Design Patterns for Real-time Insights in Financial Services
Streaming Foundations for Personalization
Personalization is a competitive differentiator for most every financial services institution (FSIs, for short), from banking to insurance and now investment management platforms. While every FSI wants to offer intelligent and real-time personalization to customers, the foundations are often glossed over or implemented with incomplete platforms, leading to stale insights, long time-to-market, and loss of productivity due to the need to glue streaming, AI, and reporting services together.
This blog will demonstrate how to lay a robust foundation for real-time insights for financial services use cases with the Databricks Lakehouse platform, from OLTP database Change Data Capture (CDC) data to reporting dashboard. Databricks has long supported streaming, which is native to the platform. The recent release of Delta Live Tables (DLT) has made streaming even simpler and more powerful with new CDC capabilities. We have covered a guide to CDC using DLT in a recent comprehensive blog. In this blog, we focus on streaming for FSIs and show how these capabilities help streamline new product differentiators and internal insights for FSIs.
Why streaming ingestion is critical
Before getting into technical details, let’s discuss why Databricks is best for personalization use cases, and specifically why implementing streaming should be the first step. Many Databricks customers who are implementing Customer 360 projects or full-funnel marketing strategies typically have the base requirements below. Note the temporal (time-related) data flow.
FSI Data Flow and Requirements
- User app saves and updates data such as clickstream, user updates, and geolocation data - requires operational databases
- Third party behavioral data is delivered incrementally via object storage or is available in a database in a cloud account - requires streaming capabilities to incrementally add/update/delete new data in single source of truth for analytics
- FSI has an automated process to export all database data including user updates, clickstream, and user behavioral data into data lake - requires Change Data Capture (CDC) ingestion and processing tool, as well as support for semi-structured and unstructured data
- Data engineering teams run automated data quality checks and ensure the data is fresh - requires data quality tool and native streaming
- Data science teams use data for next best action or other predictive analytics - requires native ML capabilities
- Analytics engineers and Data analysts will materialize data models and use data for reporting - requires dashboard integration and native visualization
The core requirements here are data freshness for reporting, data quality to maintain integrity, CDC ingestion, and ML-ready data stores. In Databricks, these map directly to Delta Live Tables (notably Auto Loader, Expectations, and DLT’s SCD Type I API), Databricks SQL, and Feature Store. Since reporting and AI-driven insights depend upon a steady flow of high-quality data, streaming is the logical first step to master.

Consider, for example, a retail bank wanting to use digital marketing to attract more customers and improve brand loyalty. It is possible to identify key trends in customer buying patterns and send personalized communication with exclusive product offers in real time tailored to the exact customer needs and wants. This is a simple, but an invaluable use case that's only possible with streaming and change data capture (CDC) - both capabilities required to capture changes in consumer behavior and risk profiles.
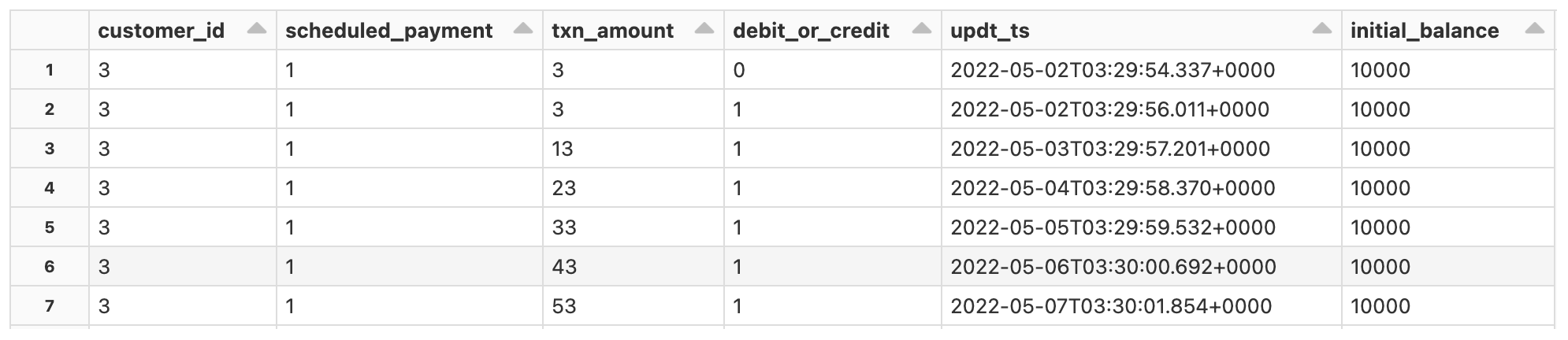
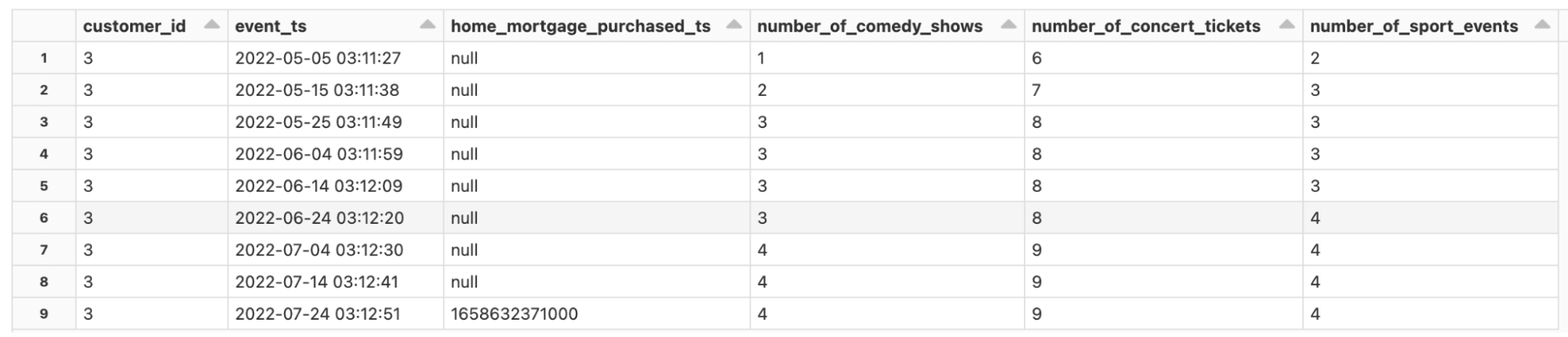
For a sneak peak at the types of data we handle in our reference DLT pipeline, see the samples below. Notice the temporal nature of the data - all banking or lending systems have time-ordered transactional data, and a trusted data source means having to incorporate late-arriving and out-of-order data. The core datasets shown include transactions from, say, a checking account (Figure 2), customer updates, but also behavioral data (Figure 3) which may be tracked from transactions or upstream third-party data.
Getting started with Streaming
In this section, we will demonstrate a simple end-to-end data flow so that it is clear how to capture continuous changes from transactional databases and store them in a Lakehouse using Databricks streaming capabilities.
Our starting point are records mocked up from standard formats from transactional databases. The diagram below provides an end-to-end picture of how data might flow through an FSI’s infrastructure, including the many varieties of data which ultimately land in Delta Lake, are cleaned, and summarized and served in a dashboard. There are three main processes mentioned in this diagram, and in the next section we'll break down some prescriptive options for each one.
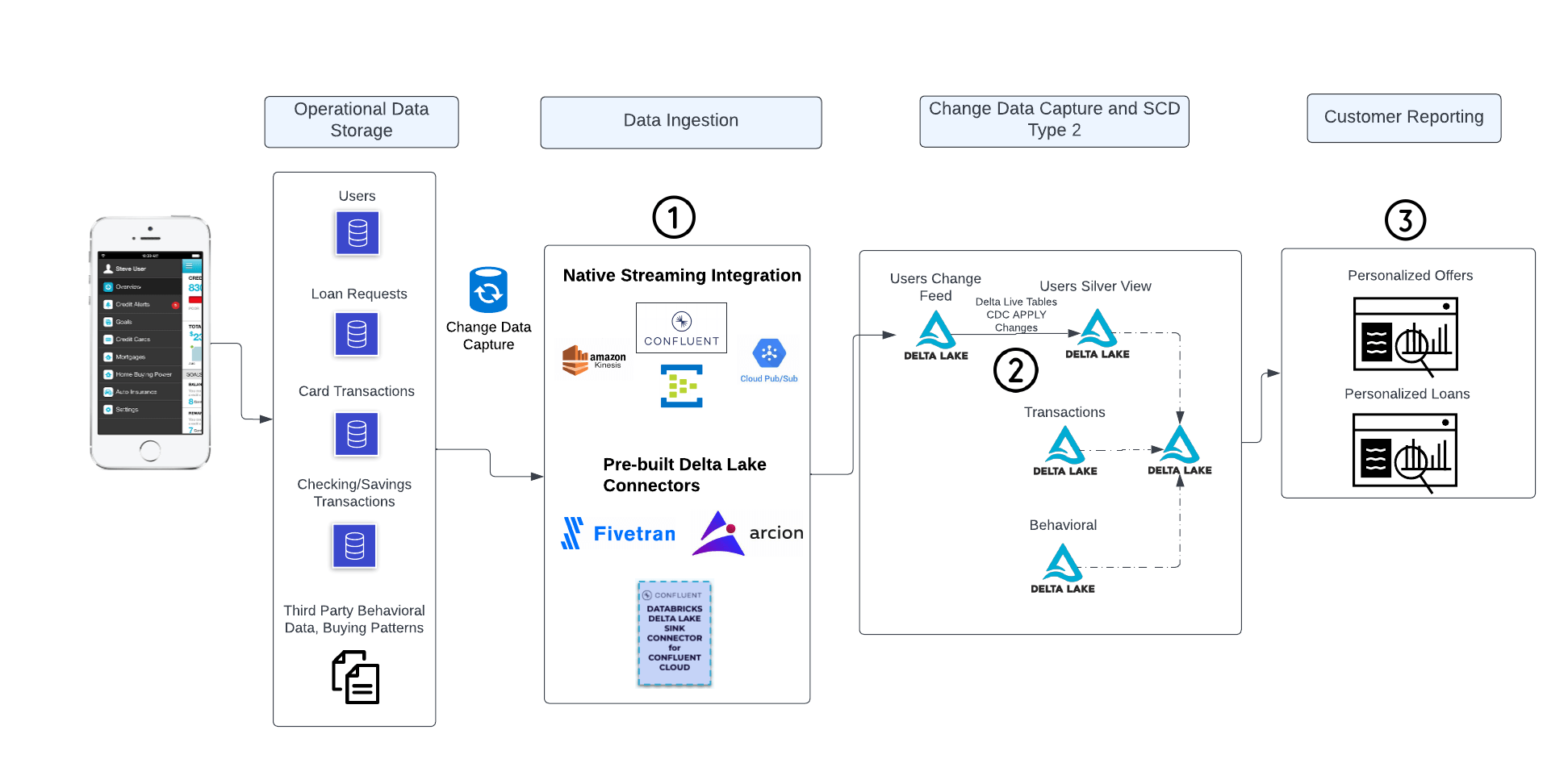
Process #1 - Data ingestion
Native structured streaming ingestion option
With the proliferation of data that customers provide via banking and insurance apps, FSIs have been forced to devise strategies around collecting this data for downstream teams to consume for various use cases. One of the most basic decisions these companies face is how to capture all changes from app services which customers have in production: from users, to policies, to loan apps and credit card transactions. Fundamentally, these apps are backed by transactional data stores, whether it’s MySQL databases or more unstructured data residing in NoSQL databases such as MongoDB.
Luckily, there are many open source tools, like Debezium, that can ingest data out of these systems. Alternatively, we see many customers writing their own stateful clients to read in data from transactional stores, and write to a distributed message queue like a managed Kafka cluster. Databricks has tight integration with Kafka, and a direct connection along with a streaming job is the recommended pattern when the data needs to be as fresh as possible. This setup enables near real-time insights to businesses, such as real-time cross-sell recommendations or real-time views of loss (cash rewards effect on balance sheets). The pattern is as follows:
- Set up CDC tool to write change records to Kafka
- Set up Kafka sink for Debezium or other CDC tool
- Parse and process Change Data Capture (CDC) records in Databricks using Delta Live Tables, first landing data directly from Kafka into Bronze tables
Considerations
Pros
- Data arrives continuously with lower latencies, so consumers get results in near real-time without relying on batch updates
- Full control of the streaming logic
- Delta Live Tables abstracts cluster management away for the bronze layer, while enabling users to efficiently manage resources by offering auto-scaling
- Delta Live Tables provides full data lineage, and seamless data quality monitoring for the landing into bronze layer
Cons
- Directly reading from Kafka requires some parsing code when landing into the Bronze staging layer
- This relies on extra third party CDC tools to extract data from databases and feed into a message store rather than using a tool that establishes a direct connection
Partner ingestion option
The second option for getting data into a dashboard for continuous insights is Databricks Partner Connect, the broad network of data ingestion partners that simplify data ingestion into Databricks. For this example, we'll ingest data via a Delta connector created by Confluent, a robust managed Kafka offering which integrates closely with Databricks. Other popular tools like Fivetran & Arcion have hundreds of connectors to core transactional systems.

Both options abstract away much of the core logic for reading raw data and landing it in Delta Lake through the use of COPY INTO commands. In this pattern, the following steps are performed:
- Set up CDC tool to write change records to Kafka (same as before)
- Set up the Databricks Delta Lake Sink Connector for Confluent Cloud and hook this up to the relevant topic
The main difference between this option and the native streaming option is the use of Confluent’s Delta Lake Sink Connector. See the trade-offs for understanding which pattern to select.
Considerations
Pros
- Low-code CDC through partner tools supports high speed replication of data from on-prem legacy sources, databases, and mainframes (e.g. Fivetran, Arcion, and others with direct connection to databases)
- Low-code data ingestion for data platform teams familiar with streaming partners (such as Confluent Kafka) and preferences to land data into Delta Lake without the use of Apache Spark™
- Centralized management of topics and sink connectors in Confluent Cloud (similarly with Fivetran)
Cons
- Less control over data transformation and payload parsing with Spark and third party libraries in the initial ETL stages
- Databricks cluster configuration required for the connector
File-based ingestion
Many data vendors — including mobile telematics providers, tick data providers, and internal data producers — may deliver files to clients. To best handle incremental file ingestion, Databricks introduced Auto Loader, a simple, automated streaming tool which tracks state for incremental data such as intraday feeds for trip data, trade-and-quote (TAQ) data, or even alternative data sets such as sales receipts to predict earnings forecasts.
Auto Loader is now available to be used in the Delta Live Tables pipelines, enabling you to easily consume hundreds of data feeds without having to configure lower level details. Auto Loader can scale massively, handling millions of files per day with ease. Moreover, it is simple to use within the context of Delta Live Tables APIs (see SQL example below):
Process #2 - Change Data Capture
Change Data Capture solutions are necessary since they ultimately save changes from core systems to a centralized data store without imposing additional stress on transactional databases. With abundant streams of digital data, capturing changes to customers' behavior are paramount to personalizing the banking or claims experience.
From a technical perspective, we are using Debezium as our highlighted CDC tool. Of importance to note is the sequence key, which is Debezium’s datetime_updated epoch time, which Delta Live Tables (DLT) uses to sort through records to find the latest change and apply to the target table in real time. Again, because a user journey has an important temporal component, the APPLY CHANGES INTO functionality from DLT is an elegant solution since it abstracts the complexity of having to update the user state - DLT simply updates the state in near real-time with a one-line command in SQL or Python (say, updating customer preferences in real-time from 3 concert events attended to 5, signifying an opportunity for a personalized offer).
In the code below, we are using SQL streaming functionality which allows us to specify a continuous stream landing into a table to which we apply changes to see the latest customer or aggregate update. See the full pipeline configuration below. The full code is available here.
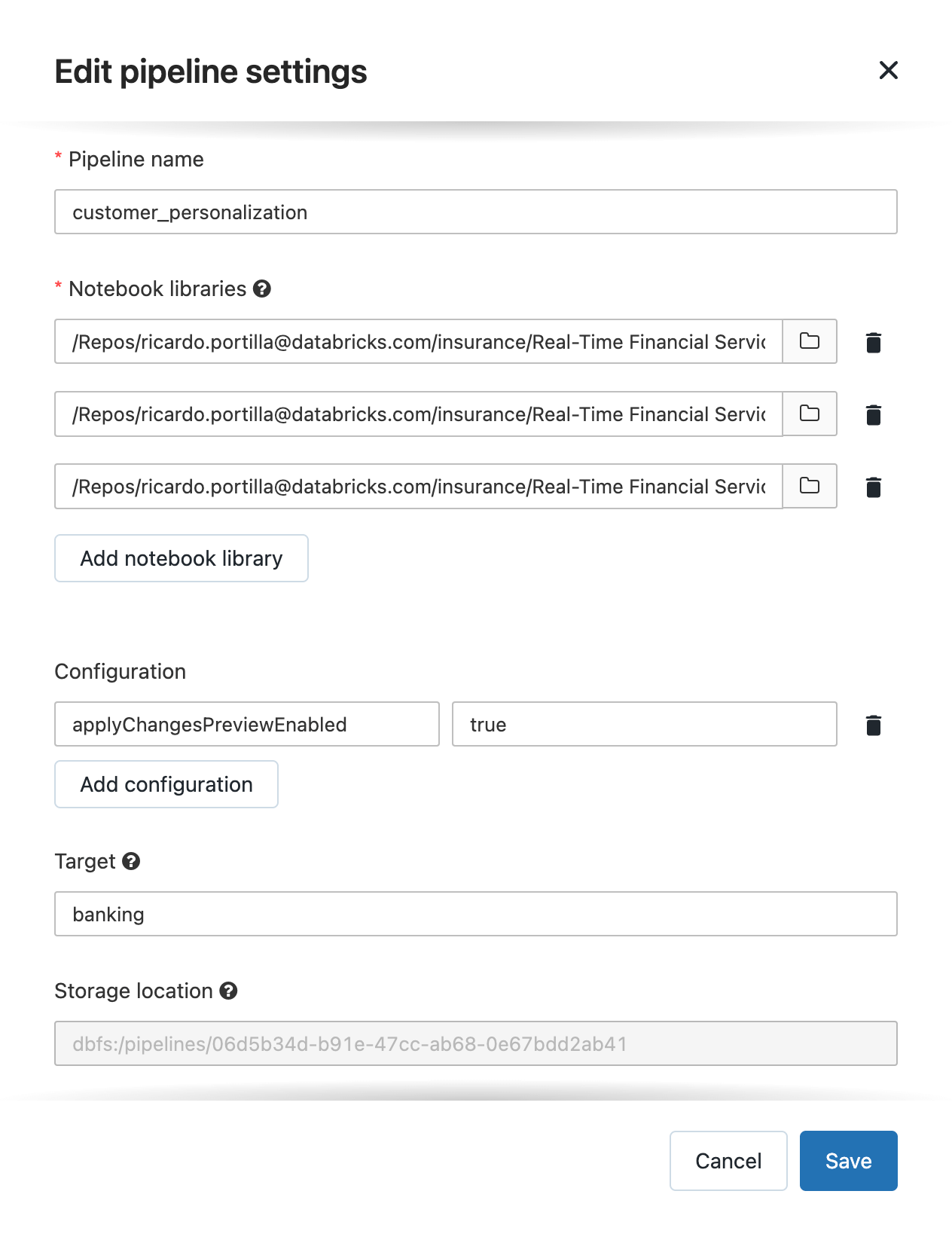
Here are some basic terms to note:
- The
STREAMINGkeyword indicates a table (like customer transactions) which accept incremental insert/updates/deletes from a streaming source (e.g. Kafka) - The
LIVEkeyword indicates the dataset is internal, meaning it has already been saved using the DLT APIs and comes with all the auto-managed capabilities (including auto-compaction, cluster management, and pipeline configurations) that DLT offers APPLY CHANGES INTOis the elegant CDC API that DLT offers, handling out-of-order and late-arriving data by maintaining state internally — without users having to write extra code or SQL commands.
Process #3 - Summarizing Customer Preferences and Simple Offers
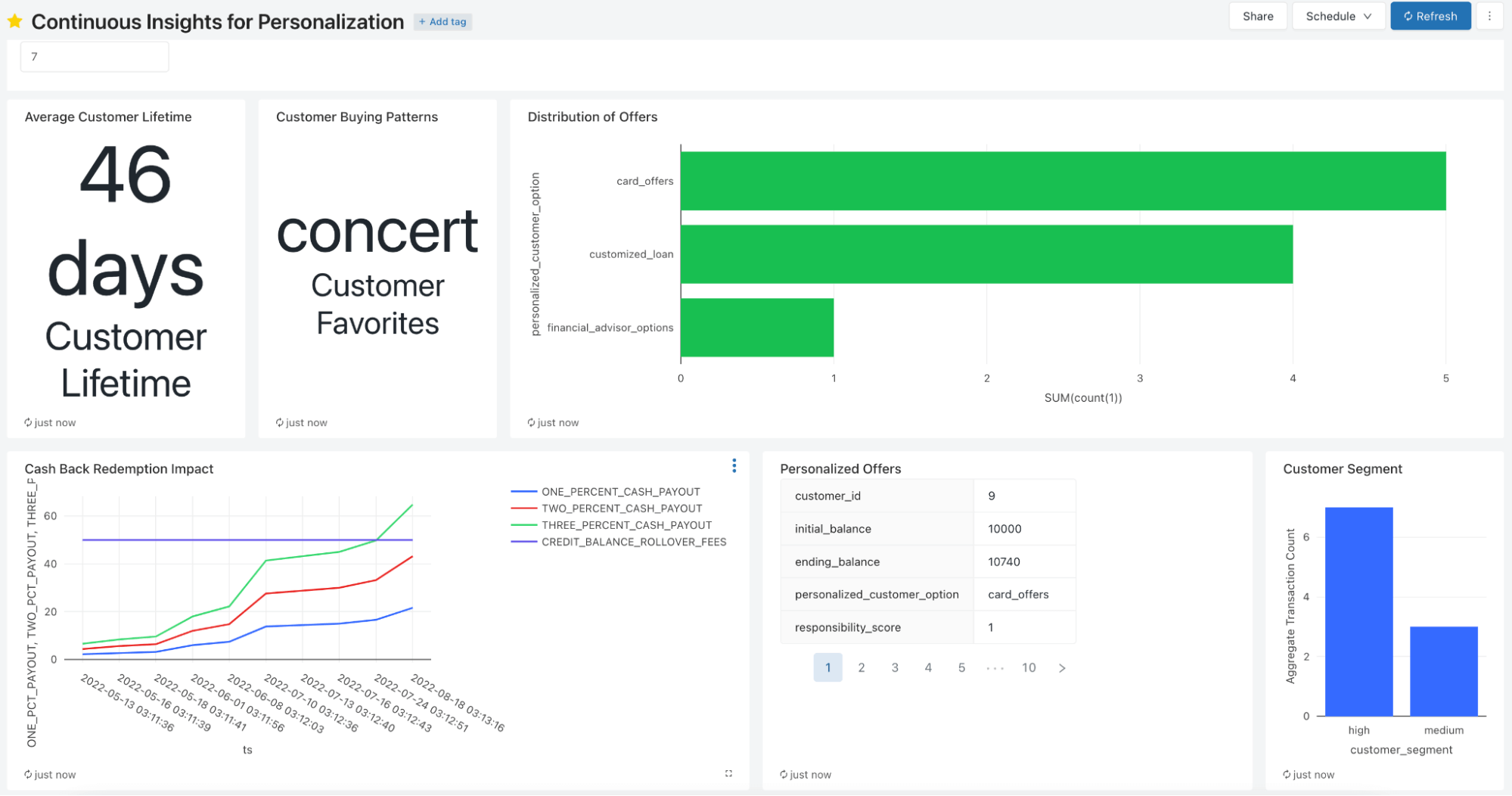
To cap off the simple ingestion pipeline above, we now highlight a Databricks SQL dashboard to show what types of features and insights are possible with the Lakehouse. All of the metrics, segments, and offers seen below are produced from the real-time data feeds mocked up for this insights pipeline. These can be scheduled to refresh every minute, and more importantly, the data is fresh and ML-ready. Metrics to note are customer lifetime, prescriptive offers based on a customer’s account history and purchasing patterns, and cash back losses and break even thresholds. Simple reporting on real-time data can highlight key metrics that will inform how to release a specific product, such as cash back offers. Finally, reporting dashboards (Databricks or BI partners such as Power BI or Tableau) can surface these insights; when AI insights are available, they can easily be added to such a dashboard since the underlying data is centralized in one Lakehouse.
Conclusion
This blog highlights multiple facets of the data ingestion process, which is important to support various personalization use cases in financial services. More importantly, Databricks supports near real-time use cases natively, offering fresh insights and abstracted APIs (Delta Live Tables) for handling change data, supporting both Python and SQL out-of-the-box.
With more banking and insurance providers incorporating more personalized customer experiences, it will be critical to support the model development but more importantly, create a robust foundation for incremental data ingestion. Ultimately, Databricks' Lakehouse platform is second-to-none in that it delivers both streaming and AI-driven personalization at scale to deliver higher CSAT/NPS, lower CAC/churn, and happier and more profitable customers.
To learn more about the Delta Live Tables methods applied in this blog, find all the sample data and code in this GitHub repository.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.