How ActionIQ Integrates with the Databricks Lakehouse Part One: Enable Personalization Without Data Replication
by Sophie Wang and Bryan Smith

The Personalization Paradigm: Balancing Business Self-Service and Data Governance
Personalization transforms businesses, shaping and reshaping the way brands connect with their audiences. Its impact reaches across industries, particularly in the crowded retail market landscape where consumer habits undergo dramatic shifts. Research conducted by McKinsey & Company indicates that brands unlock a remarkable 40% increase in revenue with personalization. As the demand for personalized experiences continues to soar, companies that implement personalization across customer lifecycles will thrive.
The key to delivering personalization lies in how organizations utilize customer data. A 360-degree view of the customer, assembled from data from every touchpoint and extended through third-party and partner data sources, provides marketing teams with the information they need to identify target customers and tailor content and offers to their needs and interests.
But a 360-degree view is not enough. Marketing teams require access to low-code and no-code user interfaces that facilitate their workflows. This functionality is typically provided through a Customer Data Platform (CDP), which also includes capabilities for integrating and managing customer data. These data-oriented capabilities may appear to be at odds with many organization's stated direction of managing their information assets through a unified data platform such as the Databricks Lakehouse. However, due to the differing functional alignment of these two systems, organizations often find it necessary to implement both a CDP and data platform in parallel.
The challenges of this parallel implementation extend beyond the overhead of implementing two separate systems. Quite often the information assets required by one are also needed by the other. Marketing teams operating in the CDP often rely on their data engineers and data scientists working in the lakehouse to assist with various data processing and analytic needs. This leads to data replication, which adds to the operational burden of the environment and complicates consistent governance and protection of customer data.
Synergy Between the Lakehouse and ActionIQ's Composable CDP
Today, ActionIQ provides multiple architecture options for integrating with Databricks, enabling organizations using the Databricks Lakehouse to consolidate the data backend while granting business access to the user experiences necessary for driving personalized engagement. To learn more about the different integration patterns for ActionIQ with the Databricks Lakehouse, please check out our joint paper on this topic.
What sets ActionIQ apart from other CDP vendors is its unique ability to run its composable CDP from within the Databricks Lakehouse, powered by ActionIQ's HybridCompute technology. Unlike the bundled architecture where CDP and lakehouse are implemented independently of each other, this innovative approach achieves a deeper integration between the two systems. It allows organizations to leverage information in the Databricks Lakehouse as if it were resident from within the ActionIQ composable CDP. Specifically, user actions in the CDP can trigger native query pushdown to Databricks Lakehouse, eliminating the need to copy or move data and providing a single, consistent point of data governance and security.
An Example Workflow: Retail Brands Operationalize Propensity Models With a User-Friendly UI
To illustrate how organizations can deploy ActionIQ's composable CDP directly within the Databricks Lakehouse environment, we have envisioned a simple workflow. In this workflow, customer loyalty data of a retail brand is used to score customers based on their likelihood to purchase items in different product categories aligned with content and promotional offers the marketing team wishes to employ. These propensity scores, with values ranging from 0.0 to 1.0, represent the probability of a customer making a purchase from a specific product category within the next 30 days. The scores are calculated and recorded in a table residing in the Databricks Lakehouse (Figure 1). (Please see this blog for detailed information on how exactly these scores are calculated within Databricks.)
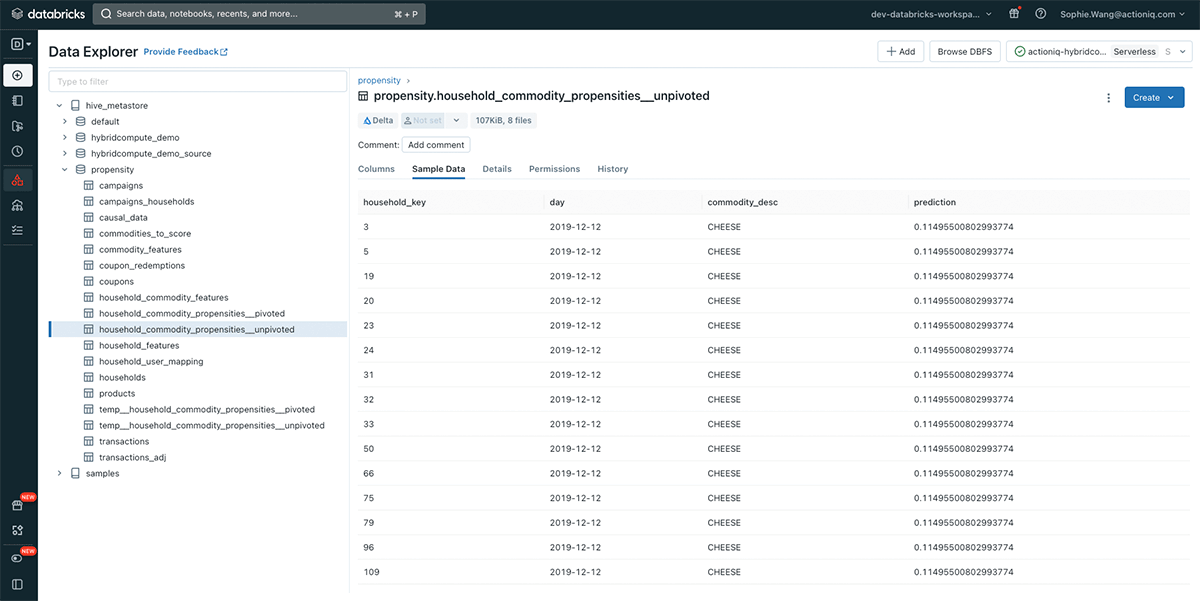
Using this information, the marketing team aims to target customers with a high probability of purchasing bread in the next 30 days, but only a moderate probability of purchasing soft drinks during the same period. They plan to engage these customers through outbound channels such as email and paid media, with a bundled offer designed to encourage the purchase of items in both product categories together. For visitors to the brand's website, the marketing team seeks to provide a consistent and personalized experience on the main page, where the banner presented showcases the product category that the particular visitor is most likely to purchase.
To enable the marketing team's workflow with this data, the CDP administrators have configured a seamless connection between the ActionIQ platform and Databricks, leveraging ActionIQ's HybridCompute integration. Simultaneously, the Databricks administrators have set up permissions on the appropriate objects to allow queries originating from ActionIQ to be performed. The marketing team does not require knowledge of these technical details. To them, the propensity score data simply appears as a source of customer data within the ActionIQ user interface. (Figure 2).
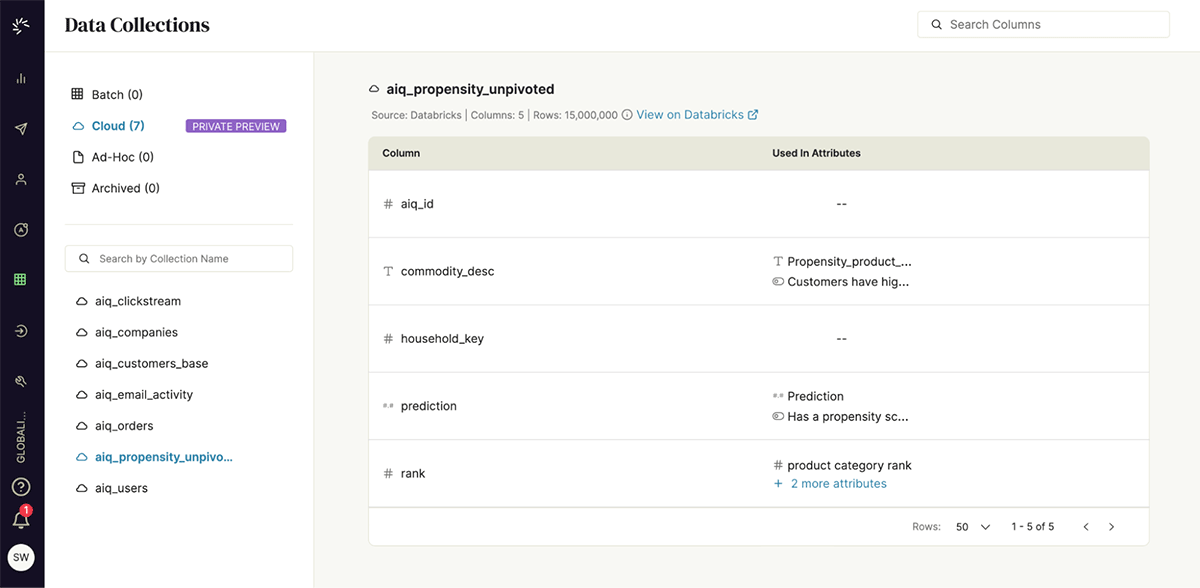
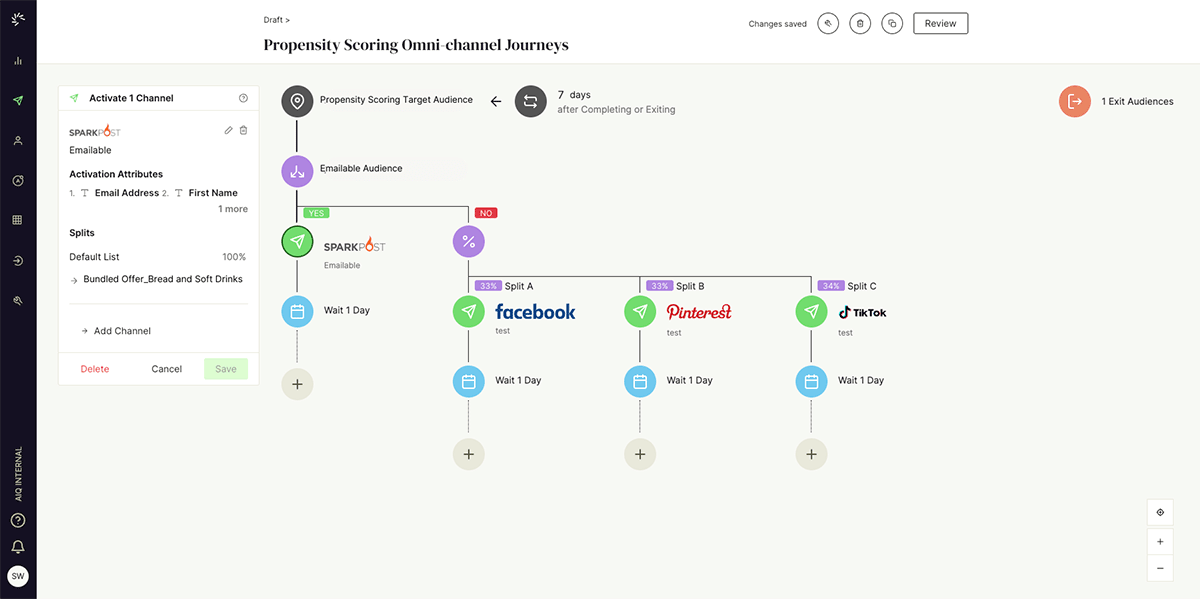
Within ActionIQ, the marketing team can instantly create audience segments using the no-code UI, without relying on IT teams. They can then map out the multi-step customer journeys using the drag-and-drop canvas in ActionIQ, easily orchestrating personalized experiences across all outbound channels where they want to engage the customers —— in this case, email and paid media channels. Once completed, the specific content or offer is targeted to the right customers, and the necessary steps are taken to trigger activation (Figure 3).
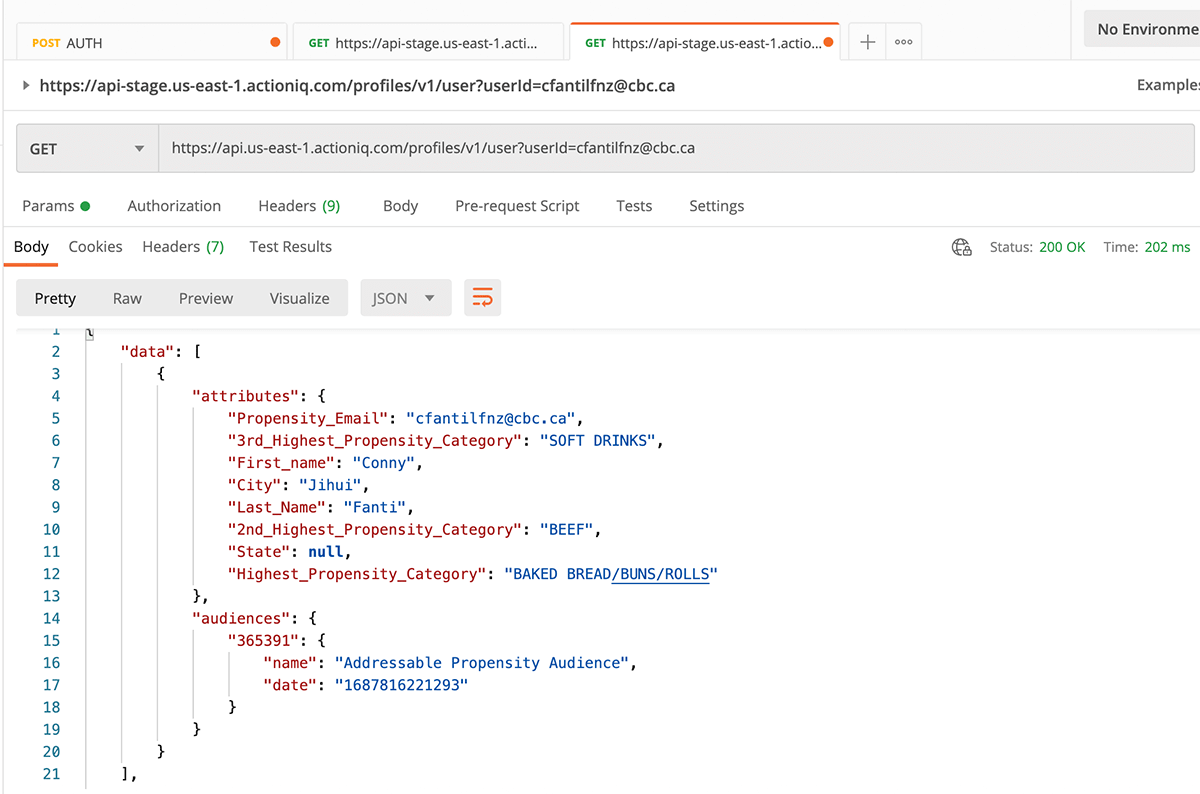
Additionally, the marketing team can personalize the main page of the website in real time by accessing the visitor's purchase propensity information within millisecond, leveraging the ActionIQ Profile API (Figure 4).
The beauty of this approach is again that the data scientists and data engineers responsible for continuously deriving these propensity scores using the latest customer data can work in their preferred environment. As soon as the data is updated in the Databricks Lakehouse, the marketing team can tap into it right away, without having to wait for a slow and cumbersome data replication process to be triggered. Furthermore, the data governance team can be assured that this sensitive data is managed from a central location while still enabling the business outcomes that provide value.
Put It Into Action in Part Two
In part two of our how-to, get step-by-step details with visuals on how ActionIQ integrates with Databricks via HybridCompute, enabled by native query pushdown to the Databricks Lakehouse. For each step, we will first provide a high level description on the concept, and then explain its implementation in the context of the use case outlined above.
Interested to learn more about how a Composable CDP can help you scale your customer data operations? Reach out to the ActionIQ team.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.