Need for Data-centric ML Platforms
Why switching from a model-centric to a data-centric approach solves the biggest challenges facing MLOps
Introduction
Recently, I learned that the failure rate for machine learning projects is still astonishingly high. Studies suggest that between 85-96% of projects never make it to production. These numbers are even more remarkable given the growth of machine learning (ML) and data science in the past five years. What accounts for this failure rate?
For businesses to be successful with ML initiatives, they need a comprehensive understanding of the risks and how to address them. In this post, we attempt to shed light on how to achieve this by moving away from a model-centric view of ML systems towards a data-centric view. We’ll also dive into MLOps and model governance and the importance of leveraging data-centric ML platforms such as Databricks.
The data of ML applications
Of course, everyone knows that data is the most important component of ML. Nearly every data scientist has heard: "garbage in, garbage out" and "80% of a data scientist’s time is spent cleaning data". These aphorisms remain as true today as they did five years ago, but both refer to data purely in the context of successful model training. If the input training data is garbage, then the model output will be garbage, so we spend 80% of our time ensuring that our data is clean and our model makes useful predictions. Yet model training is only one component of a production ML system.
In Rules of Machine Learning, research scientist Martin Zinkevich emphasizes implementing reliable data pipelines and infrastructure for all business metrics and telemetry before training your first model. He also advocates testing pipelines on a simple model or heuristic to ensure that data is flowing as expected prior to any production deployment. According to Zinkevich, successful ML application design considers the broader requirements of the system first, and does not overly focus on training and inference data.
Zinkevich isn’t the only one who sees the world this way. The Tensorflow Extended (TFX) team at Google has cited Zinkevich and echoes that building real world ML applications “necessitates some mental model shifts (or perhaps augmentations).”
Prominent AI researcher Andrew Ng has also recently spoken about the need to embrace a data-centric approach to machine learning systems, as opposed to the historically predominant model-centric approach. Ng talked about this in the context of improving models through better training data, but I think he is touching upon something deeper. The message from both of these leaders is that deploying successful ML applications requires a shift in focus. Instead of asking, What data do I need to train a useful model?, the question should be: What data do I need to measure and maintain the success of my ML application?
To confidently measure and maintain success, a variety of data must be collected to satisfy business and engineering requirements. For example, how do we know if we’re hitting business KPIs for this project? Or, where is our model and its data documented? Who is accountable for the model, and how do we trace its lineage? Looking at the flow of data in a ML application can shed some light on where these data points are found.
The diagram below illustrates one possible flow of data in a fictional web app that uses ML to recommend plants to shoppers and the personas that own each stage.
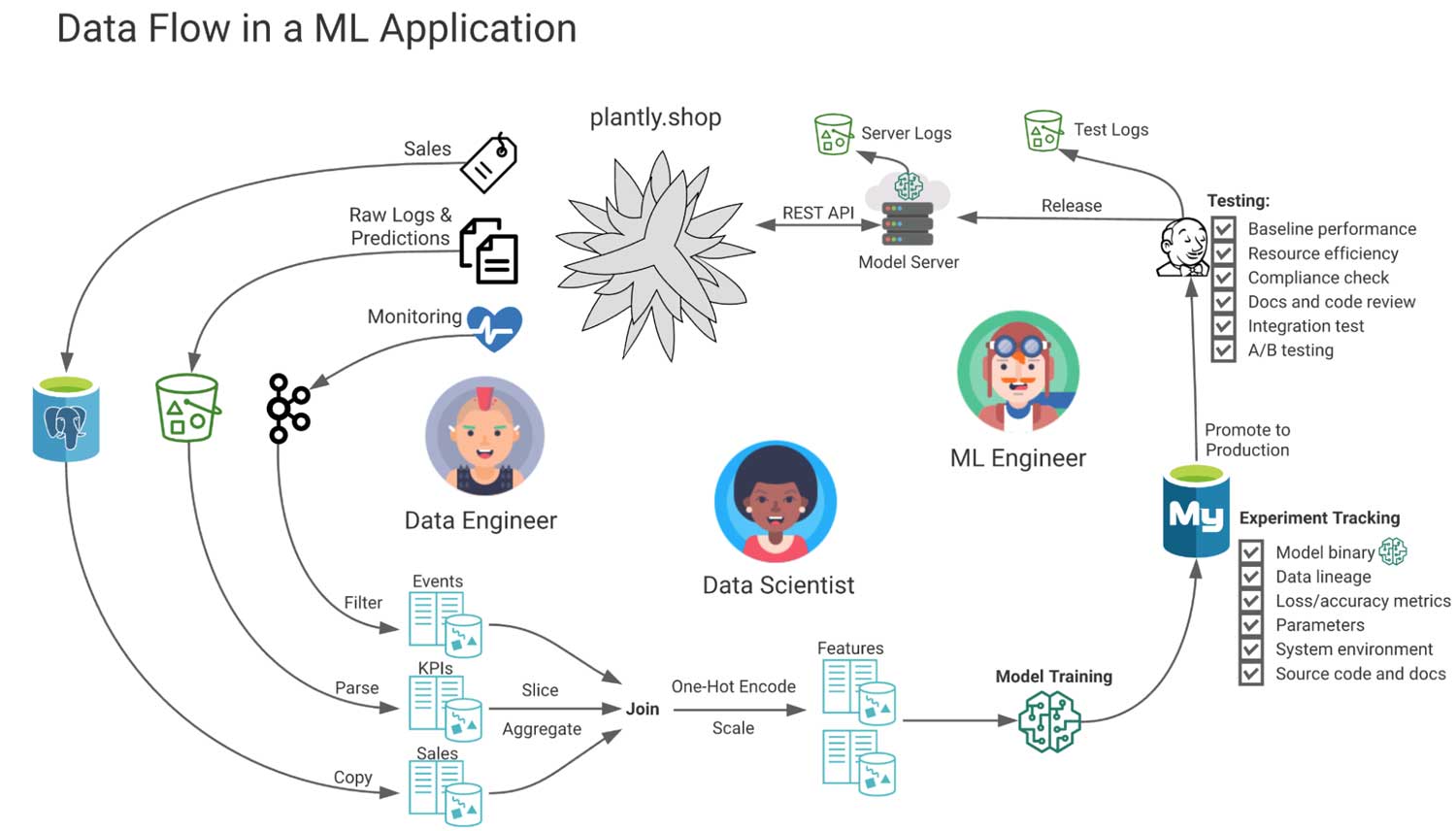
In this diagram, source data flows from the web app to intermediate storage, and then to derived tables. These are used for monitoring, reporting, feature engineering and model training. Additional metadata about the model is extracted, and logs from testing and serving are collected for auditing and compliance. A project that neglects or is incapable of managing this data is at risk of underperforming or failing entirely, regardless of how well the ML model performs on its specific task.
ML engineering, MLOps & model governance
Much like DevOps and data governance have lowered risk and become disciplines in their own right, ML engineering has emerged as a discipline to handle the operations (aka MLOps) and governance of ML applications. There are basically two kinds of risk that need to be managed in this context: risk inherent to the ML application system and risk of non-compliance with external systems. If data pipeline infrastructure, KPIs, model monitoring and documentation are lacking, then the risk of your system becoming destabilized or ineffective increases. On the other hand, a well-designed app that fails to comply with corporate, regulatory and ethical requirements runs the risk of losing funding, receiving fines or reputational damage.
How can organizations manage this risk? MLOps and model governance are still in their early stages, and there are no official standards or definitions for them. Therefore, based on our experience working with customers, we propose useful definitions to help you think about it.
MLOps (machine learning operations) is the active management of a productionized model and its task, including its stability and effectiveness. In other words, MLOps is primarily concerned with maintaining the function of the ML application through better data, model and developer operations. Simply put, MLOps = ModelOps + DataOps + DevOps.
Model governance, on the other hand, is the control and regulation of a model, its task and its effect on surrounding systems. It is primarily concerned with the broader consequences of how an ML application functions in the real world.
To illustrate this distinction, imagine an extreme case in which someone builds a highly-functional ML application that is used to secretly mine Bitcoin on your devices. That would be very effective, but its lack of governance has negative consequences on society. At the same time, you could write 400 page compliance and auditing reports for a credit risk model to satisfy federal regulations, but if the application isn't stable or effective, then it is lacking in the operational dimension.
So, to build a system that is functional and respects human values, we need both. At a minimum, operations are responsible for maintaining uptime and stability, and each organization assumes legal and financial responsibility for the ML applications they create. Today, this responsibility is relatively limited because the regulatory environment for AI is in its infancy. However, leading corporations and academic institutions in the space are working to shape its future. Much like GDPR caused major waves in the data management space, it seems that similar regulation is an inevitability for ML.
Essential Capabilities
Having distinguished between operations and governance, we are now in a position to ask: What specific capabilities are required to support them? The answers fall into roughly six categories:
Data processing and management
Since the bulk of innovation in ML happens in open source, support for structured and unstructured data types with open formats and APIs is a prerequisite. The system must also process and manage pipelines for KPIs, model training/inference, target drift, testing and logging. Note that not all pipelines process data in the same way or with the same SLA. Depending on the use case, a training pipeline may require GPUs, a monitoring pipeline may require streaming and an inference pipeline may require low latency online serving. Features must be kept consistent between training (offline) and serving (online) environments, leading many to look to feature stores as a solution. How easy is it for engineers to manage features, retry failed jobs, understand data lineage, and comply with regulatory mandates like GDPR? The choices made to deliver these capabilities can result in significant swings in ROI.
Secure collaboration
Real world ML engineering is a cross-functional effort - thorough project management and ongoing collaboration between the data team and business stakeholders are critical to success. Access controls play a large role here, allowing the right groups to work together in the same place on data, code and models while limiting the risk of human error or misconduct. This notion extends to separation of dev and prod environments too.
Testing
To ensure the system meets expectations for quality, tests should be run on code, data and models. This includes unit tests for pipeline code covering feature engineering, training, serving and metrics, as well as end-to-end integration testing. Models should be tested for baseline accuracy across demographic and geographic segments, feature importance, bias, input schema conflicts and computational efficiency. Data should be tested for the presence of sensitive PII or HIPAA data and training/serving skew, as well as validation thresholds for feature and target drift. Ideally automated, tests reduce the likelihood of human error and aid in compliance.
Monitoring
Regular surveillance over the system helps identify and respond to events that pose a risk to its stability and effectiveness. How soon can it be discovered when a key pipeline fails, a model becomes stale or a new release causes a memory leak in production? When was the last time all input feature tables were refreshed or someone tried to access restricted data? The answers to these questions may require a mix of live (streaming), periodic (batch) and event driven updates.
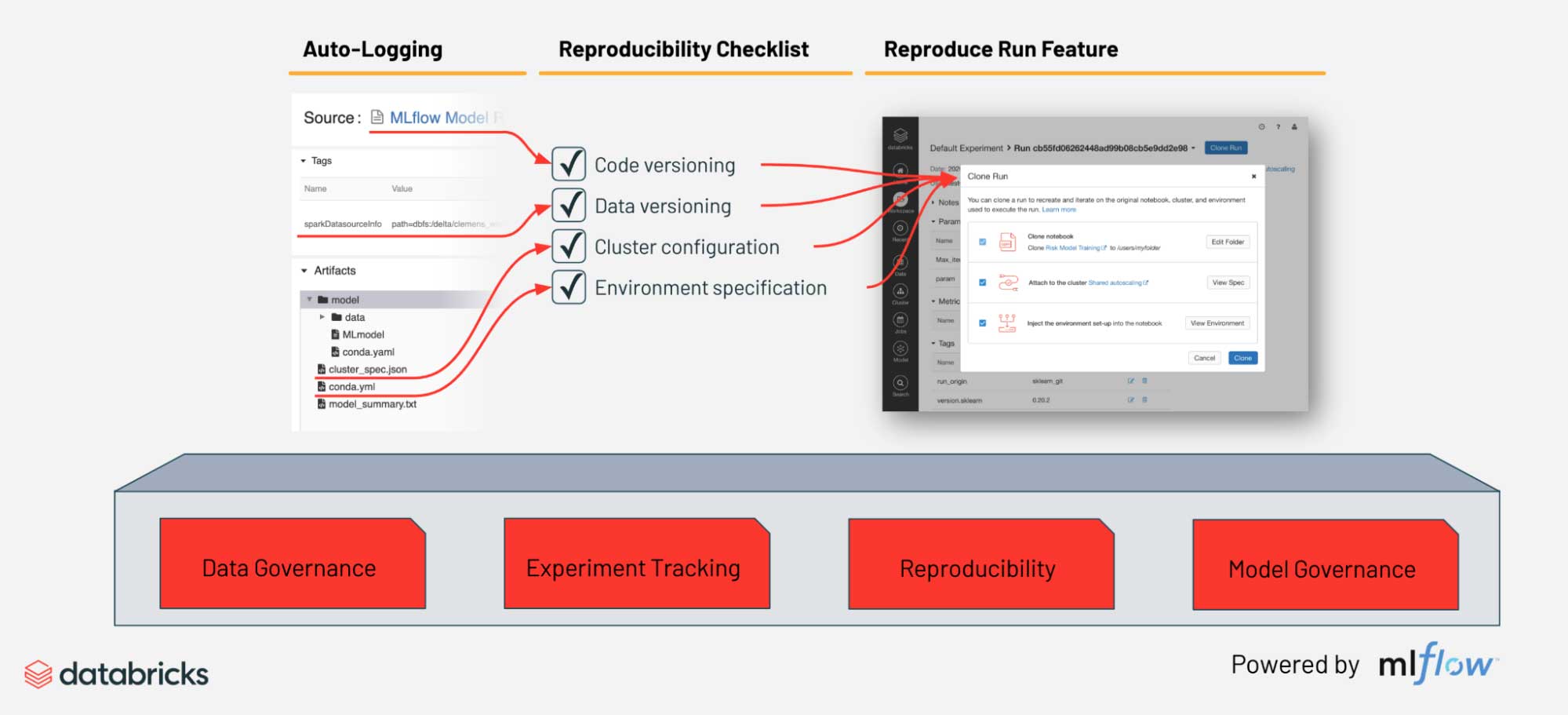
Reproducibility
This refers to the ability to validate the output of a model by recreating its definition (code), inputs (data) and system environment (dependencies). If a new model shows unexpectedly poor performance or contains bias towards a segment of the population, organizations need to be able to audit the code and data used for feature engineering and training, reproduce an alternate version, and re-deploy. Also, if a model in production is behaving strangely, how will we be able to debug it without reproducing it?
Documentation
Documenting a ML application scales operational knowledge, lowers the risk of technical debt and acts as a bulwark against compliance violations. This includes an accounting and visualization of the system architecture; the schemas, parameters and dependencies of features, models and metrics; and reports of every model in production and accompanying governance requirements.
The need for a data-centric machine learning platform
In a recent webinar, Matei Zaharia listed ease of adoption by data teams alongside integration with data infrastructure and collaboration functions as desirable features in a ML platform.
In this regard, data science tools that emerged from a model-centric approach are fundamentally limited. They offer advanced model management features in software that is separated from critical data pipelines and production environments. This disjointed architecture relies on other services to handle the most critical component of the infrastructure – data.
As a result, access control, testing and documentation for the entire flow of data are spread across multiple platforms. To separate these at this point seems arbitrary and, as has been established, unnecessarily increases the complexity and risk of failure for any ML application.
A data-centric ML platform brings models and features alongside data for business metrics, monitoring and compliance. It unifies them, and in doing so, is fundamentally simpler. Enter lakehouse architecture.
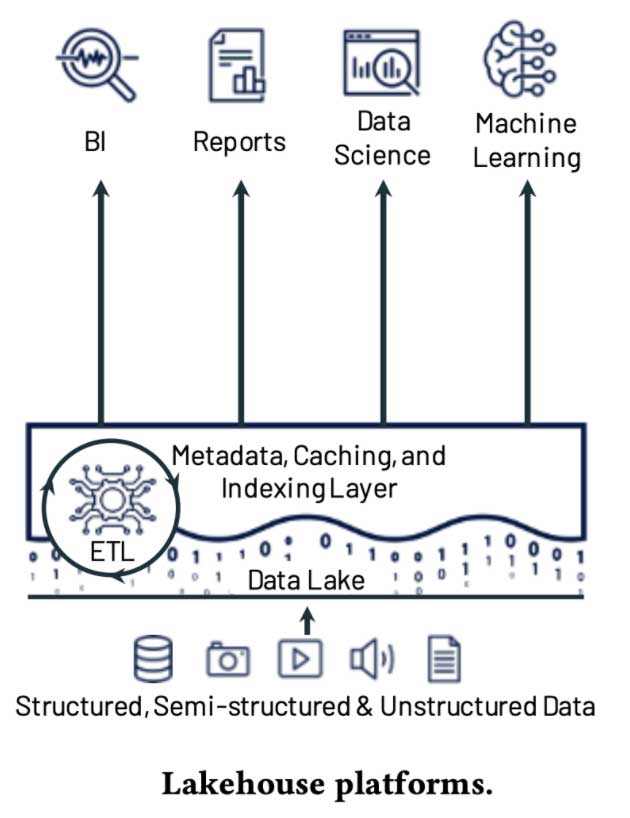
Lakehouses are by definition data-centric and combine the flexibility and scalability of data lakes with the performance and data management of a data warehouse. Their open source nature makes it easy to integrate ML with where the data lives. There’s no need to export data out of a proprietary system in order to use ML frameworks like Tensorflow, PyTorch or scikit-learn. This also makes them considerably easier to adopt.
Databricks Machine Learning is built upon a lakehouse architecture and supports critical MLOps and governance needs including secure collaboration, model management, testing and documentation.
Data processing and management
To manage and process the variety and volume of data sources required by a ML application, Databricks uses a high performance combination of Apache Spark and Delta Lake. These unify batch and streaming workloads, operate at petabyte scale and are used for monitoring, metrics, logging and training/inference pipelines that are built with or without GPUs. Delta Lake’s data management capabilities make it easy to maintain compliance with regulations. The Feature Store is tightly integrated with Delta, Spark and MLflow to make feature discovery and serving simple for training and inference jobs. Multi-step pipelines can be executed as scheduled jobs or invoked via API, with retries and email notifications. For low latency online serving, Databricks offers hosted MLflow model serving for testing, publishing features to an online store, and integrating with Kubernetes environments or managed cloud services like Azure ML and Sagemaker for production.
Secure collaboration
In addition to defining data access privileges at the table, cloud resource or user identity level, Databricks also supports access control of models, code, compute and credentials. These enable users to co-edit and co-view notebooks in the workspace in compliance with security policies. The administrative features that limit access to production environments and sensitive data are used by customers in financial services, health care, and government around the world.
Testing
Databricks Repos allow users to integrate their project with version control systems and automated build and test servers like Jenkins or Azure DevOps. These can be used for unit and integration tests whenever code is committed. Databricks also offers MLflow webhooks that can be triggered at key stages of a model’s lifecycle - for example promotion to staging or production. These events can force an evaluation of the model for baseline accuracy, feature importance, bias, and computational efficiency, rejecting candidates that fail to pass or inviting a code review and tagging models accordingly. The signature or input schema of a MLflow model can also be provided at logging time and tested for compatibility with the data contract of the production environment.
Monitoring
For ongoing surveillance, Structured Streaming and Delta Lake can be used in conjunction with Databricks SQL to visualize system telemetry, KPIs, and feature distributions to stakeholders in real time dashboards. Periodic, scheduled batch jobs keep static historical and audit log tables fresh for analysis. To stay abreast of important events teams can receive email or Slack notifications for job failures. To maintain the validity of input features, routine statistical testing of feature distributions should be performed and logged with MLflow. Comparing runs makes it easy to tell if the shape of feature and target distributions is changing. If a distribution or application latency metric breaches a threshold value, an alert from SQL Analytics can trigger a training job using webhooks to automatically redeploy a new version. Changes to the state of a model in the MLflow Model Registry can be monitored via the same webhooks mentioned for testing. These alerts are critical to maintaining the efficacy of a model in production.
Reproducibility
MLflow is a general framework to track and manage models from experimentation through deployment. The code, data source, library dependencies, infrastructure and model can be logged (or auto-logged) at training time alongside other arbitrary artifacts like SHAP explainers or pandas-profiling. This allows for reproducing a training run at the click of a button. This data is preserved when models are promoted to the centralized Model Registry, serving as an audit trail of their design, data lineage and authorship. Maintaining model versions in the registry makes it easy to quickly roll back breaking changes while engineers trace a model artifact back to its source for debugging and investigation.
Documentation
Following the notion that documentation should be easy to find, Databricks Notebooks are a natural fit for documenting pipelines that run on the platform and system architecture. In addition to notebooks, models can also be elucidated by conveniently logging relevant artifacts alongside them to the MLflow tracking server, as described above. The tracking server and registry also support annotation of a model and a description of its lifecycle stage transitions via the UI and API. These are important features that bring human judgement and feedback to an AI system.
Putting it all together
To illustrate what the experience of developing a ML application on a data-centric ML platform like Databricks looks like, consider the following scenario:
A team of three practitioners (data engineer, scientist, machine learning engineer) are tasked with building a recommender to improve sales for their online store - plantly.shop.
At first, the team meets with business stakeholders to identify KPI and metric requirements for the model, application, and corresponding data pipelines, identifying any data access and regulatory issues up front. The data engineer starts a project in version control, syncs their code to a Databricks Repo, then gets to work using Apache Spark to ingest sales and application log data into Delta Lake from an OLTP database and Apache Kafka. All pipelines are built with Spark Structured Streaming and TriggerOnce to provide turnkey streaming in the future. Data expectations are defined on the tables to ensure quality, and unit and integration tests are written with Spark in local mode in their IDE. Table definitions are documented with markdown in shared notebooks on Databricks and copied into an internal wiki.
The data scientist is granted access to the tables using SQL, and they use Databricks AutoML, koalas and notebooks to develop a simple baseline model predicting if a user will purchase plants shown to them. The system environment, code, model binary, data lineage and feature importance of this baseline are automatically logged to the MLflow tracking server, making auditing and reproducibility simple.
Eager to test in a production pipeline, the data scientist promotes the model to the MLflow Model Registry. This triggers a webhook, which in turn kicks off a series of validation tests written by the ML engineer. After passing checks for prediction accuracy, compatibility with the production environment, computational performance, and any compliance concerns with the training data or predictions (can’t recommend invasive species, can we!), the ML engineer approves the transition to production. MLflow model serving is used to expose the model to the application via REST API.
In the next release, the model is tested by sending a subset of production traffic to the API endpoint and the monitoring system comes to life! Logs are streaming into Delta Lake, parsed and served in SQL Analytics dashboards that visualize conversion rates, compute utilization, rolling prediction distributions and any outliers. These give the business stakeholders direct visibility into how their project is performing.
In the meantime the data scientist is busy working on version 2 of the model, a recommender using deep learning. They spin up a single node, GPU enabled instance with the ML Runtime and develop a solution with PyTorch that is automatically tracked by MLflow. This model performs far better than the baseline model, but uses features that are completely different. They save these to Delta Lake, documenting each feature, its source tables and the code used to generate it. After passing all tests, the model is registered as version 2 of the plant recommender.
The pandemic has certainly caused plant sales to spike and to cope with the higher than expected traffic the team uses the mlflow.pyfunc.spark_udf to generate predictions with the new model in near real-time with Spark Structured Streaming. In the next release, everyone is recommended a variegated ficus elastica, which immediately sells out. No surprise there! The team celebrates their success, but in a quiet moment, the data scientist can be heard muttering something about ‘overfitting’...
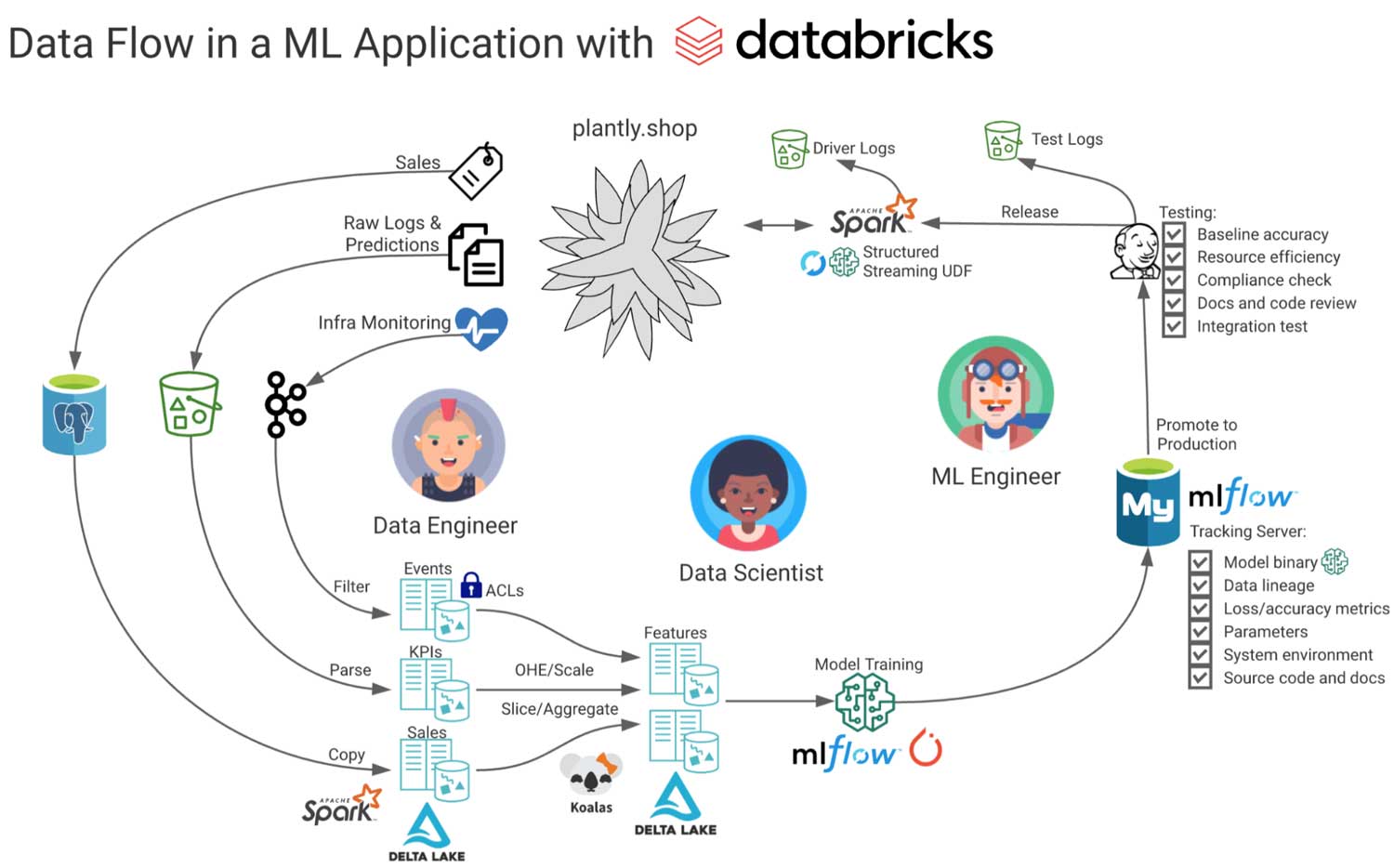
This simplified example of a real-life workflow helps animate MLOps and governance alongside traditional work on a data-centric ML platform.
Conclusion
In this blog, we endeavoured to understand why ML initiatives continue to fail. We discovered that a model-centric approach to ML applications can unintentionally be a tremendous source of risk. Switching to a data-centric approach clarifies the nature of that risk as belonging to the application function itself, or to compliance with external systems. MLOps and governance are emerging disciplines that seek to establish confidence in and derisk ML initiatives, which they accomplish through a set of essential capabilities. The Databricks Lakehouse is one proven data-centric ML platform that delivers these capabilities while remaining open and easy to adopt.
We may still be early in the days of machine learning, but it doesn’t feel like that will be the case for much longer. AI will continue to change every sector of the economy and our lives. Organizations that adopt a data-centric ML platform with strong MLOps and governance practices will play a role in that transformation.
Next steps
To see a live demonstration of many of these concepts, see the DAIS 2021 session Learn to Use Databricks for the Full ML Lifecycle.
In future posts, we hope to dive deeper into how Databricks realizes these capabilities for its customers. In the meantime, here are some resources to learn more:
- Operationalizing Machine Learning at Scale featuring Matei Zaharia, J.B. Hunt, H&M (2021)
- Tech Talk: MLOps on Azure Databricks with MLflow (2021)
- 1. Most Data Science Projects Fail, But Yours Doesn’t Have To, Datanami, Oct. 2020
- 2. Rules of Machine Learning: Best Practices for ML Engineering, Zinkevich, M. 2017
- 3. Towards ML Engineering: A Brief History of Tensorflow Extended (TFX), Katsiapis et al., page 3, 2020.
- 4. See Andrew Ng’s discussion on ML Ops
- 5. For a more comprehensive discussion on mitigating risk in ML applications, see ML Engineering in Action, Wilson, B., 2021
- 6. EU outlines ambitious AI regulations focused on risky uses, Associated Press 2021
- 7. See “Data Dependencies Cost More Than Code Dependencies”, Hidden Technical Debt in Machine Learning Systems, Scully, et al., 2015.
- 8. See “Data Dependencies Cost More Than Code Dependencies”, Hidden Technical Debt in Machine Learning Systems, Scully, et al., 2015.
- 9. See Chapter 3, “Before you model: Planning and Scoping”, ML Engineering in Action, Wilson, B., 2021
- 10. For an excellent treatment of testing, see The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction, Breck, et al., 2017.
- 11. Ibid.
- 12. Keynote: Operationalizing Machine Learning Systems at Scale, 2021
- 13. See Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, Armbrust, et al., 2021
- 14. Ibid., especially the section ‘Efficient Access for Advanced Analytics’.
- 15. See Running Streaming Jobs Once a Day for 10x Cost Savings, Yavuz, B., Condie, T., 2017
- 16. https://www.databricks.com/customers
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.