Implementing More Effective FAIR Scientific Data Management With a Lakehouse
by Greg Wood and Amir Kermany
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Data powers scientific discovery and innovation. But data is only as good as its data management strategy, the key factor in ensuring data quality, accessibility, and reproducibility of results – all requirements of reliable scientific evidence.
As large datasets have become more and more important and accessible to scientists across disciplines, the problems of big data in the past decade -- unruly, untamed, uncontrolled, and unreproducible data workflows -- have become increasingly relevant to scientific organizations.
This led to industry experts to develop a framework for “good data management and stewardship,” initially introduced in a 2016 article in Nature, with “long-term care of valuable digital assets” at the core of it. These principles, now widely known as FAIR, consist of four main tenets: Findability, Accessibility, Interoperability, and Reuse of digital assets. Through its framework, FAIR helps to address these issues by emphasizing machine-actionability and the capacity of computational systems to find, access, interoperate and reuse data with no or minimal human intervention.
Nearly every scientific workflow -- from performing detailed data quality controls to advanced analytics -- relies on de-novo statistical methods to tackle a particular problem. Therefore any data architecture designed to address good data governance should also have support for the development and application of advanced analytics tools on the data. These characteristics are inherently limited in legacy two-tier data architectures and don’t support modern data and advanced analytics use cases. That’s where a lakehouse architecture can help.
Over the past few years, the lakehouse paradigm, which unifies the benefits of data warehouses and data lakes into a new data platform architecture, has become increasingly prevalent across industries. As the next generation of enterprise-scale data architectures emerges, the lakehouse has proven to be a versatile structure that can support traditional analytics and machine learning use cases. Key to much of this versatility is Delta Lake, an open-source data management layer for your data lake, that provides warehouse-style consistency and transactionality with the scale, flexibility, and cost savings of a data lake.
In this post, we’ll take a closer look at how a lakehouse built on top of Delta Lake enables a FAIR data system architecture within organizations pursuing scientific research.
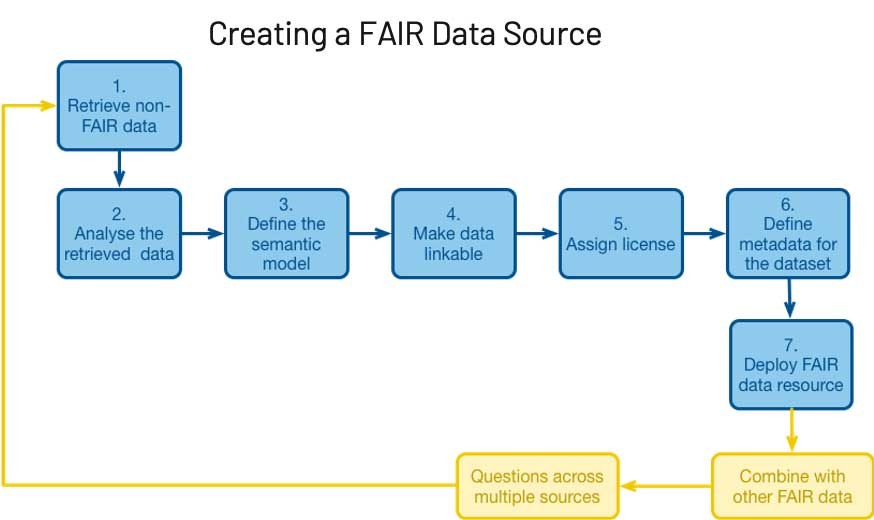
While their value is apparent, objectives like these have given data teams fits for years. Take, for example, the data lake; no part of a system is more accessible than a data lake, but while it has brought great promise to the world of data organization, it has simultaneously created great disarray. The cloud, for all of its benefits, has made this challenge even more difficult: plummeting storage costs and everywhere-all-the-time data access equals data proliferation. With all the pressures of this growth, lofty stewardship principles such as FAIR often get deprioritized.
Inevitably, the downsides of an uncontrolled cloud rear their heads – cost explodes, utilization plummets and risk becomes untenable due to lack of governance. This rings especially true in the scientific world, where uncertainty and change are present in every cell, subject, and trial. So why introduce more unknowns with a new data platform, when a laptop works perfectly fine? In this light, data disorganization is the enemy of innovation, and FAIR aims to make an organization a reproducible process. So, to the real question: “How do I put FAIR into practice?”
Fortunately, recent developments in cloud architecture make this question easier to answer than ever before. Specifically, let's take a look at how a lakehouse built on top of Delta Lake addresses each of the FAIR guiding principles.
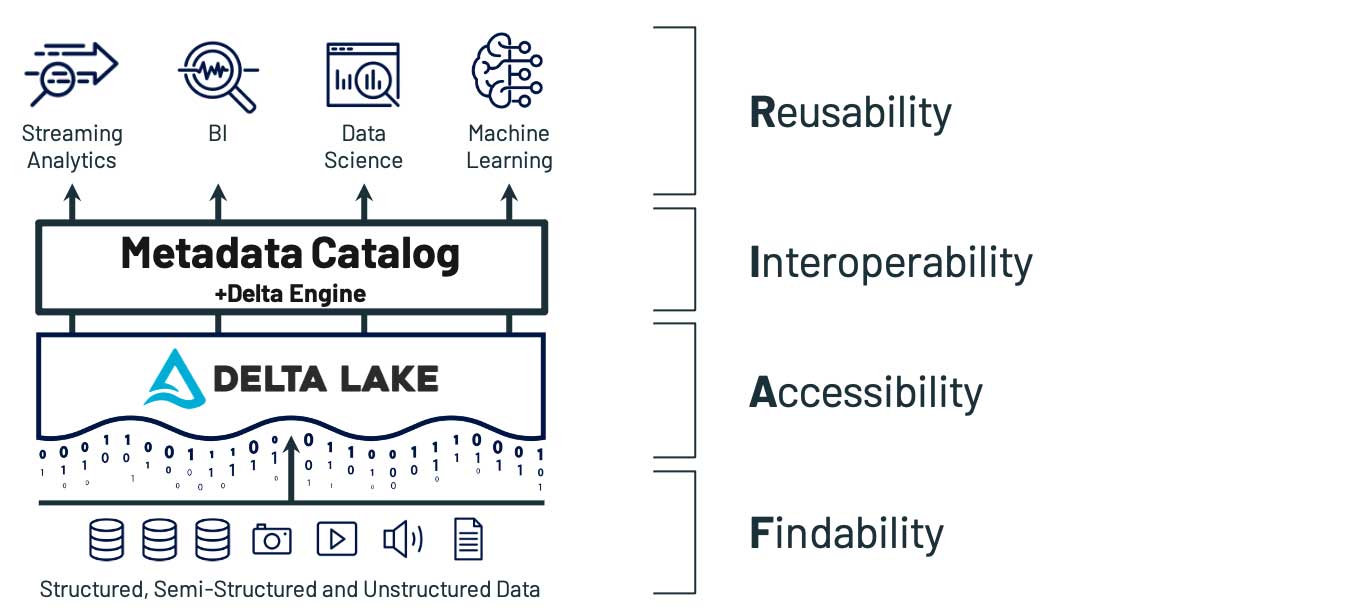
Findability: How do users find data in an automated, repeatable way?
Data findability is the first hurdle of any experiment, pipeline or process. It is also one of the main victims of data proliferation. With petabytes of data smattered across dozens of disconnected systems, how can even the savviest users (let alone the poor souls uninitiated to the company’s tribal knowledge) possibly navigate the data landscape? Bringing disparate data from multiple systems into a single location is a core principle of the data lake. The lakehouse expands this concept even further by building the other principles of FAIR on top, but the core idea stays the same: when done right, unifying data in a single layer makes every other architecture decision easier.
The FAIR standards for Findability are broken down into several sub-objectives:
- F1: (Meta) data is assigned globally unique and persistent identifiers.
- F2: Data is described with rich metadata.
- F3: Metadata clearly and explicitly includes the identifier of the data they describe.
- F4: (Meta)data is registered or indexed in a searchable resource.
Each of these points lines up with a Delta-based lakehouse. For example, with Delta Lake, metadata includes the standard information, such as schema, as well as versioning, schema evolution over time and user-based lineage. There is also never any ambiguity about which data any given metadata describes, since data and metadata are co-located, and as a best practice, the lakehouse includes a central, high-accessible metastore to provide easy searchability. All of these result in highly-findable data in the lakehouse paradigm.
As one example of how the lakehouse enables data findability, consider the following:
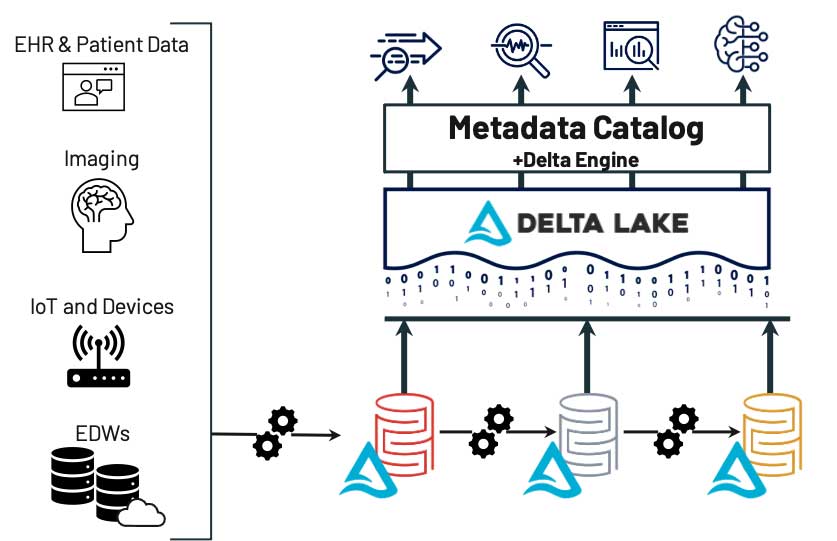
Here, we have ingestion from many systems -- imaging systems, on-prem and cloud data warehouses, Electronic Health Record (EHR) systems, etc. Regardless of the source, they are deposited into a “bronze” layer within the underlying data lake, and then automatically fed through refinement processes that might include de-identification, normalization and filtering. Finally, data is deposited into a “gold” layer, which includes only high-quality data; users (or automated feeds) need only look in one place to find the latest version of usable data. Even data science or ML processes that might require less-refined data can leverage the silver or bronze layers; these processes know where the data resides and what each layer contains. As we’ll see, this makes every other principle of FAIR easier to implement and track.
Accessibility: How do users access the data once it has been found?
According to the FAIR principles, accessible data is “retrievable… using a standardised communications protocol” and “accessible even when the data are no longer available.” Traditionally, this is where the data lake model would begin to break down; almost by definition, a data lake has an arbitrary number of schemas, file types and formats and versions of data. While this makes findability simple, it makes for an accessibility nightmare; even more, what is in the lake one day may either change, move or completely disappear the next. This was one of the primary failings of the data lake -- and where the lakehouse begins to diverge.
A well-architected lakehouse requires a layer to facilitate accessibility in between the underlying data lake and consumers; there are several tools that provide such a layer today, but the most widely used is Delta Lake. Delta brings a huge number of benefits (ACID transactions, unified batch/streaming, cloud-optimized performance, etc.), but two are of particular importance in relation to FAIR. First, Delta Lake is an open-source format governed by the Linux Foundation, meaning that it is a standardized, nonproprietary and inherently multi-cloud protocol. Regardless of which vendor(s) is used, data that is written in Delta will always be openly accessible. Second, Delta provides a transaction log that is distinct from the data itself; this log allows actions such as versioning, which are essential to reproducibility, and also means that even if the data itself is deleted, the metadata (and in many cases, with appropriate versioning, even the data) can be recovered. This is an essential piece of the accessibility tenet of FAIR -- if stability over time cannot be guaranteed, data may as well not exist to begin with.
As an example of how Delta Lake enables accessibility, consider the following scenario in which we begin with a table of patient information, add some new data and then accidentally make some unintentional changes.

Because Delta persists our metadata and keeps a log of changes, we are able to access our previous state even for data deleted accidentally -- this applies even if the whole table is deleted! This is a simple example but should give a flavor of how a lakehouse built on top of Delta Lake can bring stability and accessibility to your data. This is especially valuable in any organization in which reproducibility is imperative. Delta Lake can lighten the load on data teams while allowing scientists to freely innovate and explore.
And finally, Delta Lake provides Delta Sharing, an open protocol for secure data sharing. This makes it simple for scientific researchers to share research data directly with other researchers and organizations, regardless of which computing platforms they use, in an easy-to-manage and open format.
Interoperability: How are data systems integrated?
There is no shortage of data formats today. Once the familiar formats of CSV and Excel spreadsheets provided all the functionality we could ever need, but today there are thousands of domain-specific healthcare formats, from BAM and SAM to HL7. This is, of course, before we even get to unstructured data such as DICOM images, big data standards like Apache Parquet, and the truly limitless number of vendor-specific proprietary formats. Throw all of this together in a data lake, and you’ve created a truly frightening cocktail of data. An effective interoperable system, and one that meets the FAIR principles, must be machine-readable in every format that it is fed -- a feat that is difficult at best, and impossible at worst, when it comes to the huge variety of data formats used in HLS.
In the lakehouse paradigm, we tackle this issue using Delta Lake. We first land the data in its raw format, keeping an as-is copy for historical and data-mining purposes; we then transform all data to the Delta format, meaning that downstream systems need only understand a single format in order to function.
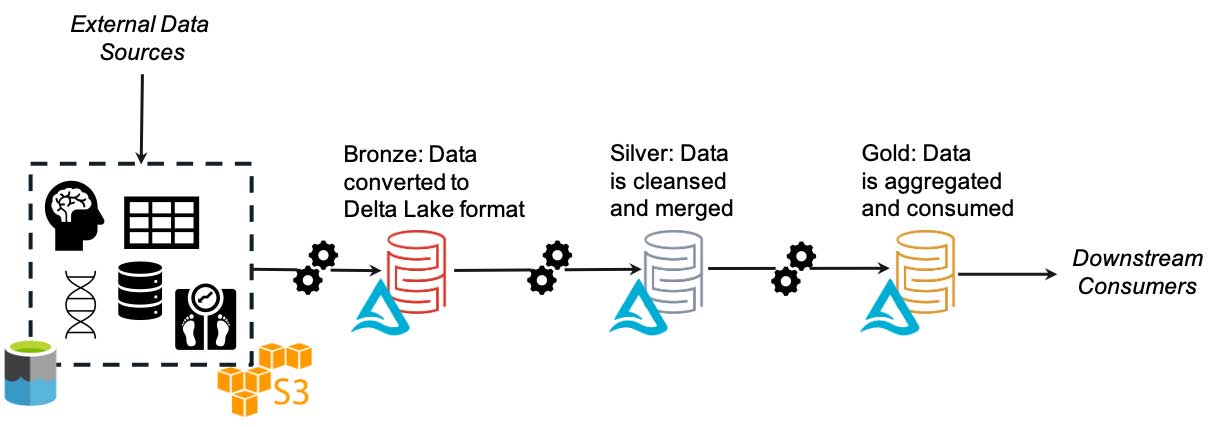
Additionally, the lakehouse promotes a single, centralized metadata catalog; this means that no matter where or how the original and transformed data is stored, there is one point of reference to access and use it. Furthermore, this means that there is a single point of control for sensitive PHI or HIPAA-compliant data, enhancing the governance and control of data flow.
One common question is how to actually convert all of these disparate formats; after all, although downstream systems must only understand Delta, something in the lakehouse must understand the upstream data. At Databricks, we’ve worked with industry experts and partners to create solutions that handle some of the most commonly encountered formats. A few examples of these in healthcare and life sciences include:
- GLOW, a joint collaboration between Databricks and Regeneron Genetic Center, that makes ingestion and processing of common genomics formats scalable and easy, and is designed to make it easy to integrate genomics workflows within a broader data and AI ecosystem.
- SMOLDER is a scalable, Spark-based framework for ingestion and processing of HL7 data; it provides an easy-to-use interface for what is often a difficult and mutable format. It provides native readers and plugins so that consuming HL7 data is just as easy as consuming a CSV file.
Reusability: How can data be reused across multiple scenarios?
Reusability is a fickle subject; even companies who are already building on a lakehouse architecture are prone to missing out on this pillar. This is mostly because reusability is more than a technical problem -- it cuts to the core of the business, and forces us to ask hard questions. Is the business siloed? Is there a strong culture of cross-functional collaboration and teamwork? Do the leaders of R&D know how data is being used in manufacturing, and vice versa? A strong lakehouse cannot answer these questions or fix the structural issues that may underlie them, but it can provide a strong foundation to build upon.
Much of the value of the lakehouse is derived not from the ability to ingest, store, version or clean data -- rather, it comes from the ability to provide a single, centralized platform where all data, regardless of use case, can be processed, accessed and understood. The underlying pieces -- the data lake, Delta Lake, Delta Engine and catalog -- all serve to enable these use cases. Without strong use cases, no data platform, no matter how well-architected, will bring value.
We can’t possibly cover every data use case here, but hopefully this blog has given a brief overview of how Databricks enables more effective scientific data management and community standards. As a primer to some solutions we’ve seen on the lakehouse, here are some resources:
- Visit our Healthcare and Life Sciences pages to learn about our solutions and customers in this industry.
- Learn how Biogen is using the Databricks Lakehouse Platform to advance the development of novel disease therapies
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.