations.
Providing an experience that makes customers feel understood helps retailers stand out from the crowd of mass merchants and build loyalty. This was true before COVID but shifting consumer preferences make this more critical for retail organizations. With research showing the cost of customer acquisition being as much as five times as retaining existing ones, organizations looking to succeed in the new normal must continue to build deeper connections with the existing customers in order to retain a solid consumer base. There is no shortage of options and incentives for today’s consumers to rethink long-established patterns of spending.
Personalization is a must to compete
Presented with overwhelming choice, consumers expect the brands they buy and the organizations they buy them from to deliver an experience aligned with their needs and preferences. Personalization, once presented as an exotic vision for what could be, is increasingly becoming the baseline expectation for consumers continuously connected, short on time and seeking value through an increasingly more complex set of considerations.
Brands that deliver personalized experiences can compete with these retail giants. In a pre-COVID analysis of consumer attitudes and spending patterns, 80% of participants indicated they were more likely to do business with a company offering personalized experiences. Those individuals were found to be 10-times more likely to make 15 or more purchases per year with organizations they believe understood and responded to their personal needs and preferences. In a separate survey, 50% of participants reported seeing the brands they buy as extensions of themselves, driving deeper, more sustained customer loyalty for the brands that get it right.
As COVID forced a shift in consumer focus towards value, availability, quality, safety and community, brands most attuned to changing needs and sentiments saw customers switch from rivals. While some segments gained business and many lost, organizations that had already begun the journey towards improved customer experience saw better outcomes, closely mirroring patterns observed in the 2007-2008 recession (Figure 1).
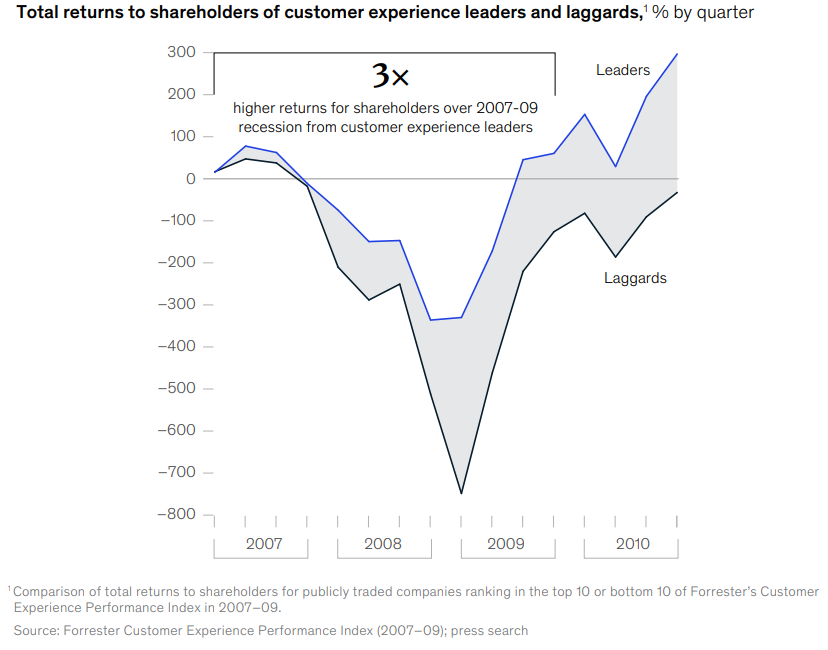
Figure 1. CX leaders outperform laggards, even in a down market, a visualization of the Forrester Customer Experience Performance Index as provided by McKinsey & Company (link
As we look towards what will be the new normal, it is clear that the personalization of customer experiences will remain a key focus for many B2C and even B2B organizations. Increasingly, market analysts are recognizing customer experience as a disruptive force enabling upstart organizations to upend long-established players. Organizations focused on competing through product, placement, pricing and promotion alone will find themselves under pressure from competitors capable of delivering more value to consumers for each dollar received.
Focus on the customer journey
Personalization starts with a careful exploration of the customer journey. This starts as customers come to recognize a need and move to identify a product to fulfill it. It then shifts towards the selection of a channel for its purchase and concludes with consumption, disposal and the possible repeat purchase. The path is varied and not simply linear, but with every stage, there is an opportunity for value to be created for the customer.
The digitization of each stage provides the customer with flexibility in terms of how they will engage and provides the organization with the ability to assess the health of their model. While part and parcel of the online and mobile experience, digitization can be extended to the in-store, in-transit and even the in-home stages of the customer journey with appropriate considerations of transparency, privacy and value-add for the customer.

This customer-generated data as well as third-party inputs provide the organization with the information they need to refine their understanding of the customer and their unique journeys. Individual motivations, goals and preferences can now be better understood and more personalized experiences delivered to the customer.
The examination of the customer journey, its digitization and the analysis of the data generated by it are used to create a feedback loop through which the customer experience improves. To get this loop in motion and sustain it over time, a clear vision for competing on customer experience must be expressed. This vision must bring together the entire organization, not just marketing and their IT-enablers, around shared goals. These goals must then be translated into incentive structures that encourage cross-departmental collaboration and innovation. The organization’s journey towards delivering differentiating customer experiences is fundamentally a journey towards becoming a learning organization, one which puts insights into motion, celebrates the learnings that come with failure, and rapidly scales its successes to drive customer value.
Leverage customer preferences
Personalization is multifaceted, but at various points in the customer journey, organizations will have the opportunity to select content, products, promotions to be presented to the customer. In these moments, we can take into consideration past feedback from customers to select the right items to present. Customer feedback doesn’t always come to us in the form of 1-to-5 star ratings or written reviews. Feedback may be expressed through interactions, dwell times, product searches, and purchase events. Careful consideration of how customers interact with various assets and how these interactions may be interpreted as expressions of preference can unlock a wide range of data with which you can enable personalization.
With feedback in hand, we now consider which items to present. Consider a customer browsing an assortment of recommended products, clicking on one, exploring alternatives to this item, putting it into their cart and then exploring items frequently bought in combination with this item. At each stage of this very narrow slice of the customer’s journey, the customer is interacting with our content with very different goals in mind. The customer’s preferences are unchanged throughout this journey but their intent leads us to use that information to make very different choices with regards to what we might present.
Understand it’s as much art as science
The engines we use to serve content based on customer preferences are known as recommenders. To describe their construction as much Art as Science would be an understatement. With some recommenders, we focus heavily on the shared preferences of similar customers to expand the range of content we might expose to customers. With others, we focus on the properties of the content itself (e.g., product descriptions) and leverage user-specific interactions with related content to quantify the likelihood an item is likely to resonate with the customer. Each class of recommendation engine orients around a general goal, but within each, there are myriad decisions the business must make that orient its recommendations towards specific goals.
The complexity of these engines and the nature of why we build them are such that any upfront evaluation of their supposed accuracy is suspect. While offline evaluation methods have been proposed and should be employed to ensure that the recommenders we build are not flying off the rails, the reality is that we can only effectively evaluate their ability to assist us in achieving a particular goal by releasing them in limited pilots and assessing customer response. And in those assessments, it’s important to keep in mind that there is no expectation of perfection, only incremental improvement over the prior solution.
Consider tradeoffs between performance & completeness
The primary challenge we must overcome in the assembly of any recommender is scalability. Consider a recommender leveraging user similarities. A small pool of 100,000 users requires the evaluation of approximately 5,000,000,000 user pairs and each of those evaluations may involve a comparison of preferences for each item we might recommend. From a purely technical standpoint, performing this number of calculations is not a problem, but the cost of doing it on a regular basis and within the time-constraints imposed on these systems makes a brute-force evaluation untenable.
It’s for this reason that the technical literature surrounding the development of recommender systems puts a heavy emphasis on approximate similarity techniques. These techniques offer shortcuts that allow us to home in on those users or items most likely to be similar to the objects we are comparing. With these techniques, there is a tradeoff between performance gains and recommendation completeness. So while these techniques are quite technically oriented, there is an important conversation to be had between solution architects and the business stakeholders about the right balance between these two considerations.
Jumpstart your efforts with solution accelerators
It goes without saying that careful management of resources can go a long way to keeping the cost of on-going recommender development, training and deployment. Databricks is purpose-built for scalable development on cloud infrastructures that allow organizations to rapidly provision and then deprovision resources for exactly this reason.
To help our customers understand how they might use Databricks to develop various recommenders, we’ve made available a series of detailed notebooks as part of our Solution Accelerators program. Each notebook leverages a real-world dataset to show how raw data may be transformed into one or more recommender solutions.
The focus of these notebooks is on education. No one should take the techniques demonstrated here as the only way or even the preferred way to solve a specific recommendation challenge. Still, in wrestling with the issues described above, we hope that some portions of the presented code will assist our customers in tackling their own recommender needs.
Collaborative Filter Recommenders
- CF 01: Data Preparation
- CF 02: Identify Similar Users
- CF 03: Build User-Based Recommendations
- CF 04: Build Item-Based Recommendations
- CF 05: Deploy Collaborative Filters
Content-Based Recommenders
You can also view our on-demand webinar around personalization and recommendations.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.