Implementing MLOps on Databricks using Databricks notebooks and Azure DevOps, Part 2
by Piotr Majer and Michael Shtelma
This is the second part of a two-part series of blog posts that show an end-to-end MLOps framework on Databricks, which is based on Notebooks. In the first post, we presented a complete CI/CD framework on Databricks with notebooks. The approach is based on the Azure DevOps ecosystem for the Continuous Integration (CI) part and Repos API for the Continuous Delivery (CD). This post extends the presented CI/CD framework with machine learning providing a complete ML Ops solution.
The post is structured as follows:
- Introduction of the ML Ops methodology.
- Using notebooks in the development and deployment lifecycle.
- A detailed example that includes code snippets and showcases a complete pipeline with an ML-specific testing suite, version control and development, staging, and production environments.
Why do we need MLOps?
Artificial intelligence and machine learning are some of the biggest phenomena in the past two decades, changing and shaping our everyday life. This automated decision-making comes, however, with its own set of challenges and risks, and there is no free lunch here. Productionizing ML is difficult as it is not only underlying software changes that affect the output but even more, so a good quality model is powered by high-quality data.
Furthermore, versioning of data, code and models becomes even more difficult if an organization tries to apply it at a massive scale to really become an AI-first company. Putting a single machine learning model to use comes with completely different costs and risks than having thousands of models iterated and improved frequently. Therefore, a holistic approach is needed across the entire product lifecycle, from an early prototype to every single release, repeatedly testing multiple aspects of the end result and highlighting any issues prior to end-customer exposure. Only that practice lets teams and companies scale their operations and deliver high-quality autonomous systems. This development practice for data products powered by ML is called MLOps.
What is MLOps?
DevOps practices are a common IT toolbox and a philosophy that enables fast, iterative release processes for software in a reliable and performant manner. This de-facto standard for software engineering becomes much more challenging in Machine Learning projects, where there are new dimensions of complexity - data and derived model artifacts, that need to be accounted for. The changes in data, popularly known as drift, which may affect the models and model-related outputs, yield the birth of new terminology: MLOps.
In a nutshell, MLOps extends and profoundly inherits practices from DevOps, adding new tools and methodology that allow for the CI/CD process on the system, where not only code but also data changes. Thus the suite of tools needed addresses typical software development techniques but also adds similar programmatic and automated rigor to the underlying data.
Therefore, hand in hand with the growing adaptation of AI and ML across businesses and organizations, there is a growing need for best-in-class MLOps practices and monitoring. This essential functionality provides organizations with the necessary tools, safety nets, and confidence in automation solutions enabling them to scale and drive value. The Databricks platform comes equipped with all the necessary solutions as a managed service, allowing companies to automate and use ready technologies focusing on high-level business challenges.
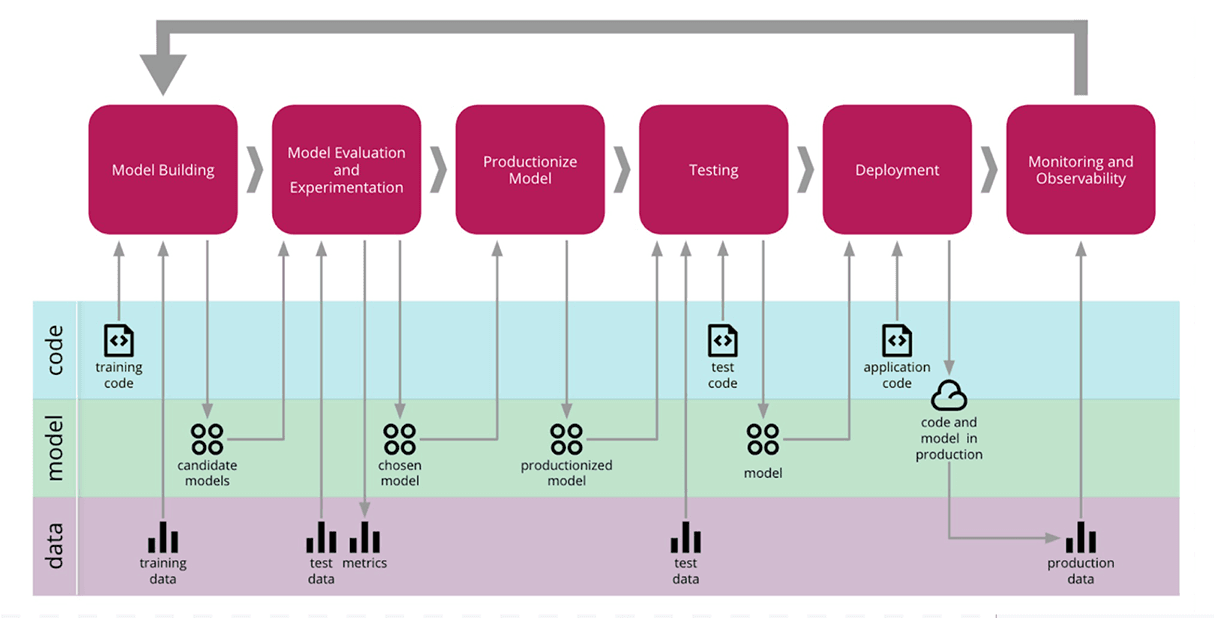
Why is it hard to implement MLOps using notebooks?
While notebooks have gained tremendous popularity over the past decade and have become synonymous with data science, there are still a few challenges faced by machine learning practitioners working in agile development. Most of the machine learning projects have their roots in notebooks, where one can easily explore, visualize and understand the data. Most of the coding starts in a notebook where data scientists can promptly experiment, brainstorm, build and implement a modeling approach in a collaborative and flexible manner. While historically, most of the hardening and production code had to be rewritten and reimplemented in IDEs, over the last few years, we have observed a sharp rise in using notebooks for production workloads. That is usually feasible whenever the code base has small and manageable interdependencies and mostly consumes libraries. In that case, teams can minimize and simplify the implementation time while keeping the code base transparent, robust, and agile in notebooks. One of the key reasons for that dramatic shift has been the growing wealth of CI/CD tools now at our disposal. Machine learning, however, adds another dimension of complexity to the CI/CD pipelines delivered in notebooks with multiple dependencies between modules/notebooks.
Continuous delivery and monitoring of ML projects
In the previous paragraph, we depicted a framework for testing our codebase, as well as testing and quality assurance of newly trained ML models -- MLOps. Now we can discuss how we use these tools to implement our ML project using the following principles:
- The model interface is unified. Establishing a common structure of each model, similarly to packages like scikit-learn with common .fit() and .predict() methods, is essential for the reusability of the framework for various ML techniques that can be easily interchanged. That allows us to start with potentially simpler baseline ML models in an end-to-end fashion and iterate with other ML algorithms without changing the pipeline code.
- Model training must be decoupled from evaluation and scoring and implemented as independent pipelines/notebooks. The decoupling principle makes the code base modular and allows us, again, to compare various ML architectures/frameworks with each other. This is an important part of MLOps, where we can easily evaluate various ML models and test the predictive power prior to promotion. Furthermore, the trained model persisted in MLflow can be easily reused in other jobs and frameworks, without dependency on the training/environment setup, e.g., deployed as a REST API service.
- Model scoring must be able to always rely on a model repository to get the latest approved version of our model. This, in conjunction j with the MLOps framework, where only tested and well-performing models are promoted, ensures the right, high-quality model version is being deployed in a fully-automated fashion to our production environment while keeping the training pipeline proposing new models regularly using new data inputs.
We can fulfill the requirements defined earlier by using the architecture depicted in the following illustration:
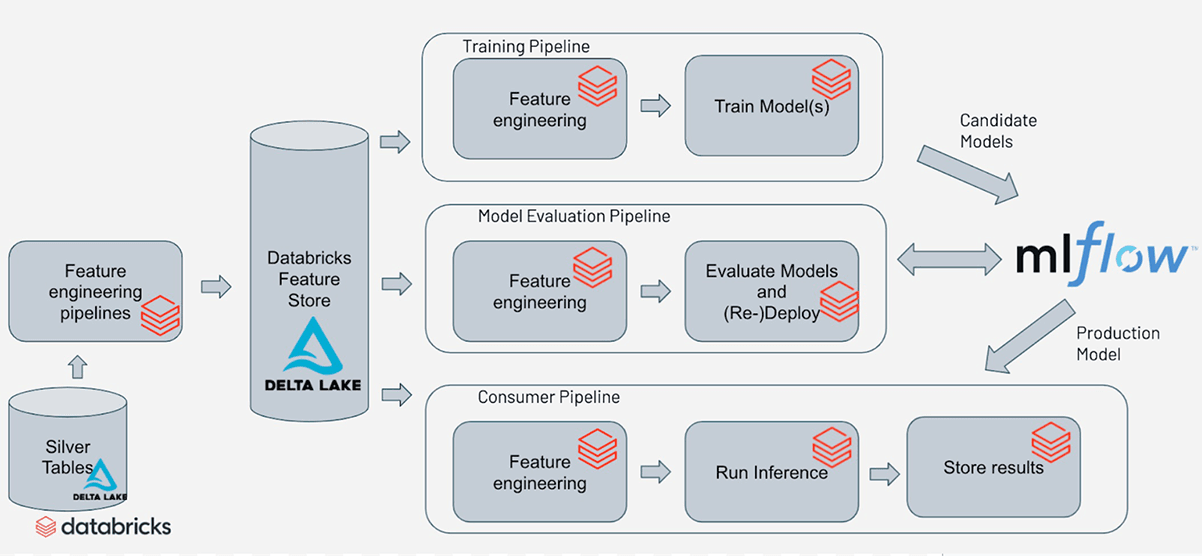
As depicted above, the training pipeline (you can review the code here) trains models and logs them to MLflow. We can have multiple training pipelines for different model architectures or different model types. All models trained by these pipelines can be logged to MLflow and used for scoring using a unified MLflow interface. The evaluation pipeline (you can review the code here) can then be run after every training pipeline and be used at the outset to compare all these new models against one another. In this way, the candidate models can be evaluated against the current production model too. An example of the ideal evaluation pipeline, implemented using MLFlow, is discussed below.
Let's implement model comparison and selection!
We will need a couple of building blocks to implement the full functionality, which we will place into individual functions. The first one will allow us to get all the newly trained models from our MLflow training pipelines. To do this, we will leverage the MLflow-experiment data source that allows us to use Apache Spark™ to query MLflow experiment data. Having MLflow experiment data available as a Spark dataframe makes the job really easy:
To compare models, we will need to come up with some metrics first. This is usually case specific and should be aligned to business requirements. The functions shown below load the model using run_id from the MLflow experiment and calculate the predictions using the latest available data. For a more robust evaluation, we apply bootstrapping and derive multiple metrics for samples drawn, with repetition from the original evaluation set. Then it calculates the ROC AUC metric for each randomly drawn set that will be used to compare the models. If the candidate model outperforms the current version on at least 90% of samples, it is then promoted to production. In an actual project, this metric must be selected carefully.
Now let's put all these building blocks together and see how we can evaluate all new models and compare the best new model with the ones in production. After determining the best newly trained model, we will leverage the MLflow API to load all production model versions and compare them using the same function that we have used to compare newly trained models.
After that, we can compare the metrics of the best production model and the new one and decide whether or not to put the latest model to production. In the case of a positive decision, we can leverage MLflow Model Registry API to register our best newly-trained model as a registered model and promote it to a production state.
Summary
In this blog post, we presented an end-to-end approach for MLOps on Databricks using notebook-based projects. This machine learning workflow is based on the Repos API functionality that not only lets the data teams structure and version control their projects in a more practical way but also greatly simplifies the implementation and execution of the CI/CD tools. We showcased an architecture where all operational environments are fully isolated, ensuring a high degree of security for production workloads powered by ML. An exemplary workflow was discussed that spans all steps in the model lifecycle with a strong focus on an automated testing suite. These quality checks may not only cover typical software development steps (unit, integration, etc.) but also focus on the automated evaluation of any new iteration of the retrained model. The CI/CD pipelines are powered by a framework of choice and integrate with the Databricks Lakehouse platform smoothly, triggering execution of the code and infrastructure provisioning end-to-end. Repos API radically simplifies not only the version management, code structuring, and development part of a project lifecycle but also the Continuous Delivery, allowing to deploy the production artifacts and code between environments. It is an important improvement that adds to the overall efficiency and scalability of Databricks and greatly improves software developer experience.
References:
- Github repository with implemented example project: https://github.com/mshtelma/databricks_ml_demo/
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.html
- Part 1: Implementing CI/CD on Databricks Using Databricks Notebooks and Azure DevOps, https://www.databricks.com/blog/2021/09/20/part-1-implementing-ci-cd-on-databricks-using-databricks-notebooks-and-azure-devops.html
- Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.