Managing Model Ensembles With MLflow
In machine learning, an ensemble is a collection of diverse models that provide more predictive power together than any single model would on its own. The outputs of multiple learning algorithms are combined through a process of averaging or voting, resulting in potentially a better prediction for a given set of inputs.
However, there are tradeoffs to the ensemble learning approach; each prediction becomes more difficult to ‘explain’ (model interpretability). In addition, this approach can increase engineering complexity, and it's often not immediately obvious how to manage ensemble models throughout their lifecycle. Apart from the fact that we are creating N different models, there are several additional concerns around their management such as:
- If one model changes, how does this impact the ensemble versioning?
- How do we detect model drift of an ensemble?
- How do we package the ensemble artifacts and maintain lineage?
This blog post walks through the process of creating and managing ensembles aided by MLflow and Databricks AutoML. If creating and productionizing a single model is hard, then doing the same for an ensemble of models is even harder! Since Databricks AutoML does the heavy lifting of creating all the models, we now have the opportunity of leveraging ensembles with far less effort. A simple stacking strategy using the top N models from some of the architecture types may outperform the single best model.
Ensembles
Some algorithms are natural ensembles (Random forest, AdaBoost), while others are combinations of decision trees and more traditional algorithms like logistic and linear regression. They can even extend into neural networks and deep learning scenarios. Since each algorithm has its own method of modeling the relationships in data, their ensemble can reduce overall variance and bias while improving accuracy.
There are several factors to consider while building an ensemble:
- What is the size of the dataset?
- How many models to include in the ensemble?
- How diverse are the individual models?
- How are multiple versions of the model maintained?
- How should they be packaged?
- Is the model reused across different use cases?
Ensembles usually perform better if there is a lot of variation in the data characteristics. Having a set of diverse learners will help in the overall prediction. However, there is a plateau point, beyond which adding models does not have much impact on the performance. Hence, it is important to balance the cost of creating and managing ensembles with the additional performance gains. Each sub-model in the ensemble will have its own life cycle. Some may have stronger inter-dependencies while others may be more stand-alone. So it is important to consider how the sub-models are trained and packaged for flexible reuse and upgrade.
Let’s take a look at a few use cases that benefit most from an ensemble strategy:
- Analyzing the ‘Voice of the Customer’ data
Complaint data needs to be addressed as per regulatory guidelines. This requires swift and accurate classification of the complaints as well as human intervention to redress. This data comes along with the regular customer chatter. While it is alright to respond to some customer queries at leisure, the ones which are labelled ‘legal’ or ‘regulatory’ need to be addressed immediately. This is an excellent candidate use case for ensembles as even a small accuracy boost has a magnified impact on business.
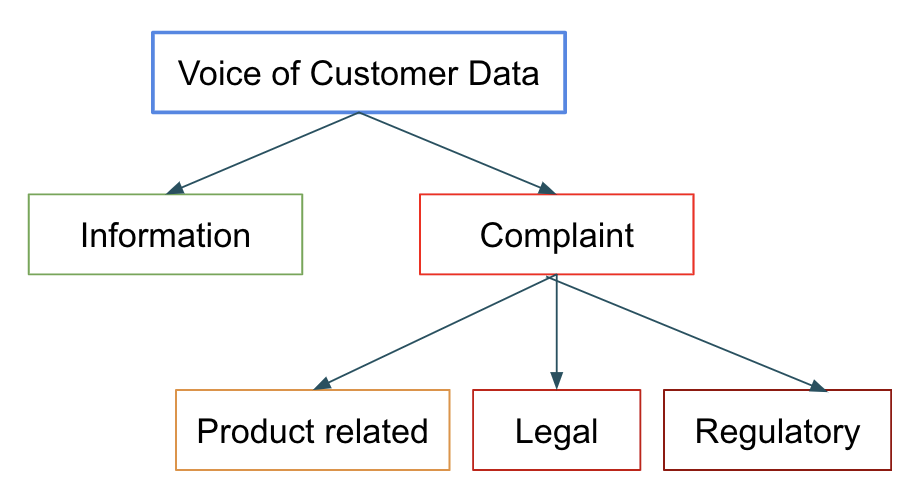
- Finding the best fit in a multi-classification scenario for product recommendations
Prescription data is analyzed to find the appropriate product SKU fit. Models at each layer take the data from the previous layer and refine the classification.
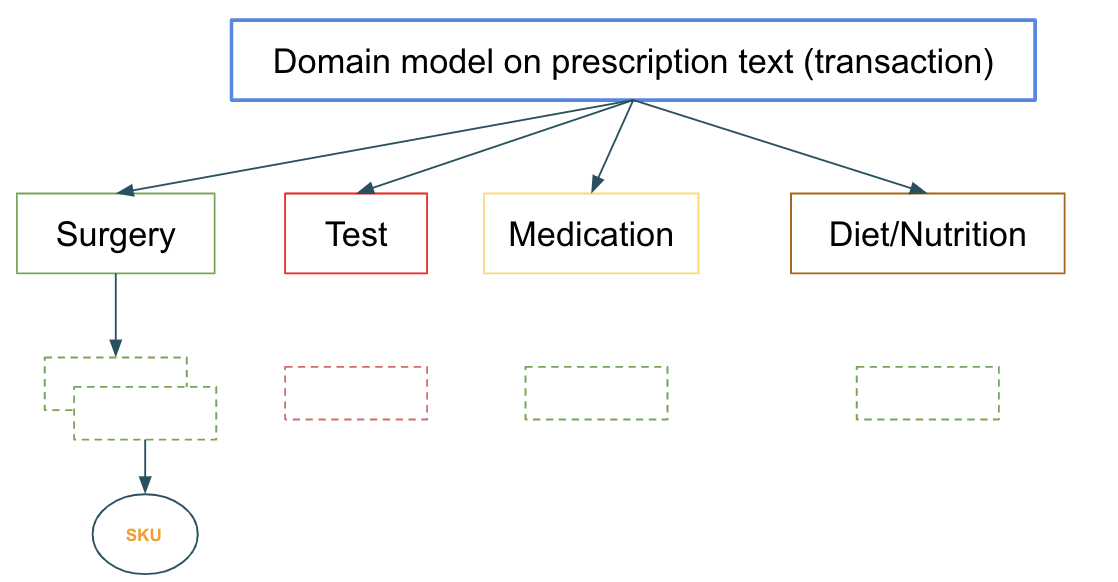
Once created and deployed, the model becomes a living artifact that needs to be managed. There are several challenges to consider while managing dependencies and versions of the ensemble and the individual sub-models. In addition, there are various stages(environments), and a model has to successfully perform at each stage to be promoted to the next higher one. It is further exacerbated when the model is part of an ensemble. Yet another level of complexity is if the model is shared by different use cases where the version across each use case may be different. So pulling the latest version from production may not be the right thing to do for all the dependent use cases.
Simplify ensemble creation and management with Databricks AutoML + MLflow
MLflow is an open source, scalable framework for end-to-end model management. It aids the entire MLOps cycle from artifact development all the way to deployment with reproducible runs.
An ML practitioner can either create models from scratch or leverage Databricks AutoML. For any set of models logged in MLflow, not only can you take the best one, but you could also see how well a combination of the top N models performs.
Databricks AutoML is a fully automated, glass box approach model development solution to democratize machine learning for rapid prototyping and using a selected dataset. Under the hood, it leverages MLflow. AutoML solves two key pain points for data scientists, namely quickly verifying the predictive power of a dataset and getting a baseline model to use as is or start refining and includes:
- Data pre-processing including Exploratory Data Analytics (EDA) notebooks.
- Feature engineering & selection.
- Automated training with hyperparameter tuning and tracking of each run with MLflow Tracking, aiding in the selection of the best model and registering in MLflow Registry.
It is not uncommon for data teams to spend a lot of time and effort to produce several models of different architecture types in pursuit of optimal model performance. With AutoML, the model creation process has been completely auto-generated, thereby simplifying the subsequent process of model selection.
AutoML currently supports both regression and classification and includes these phases:
- Configuration: This is where we specify the dataset, problem type, target or label column to predict, the metric for evaluating and scoring the experiment runs, and stopping conditions (such as number of trials or maximum amount of time to run)
- Training : Each ML training runs in an experiment that we can query and explore subsequently since all the details (code, parameters, metrics, models, artifacts) are logged.
- Evaluation: The top model based on our selection criteria is highlighted for scrutiny and subsequent registration. This is where we can use either the single best model (champion) or a combination of top models (challenger) if that outperforms the champion.
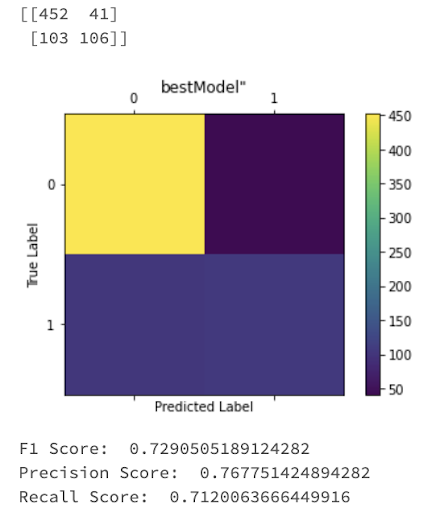
Let’s examine the kaggle telco dataset that is used to predict which customers may churn in the next round. Based on the selection criteria, AutoML recommends not only the single best model but also provides details on all the runs across all the model types. We’ll start by logging the recommended Best Model (Champion) in the MLflow model registry, along with the top models in each sub-category (Challengers)
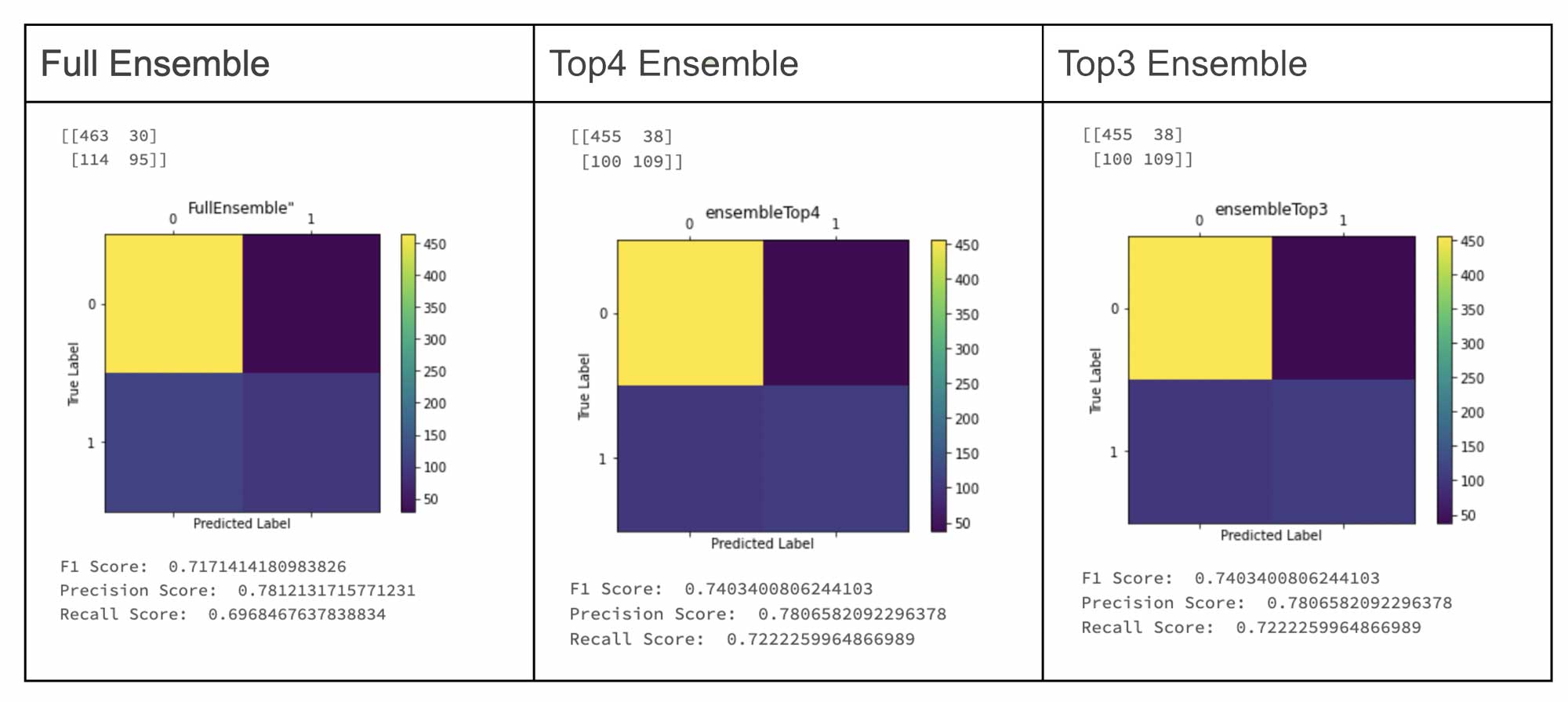
Using a test dataset, we compare the performance between the Champion and the Challengers in this notebook. In the case of the ensemble, a voting strategy was used for final classification. If the ensemble performance is significantly better, that can be the new champion model. Users have different options on how to consume the ensemble model, either individually or collectively.
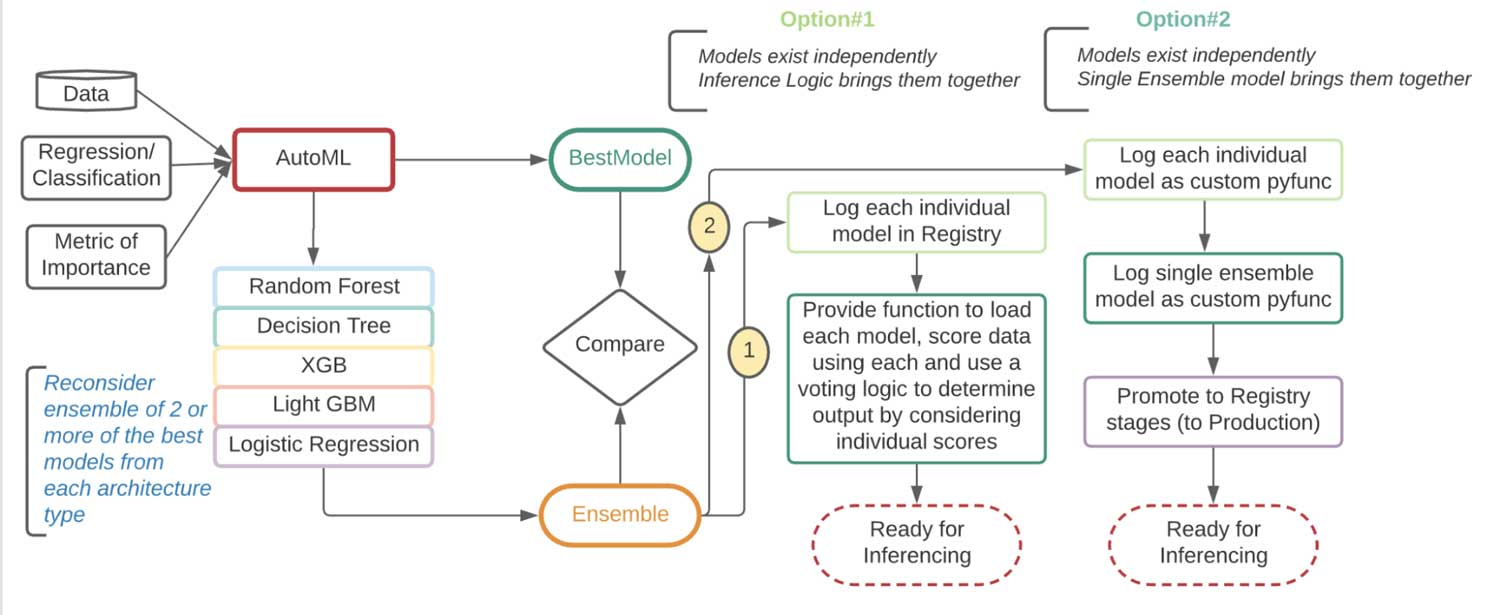
| Option #1 | Option #2 |
|
|
In this example, we opt for option #2, which entails logging each model independently and as a single ensemble wrapper model in MLflow.
The ensemble encapsulates all the independent models as a single pickle file. This allows us to deploy the ensemble as one artifact that has a life cycle of its own, separate from the individual contributing models, which can continue to evolve independently. This is very similar to shipping a docker container or an uber jar after combining relevant individual libraries.
Step #1: Fetch the "best" models of each architecture type from the AutoML experiment:
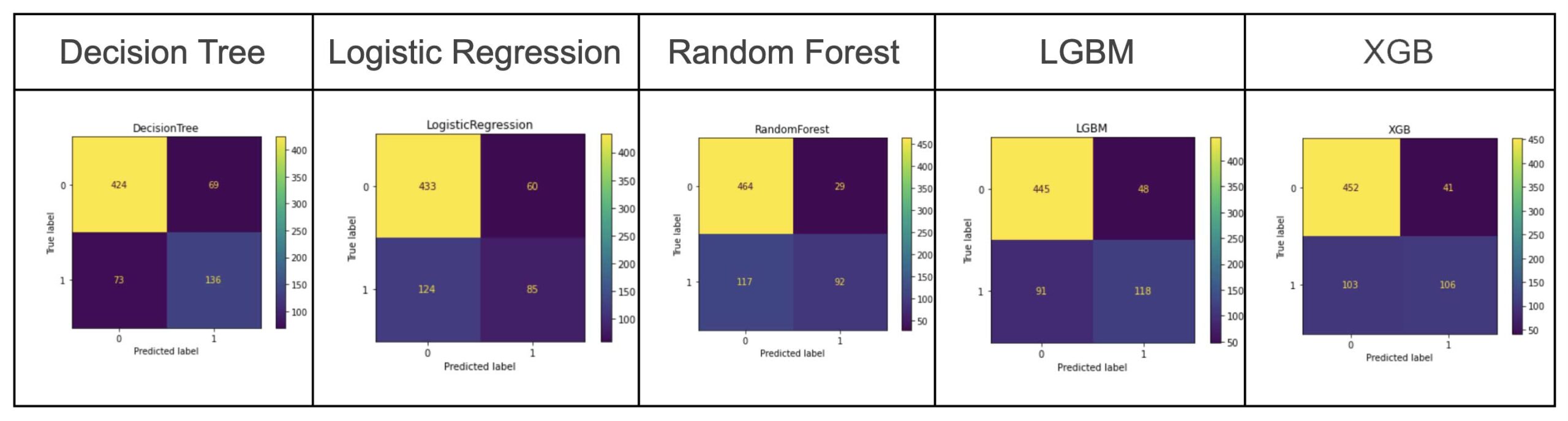
Figure: Best Models of each model type generated by AutoML
Step #2: Build a custom pyfunc model class that encapsulates the best models
This will pickle the different models along with the ensemble. The required functions for the ensemble class are the __init__, load_context, decide, ensembleTopN and predict methods – all of which will be fleshed further down.
Step #3: Provide a predict function for the ensemble
The predict function for any pyfunc model needs to fit the following paradigm, which is what will be used at inference time to score new data.
The predict function accepts data as a pandas dataframe and returns another pandas dataframe. This allows the model to be interoperable as a web API via MLflow model serving or via Apache Spark™ UDFs/pandas functions.
Step #4: Provide a voting function
The meat of the prediction is determined by the voting algorithm, which can have several variations. Here is an example with the simple approach of majority vote.
Step# 5: Package and log the model in MLflow as a custom pyfunc model
Provenance back to the encapsulated models needs to be maintained, and this is where the MLflow tracking server and parameters/tags are used to save the parent model URIs in the ensemble run.
This process becomes very easy to manage and version because there is a single artifact. If something in the pipeline is not functioning, there are significantly fewer moving parts, which make it easy to debug and validate before the model gets placed in the registry. This paradigm is very similar to shipping a sklearn pipeline, where the pipeline encapsulates all the transformations needed before the predictor. In the end, you also only need to manage just one registry for the prediction.
Step #6: Scoring
The model is now ready to score new data:
Nuances of ensembles
Multiple models do not necessarily mean an ensemble!
Let us consider the scenario of IoT data sent from different machines across several factories. Each machine has a different operating cycle, so it would be wrong to baseline them together. A model needs to be built per machine. The incoming data is filtered by the type of machine and an appropriate model is applied. Some may argue this is an ensemble. It is a divide-and-conquer approach but the data is trained/scored by a single model. Multiple models are not combined to improve accuracy; hence, this is not an ensemble scenario -- it is just N models. The voting strategy discussed earlier can, however, be used on the input data characteristics to invoke the right sub-model.
Summary
The ensemble method is a layering approach where moderately performant un-correlated models are combined to produce a supermodel that improves accuracy while improving stability and is often a divide and conquer strategy used in large, diverse datasets. Apart from the increased engineering complexity and manageability, there is often a tradeoff between accuracy and explainability, which is why people sometimes shy away from ensembles in production, although it is the preferred approach in Kaggle competitions. AutoML, with its inherent use of MLflow, comes to aid by automating and simplifying the creation and management of the underlying models, thereby helping ML practitioners to push the boundaries in their quest to extract value from data.
Related blogs:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.