Managing Complex Propensity Scoring Scenarios with Databricks
by Tian Tan and Bryan Smith

Check our Solution Accelerator for Propensity Scoring for more details and to download the notebooks.
Consumers increasingly expect to be engaged in a personalized manner. Whether it’s an email message promoting products to complement a recent purchase, an online banner ad announcing a sale on products in a frequently browsed category or videos or articles aligned with expressed (or implied) interests, consumers have demonstrated a preference for messaging that recognizes their personal needs and values.
Organizations that can meet this preference with targeted content have the opportunity to generate higher revenues from consumer engagements, while those that cannot run the risk of customer defection in an increasingly crowded and more analytically sophisticated retail landscape. As a result, many organizations are making sizeable investments in personalization, despite economic uncertainty that’s slowing spend in other areas.
But where to get started? Once an organization has established processes for collecting and harmonizing customer data from across various touch points, how might marketers use this data to provide better content alignment?
Propensity scoring remains one of the most widely adopted approaches for building targeted marketing campaigns. The basic technique entails the training of a simple machine learning model to predict whether or not a customer will purchase an item from within a larger group of products within a specified period of time. Marketers can use the estimated probability of a purchase to decide not just who to target with product-aligned campaigns but messages and offers to employ to drive a desired outcome.
Managing Numerous, Overlapping Models Creates Complexity
The challenge faced by most organizations is not the development of a given propensity model but the support of the tens if not hundreds of models required to cover the various marketing campaigns within which they are engaging. Let’s say a business intends to run a campaign focused on grocery items associated with a mid-Summer grilling party. The promotions team may define a product group consisting of select brands of hot dogs, chips, sodas and beer, and the marketing team would then need to have a model created for that specific group. This campaign may run concurrent with several other campaigns, each of which will have their own, possibly overlapping product groups and associated models. Pretty soon, the organization finds itself juggling a large number of models and workflows through which they are employed to re-evaluate individual customers’ receptiveness to product offers.
From the outside looking in, all this work is reflected in a fairly simple table structure. Within this structure, each customer is assigned a score for each product group (Figure 1). Using these scores, the marketing team defines audiences/segments to associate with specific campaigns and content.

But to the data scientists and data engineers responsible for ensuring these scores are accurate and up to date, assembling this information requires the thoughtful coordination of three separate tasks.
This Complexity Can Be Tackled through Three Tasks
The first of these tasks is the derivation of feature inputs. Some of these are simply attributes associated with a user or product group that slowly change over time, but the vast majority are metrics typically derived from transactional history. With each new transaction, previously derived metrics become dated so that data engineers are often challenged to strike a balance between the cost of recomputing these metrics and the impact of changes in these values on prediction accuracy.
Closely coupled to this first task is the task of propensity re-estimation. As features are recomputed, these values are fed to previously trained models to generate updated scores (which are then recorded in the profile table). The challenge here is to not only generate the scores for all the different households and active models, but to keep track of which of the often hundreds if not thousands of feature inputs are employed by a given model.
Lastly, data scientists must consider how customer behavior changes over time and periodically retrain each model, allowing it to learn new insights from the historical data that will help it generate accurate predictions in the period ahead.
Databricks Helps Coordinate These Tasks
Keeping up with all these challenges while juggling so many different models can start to feel a bit overwhelming, but the data scientists and engineers tasked with managing this process can simplify things greatly by managing these tasks as part of two general workflows and by taking advantage of key features in the Databricks platform intended to assist them with these processes (Figure 2).
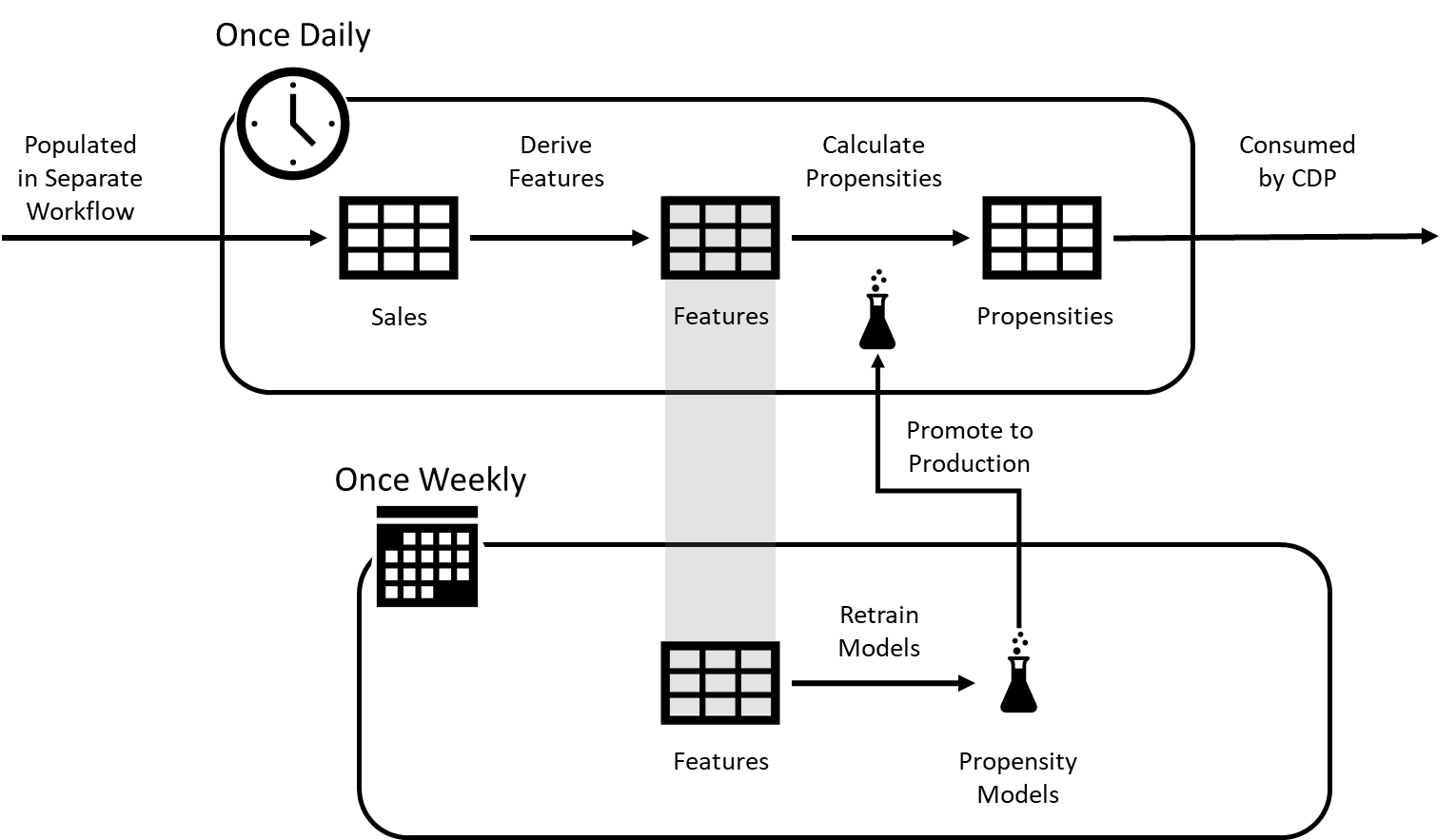
In the first of the workflows (often scheduled on a daily basis), the back office team focuses on the recalculation of features and scores. Information on active product groupings is retrieved to control which features need to be recalculated and these values are recorded to the Databricks feature store.
The feature store is a specialized capability within the Databricks platform that allows previously trained models to retrieve the features on which they depend with minimal input at the time of model inference. In the case of propensity scoring, just provide an identifier for the customer and product group you wish to score and the model will leverage the feature store to retrieve the specific values it needs to return a prediction.
In the second of the workflows (often scheduled on a weekly or longer basis), the data science team schedules each model for periodic re-training. Newly trained models are registered with the pre-integrated MLflow registry, which allows the Databricks environment to track multiple versions for each model. Internal processes can be employed to test and evaluate newly trained models without concern that they may be exposed to the scoring workflow until they have been fully vetted and blessed for production readiness. Once assigned this status, the first workflow sees the model as the current active model and uses it for model scoring with its next cycle.
While each workflow is dependent on the other, they each operate on different frequencies. The feature generation and scoring workflow typically occurs on a daily or sometimes weekly basis, depending on the needs of the organization. The model retraining workflow occurs far less frequently, possibly on a weekly, monthly or even quarterly basis. To coordinate these two, organizations can leverage the built-in Databricks Workflows capability.
Databricks Workflows go far beyond simple process scheduling. They allow you to not only define the various tasks that make up a workflow but the specific resources required to execute them. Monitoring and alerting capabilities help you manage these processes in the background, while state management features help you not just troubleshoot but restart failed jobs should they occur.
By approaching propensity scoring as two closely related streams of work and leveraging the Databricks feature store, workflows and the integrated MLflow model registry, you can greatly reduce the complexity associated with this work. Want to see these workflows in action? Check out our Solution Accelerators for Propensity Scoring where we put these concepts and features into practice against a real-world dataset. We demonstrate how configurable sets of products can be enlisted for use in the development of several propensity scoring models and how those models can then be used to generate up-to-date scores, accessible to a wide variety of marketing platforms. We hope this resource helps retail organizations define a sustainable process for propensity scoring that will advance their initial personalization efforts.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.