What’s new with Databricks SQL?
AI-driven optimizations, lakehouse federation, and more for enterprise-grade BI
by Alex Lichen, Miranda Luna, Can Efeoglu and Cyrielle Simeone
At this year's Data+AI Summit, Databricks SQL continued to push the boundaries of what a data warehouse can be, leveraging AI across the entire product surface to extend our leadership in performance and efficiency, while still simplifying the experience and unlocking new opportunities for our customers. In parallel, we continue to deliver improvements to our core data warehousing capabilities to help you unify your data stack under Lakehouse.
In this blog post, we are thrilled to share the highlights of what's new and coming next in Databricks SQL:
- AI-driven performance optimizations like Predictive I/O that deliver leading performance and cost-savings, without manual tuning required.
- New user experiences with AI Functions, SQL Warehouses in Notebooks, new Dashboards, and Python User Defined Functions.
- Rich external data source support with Lakehouse Federation.
- New ways to access your data with the SQL Statement Execution API.
- Simple and efficient data processing with Streaming Tables, Materialized Views and Workflows integration.
- Intelligent assistance powered by LakehouseIQ, our knowledge engine.
- Enhanced administration tools with Databricks SQL System Tables and Live Query Profile.
- Additional features for our partner integrations with Fivetran, dbt labs and PowerBI
The AI-optimized warehouse: Ready for all your workloads - no tuning required
We believe that the best data warehouse is a lakehouse; therefore, we continue to extend our leadership in ETL workloads and harnessing the power of AI. Databricks SQL now also delivers industry-leading performance for your EDA and BI workloads, while improving cost savings - with no manual tuning.

Say goodbye to manually creating indexes. With Predictive I/O for reads (GA) and updates (Public Preview), Databricks SQL now analyzes historical read and write patterns to intelligently build indexes and optimize workloads. Early customers have benefited from a remarkable 35x improvement in point lookup efficiency, impressive performance boosts of 2-6x for MERGE operations and 2-10x for DELETE operations.
With Predictive Optimizations (Public Preview), Databricks will seamlessly optimize file sizes and clustering by running OPTIMIZE, VACUUM, ANALYZE and CLUSTERING commands for you. With this feature, Anker Innovations benefited from a 2.2x boost to query performance while delivering 50% savings on storage costs.
"Databricks' Predictive Optimizations intelligently optimized our Unity Catalog storage, which saved us 50% in annual storage costs while speeding up our queries by >2x. It learned to prioritize our largest and most-accessed tables. And, it did all of this automatically, saving our team valuable time." —Anker Innovations
Tired of managing different warehouses for smaller and larger workloads or fine tuning scaling parameters? Intelligent Workload Management is a suite of features that keeps queries fast while keeping cost low. By analyzing real time patterns, Intelligent Workload Management ensures that your workloads have the optimal amount of compute to execute incoming SQL statements without disrupting already running queries.
With AI-powered optimizations, Databricks SQL provides industry leading TCO and performance for any kind of workload, without any manual tuning needed. To learn more about available optimization previews, watch Reynold Xin's keynote and Databricks SQL Serverless Under the Hood: How We Use ML to Get the Best Price/Performance from the Data+AI Summit.
Unlock siloed data with Lakehouse Federation
Today's organizations face challenges in discovering, governing and querying siloed data sources across fragmented systems. With Lakehouse Federation, data teams can use Databricks SQL to discover, query and manage data in external platforms including MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, Google's BigQuery (coming soon) and more.
Furthermore, Lakehouse Federation seamlessly integrates with advanced features of Unity Catalog when accessing external data sources from within Databricks. Enforce row and column level security to restrict access to sensitive information. Leverage data lineage to trace the origins of your data and ensure data quality and compliance. To organize and manage data assets, easily tag federated catalog assets for simple data discovery.
Finally, to accelerate complicated transformations or cross-joins on federated sources, Lakehouse Federation supports Materialized Views for better query latencies.
Lakehouse Federation is in Public Preview today. For more details, watch our dedicated session Lakehouse Federation: Access and Governance of External Data Sources from Unity Catalog from the Data+AI Summit.
Develop on the Lakehouse with the SQL Statement Execution API
The SQL Statement Execution API enables access to your Databricks SQL warehouse over a REST API to query and retrieve results. With HTTP frameworks available for almost all programming languages, you can easily connect to a diverse array of applications and platforms directly to a Databricks SQL Warehouse.
The Databricks SQL Statement Execution API is available with the Databricks Premium and Enterprise tiers. To learn more, watch our session, follow our tutorial (AWS | Azure), read the documentation (AWS | Azure), or check our repository of code samples.
Streamline your data processing with Streaming Tables, Materialized Views, and DB SQL in Workflows
With Streaming Tables, Materialized Views, and DB SQL in Workflows, any SQL user can now apply data engineering best practices to process data. Efficiently ingest, transform, orchestrate, and analyze data with just a few lines of SQL.
Streaming Tables are the ideal way to bring data into "bronze" tables. With a single SQL statement, scalably ingest data from various sources such as cloud storage (S3, ADLS, GCS), message buses (EventHub, Kafka, Kinesis), and more. This ingestion occurs incrementally, enabling low-latency and cost-effective pipelines, without the need for managing complex infrastructure.
Materialized Views reduce cost and improve query latency by pre-computing slow queries and frequently used computations, and are incrementally refreshed to improve overall latency. In a data engineering context, they are used for transforming data. But they are also valuable for analyst teams in a data warehousing context because they can be used to (1) speed up end-user queries and BI dashboards, and (2) securely share data. In just four lines of code, any user can create a materialized view for performant data processing.
Need orchestration with DB SQL? Workflows now allows you to schedule SQL queries, dashboards and alerts. Easily manage complex dependencies between tasks and monitor past job executions with the intuitive Workflows UI or via API.
Streaming Tables and Materialized Views are now in public preview. To learn more, read our dedicated blog post. To enroll in the public preview for both, enroll in this form. Workflows in DB SQL is now generally available, and you can learn more by reading the documentation (AWS | Azure).
Databricks Assistant: Write better and faster SQL with natural language
Databricks Assistant is a context-aware AI assistant embedded inside Databricks Notebooks and the SQL Editor. Databricks Assistant can take a natural language question and suggest a SQL query to answer that question. When trying to understand a complex query, users can ask the Assistant to explain it using natural language, enabling anyone to understand the logic behind query results.
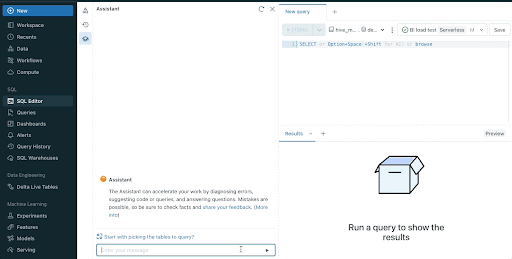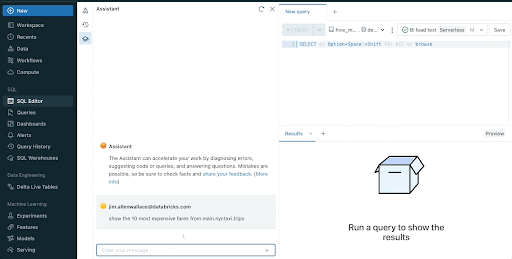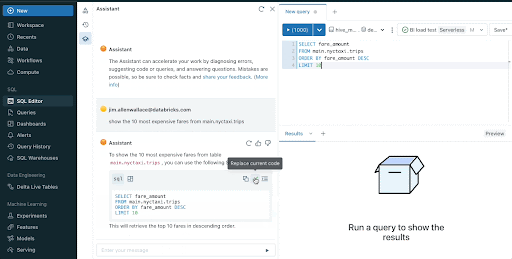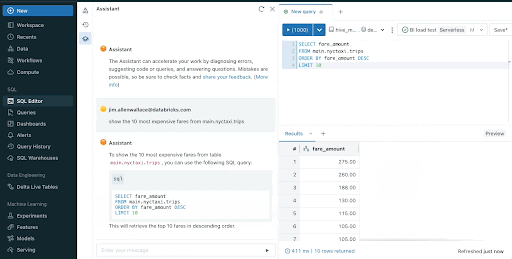
Databricks Assistant uses a number of signals to provide more accurate, relevant results. It uses context from code cells, libraries, popular tables, Unity Catalog schemas and tags to map natural language questions into queries and code.
In the future, we will be adding integration with LakehouseIQ to provide even more context for your requests.
Manage your data warehouse with confidence
Administrators and IT teams need the tools to understand data warehouse usage. With System Tables, Live Query Profile, and Statement Timeouts, admins can monitor and fix problems when they occur, ensuring that your data warehouse runs efficiently.
Gain deeper visibility and insights into your SQL environment with System Tables. System Tables are Databricks-provided tables that contain information about past statement executions, costs, lineage, and more. Explore metadata and usage metrics to answer questions like "What statements were run and by whom?", "How and when did my warehouses scale?" and "What was I billed for?". Since System Tables are integrated within Databricks, you have access to native capabilities such as SQL alerts and SQL dashboards to automate the monitoring and alerting process.
As of today, there are three System Tables currently in public preview: Audit Logs, Billable Usage System Table, and Lineage Sytem Table (AWS | Azure). Additional system tables for warehouse events and statement history are coming soon.
For example, to compute the monthly DBUs used per SKU, you can query the Billiable Usage System Tables.
With Live Query Profile, users gain real-time insights into query performance to help optimize workloads on the fly. Visualize query execution plans and assess live query task executions to fix common SQL mistakes like exploding joins or full table scans. Live Query Profile allows you to ensure that running queries on your data warehouse are optimized and running efficiently. Learn more by reading the documentation (AWS | Azure).
Looking for automated controls? Statement Timeouts allow you to set a custom workspace or query level timeout. If a query's execution time exceeds the timeout threshold, the query will be automatically halted. Learn more by reading the documentation (AWS | Azure)
Compelling new experiences in DBSQL
Over the past year, we've been hard at work to add new, cutting-edge experiences to Databricks SQL. We're excited to announce new features that put the power of AI in SQL users hands such as, enabling SQL warehouses throughout the entire Databricks platform; introducing a new generation of SQL dashboards; and bringing the power of Python into Databricks SQL.
Democratize unstructured data analysis with AI Functions
With AI Functions, DB SQL is bringing the power of AI into the SQL warehouse. Effortlessly harness the potential of unstructured data by performing tasks such as sentiment analysis, text classification, summarization, translation and more. Data analysts can apply AI models via self-service, while data engineers can independently build AI-enabled pipelines.
Using AI Functions is quite simple. For example, consider a scenario where a user wants to classify the sentiment of some articles into Frustrated, Happy, Neutral, or Satisfied.
AI Functions are now in Public Preview. To sign up for the Preview, fill out the form here. To learn more, you can also read our detailed blog post or review the documentation (AWS | Azure).
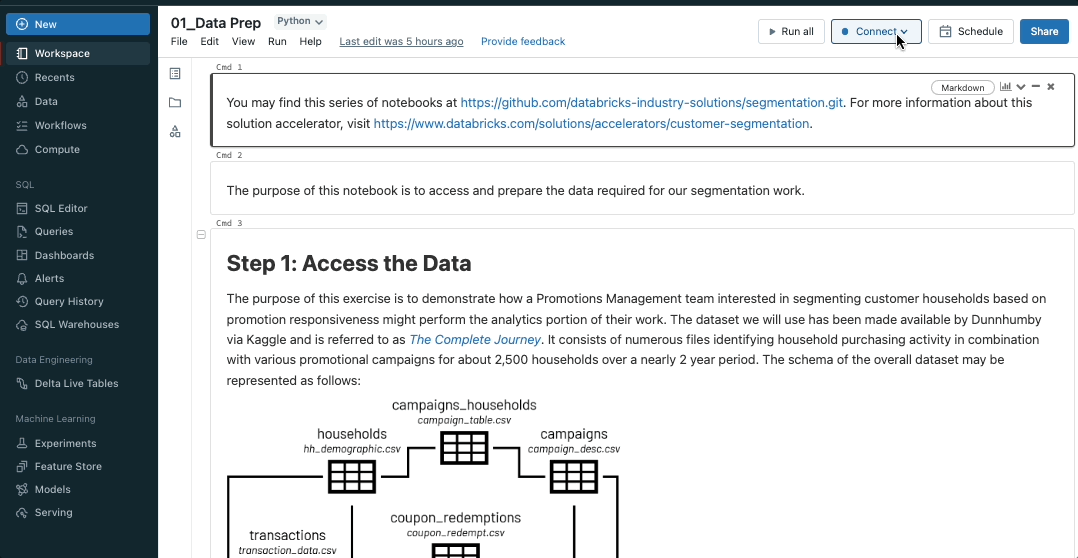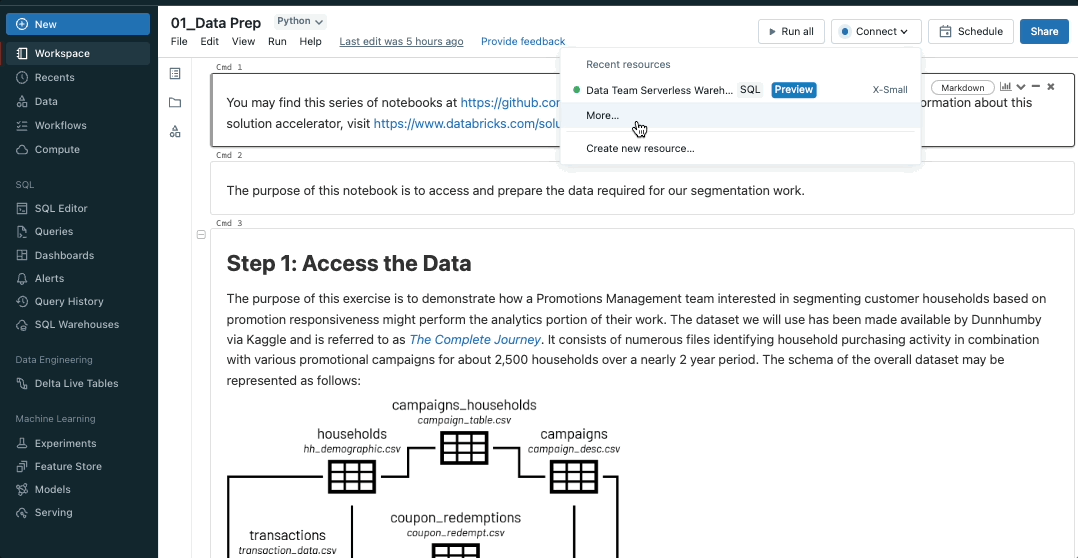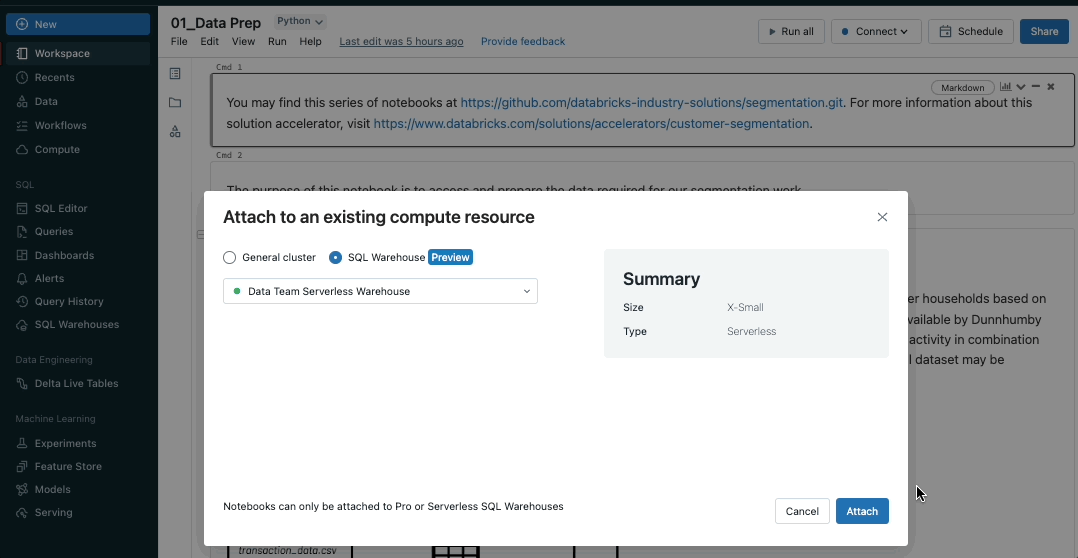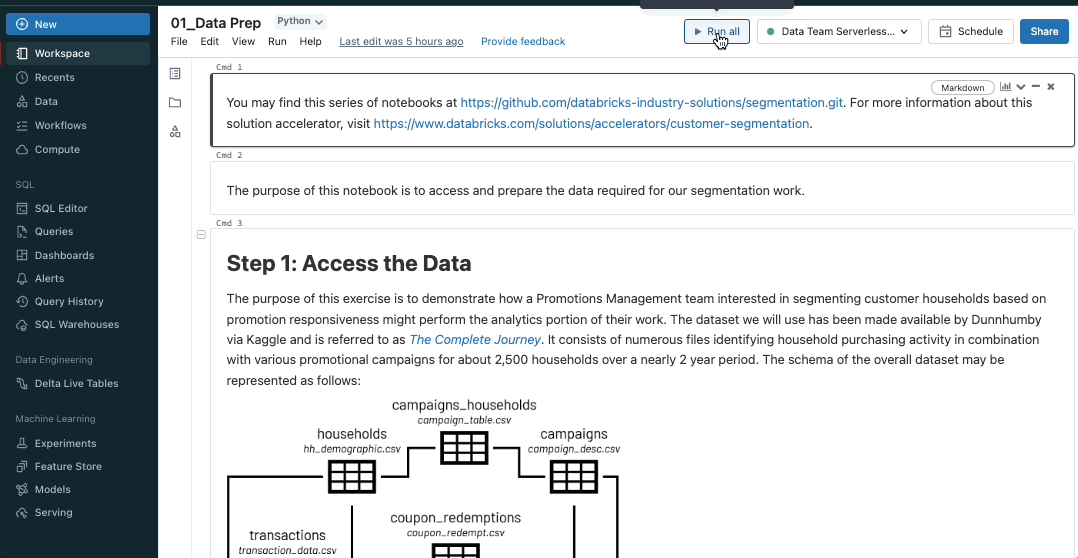
Bring the power of SQL warehouses to notebooks
Databricks SQL warehouses are now public preview in notebooks, combining the flexibility of notebooks with the performance and TCO of Databricks SQL Serverless and Pro warehouses. To enable SQL warehouses in notebooks, simply select an available SQL warehouse from the notebooks compute dropdown.
Find and share insights with a new generation of dashboards
Discover a revamped dashboarding experience directly on the Lakehouse. Users can simply select a desired dataset and build stunning visualizations with a SQL-optional experience. Say goodbye to managing separate queries and dashboard objects - an all-in-one content model simplifies the permissions and management process. Finally, publish a dashboard to your entire organization, so that any authenticated user in your identity provider can access the dashboard via a secure web link, even if they don't have Databricks access.
New Databricks SQL Dashboards are currently in Private Preview. Contact your account team to learn more.
Leverage the flexibility of Python in SQL
Bring the flexibility of Python into Databricks SQL with Python user-defined functions (UDFs). Integrate machine learning models or apply custom redaction logic for data processing and analysis by calling custom Python functions directly from your SQL query. UDFs are reusable functions, enabling you to apply consistent processing to your data pipelines and analysis.
For instance, to redact email and phone numbers from a file, consider the following CREATE FUNCTION statement.
Learn more about enrolling in the private preview here.
Integrations with your data ecosystem
At Data+AI Summit, Databricks SQL announced new integrations for a seamless experience with your tools of choice.
Databricks + Fivetran
We're thrilled to announce the general availability of Fivetran access in Partner Connect for all users including non-admins with sufficient privileges to a catalog. This innovation makes it 10x easier for all users to ingest data into Databricks using Fivetran. This is a huge win for all Databricks customers as they can now bring data into the Lakehouse from hundreds of connectors Fivetran offers, like Salesforce and PostgreSQL. Fivetran now fully supports Serverless warehouses as well!
Learn more by reading the blog post here.
Databricks + dbt Labs
Simplify real-time analytics engineering on the lakehouse architecture with Databricks and dbt Labs. The combination of dbt's highly popular analytics engineering framework with the Databricks Lakehouse Platform provides powerful capabilities:
- dbt + Streaming Tables: Streaming ingestion from any source is now built-in to dbt projects. Using SQL, analytics engineers can define and ingest cloud/streaming data directly within their dbt pipelines.
- dbt + Materialized Views: Building efficient pipelines becomes easier with dbt, leveraging Databricks' powerful incremental refresh capabilities. Users can use dbt to build and run pipelines backed by MVs, reducing infrastructure costs with efficient, incremental computation.
To learn more, read the detailed blog post.
Databricks + PowerBI: Publish to PowerBI Workspaces
Publish datasets from your Databricks workspace to PowerBI Online workspace with a few clicks! No more managing odbc/jdbc connections - simply select the dataset you want to publish. Simply select the datasets or schema you want to publish and select your PBI workspace! This makes it easier for BI admins and report creators to support PowerBI workspaces without also having to use Power BI Desktop.
PowerBI integration with Data Explorer is coming soon and will only be available on Azure Databricks.
Getting Started with Databricks SQL
Follow the guide (AWS | Azure | GCP ) on how to setup a SQL warehouse to get started with Databricks SQL today! Databricks SQL Serverless is currently available with a 20%+ promotional discount, visit our pricing page to learn more.
You can also watch Databricks SQL: Why the Best Serverless Data Warehouse is a Lakehouse and What's New in Databricks SQL -- With Live Demos for a complete overview.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.