Streaming Windows Event Logs into the Cybersecurity Lakehouse
An architecture for endpoint log collection into the delta lake
by Derek King
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Streaming windows events into the Cybersecurity Lakehouse
Enterprise customers often ask, what is the easiest and simplest way to send Windows endpoint logs into Databricks in real time, perform ETL and run detection searches for security events against the data. This makes sense. Windows logs in large environments must be monitored but can be very noisy and consume considerable resources in traditional SIEM products. Ingesting system event logs into Delta tables and performing streaming analytics has many cost and performance benefits.
This blog focuses on how organizations can collect Windows event logs from endpoints, directly into a cybersecurity lakehouse. Specifically, we will demonstrate how to create a pipeline for Microsoft sysmon process events, and transform the data into a common information model (CIM) format that can be used for downstream analytics.
"How can we ingest and hunt windows endpoints at scale, whilst also maintaining our current security architecture?"Curious Databricks Customer
Proposed architecture
For all practical purposes, Windows endpoint logs must be shipped via a forwarder into a central repository for analysis. There are many vendor-specific executables to do this, so we have focused on the most universally applicable architecture available to everyone, using winlogbeats and a Kafka cluster. The elastic winlogbeats forwarder has both free and open source licensing, and Apache Kafka is also an open-source distributed event streaming platform. You can find a sample configuration file for both in the notebook or create your own specific configuration for Windows events using the winlogbeats manual. If you want to use a Kafka server for testing purposes, I created a github repository to make it easy. You may need to make adjustments to this architecture if you use other software.
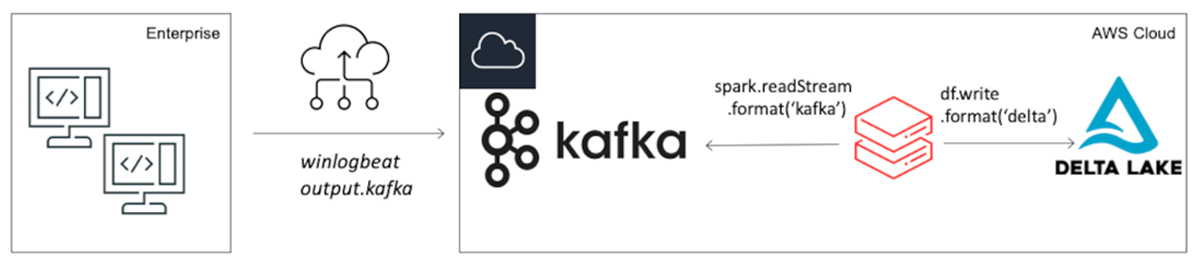
The data set
We have also installed Microsoft system monitor (sysmon) due to its effectiveness for targeted collection used for security use cases. We will demonstrate how to parse the raw JSON logs from the sysmon/operational log and apply a common information model to the most relevant events. Once run, the notebook will produce silver level Delta Lake tables for the following events.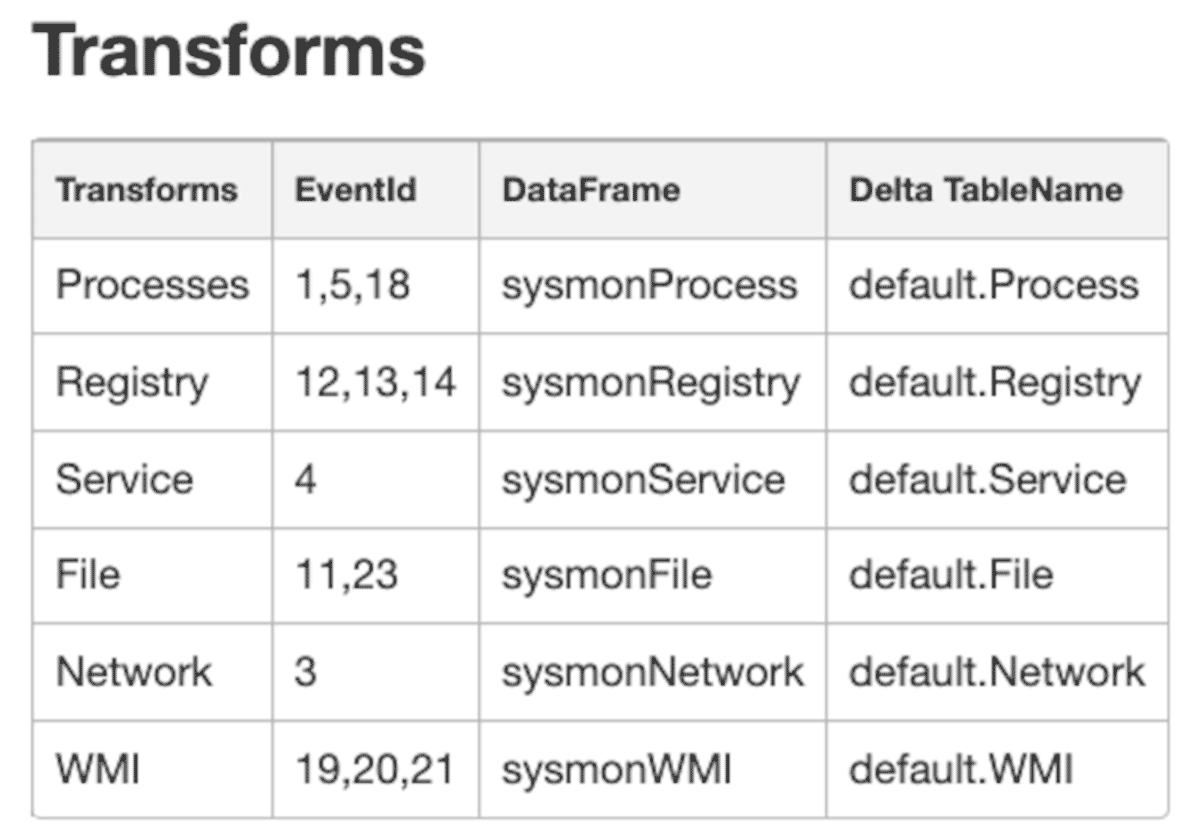
Using the winlogbeats configuration file in the notebook, endpoints will also send WinEventLog:Security, WinEventLog:System, WinEventLog:Application, Windows Powershell and WinEventLog:WMI log files, which can also be used by the interested reader.
Ingesting the data set through Kafka
You may be forgiven for thinking that getting data out of Kafka and into Delta Lake is a complicated business! However, it could not be simpler. With Apache Spark™, the Kafka connector is ready to go and can stream data directly into Delta Lake using Spark Streaming.
Tell spark.readStream to use the apache spark Kafka connector, located atkafka.bootstrap.servers
ip address. subscribe to the topic that the windows events arrive on, and you are off to the races!
For readability, we'll show only the most prevalent parts of the code, however, the full notebook can be downloaded using the link at the bottom of the article, including a link to a community edition of Databricks if required.
Using the code above we read the raw Kafka stream using the read_kafka_topic function, and apply some top level extractions, primarily used to partition the bronze level table.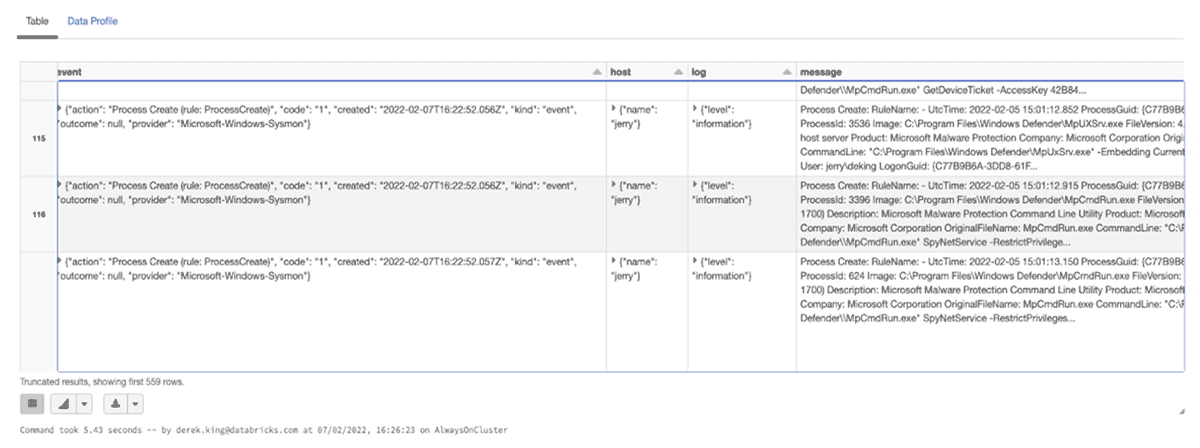
This is a great start. Our endpoint is streaming logs in real time to our Kafka cluster and into a Databricks dataframe. However, it appears we have some more work to do before that dataframe is ready for analytics!
Taking a closer look, the event_data field is nested in a struct, and looks like a complex json problem.

Before we start work transforming columns, we write the data frame into the bronze level table, partitioned by _event_date, and _sourcetype. Choosing these partition columns will allow us to efficiently read only the log source we need when filtering for events to apply our CIM transformations on.
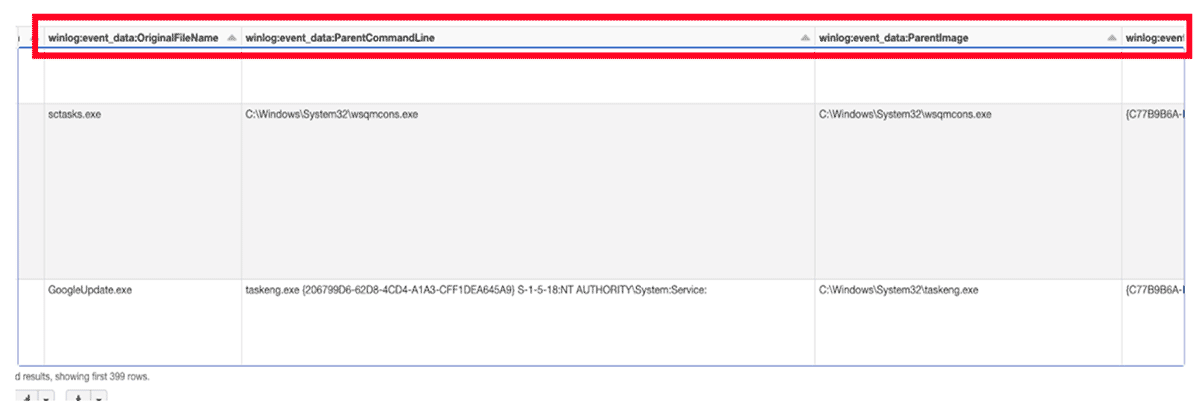
The above data frame is the result of reading back the bronze table, flattening the columns and filtering for only process related events (process start, process end and pipe connected).
With the flattened column structure and a filtered data frame consisting of process related events, the final stage is to apply a data dictionary to normalize the field names. For this, we use the OSSEM project naming format, and apply a function that takes the input dataframe, and a transformation list, and returns the final normalized dataframe.
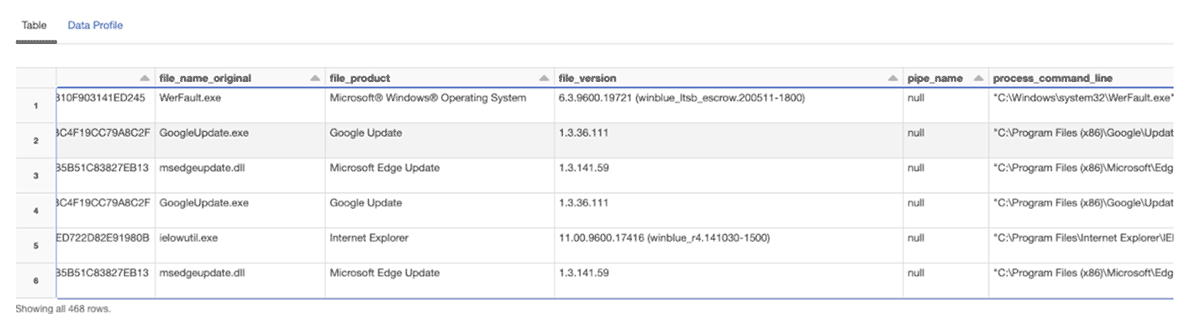
The resulting data frame has been normalized to be CIM compliant and has been written to a silver table, partitioned by _event_date. Silver level tables are considered suitable for running detection rules against. et-voila!
Optionally, a good next step to increase the performance of the silver table, would be to z-order it based on the columns most likely used for filtering on. The columns process_name and event_id would be good candidates. Similarly applying a bloom filter based on the user_name column would speed up read activity when doing entity based searches. An example below.
Conclusion
We have seen how to create a scalable streaming pipeline from enterprise endpoints that contains complex structures, directly into the lakehouse. This offers two major benefits. Firstly, the opportunity for targeted but often noisy data that can be analyzed downstream using detection rules, or AI for threat detection. Secondly the ability to maintain granular levels of historic endpoint data using Delta tables in cost effective storage, for long term retention and look backs if and when required.
Look out for future blogs, where we will dive deeper into some analytics using these data sets. Download the full notebook and a preconfigured Kafka server to get started streaming Windows endpoint data into the lakehouse today! If you are not already a Databricks customer, feel free to spin up a Community Edition from here too.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.